本文介紹作業效能相關的常見問題。
如何拆分運算元節點?
在頁面,單擊目標作業名稱,在部署詳情頁簽的運行參數配置地區的其他配置中,添加如下代碼後儲存生效。
pipeline.operator-chaining: 'false'Group Aggregate最佳化技巧有哪些?
-
開啟MiniBatch(提升吞吐)
MiniBatch是緩衝一定的資料後再觸發處理,以減少對State的訪問,從而提升輸送量並減少資料的輸出量。
MiniBatch主要基於事件訊息來觸發微批處理,事件訊息會按您指定的時間間隔在源頭插入。
-
適用情境
微批處理通過增加延遲換取高吞吐,如果您有超低延遲的要求,不建議開啟微批處理。通常對於彙總情境,微批處理可以顯著提升系統效能,建議開啟。
-
開啟方式
MiniBatch預設關閉,您需要在目標作業的部署詳情頁簽,運行參數配置地區的其他配置中,填寫以下代碼。
table.exec.mini-batch.enabled: true table.exec.mini-batch.allow-latency: 5s參數解釋如下表所示。
參數
說明
table.exec.mini-batch.enabled
是否開啟mini-batch。
table.exec.mini-batch.allow-latency
批量輸出資料的時間間隔。
-
-
開啟LocalGlobal(解決常見資料熱點問題)
LocalGlobal機制通過LocalAgg彙總篩選部分傾斜資料,有效減輕GlobalAgg的熱點壓力,提升整體效能。
LocalGlobal最佳化將原先的Aggregate分成Local和Global兩階段彙總,即MapReduce模型中的Combine和Reduce兩階段處理模式。第一階段在上遊節點本地攢一批資料進行彙總(localAgg),並輸出這次微批的增量值(Accumulator)。第二階段再將收到的Accumulator合并(Merge),得到最終的結果(GlobalAgg)。
-
適用情境
提升普通彙總(例如SUM、COUNT、MAX、MIN和AVG)的效能,以及這些情境下的資料熱點問題。
-
使用限制
LocalGlobal是預設開啟的,但是有以下限制:
-
在minibatch開啟的前提下才會生效。
-
需要使用AggregateFunction實現Merge。
-
-
判斷是否生效
觀察最終產生的拓撲圖的節點名字中是否包含GlobalGroupAggregate或LocalGroupAggregate。
-
-
開啟PartialFinal(解決COUNT DISTINCT熱點問題)
為瞭解決COUNT DISTINCT的熱點問題,通常需要手動改寫為兩層彙總(增加按Distinct Key模數的打散層)。目前,Realtime Compute提供了COUNT DISTINCT自動打散,即PartialFinal最佳化,您無需自行改寫為兩層彙總。
LocalGlobal最佳化針對普通彙總(例如SUM、COUNT、MAX、MIN和AVG)有較好的效果,對於COUNT DISTINCT收效不明顯,因為COUNT DISTINCT在Local彙總時,對於DISTINCT KEY的去重率不高,導致在Global節點仍然存在熱點問題。
-
適用情境
使用COUNT DISTINCT,但無法滿足彙總節點效能要求。
重要-
不能在包含UDAF的Flink SQL中使用PartialFinal最佳化方法。
-
資料量較少的情況,不建議使用PartialFinal最佳化方法,以免浪費資源。因為PartialFinal最佳化會自動打散成兩層彙總,引入額外的網路Shuffle。
-
-
開啟方式
預設不開啟。如果您需要開啟,則需要在目標作業的部署詳情頁簽,運行參數配置地區的其他配置中,填寫以下代碼。
table.optimizer.distinct-agg.split.enabled: true -
判斷是否生效
觀察最終產生的拓撲圖,是否由原來一層的彙總變成了兩層的彙總。
-
-
AGG WITH CASE WHEN改寫為AGG WITH FILTER文法(提升大量COUNT DISTINCT情境效能)
統計作業需要計算各種維度UV,例如全網UV、來自手機用戶端的UV、來自PC的UV等等。建議使用標準的AGG WITH FILTER文法來代替CASE WHEN實現多維度統計的功能。Realtime Compute目前的SQL最佳化器能分析出Filter參數,從而同一個欄位上計算不同條件下的COUNT DISTINCT能共用State,減少對State的讀寫操作。效能測試中,使用AGG WITH FILTER文法來代替CASE WHEN能夠使效能提升1倍。
-
適用情境
對於在同一個欄位上計算不同條件下的COUNT DISTINCT結果的情境,效能提升很大。
-
原始寫法
COUNT(distinct visitor_id) as UV1 , COUNT(distinct case when is_wireless='y' then visitor_id else null end) as UV2 -
最佳化寫法
COUNT(distinct visitor_id) as UV1 , COUNT(distinct visitor_id) filter (where is_wireless='y') as UV2
-
TopN最佳化技巧有哪些?
-
TopN演算法
當TopN的輸入是非更新流(例如SLS資料來源),TopN只有1種演算法AppendRank。當TopN的輸入是更新流時(例如經過了AGG或JOIN計算),TopN有2種演算法,效能從高到低分別是:UpdateFastRank和RetractRank。演算法名字會顯示在拓撲圖的節點名字上。
-
AppendRank:對於非更新流,只支援該演算法。
-
UpdateFastRank:對於更新流,最優演算法。
-
RetractRank:對於更新流,保底演算法。效能不佳,在某些業務情境下可最佳化成UpdateFastRank。
下面介紹RetractRank如何最佳化成UpdateFastRank。使用UpdateFastRank演算法需要具備3個條件:
-
輸入資料流為更新流。
-
輸入資料流有Primary Key資訊,例如上遊做了GROUP BY彙總操作。
-
排序欄位的更新是單調的,且單調方向與排序方向相反。例如,ORDER BY COUNT、COUNT_DISTINCT或SUM(正數)DESC。
如果您要擷取到UpdateFastRank的最佳化Plan,則您需要在使用ORDER BY SUM DESC時,添加SUM為正數的過濾條件,確保total_fee為正數。
insert into print_test SELECT cate_id, seller_id, stat_date, pay_ord_amt --不輸出rownum欄位,能減小結果表的輸出量。 FROM ( SELECT *, ROW_NUMBER () OVER ( PARTITION BY cate_id, stat_date --注意要有時間欄位,否則State到期會導致資料錯亂。 ORDER BY pay_ord_amt DESC ) as rownum --根據上遊sum結果排序。 FROM ( SELECT cate_id, seller_id, stat_date, --重點。聲明Sum的參數都是正數,所以Sum的結果是單調遞增的,因此TopN能使用最佳化演算法,只擷取前100個資料。 sum (total_fee) filter ( where total_fee >= 0 ) as pay_ord_amt FROM random_test WHERE total_fee >= 0 GROUP BY cate_name, seller_id, stat_date, cate_id ) a ) WHERE rownum <= 100; -
-
TopN最佳化方法
-
無排名最佳化
TopN的輸出結果不需要顯示rownum值,僅需在最終最上層顯示時進行1次排序,極大地減少輸入結果表的資料量。無排名最佳化方法詳情請參見Top-N。
-
增加TopN的Cache大小
TopN為了提升效能有一個State Cache層,Cache層能提升對State的訪問效率。TopN的Cache命中率的計算公式如下。
cache_hit = cache_size*parallelism/top_n/partition_key_num例如,Top100配置緩衝10000條,並發50,當您的PartitionBy的Key維度較大時,例如10萬層級時,Cache命中率只有10000*50/100/100000=5%,命中率會很低,導致大量的請求都會擊中State(磁碟),觀察state seek metric可能會有很多毛刺。效能會大幅下降。
因此當partitionKey維度特別大時,可以適當加大TopN的cache size,相應的也建議適當加大TopN節點的heap memory,詳情請參見配置作業部署資訊。
table.exec.rank.topn-cache-size: 200000預設值為10000條,調整TopN cache到200000,那麼理論命中率能達到
200000*50/100/100000 = 100%。 -
PartitionBy的欄位中要有時間類欄位
例如每天的排名,要帶上Day欄位,否則TopN的最終結果會由於State TTL產生錯亂。
-
有哪些高效去重方案?
Realtime ComputeFlink版的來源資料在部分情境中存在重複資料,去重成為了使用者經常反饋的需求。Realtime Compute有保留第一條(Deduplicate Keep FirstRow)和保留最後一條(Deduplicate Keep LastRow)2種去重方案。
-
文法
由於SQL上沒有直接支援去重的文法,還要靈活地保留第一條或保留最後一條。因此我們使用了SQL的ROW_NUMBER OVER WINDOW功能來實現去重文法。去重本質上是一種特殊的TopN。
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY col1[, col2..] ORDER BY timeAttributeCol [asc|desc]) AS rownum FROM table_name) WHERE rownum = 1參數
說明
ROW_NUMBER()
計算行號的OVER視窗函數。行號從1開始計算。
PARTITION BY col1[, col2..]
可選。指定分區的列,即去重的KEYS。
ORDER BY timeAttributeCol [asc|desc])
指定排序的列,必須是一個時間屬性的欄位(即Proctime或Rowtime)。可以指定順序(Keep FirstRow)或者倒序 (Keep LastRow)。
rownum
僅支援
rownum=1或rownum<=1。如上文法所示,去重需要兩層Query:
-
使用
ROW_NUMBER()視窗函數來對資料根據時間屬性列進行排序並標上排名。-
當排序欄位是Proctime列時,Flink就會按照系統時間去重,其每次啟動並執行結果是不確定的。
-
當排序欄位是Rowtime列時,Flink就會按照業務時間去重,其每次啟動並執行結果是確定的。
-
-
對排名進行過濾,只取第一條,達到了去重的目的。
排序方向可以是按照時間列的順序,也可以是倒序:
-
Deduplicate Keep FirstRow:順序並取第一行資料。
-
Deduplicate Keep LastRow:倒序並取第一行資料。
-
-
-
Deduplicate Keep FirstRow
保留首行的去重策略:保留KEY下第一條出現的資料,之後出現該KEY下的資料會被丟棄。因為STATE中只儲存了KEY資料,所以效能較優,樣本如下。
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY b ORDER BY proctime) as rowNum FROM T ) WHERE rowNum = 1以上樣本是將T表按照b欄位進行去重,並按照系統時間保留第一條資料。proctime在這裡是源表T中的一個具有Processing Time屬性的欄位。如果您按照系統時間去重,也可以將proctime欄位簡化proctime()函數調用,可以省略proctime欄位的聲明。
-
Deduplicate Keep LastRow
保留末行的去重策略:保留KEY下最後一條出現的資料。保留末行的去重策略效能略優於LAST_VALUE函數,樣本如下。
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY b, d ORDER BY rowtime DESC) as rowNum FROM T ) WHERE rowNum = 1以上樣本是將T表按照b和d欄位進行去重,並按照業務時間保留最後一條資料。rowtime在這裡是源表T中的一個具有Event Time屬性的欄位。
在使用內建函數時,需要注意什嗎?
-
使用內建函數替換自訂函數
Realtime Compute的內建函數在持續的最佳化當中,請盡量使用內建函數替換自訂函數。Realtime Compute對內建函數主要進行了如下最佳化:
-
最佳化資料序列化和還原序列化的耗時。
-
新增直接對位元組單位進行操作的功能。
-
-
KEY VALUE函數使用單字元的分隔字元
KEY VALUE的簽名:
KEYVALUE(content, keyValueSplit, keySplit, keyName),當keyValueSplit和keySplit是單字元,例如,冒號(:)、逗號(,)時,系統會使用最佳化演算法,在位元據上直接尋找所需的keyName值,而不會將整個content進行切分,效能約提升30%。 -
LIKE操作注意事項
-
如果需要進行StartWith操作,使用
LIKE 'xxx%'。 -
如果需要進行EndWith操作,使用
LIKE '%xxx'。 -
如果需要進行Contains操作,使用
LIKE '%xxx%'。 -
如果需要進行Equals操作,使用
LIKE 'xxx',等價於str = 'xxx'。 -
如果需要匹配底線(_),請注意要完成轉義
LIKE '%seller/_id%' ESCAPE '/'。底線(_)在SQL中屬於單字元萬用字元,能匹配任何字元。如果聲明為LIKE '%seller_id%',則不僅會匹配seller_id,還會匹配seller#id、sellerxid或seller1id等,導致結果錯誤。
-
-
慎用正則函數(REGEXP)
Regex是非常耗時的操作,對比加減乘除通常有百倍的效能開銷,而且Regex在某些極端情況下可能會進入無限迴圈,導致作業阻塞,具體情況請參見Regex execution is too slow,因此建議使用LIKE。正則函數包括:
全表讀取階段效率低且存在反壓,如何解決?
可能是下遊節點處理太慢導致了反壓。因此您需要先排查下遊節點是否存在反壓。如果存在,則需要先解決下遊節點的反壓問題。您可以通過以下方式處理:
-
增加並發數。
-
開啟minibatch等彙總最佳化參數(下遊彙總節點)。
作業狀態總覽中vertex subtask的Status Durations顏色標識含義
在作業狀態總覽頁面,單擊運算元節點後選擇SubTasks頁簽,可查看Status Durations列中各階段的彩色耗時徽章。
Status Durations表示vertex subtask在各個階段的耗時,各顏色標識含義如下:
-
 :CREATED
:CREATED -
 :SCHEDULED
:SCHEDULED -
 :DEPLOYING
:DEPLOYING -
 :INITIALIZING
:INITIALIZING -
 :RUNNING
:RUNNING
RMI TCP Connection是什麼線程?為什麼佔用的CPU比其他線程高這麼多?
線上程監控列表中,按CPU降序排列,RMI TCP Connection(62)-172.25.240.255線程狀態為RUNNABLE,CPU佔用82.3%,遠高於其他kafkaRequestSource相關線程(CPU佔用16.9%~26.4%,狀態多為TIMED_WAITING)。
RMI TCP Connection線程是Java內建的RMI(Remote Method Invocation)架構中的線程,負責執行遠程方法調用。線程佔用CPU是動態即時變化的,短暫的指標波動不能代表CPU整體的負載過高。在一段時間內觀察CPU的使用方式,可以通過分析線程的火焰圖進行評估,從下圖可以看出RMI線程幾乎不消耗CPU。

運行拓撲圖中顯示的Low Watermark、Watermark以及Task InputWatermark指標顯示的時間和目前時間有時差?
-
原因1:聲明源表Watermark時使用了
TIMESTAMP_LTZ(TIMESTAMP(p) WITH LOCAL TIME ZONE)類型,導致Watermark和目前時間有時差。下文以具體的樣本為您展示使用TIMESTAMP_LTZ類型和TIMESTAMP類型對應的Watermark指標差異。
-
源表中Watermark聲明使用的欄位是TIMESTAMP_LTZ類型。
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts as CURRENT_TIMESTAMP,--使用CURRENT_TIMESTAMP內建函數產生TIMESTAMP_LTZ類型。 WATERMARK FOR ts AS ts - INTERVAL '5' SECOND ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE t1 ( k INT, ts_ltz timestamp_ltz(3), cnt BIGINT ) WITH ('connector' = 'print'); -- 輸出計算結果。 INSERT INTO t1 SELECT b, window_start, COUNT(*) FROM TABLE( TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '5' SECOND)) GROUP BY b, window_start, window_end;說明Legacy Window對應的老文法和
TVF Window(Table-Valued Function)產生的結果是一致的。以下為Legacy Window對應的老文法的範例程式碼。SELECT b, TUMBLE_END(ts, INTERVAL '5' SECOND), COUNT(*) FROM s1 GROUP BY TUMBLE(ts, INTERVAL '5' SECOND), b;在Realtime Compute開發控制台將作業部署上線運行後,以北京時間為例,可以觀察到作業運行拓撲圖及監控警示上顯示的Watermark和目前時間存在8小時時差。
-
Watermark&Low Watermark
在Flink作業監控介面的Watermarks頁簽中,SubTask 0的Watermark值為
1706778525521,對應Datetime of Watermark Timestamp為02-01 09:08:45,而作業啟動時間為02-01 17:03:04,兩者存在約8小時的時差。左側運算元面板的Low Watermark同樣顯示為02-01 09:08:45。 -
Task InputWatermark

-
-
源表中Watermark聲明使用的欄位是TIMESTAMP(TIMESTAMP(p) WITHOUT TIME ZONE)類型。
CREATE TEMPORARY TABLE s1 ( a INT, b INT, -- 類比資料源中的TIMESTAMP無時區資訊,從2024-01-31 01:00:00開始逐秒累加。 ts as TIMESTAMPADD(SECOND, a, TIMESTAMP '2024-01-31 01:00:00'), WATERMARK FOR ts AS ts - INTERVAL '5' SECOND ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.a.kind'='sequence','fields.a.start'='0','fields.a.end'='100000', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE t1 ( k INT, ts_ltz timestamp_ltz(3), cnt BIGINT ) WITH ('connector' = 'print'); -- 輸出計算結果。 INSERT INTO t1 SELECT b, window_start, COUNT(*) FROM TABLE( TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '5' SECOND)) GROUP BY b, window_start, window_end;在Realtime Compute開發控制台上將作業部署上線運行後,可以觀察到作業運行拓撲圖及監控警示上顯示的Watermark和目前時間是同步的(本樣本是與類比資料的時間同步的),不存在時差現象。
-
Watermark&Low Watermark
在 Flink Web UI 的任務詳情頁面中,選擇運算元(如 GlobalWindowAggregate)後,左側運算元資訊框中顯示 Low Watermark 值(如 01-31 01:03:49),右側切換到 Watermarks 標籤頁可查看各 SubTask 的 Watermark 值及對應時間戳記,兩者顯示的時間一致。
-
Task InputWatermark

-
-
-
原因2:Realtime Compute開發控制台和Apache Flink UI的展示時間存在時區差異。
Realtime Compute開發控制台UI介面是以UTC+0顯示時間,而Apache Flink UI是通過瀏覽器擷取本地時區並進行相應的時間轉換後的本地時間。以北京時間為例,為您展示二者顯示區別,您會觀察到在Realtime Compute開發控制台顯示的時間比Apache Flink UI時間慢8小時。
-
Realtime Compute開發控制台
在作業營運頁面的運行拓撲圖中,Watermark 時間以 UTC+0 時區顯示。例如,事件時間為北京時間
2024/1/31 上午9:01:34時,該頁面顯示為2024/1/31 上午1:01:34。在產品控制台的作業營運頁面中,Watermark 相關監控指標的時間以 UTC+0 時區顯示,即顯示的時間比北京時間慢 8 小時。
-
Apache Flink UI
在 Apache Flink Web UI 中,選中作業拓撲圖中的運算元節點(例如
GlobalWindowAggregate),切換到 Watermarks 頁簽,可查看各 SubTask 的 Watermark 值及其對應的事件時間。例如,Low Watermark 為1706662894000,對應的 Datetime of Watermark Timestamp 為2024/1/31 上午9:01:34。該時間為事件時間戳記而非當前處理時間,因此與系統目前時間存在時差屬於正常現象。
-
如何排查作業反壓問題?
-
在作業營運頁面,單擊目標作業名稱,進入狀態總覽頁簽。
-
查看Busy和BackPressure,確定反壓位置。
Busy指示燈顏色越紅,表示任務負載越重;BackPressure指示燈顏色越深,表示受反壓影響越嚴重。
例如,在作業拓撲圖中,上遊運算元 Backpressured (max) 為 99%,中間運算元 Busy (max) 為 100%(紅色高亮),下遊運算元 Busy (max) 僅為 7%,說明瓶頸在中間運算元,需針對該運算元進行最佳化。
-
單擊發生反壓的Operator。
-
在BackPressure頁簽,排查SubTask反壓情況。
頁面顯示 Back Pressure Status 為綠色 OK,表格列出 SubTask 0–7,每行 Backpressured / Idle / Busy 分別為
0%, 0%, N/A,狀態均為 OK,表明當前作業無反壓問題。
如何排查作業延遲過高的問題?
在作業營運頁面的監控警示或資料曲線頁簽下,查看currentEmitEventTimeLag和currentFetchEventTimeLag指標並進行對應的處理。指標說明如下:
-
若
currentEmitEventTimeLag指標數值偏高,表明作業在拉取資料或處理上存在延遲,需檢查運算元效能是否達標。 -
若
currentFetchEventTimeLag指標數值偏高,表明作業在拉取資料或上遊系統資料處理上存在延遲,需排查網路I/O和上遊系統。
當由上遊因素導致延遲較高時,兩個指標會同時增加。
Flink SQL作業資料熱點問題導致反壓,該如何最佳化?
作業存在反壓時,經查看Subtask反壓情況後,發現是資料熱點問題。此時您可以參考以下方式進行最佳化:
-
開啟LocalGlobal(解決常見資料熱點問題)
LocalGlobal機制通過LocalAgg彙總篩選部分傾斜資料,有效減輕GlobalAgg的熱點壓力,提升整體效能。
LocalGlobal最佳化將原先的Aggregate分成Local和Global兩階段彙總,即MapReduce模型中的Combine和Reduce兩階段處理模式。第一階段在上遊節點本地攢一批資料進行彙總(localAgg),並輸出這次微批的增量值(Accumulator)。第二階段再將收到的Accumulator合并(Merge),得到最終的結果(GlobalAgg)。
-
適用情境
提升普通彙總(例如SUM、COUNT、MAX、MIN和AVG)的效能,以及這些情境下的資料熱點問題。
-
使用限制
LocalGlobal是預設開啟的,但是有以下限制:
-
在minibatch開啟的前提下才會生效。
-
需要使用AggregateFunction實現Merge。
-
-
判斷是否生效
觀察最終產生的拓撲圖的節點名字中是否包含GlobalGroupAggregate或LocalGroupAggregate。
-
-
開啟PartialFinal(解決COUNT DISTINCT熱點問題)
為瞭解決COUNT DISTINCT的熱點問題,通常需要手動改寫為兩層彙總(增加按Distinct Key模數的打散層)。目前,Realtime Compute提供了COUNT DISTINCT自動打散,即PartialFinal最佳化,您無需自行改寫為兩層彙總。
LocalGlobal最佳化針對普通彙總(例如SUM、COUNT、MAX、MIN和AVG)有較好的效果,對於COUNT DISTINCT收效不明顯,因為COUNT DISTINCT在Local彙總時,對於DISTINCT KEY的去重率不高,導致在Global節點仍然存在熱點問題。
-
適用情境
使用COUNT DISTINCT,但無法滿足彙總節點效能要求。
重要-
不能在包含UDAF的Flink SQL中使用PartialFinal最佳化方法。
-
資料量較少的情況,不建議使用PartialFinal最佳化方法,以免浪費資源。因為PartialFinal最佳化會自動打散成兩層彙總,引入額外的網路Shuffle。
-
-
開啟方式
預設不開啟。如果您需要開啟,則需要在目標作業的部署詳情頁簽,運行參數配置地區的其他配置中,填寫以下代碼。
table.optimizer.distinct-agg.split.enabled: true -
判斷是否生效
觀察最終產生的拓撲圖,是否由原來一層的彙總變成了兩層的彙總。
-
消費上遊資料速度不穩定,該如何排查?
此類問題可能的原因與解決方案如下:
-
上遊生產資料規律與當前資料處理速度不一致。
請分析上遊資料產生規律,確保資料生產和處理速度相匹配。
-
作業存在反壓。
請檢查作業節點是否存在反壓影響消費上遊速度。如果當前作業顯示只有一個節點,添加
pipeline.operator-chaining: 'false'參數後重啟作業,拆開運算元鏈,觀察是否有被反壓的節點影響消費速率。 -
IO速率異常。
查看Flink對應時間下資料輸入曲線和消費速率的規律,以排查是否是由IO引起。
-
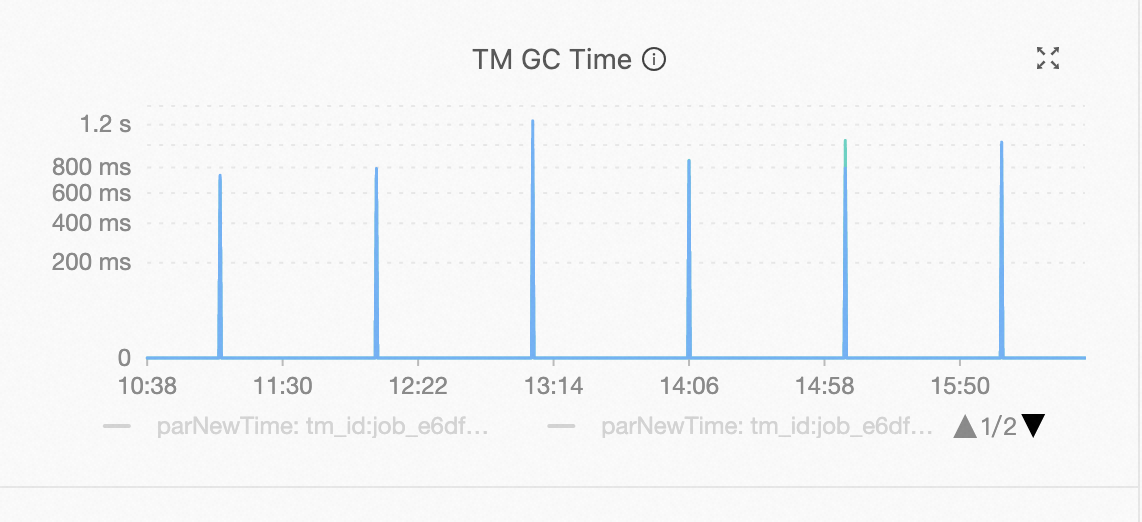
消費速率異常。
請觀察消費速度波動規律,是否與Garbage Collection (GC)時間點對應。如果波動與GC時間點對應,請檢查對應TM節點的記憶體情況。