本文為您介紹如何使用百鍊平台的模型服務進行資料分析。
背景資訊
阿里雲百鍊大模型服務平台是面向AI開發人員與業務團隊的一站式大模型開發及應用構建平台,深度融合了FlinkRealtime Compute能力。使用者可快速調用百鍊大模型能力,結合Flink即時資料處理管道,顯著縮短從資料接入到智能決策的鏈路。以下是兩種核心模型的應用情境:
chat/completions模型 chat/completions模型是一種基於對話產生和文本理解的大模型,廣泛應用於情感分析、意圖識別、問答系統等情境。
情感分析:對企業社交媒體評論進行即時情感分類,快速識別使用者情緒(如正面、負面、中性)。
智能客服:通過對話產生能力,為使用者提供自然語言互動的智能客服服務。
內容審核:自動檢測文本中的敏感內容或違規資訊,提升Alibaba Content Security Service審核效率。
embedding模型 embedding模型能夠將文本轉換為高維向量表示,適用於語義搜尋、推薦系統、知識圖譜構建等情境。
語義搜尋:通過對商品描述或使用者查詢進行向量化處理,實現基於語義的相關性搜尋。
推薦系統:利用文本向量化技術,挖掘使用者興趣與商品特徵之間的潛在關聯,提升推薦精準度。
知識圖譜:將非結構化文本轉化為向量形式,便於後續的知識抽取和關係建模。
前提條件
已開通Flink工作空間,詳情請參見開通Realtime ComputeFlink版。
已開通百鍊平台工作空間,並打通與Realtime Compute開發控制台的網路。通過VPC訪問百鍊,請參考私網訪問阿里雲百鍊模型或應用 API。
百鍊平台通過網域名稱的方式進行訪問,請參考管理網域名稱將開通的百鍊平台網域名稱註冊到Realtime Compute開發控制台。
使用限制
僅Realtime Compute引擎VVR 11.1及以上版本支援。
步驟一:註冊百鍊模型
請參見模型設定註冊百鍊模型。
chat/completions模型任務
以註冊通義千問qwen-turbo模型為例,SQL代碼如下:
CREATE MODEL ai_analyze_sentiment
INPUT (`input` STRING)
OUTPUT (`content` STRING)
WITH (
'provider'='bailian',
'endpoint'='<base_url>/compatible-mode/v1/chat/completions', -- chat/completions模型任務連接埠
'api-key' = '<YOUR KEY>',
'model'='qwen-turbo', -- 通義千問qwen-turbo模型
'system-prompt' = 'Classify the text below into one of the following labels: [positive, negative, neutral, mixed]. Output only the label.'
);根據業務需要,將endpoint參數值的<base_url>進行替換:
公網訪問百鍊:將
<base_url>替換為https://dashscope-intl.aliyuncs.com。VPC訪問百鍊:將
<base_url>替換為https://vpc-ap-southeast-1.dashscope.aliyuncs.com。說明endpoint僅支援HTTPS協議。
embedding模型任務
以註冊文本向量text-embedding-v3模型為例,SQL代碼如下:
CREATE MODEL embedding_model
INPUT (`input` STRING)
OUTPUT (`embeddings` ARRAY<FLOAT>)
WITH (
'provider'='bailian',
'endpoint'='https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings', -- embeddings模型任務連接埠
'api-key' = '<YOUR KEY>',
'model'='text-embedding-v3' -- 文本向量text-embedding-v3模型
);步驟二:建立作業
請參見Flink SQL作業建立SQL流作業草稿。
步驟三:編寫SQL作業進行AI大模型分析
chat/completions模型任務
使用AI函數通用調用調用登入的ai_analyze_sentiment模型,對電影評論進行情感分析。
ML_PREDICT語句相關的Flink運算元的輸送量受到百鍊平台限流的限制。當觸及百鍊平台允許的訪問資料傳輸量上限時,Flink作業會表現出以ML_PREDICT運算元為瓶頸的反壓現象。在限流情況嚴重時,可能會觸發相關運算元的逾時報錯及作業重啟。您可查詢百鍊平台限流瞭解不同模型的限流條件,或聯絡商務申請或PDSA瞭解如何解除限流。
拷貝如下樣本SQL到SQL編輯地區。
--建立臨時結果表
CREATE TEMPORARY TABLE print_sink(
id BIGINT,
movie_name VARCHAR,
predict_label VARCHAR,
actual_label VARCHAR
) WITH (
'connector' = 'print', -- print連接器
'logger' = 'true' -- 控制台顯示計算結果
);
-- 建立臨時資料檢視構造測試資料
-- | id | movie_name | comment | actual_label |
-- | 1 | 好東西 | 最愛小孩子猜聲音那段,算得上看過的電影裡相當浪漫的敘事了。很溫和也很有愛。| POSITIVE |
-- | 2 | 水餃皇后 | 乏善可陳 | NEGATIVE |
CREATE TEMPORARY VIEW movie_comment(id, movie_name, user_comment, actual_label)
AS VALUES (1, '好東西', '最愛小孩子猜聲音那段,算得上看過的電影裡相當浪漫的敘事了。很溫和也很有愛。', 'positive'), (2, '水餃皇后', '乏善可陳', 'negative');
INSERT INTO print_sink
SELECT id, movie_name, content as predict_label, actual_label
FROM ML_PREDICT(
TABLE movie_comment,
MODEL ai_analyze_sentiment, -- 註冊的通義千問qwen-turbo模型
DESCRIPTOR(user_comment)); embedding模型任務
使用AI函數通用調用調用登入的embedding_model模型,對電影評論進行情感分析,並將結果寫入Milvus(公測中)。
ML_PREDICT語句相關的Flink運算元的輸送量受到百鍊平台限流的限制。當觸及百鍊平台允許的訪問資料傳輸量上限時,Flink作業會表現出以ML_PREDICT運算元為瓶頸的反壓現象。在限流情況嚴重時,可能會觸發相關運算元的逾時報錯及作業重啟。您可查詢百鍊平台限流瞭解不同模型的限流條件,或聯絡商務申請或PDSA瞭解如何解除限流。
拷貝如下樣本SQL到SQL編輯地區。
-- 建立臨時結果表milvus_sink
CREATE TEMPORARY TABLE milvus_sink
(
id STRING,
movie_name STRING,
user_comment STRING,
embeddings ARRAY<FLOAT>,
PRIMARY KEY (id) NOT ENFORCED
)
WITH (
'connector' = 'milvus',
'endpoint' = '<YOUR-ENDPOINT>',
'port' = '<YOUR-PORT>',
'userName' = '<YOUR-USERNAME>',
'password' = '<YOUR-PASSWORD>',
'databaseName' = 'default',
'collectionName' = 'movie-comment-embeddings'
);
-- 建立臨時資料檢視構造測試資料
-- | id | movie_name | comment | actual_label|
-- | 1 | 好東西 |最愛小孩子猜聲音那段,算得上看過的電影裡相當浪漫的敘事了。很溫和也很有愛。| POSITIVE |
-- | 2 | 水餃皇后 | 乏善可陳 | NEGATIVE |
CREATE TEMPORARY VIEW movie_comment(id, movie_name, user_comment)
AS VALUES ('1', '好東西', '最愛小孩子猜聲音那段,算得上看過的電影裡相當浪漫的敘事了。很溫和也很有愛。'), ('2', '水餃皇后', '乏善可陳');
INSERT INTO
milvus_sink
SELECT
id,
movie_name,
user_comment,
embeddings
FROM
ML_PREDICT (
TABLE movie_comment,
MODEL embedding_model, -- 註冊的文本向量text-embedding-v3模型
DESCRIPTOR (user_comment)
);步驟四:作業部署並啟動
請參見Flink SQL作業部署作業並啟動。
步驟五:查看分析結果
chat/completions模型任務
查看目標作業狀態已完成。
在頁面,單擊目標作業名稱。
在作業日誌頁簽,選擇Task Managers頁簽下的當前TaskManager。
單擊日誌,在頁面搜尋PrintSinkOutputWriter相關的日誌資訊。
經模型分析後的結果
predict_label和實際結果actual_label一致。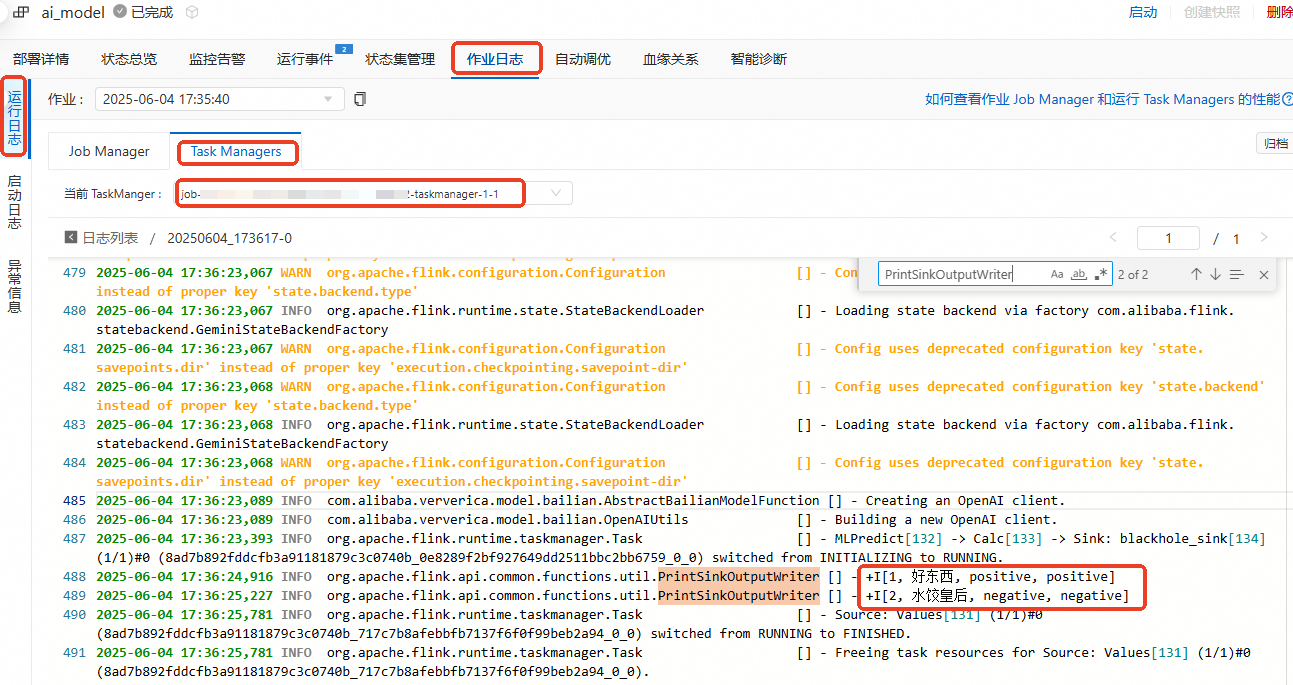
相關文檔
AI模型DDL資料定義語句請參見模型設定。
AI函數請參見通用調用。
向量檢索服務Milvus(公測中)。