隨著大語言模型技術的普及,企業對推理過程中的資料安全問題日益關注。本文將介紹如何基於阿里雲異構機密計算執行個體及Confidential AI方案(以下簡稱CAI),快速構建安全的大語言模型推理環境。
背景說明
阿里雲異構機密計算執行個體(gn8v-tee)在CPU TDX機密計算執行個體的基礎上,額外將GPU引入到TEE(Trusted Execution Environment)中,可以保護CPU和GPU之間的資料轉送及GPU中的資料計算。結合阿里雲KMS服務作為金鑰儲存區後端,並在ACK叢集內部署Trustee遠程證明服務,經過簡單配置後,您的推理服務無需修改即可無縫實現機密計算的安全推理保護。該方案旨在協助您在阿里雲上迅速構建安全的大語言模型推理環境,從而為您的業務提供支援。
方案架構
上述方案的整體架構如下圖所示。
操作步驟
步驟一:準備加密的模型資料
該步驟包括下載模型、加密模型和上傳模型三個環節。由於模型檔案較大,整個過程耗時較長。
如果您希望快速體驗此方案,可以使用我們為您準備的加密模型檔案進行試用。選擇我們已加密的模型檔案後,您將能夠跳過該步驟。直接進行步驟二:搭建Trustee遠程證明服務。點擊下方以擷取加密模型檔案資訊。
1.下載模型
在模型正式上雲部署之前,您需要先對模型進行加密,然後將其上傳到雲端儲存。解密模型的密鑰將由遠程證明服務控制的KMS(Key Management Service)負責託管。請在本地或可信環境中執行模型的加密操作。以部署Qwen2.5-3B-Instruct大模型為例,提供如下指導。
如果您已經擁有自己的模型,請跳過本章節,直接進入2.加密模型章節。
以使用modelscope工具下載Qwen2.5-3B-Instruct模型為例(需要 Python 3.9 或更高版本),在終端中執行如下命令下載模型。
pip3 install modelscope importlib-metadata
modelscope download --model Qwen/Qwen2.5-3B-Instruct成功執行命令後,模型將被下載到~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct/目錄下。
2.加密模型
目前支援如下兩種加密方式,本方案以Gocryptfs為例。
Gocryptfs:基於AES256-GCM,符合開源Gocryptfs標準的加密模式。
Sam:阿里雲可信AI模型加密格式,保護模型機密性和License內容不被篡改和非法使用。
執行Gocryptfs加密
安裝用於加密模型的工具Gocryptfs (目前只支援使用預設參數進行加密的Gocryptfs v2.4.0 版本)。您可以選擇以下任意一種方式進行安裝:
方式一:(推薦)從yum源安裝
如果您使用Alinux3或者AnolisOS 23作業系統,可以直接利用yum源安裝gocryptfs。
Alinux 3
sudo yum install gocryptfs -yAnolisOS 23
sudo yum install anolis-epao-release -y sudo yum install gocryptfs -y方式二:直接下載先行編譯binary
# 下載先行編譯Gocryptfs壓縮包 wget https://github.jobcher.com/gh/https://github.com/rfjakob/gocryptfs/releases/download/v2.4.0/gocryptfs_v2.4.0_linux-static_amd64.tar.gz # 解壓並安裝 tar xf gocryptfs_v2.4.0_linux-static_amd64.tar.gz sudo install -m 0755 ./gocryptfs /usr/local/bin建立Gocryptfs密鑰檔案,作為模型加密的密鑰。在後續步驟中,您需要將該密鑰上傳到遠程證明服務(Trustee)進行託管。
在本方案中,使用
0Bn4Q1wwY9fN3P作為加密模型使用的密鑰,金鑰產製原料將儲存在cachefs-password檔案中。您也可以自訂密鑰。在實際中,建議使用隨機產生的強密鑰。cat << EOF > ~/cachefs-password 0Bn4Q1wwY9fN3P EOF使用已建立的金鑰組模型進行加密。
配置明文模型的路徑。
說明在此處配置您剛才下載的明文模型所在路徑,如果您有其他模型,請將其替換為目標模型的實際路徑。
PLAINTEXT_MODEL_PATH=~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct/使用Gocryptfs對模型分類樹進行加密。
加密完成後,模型將以密文形式儲存在
./cipher目錄中。mkdir -p ~/mount cd ~/mount mkdir -p cipher plain # 安裝Gocryptfs運行時依賴 sudo yum install -y fuse # initialize gocryptfs cat ~/cachefs-password | gocryptfs -init cipher # mount to plain cat ~/cachefs-password | gocryptfs cipher plain # move AI model to ~/mount/plain cp -r ${PLAINTEXT_MODEL_PATH}/. ~/mount/plain
執行Sam加密
單擊下載Sam加密模組壓縮包RAI_SAM_SDK_2.1.0-20240731.tgz,然後執行以下命令解壓壓縮包。
# 解壓Sam加密模組 tar xvf RAI_SAM_SDK_2.1.0-20240731.tgz使用Sam加密模組加密模型。
# 進入Sam加密模組的加密目錄 cd RAI_SAM_SDK_2.1.0-20240731/tools # 加密模型 ./do_content_packager.sh <模型目錄> <清除金鑰> <密鑰ID>其中:
<模型目錄>:待加密模型所在的目錄,可以使用相對路徑或絕對路徑,例如
~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct/。<清除金鑰>:自訂的加密金鑰,有效長度為4 ~ 128位元組,例如
0Bn4Q1wwY9fN3P。清除金鑰是需要上傳到遠程證明服務(Trustee)的模型解密密鑰。<密鑰ID>:自訂的密鑰標識,有效長度為8 ~ 48位元組,例如
LD_Demo_0001。
加密結束後,模型將以密文形式儲存在當前路徑的
<密鑰ID>目錄中。
3.上傳模型
您需要準備一個與即將部署的異構執行個體相同地區的OSS Bucket,並將加密模型上傳到阿里雲OSSObject Storage Service,以便後續從異構執行個體拉取並部署。
以Object Storage Service為例,參考控制台快速入門建立一個儲存空間(Bucket)和一個名為qwen-encrypted的目錄(例如oss://examplebucket/qwen-encrypted/)。因模型檔案較大,推薦使用ossbrowser將加密模型上傳到該目錄。
步驟二:搭建Trustee遠程證明服務
遠程證明服務是由使用者管理的驗證服務,負責對模型及推理服務的運行環境進行驗證。僅在確認異構模型部署環境的可信度符合預期條件時,才會注入模型解密密鑰以實現模型的解密掛載。
您可以使用阿里雲ACK Serverless部署遠程證明服務,以驗證模型部署環境和推理環境。同時,藉助阿里雲KMS為模型解密密鑰提供專業的安全保障。具體操作步驟如下:
ACK叢集的地區不必與異構部署服務的目標地區相同。
阿里雲KMS執行個體必須和準備部署的阿里雲Trustee遠程證明服務所在的ACK叢集處於相同地區。
在建立KMS執行個體和ACK叢集之前,請先建立專用網路和2個交換器。具體操作,請參見建立和管理專用網路。
1.建立一台阿里雲KMS執行個體作為金鑰儲存區後端
前往Key Management Service控制台,在左側導覽列選擇,然後在軟體密鑰管理頁簽建立並啟動執行個體。在啟動執行個體時,請選擇與ACK叢集相同的專用網路。具體操作,請參見購買和啟用KMS執行個體。
等待大約10分鐘,即可啟動完畢。
執行個體啟動完成後,在左側導覽列選擇,然後在密鑰管理頁面為該執行個體建立一個使用者主要金鑰。具體操作,請參見步驟一:建立軟體密鑰。
在左側導覽列選擇,然後在存取點頁面為該執行個體建立應用存取點。其中範圍選擇已建立的KMS執行個體。更多配置說明,請參見方式一:快速建立。
應用存取點建立成功後,瀏覽器會自動下載ClientKey***.zip檔案,該zip檔案解壓後包含:
應用身份憑證內容(ClientKeyContent):檔案名稱預設為
clientKey_****.json。憑證口令(ClientKeyPassword):檔案名稱預設為
clientKey_****_Password.txt。
在頁面,單擊KMS執行個體名稱,然後在基礎資訊地區,單擊執行個體CA認證後的下載,匯出KMS執行個體的密鑰憑證檔案
PrivateKmsCA_***.pem。
2.建立ACK服務叢集並安裝csi-provisioner組件
前往建立叢集頁面,建立ACK Serverless叢集,其中關鍵參數配置說明如下,更多配置說明,請參見建立叢集。
叢集配置:配置以下參數,完成後單擊下一步:組件配置。
關鍵配置
描述
專用網路
選擇使用已有,並勾選為專用網路配置SNAT,否則無法拉取Trustee鏡像。
交換器
請確保在已有專用網路中建立至少兩個虛擬交換器,否則無法暴露公網ALB。
組件配置:配置以下參數,完成後單擊下一步:確認配置。
關鍵配置
描述
服務發現
選擇CoreNDS。
Ingress
選擇ALB Ingress,ALB雲原生網關執行個體來源選擇建立,並選擇兩個虛擬交換器。
確認配置:確認配置資訊和使用須知,然後單擊建立叢集。
叢集建立成功後,安裝csi-provisioner(託管)組件。具體操作,請參見管理組件。
3.在ACK叢集中部署Trustee遠程證明服務
首先通過公網或內網串連叢集。具體操作,請參見串連叢集。
將已下載的KMS執行個體的應用身份憑證(
clientKey_****.json)、憑證口令(clientKey_****_Password.txt)和CA認證(PrivateKmsCA_***.pem),上傳到串連ACK Serverless叢集的環境中,並執行以下命令部署Trustee遠程證明服務,使用阿里雲KMS作為金鑰儲存區後端。# 安裝外掛程式 helm plugin install https://github.com/AliyunContainerService/helm-acr helm repo add trustee acr://trustee-chart.cn-hangzhou.cr.aliyuncs.com/trustee/trustee helm repo update export DEPLOY_RELEASE_NAME=trustee export DEPLOY_NAMESPACE=default export TRUSTEE_CHART_VERSION=1.0.0 # 設定ACK叢集所在的地區資訊,比如cn-hangzhou export REGION_ID=cn-hangzhou # 剛才匯出的KMS執行個體相關資訊 # 替換為您的KMS執行個體ID export KMS_INSTANCE_ID=kst-hzz66a0*******e16pckc # 替換為您的KMS執行個體應用身份憑證所在路徑 export KMS_CLIENT_KEY_FILE=/path/to/clientKey_KAAP.***.json # 替換為您的KMS執行個體憑證口令所在路徑 export KMS_PASSWORD_FILE=/path/to/clientKey_KAAP.***_Password.txt # 替換為您的KMS執行個體CA認證所在路徑 export KMS_CERT_FILE=/path/to/PrivateKmsCA_kst-***.pem helm install ${DEPLOY_RELEASE_NAME} trustee/trustee \ --version ${TRUSTEE_CHART_VERSION} \ --set regionId=${REGION_ID} \ --set kbs.aliyunKms.enabled=true \ --set kbs.aliyunKms.kmsIntanceId=${KMS_INSTANCE_ID} \ --set-file kbs.aliyunKms.clientKey=${KMS_CLIENT_KEY_FILE} \ --set-file kbs.aliyunKms.password=${KMS_PASSWORD_FILE} \ --set-file kbs.aliyunKms.certPem=${KMS_CERT_FILE} \ --namespace ${DEPLOY_NAMESPACE}說明執行代碼中第一條安裝外掛程式命令(
helm plugin install...)可能需要較長時間。如果安裝失敗,可以先通過helm plugin uninstall cm-push命令卸載該外掛程式,然後重新執行外掛程式安裝命令。返回結果樣本為:
NAME: trustee LAST DEPLOYED: Tue Feb 25 18:55:33 2025 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None在串連ACK Serverless叢集的環境中執行如下命令,來擷取Trustee的訪問地址。
export TRUSTEE_URL=http://$(kubectl get AlbConfig alb -o jsonpath='{.status.loadBalancer.dnsname}')/${DEPLOY_RELEASE_NAME} echo ${TRUSTEE_URL}返回結果樣本為
http://alb-ppams74szbwg2f****.cn-shanghai.alb.aliyuncsslb.com/trustee。在串連ACK Serverless叢集的環境中執行以下命令,測試Trustee服務的連通性。
cat << EOF | curl -k -X POST ${TRUSTEE_URL}/kbs/v0/auth -H 'Content-Type: application/json' -d @- { "version":"0.1.0", "tee": "tdx", "extra-params": "foo" } EOF若Trustee服務運行狀態正常,預期輸出如下:
{"nonce":"PIDUjUxQdBMIXz***********IEysXFfUKgSwk=","extra-params":""}
4.建立憑據來儲存模型解密密鑰
Trustee託管的模型解密密鑰實際上儲存在KMS中,只有在遠程證明服務驗證目標環境後,密鑰才能被訪問。
前往Key Management Service控制台,在左側導覽列選擇,然後在通用憑據頁簽,單擊建立憑據。其中關鍵配置說明如下:
憑據名稱:自訂憑據名稱,用於索引該密鑰,例如
model-decryption-key。設定憑據值:填寫加密模型時使用的密鑰。例如
0Bn4Q1wwY9fN3P,您的密鑰以實際為準。加密主要金鑰:選擇上述步驟建立的主要金鑰。
步驟三:建立異構機密計算執行個體
在控制台建立具備異構機密計算特性的執行個體步驟與建立普通執行個體類似,但需要注意一些特定選項。以下步驟將為您詳細介紹如何使用包含異構機密計算環境和CAI環境的雲市場鏡像,建立異構機密計算執行個體。關於異構機密計算環境的更多資訊,請參見構建異構機密計算環境。
前往執行個體購買頁。
選擇自訂購買頁簽。
選擇付費類型、地區、執行個體規格、鏡像等配置。
各配置項詳細說明如下:
配置項名稱
配置項說明
執行個體規格類型系列
必須選擇gn8v-tee執行個體規格類型系列中的如下兩種規格之一:
ecs.gn8v-tee.4xlarge
ecs.gn8v-tee.6xlarge
鏡像
單擊雲市場鏡像頁簽,輸入
Confidential AI進行搜尋,選擇Alibaba Cloud Linux 3.2104 LTS 64位單卡Confidential AI鏡像。說明關於該鏡像的更多資訊,請參見Alibaba Cloud Linux 3.2104 LTS 64位單卡Confidential AI鏡像。您可以在鏡像介紹頁面完成異構機密計算執行個體的建立。
系統硬碟
系統硬碟容量建議選擇不低於1 TiB,具體大小應根據您需要啟動並執行模型檔案大小進行合理評估。一般建議容量大於模型大小的兩倍。請您根據實際情況進行設定。
在最終建立執行個體前,請在頁面右側檢查執行個體的整體配置並配置使用時間長度等選項,確保符合您的要求。
閱讀並簽署《Elastic Compute Service服務條款》等服務合約(若已簽署,則無需重複簽署,請以頁面提示為準),然後單擊確認下單。
在執行個體建立過程中,請您耐心等待。您可前往控制台的執行個體列表頁面查看執行個體的狀態,當執行個體狀態變為運行中時,表示執行個體建立完成。
步驟四:配置異構執行個體對OSS和Trustee的存取權限
1.配置異構執行個體對OSS的存取權限
在部署過程中,執行個體需要訪問儲存模型密文的OSS bucket,並訪問Trustee獲得模型解密密鑰,因此需要配置執行個體對相關OSS和Trustee的存取權限。
登入OSS管理主控台。
單擊Bucket 列表,然後單擊目標Bucket名稱。
在左側導覽列,選擇。
在Bucket 授權策略頁簽,單擊新增授權,在新增授權頁面中,為異構機密計算執行個體的公網IP增加
Bucket授權。單擊確定。
2.配置執行個體對Trustee的存取權限
前往阿里雲ALB負載平衡控制台,建立存取控制策略組,並將訪問Trustee許可權的地址/位址區段添加為IP條目。具體操作,請參見存取控制。
其中,需要添加的地址或位址區段如下:
部署異構服務時綁定的專用網路的公網IP地址。
推理用戶端的出口IP地址。
使用如下命令獲得叢集上Trustee執行個體使用的ALBServer Load Balancer執行個體ID。
kubectl get ing --namespace ${DEPLOY_NAMESPACE} kbs-ingress -o jsonpath='{.status.loadBalancer.ingress[0].hostname}' | cut -d'.' -f1 | sed 's/[^a-zA-Z0-9-]//g'預期輸出如下結果:
alb-llcdzbw0qivhk0****在阿里雲ALB負載平衡控制台左側導覽列,選擇,在叢集所在地區下搜尋上一步獲得的ALB執行個體,並單擊執行個體ID進入執行個體詳情頁面。然後在頁面最下方執行個體屬性地區,單擊關閉配置修改保護。
切換到監聽頁面,單擊目標監聽執行個體存取控制列下的啟用,並配置白名單為上述步驟建立的存取控制策略組。
步驟五:在異構機密計算執行個體中部署vLLM大模型推理服務
在異構機密計算執行個體中部署vLLM大模型推理服務,您可以通過docker或者docker compose兩種方式來完成部署。具體操作步驟如下:
1.準備設定檔
遠端連線異構執行個體,具體操作,請參見使用Workbench登入Linux執行個體。
運行如下命令,以開啟
~/cai.env設定檔。vi ~/cai.env按
i鍵進入插入模式,將準備好的配置資訊粘貼到設定檔中。# 模型解密相關配置 TRUSTEE_URL="http://alb-xxxxxxxxx.cn-beijing.alb.aliyuncsslb.com/xxxx/" # Trustee服務url MODEL_KEY_ID="kbs:///default/aliyun/model-decryption-key" # Trustee上配置的模型解密金鑰組應的resource id。例如憑據名稱model-decryption-key對應的id是kbs:///default/aliyun/model-decryption-key # 加密模型分發相關配置 MODEL_OSS_BUCKET_PATH="<bucket-name>:<model-path>" # 存放在阿里雲OSS上的模型密文路徑,例如conf-ai:/qwen3-32b-gocryptfs/ MODEL_OSS_ENDPOINT="https://oss-cn-beijing-internal.aliyuncs.com" # 存放模型密文的OSS URL # MODEL_OSS_ACCESS_KEY_ID="" # 用於訪問OSS bucket的access key # MODEL_OSS_SECRET_ACCESS_KEY="" # 用於訪問OSS bucket的access key secret # MODEL_OSS_SESSION_TOKEN="" # 用於訪問OSS bucket的session token,僅在通過STS憑據訪問OSS時需要 MODEL_ENCRYPTION_METHOD="gocryptfs" # 加密模式使用的加密方法,取值為"gocryptfs"或"sam",預設值為"gocryptfs" MODEL_MOUNT_POINT=/tmp/model # 解密後模型明文的掛載位置,模型推理服務可以從該路徑載入模型 # 大模型服務通訊加密相關配置 MODEL_SERVICE_PORT=8080 # 業務使用的TCP連接埠號碼,該連接埠上的通訊將被透明加密保護 # 模型P2P分發加速相關配置,預設可忽略 TRUSTEE_POLICY="default" # MODEL_SHARING_PEER="172.30.24.146 172.30.24.144"輸入
:wq並按下斷行符號鍵,儲存並退出編輯器。
2.部署推理服務
通過docker部署推理服務
使用設定檔啟動CAI服務
您需要通過上一步中配置的檔案,啟動CAI服務,用於完成對加密模型的解密。這將會在host環境中
MODEL_MOUNT_POINT指定的路徑/tmp/model處掛載解密後的明文模型資料,您的推理服務程式(如vLLM)可以從該路徑載入模型。運行如下命令,以啟動CAI服務。
cd ~ docker compose -f /opt/alibaba/cai-docker/docker-compose.yml --env-file ./cai.env up -d --wait回顯結果樣本如下,說明CAI服務啟動成功。
[+] Running 5/5 ✔ Container cai-docker-oss-1 Healthy 44.7s ✔ Container cai-docker-attestation-agent-1 Healthy 44.7s ✔ Container cai-docker-tng-1 Healthy 44.7s ✔ Container cai-docker-confidential-data-hub-1 Healthy 44.7s ✔ Container cai-docker-cachefs-1 Healthy查看解密後的模型檔案
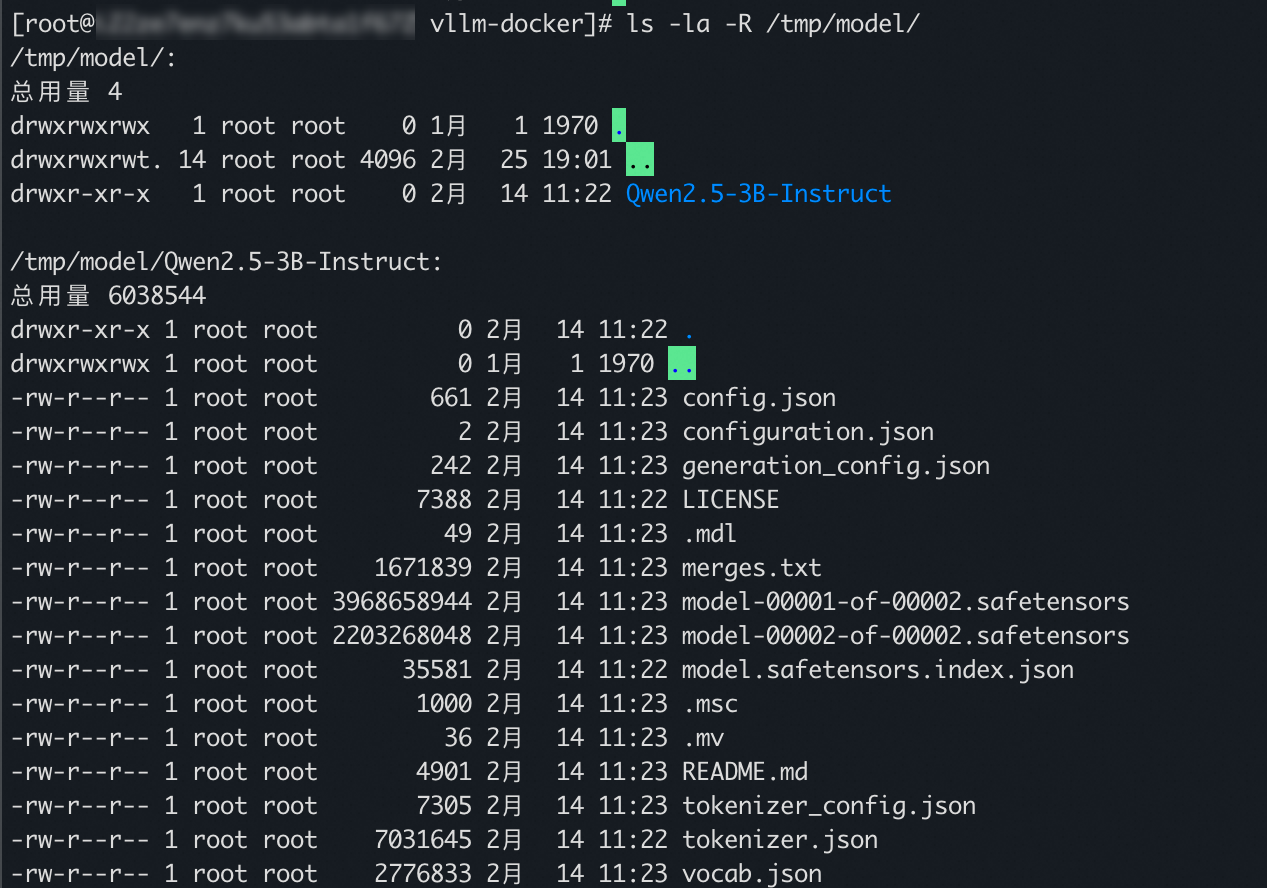
如需查看解密後的模型檔案,您可以運行如下命令。
ls -la -R /tmp/model回顯結果樣本如下,說明模型檔案解密成功。
運行如下命令,啟動vLLM推理服務。
docker run --rm \ --net host \ -v /tmp/model:/tmp/model \ --gpus all \ egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.8.5-pytorch2.6-cu124-20250429 \ python3 -m vllm.entrypoints.openai.api_server --model=/tmp/model --trust-remote-code --port 8080 --served-model-name Qwen3-32B回顯資訊樣本如下,說明推理服務啟動成功。
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s] Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:01<00:01, 1.07s/it] Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.21it/s] Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.16it/s] INFO 03-04 07:49:06 model_runner.py:732] Loading model weights took 5.7915 GB INFO 03-04 07:49:08 gpu_executor.py:102] # GPU blocks: 139032, # CPU blocks: 7281 INFO 03-04 07:49:08 model_runner.py:1024] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. INFO 03-04 07:49:08 model_runner.py:1028] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage. INFO 03-04 07:49:18 model_runner.py:1225] Graph capturing finished in 9 secs. WARNING 03-04 07:49:18 serving_embedding.py:171] embedding_mode is False. Embedding API will not work. INFO 03-04 07:49:18 launcher.py:14] Available routes are: INFO 03-04 07:49:18 launcher.py:22] Route: /openapi.json, Methods: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Route: /docs, Methods: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Route: /docs/oauth2-redirect, Methods: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Route: /redoc, Methods: HEAD, GET INFO 03-04 07:49:18 launcher.py:22] Route: /health, Methods: GET INFO 03-04 07:49:18 launcher.py:22] Route: /tokenize, Methods: POST INFO 03-04 07:49:18 launcher.py:22] Route: /detokenize, Methods: POST INFO 03-04 07:49:18 launcher.py:22] Route: /v1/models, Methods: GET INFO 03-04 07:49:18 launcher.py:22] Route: /version, Methods: GET INFO 03-04 07:49:18 launcher.py:22] Route: /v1/chat/completions, Methods: POST INFO 03-04 07:49:18 launcher.py:22] Route: /v1/completions, Methods: POST INFO 03-04 07:49:18 launcher.py:22] Route: /v1/embeddings, Methods: POST INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
通過docker compose部署推理服務
準備docker-compose.yml檔案。
運行如下命令,開啟docker-compose.yml檔案。
vi ~/docker-compose.yml按
i鍵進入插入模式,粘貼如下內容到docker-compose.yml檔案中。include: - path: /opt/alibaba/cai-docker/docker-compose.yml env_file: ./cai.env services: inference: image: egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/llm-inference:vllm0.5.4-deepgpu-llm24.7-pytorch2.4.0-cuda12.4-ubuntu22.04 volumes: - /tmp/model:/tmp/model:shared deploy: resources: reservations: devices: - driver: nvidia count: all capabilities: [gpu] network_mode: host init: true command: "python3 -m vllm.entrypoints.openai.api_server --model=/tmp/model/ --trust-remote-code --port 8080" depends_on: cachefs: condition: service_healthy restart: true按
:wq鍵後按斷行符號鍵,儲存並退出編輯器。重要如果您打算修改docker-compose.yml來部署本文所介紹其他負載,您需要注意如下額外調整:
使用
include語句引入鏡像中預裝的CAI docker-compose.yml檔案,且使用env_file指定CAI設定檔路徑。您需要為vLLM服務容器添加
depends_on條件,確保其在cachefs容器之後啟動。解密後的模型目錄將被掛載到host環境中
MODEL_MOUNT_POINT指定的路徑,因此需對vLLM服務容器添加對應的volumes條目,從而將模型目錄共用到推理服務容器內
運行vLLM推理服務
運行如下命令,以運行vLLM推理服務。
docker compose up -d回顯結果樣本如下,說明推理服務啟動成功。
[+] Running 6/6 ✔ Container root-attestation-agent-1 Healthy 3.6s ✔ Container root-oss-1 Healthy 10.2s ✔ Container root-tng-1 Healthy 44.2s ✔ Container root-confidential-data-hub-1 Healthy 34.2s ✔ Container root-cachefs-1 Healthy 54.7s ✔ Container root-inference-1 Started
步驟六:訪問異構機密計算執行個體中的推理服務
為了訪問機密計算執行個體中的推理服務,您需要準備一個用戶端環境,並安裝可信網關用戶端(Trusted Network Gateway)。下面示範將一台普通的ECS執行個體作為用戶端,訪問異構執行個體中部署的vLLM推理服務的步驟。
1.配置用戶端環境對異構機密計算執行個體和Trustee的存取權限
本文中,用戶端環境需通過異構機密計算執行個體的公網IP來訪問執行個體中部署的推理服務,因此必須為異構機密計算執行個體所在的安全性群組添加用戶端的允許存取規則,以允許用戶端環境訪問異構機密計算執行個體。同時,在與服務端建立安全通道的過程中,需依賴Trustee對異構機密計算執行個體進行遠程證明。因此,還需在Trustee的存取控制中添加用戶端環境的公網IP地址。具體操作如下。
為異構機密計算執行個體所屬安全性群組添加用戶端的允許存取規則。具體操作,請參見管理安全性群組規則。
在Trustee的存取控制中添加用戶端環境的公網IP地址。
因為在步驟四:配置異構執行個體對OSS和Trustee的存取權限中已經建立了存取控制策略組並加入了白名單,所以此時不需要建立存取控制策略組,只需將用戶端公網IP加入存取控制策略組中即可。
2.為用戶端執行個體部署可信網關用戶端
可信網關 (Trusted Network Gateway,TNG) 是針對機密計算情境設計的網路組件。它可作為一個守護進程,負責建立安全通訊通道,對進出機密執行個體的網路流量請求進行透明加解密,實現端到端的資料安全。此外,它允許您在無需修改已有應用程式的同時,根據自己的需求靈活地控制流程量的加密和解密過程。
部署可信網關用戶端。
通過docker部署
在用戶端執行個體中安裝Docker,具體操作,請參見安裝並使用Docker和Docker Compose。
運行如下命令,使用Docker部署可信網關用戶端。
重要注意:使用者需要根據前面部署的Trustee服務,對應修改
as_addr欄位的值為${trsutee_url}/as/。docker run --rm \ --network=host \ confidential-ai-registry.cn-shanghai.cr.aliyuncs.com/product/tng:2.2.1 \ tng launch --config-content ' { "add_ingress": [ { "http_proxy": { "proxy_listen": { "host": "127.0.0.1", "port": 41000 } }, "verify": { "as_addr": "http://alb-xxxxxxxxxxxxxxxxxx.cn-shanghai.alb.aliyuncsslb.com/cai-test/as/", "policy_ids": [ "default" ] } } ] } '
通過二進位檔案部署
訪問TNG · GitHub,以擷取適配用戶端執行個體架構的二進位安裝包下載地址。
運行如下命令,下載可信網關用戶端二進位檔案,下述樣本以
tng-v2.2.1.x86_64-unknown-linux-gnu.tar.gz為例,請按照實際情況進行替換。wget https://github.com/inclavare-containers/TNG/releases/download/v2.2.1/tng-v2.2.1.x86_64-unknown-linux-gnu.tar.gz運行如下命令,解壓下載的二進位壓縮檔並為其添加可執行許可權。
tar -zxvf tng-v2.2.1.x86_64-unknown-linux-gnu.tar.gz chmod +x tng運行如下命令,運行可信網關用戶端。
重要注意:使用者需要根據前面部署的Trustee服務,對應修改
as_addr欄位的值為${trsutee_url}/as/。./tng launch --config-content ' { "add_ingress": [ { "http_proxy": { "proxy_listen": { "host": "127.0.0.1", "port": 41000 } }, "verify": { "as_addr": "http://alb-xxxxxxxxxxxxxxxxxx.cn-shanghai.alb.aliyuncsslb.com/cai-test/as/", "policy_ids": [ "default" ] } } ] } '
3.為用戶端執行個體上的進程配置HTTP代理服務
部署成功後,可信網關用戶端將保持在前台運行,並在 127.0.0.1:41000 上建立了一個基於HTTP CONNECT協議的HTTP代理服務。將應用程式接入該代理,流量將被可信網關用戶端加密處理並通過可信通道發送給vLLM服務。
您可以通過如下兩種方式為用戶端執行個體上的進程配置HTTP代理服務。
按照協議類型配置代理
export http_proxy=http://127.0.0.1:41000
export https_proxy=http://127.0.0.1:41000
export ftp_proxy=http://127.0.0.1:41000
export rsync_proxy=http://127.0.0.1:41000為所有協議配置代理
export all_proxy=http://127.0.0.1:410004.通過用戶端執行個體訪問推理服務
通過在用戶端環境中運行curl命令訪問異構機密計算執行個體中的推理服務。
為用戶端執行個體重新開啟一個終端視窗。
運行如下命令,訪問推理服務。
說明您需要將下述命令中的
<異構機密計算執行個體公網IP>替換為步驟三:建立異構機密計算執行個體中建立的異構機密計算執行個體公網IP。下述命令在執行
curl命令之前設定了環境變數all_proxy='http://127.0.0.1:41000/',從而使得curl命令發出的請求能夠通過可信網關用戶端進行加密,並通過安全通道發送。
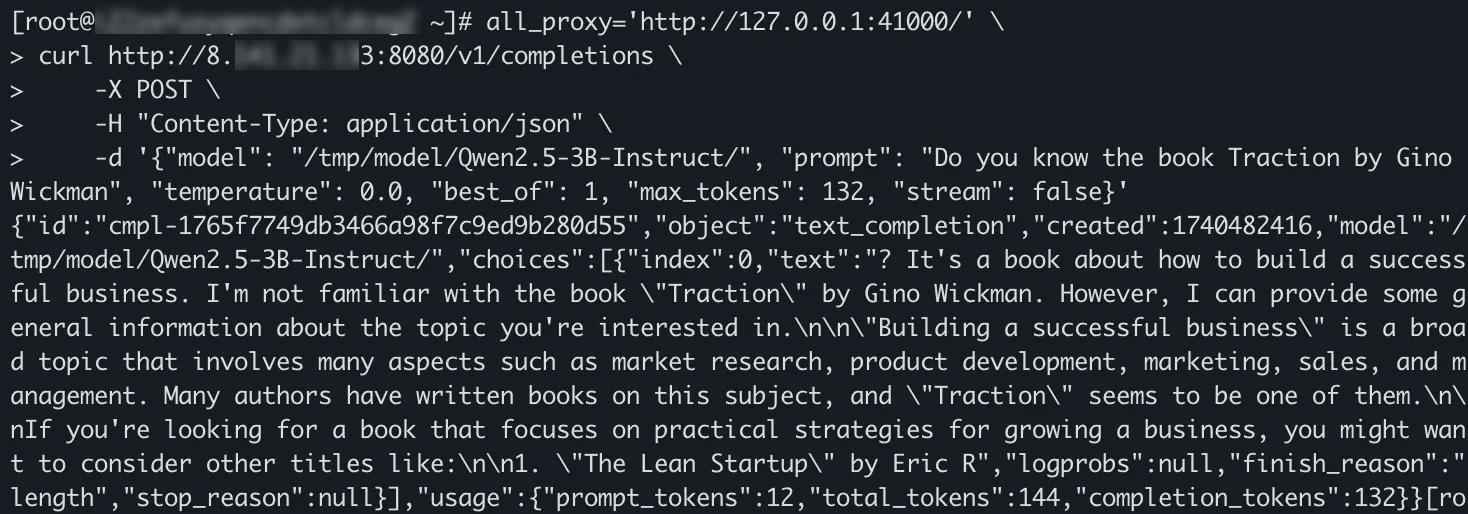
env all_proxy='http://127.0.0.1:41000/' \ curl http://<異構機密計算執行個體公網IP>:8080/v1/completions \ -X POST \ -H "Content-Type: application/json" \ -d '{"model": "Qwen3-32B", "prompt": "Do you know the book Traction by Gino Wickman", "temperature": 0.0, "best_of": 1, "max_tokens": 132, "stream": false}'回顯結果樣本如下,表示用戶端通過curl命令發出的請求能夠被可信網關用戶端加密,再通過安全通道發送。最終成功訪問異構中部署的大模型服務。
常見問題
啟動CAI服務時,cai-docker-oss容器啟動失敗。
問題現象:啟動CAI服務時,cai-docker-oss容器啟動失敗。

問題原因:此問題通常是因為該異構執行個體無法訪問模型密文所在的OSS。
解決方案:請檢查OSS存取控制策略是否配置正確。
啟動CAI服務時,cai-docker-confidential-data-hub容器啟動失敗。
問題現象:啟動CAI服務時,cai-docker-confidential-data-hub容器啟動失敗。

問題原因:此報錯說明在擷取模型解密密鑰時出現問題,通常是因為該異構執行個體無法正常訪問Trustee執行個體,或者配置的密鑰不存在。
解決方案:可以參考如下步驟進行問題排查。
檢查您在
cai.env中配置的密鑰ID是否正確,並重新部署。檢查
cai.env中的Trustee執行個體的URL是否配置正確,檢查Trustee執行個體存取控制策略是否配置正確。
啟動CAI服務時,cai-docker-tng容器啟動失敗。
啟動CAI服務時,cai-docker-cachefs容器啟動失敗。
問題現象:啟動CAI服務時,cai-docker-cachefs容器啟動失敗。

問題原因:通常是因為模型解密失敗。
解決方案:可以參考如下步驟進行問題排查。
檢查是否在Trustee的KMS後端中上傳了正確的密碼憑據。
檢查
cai.env中配置的MODEL_ENCRYPTION_METHOD欄位的值是否與模型加密時使用的加密方法匹配。
啟動CAI服務時報錯後,如何使用工具收集錯誤資訊。
相關文檔
關於如何構建異構機密計算環境,請參見構建異構機密計算環境。