本文介紹如何在阿里雲異構機密計算執行個體(gn8v-tee)中構建異構機密計算環境,並示範如何運行範例程式碼以驗證GPU機密計算功能。
背景資訊
阿里雲異構機密計算執行個體(gn8v-tee)在CPU TDX機密計算執行個體的基礎上,額外將GPU引入到TEE(Trusted Execution Environment)中,可以保護CPU和GPU之間的資料轉送及GPU中的資料計算。本文重點介紹GPU機密計算相關的功能驗證,關於CPU TDX機密計算環境的構建及其遠程證明能力驗證,請參見構建TDX機密計算環境。如您希望在異構機密計算執行個體中部署大語言模型推理環境,請參見基於異構機密計算執行個體構建支援安全度量的大語言模型推理環境。
如上圖所示,在異構機密計算執行個體上,GPU以機密計算模式啟動,機密計算執行個體的機密性由以下幾點來保證:
-
TDX特性保證Hypervisor/Host OS無法訪問執行個體的敏感寄存器資訊以及執行個體的記憶體資料。
-
PCIe防火牆可以阻止CPU訪問GPU的關鍵寄存器和GPU中受保護的顯存,Hypervisor/Host OS對GPU只能執行有限的訪問和操作(比如重設GPU),而無法訪問GPU中的敏感性資料,保證了GPU中資料的機密性。
-
GPU的NVLink Firewall阻止其他GPU直接存取GPU的顯存。
-
CPU TEE中的GPU驅動以及庫函數,初始化時會通過SPDM(Security Protocol and Data Model)協議與GPU建立加密通道。密鑰協商完成後,CPU與GPU間僅通過PCIe傳輸密文形態資料,保證了CPU與GPU之間的資料轉送鏈路的機密性。
-
通過GPU的遠程證明能力確認GPU是否處於安全狀態。
具體而言,機密計算執行個體中的應用可以通過Attestation SDK調用GPU驅動,從GPU硬體擷取其安全狀態的密碼學報告。該報告中包含由密碼學簽名的GPU硬體資訊、VBIOS及硬體狀態度量值。依賴方(Relying party)可以通過將擷取到的度量值與GPU廠商提供的參考度量值進行比對,以確認GPU是否處於機密計算的安全狀態。
適用範圍
異構機密計算僅支援Alibaba Cloud Linux 3鏡像。若使用基於Alibaba Cloud Linux 3構建的自訂鏡像建立執行個體,請確保其核心版本不低於5.10.134-18。
建立異構機密計算執行個體(gn8v-tee)
通過控制台建立
在控制台建立具備異構機密計算特性的執行個體步驟與建立普通執行個體類似,但需要注意一些特定選項。本步驟重點介紹異構機密計算執行個體相關的特定配置,如果您想瞭解其他通用配置,請參見自訂購買執行個體。
訪問ECS控制台-執行個體。
在頁面左側頂部,選擇目標資源所在的資源群組和地區。

-
單擊建立執行個體,按照以下配置建立對應執行個體。
配置項
說明
地區與可用性區域
華北2(北京)可用性區域L
執行個體規格
僅支援ecs.gn8v-tee.4xlarge及以上執行個體規格。
鏡像
選擇Alibaba Cloud Linux 3.2104 LTS 64位鏡像。
公網IP
分配公網IPv4地址。保證後續可以從NVIDIA官網下載驅動程式。
重要建立8 GPU卡機密執行個體時,請勿添加額外的輔助彈性網卡,此操作可能導致執行個體啟動失敗。
-
根據介面提示,完成建立執行個體。
通過OpenAPI或阿里雲CLI建立
您可以調用RunInstances或阿里雲CLI建立支援TDX安全特性的ECS執行個體,需要注意的參數如下表所示。
|
參數 |
說明 |
樣本 |
|
RegionId |
華北2(北京) |
cn-beijing |
|
ZoneId |
可用性區域L |
cn-beijing-l |
|
InstanceType |
選擇ecs.gn8v-tee.4xlarge及以上執行個體規格 |
ecs.gn8v-tee.4xlarge |
|
ImageId |
指定支援異構機密的鏡像ID,當前僅核心版本大於等於5.10.134-18.al8.x86_64的Alibaba Cloud Linux 3.2104 LTS 64位鏡像支援。 |
aliyun_3_x64_20G_alibase_20250117.vhd |
CLI樣本:
命令中<SECURITY_GROUP_ID>為安全性群組ID、<VSWITCH_ID>為交換器ID、<KEY_PAIR_NAME>為SSH金鑰組名稱。
aliyun ecs RunInstances \
--RegionId cn-beijing \
--ZoneId cn-beijing-l \
--SystemDisk.Category cloud_essd \
--ImageId 'aliyun_3_x64_20G_alibase_20250117.vhd' \
--InstanceType 'ecs.gn8v-tee.4xlarge' \
--SecurityGroupId '<SECURITY_GROUP_ID>' \
--VSwitchId '<VSWITCH_ID>' \
--KeyPairName <KEY_PAIR_NAME>構建異構機密計算環境
步驟一:安裝NVIDIA驅動和CUDA工具包
異構機密計算執行個體初始化較慢,當執行個體狀態為執行中,並且執行個體作業系統啟動完成以後再執行以下操作。
不同執行個體規格的安裝步驟有所不同:
-
單GPU卡機密執行個體:ecs.gn8v-tee.4xlarge和ecs.gn8v-tee.6xlarge規格
-
8 GPU卡機密執行個體:ecs.gn8v-tee-8x.16xlarge和ecs.gn8v-tee-8x.48xlarge規格
單GPU卡機密執行個體
-
遠端連線機密計算執行個體。
具體操作,請參見使用Workbench登入Linux執行個體。
-
調整核心參數,設定SWIOTLB buffer為8GB。
sudo grubby --update-kernel=ALL --args="swiotlb=4194304,any" -
重啟執行個體,使以上配置生效。
具體操作,請參見重啟執行個體。
-
下載NVIDIA驅動和CUDA工具包。
單GPU卡機密執行個體需使用
550.144.03(或更高)版本的驅動,本文以550.144.03版本為例。wget --referer=https://www.nvidia.cn/ https://cn.download.nvidia.cn/tesla/550.144.03/NVIDIA-Linux-x86_64-550.144.03.run wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda_12.4.1_550.54.15_linux.run -
安裝依賴並禁用cloudmonitor服務。
sudo yum install -y openssl3 sudo systemctl disable cloudmonitor sudo systemctl stop cloudmonitor -
建立並配置
nvidia-persistenced.service。cat > nvidia-persistenced.service << EOF [Unit] Description=NVIDIA Persistence Daemon Wants=syslog.target Before=cloudmonitor.service [Service] Type=forking ExecStart=/usr/bin/nvidia-persistenced --user root ExecStartPost=/usr/bin/nvidia-smi conf-compute -srs 1 ExecStopPost=/bin/rm -rf /var/run/nvidia-persistenced [Install] WantedBy=multi-user.target EOF sudo cp nvidia-persistenced.service /usr/lib/systemd/system/nvidia-persistenced.service -
安裝NVIDIA驅動和CUDA Toolkit。
sudo bash NVIDIA-Linux-x86_64-550.144.03.run --ui=none --no-questions --accept-license --disable-nouveau --no-cc-version-check --install-libglvnd --kernel-module-build-directory=kernel-open --rebuild-initramfs sudo bash cuda_12.4.1_550.54.15_linux.run --silent --toolkit -
啟動nvidia-persistenced和cloudmonitor服務。
sudo systemctl start nvidia-persistenced.service sudo systemctl enable nvidia-persistenced.service sudo systemctl start cloudmonitor sudo systemctl enable cloudmonitor
8 GPU卡機密執行個體
-
遠端連線機密計算執行個體。
具體操作,請參見使用Workbench登入Linux執行個體。
重要機密計算執行個體初始化較慢,請耐心等待。
-
調整核心參數,設定SWIOTLB buffer為8GB。
sudo grubby --update-kernel=ALL --args="swiotlb=4194304,any" -
配置NVIDIA驅動程式的載入行為,並重建initramfs。
sudo bash -c 'cat > /etc/modprobe.d/nvidia-lkca.conf << EOF install nvidia /sbin/modprobe ecdsa_generic; /sbin/modprobe ecdh; /sbin/modprobe --ignore-install nvidia options nvidia NVreg_RegistryDwords="RmEnableProtectedPcie=0x1" EOF' sudo dracut --regenerate-all -f -
重啟執行個體,使以上配置生效。
具體操作,請參見重啟執行個體。
-
下載NVIDIA驅動和CUDA工具包。
8 GPU卡的機密計算執行個體需使用
570.148.08(或更高)版本的驅動,以及與之對應版本的Fabric Manager,本文以570.148.08版本為例。wget --referer=https://www.nvidia.cn/ https://cn.download.nvidia.cn/tesla/570.148.08/NVIDIA-Linux-x86_64-570.148.08.run wget https://developer.download.nvidia.com/compute/cuda/12.8.1/local_installers/cuda_12.8.1_570.124.06_linux.run wget https://developer.download.nvidia.cn/compute/cuda/repos/rhel8/x86_64/nvidia-fabric-manager-570.148.08-1.x86_64.rpm -
安裝依賴並禁用cloudmonitor服務。
sudo yum install -y openssl3 sudo systemctl disable cloudmonitor sudo systemctl stop cloudmonitor -
建立並配置
nvidia-persistenced.service。cat > nvidia-persistenced.service << EOF [Unit] Description=NVIDIA Persistence Daemon Wants=syslog.target Before=cloudmonitor.service After=nvidia-fabricmanager.service [Service] Type=forking ExecStart=/usr/bin/nvidia-persistenced --user root --uvm-persistence-mode --verbose ExecStartPost=/usr/bin/nvidia-smi conf-compute -srs 1 ExecStopPost=/bin/rm -rf /var/run/nvidia-persistenced TimeoutStartSec=900 TimeoutStopSec=60 [Install] WantedBy=multi-user.target EOF sudo cp nvidia-persistenced.service /usr/lib/systemd/system/nvidia-persistenced.service -
安裝FabricManager、NVIDIA驅動和CUDA Toolkit。
sudo rpm -ivh nvidia-fabric-manager-570.148.08-1.x86_64.rpm sudo bash NVIDIA-Linux-x86_64-570.148.08.run --ui=none --no-questions --accept-license --disable-nouveau --no-cc-version-check --install-libglvnd --kernel-module-build-directory=kernel-open --rebuild-initramfs sudo bash cuda_12.8.1_570.124.06_linux.run --silent --toolkit -
啟動nvidia-persistenced和cloudmonitor服務。
sudo systemctl start nvidia-fabricmanager.service sudo systemctl enable nvidia-fabricmanager.service sudo systemctl start nvidia-persistenced.service sudo systemctl enable nvidia-persistenced.service sudo systemctl start cloudmonitor sudo systemctl enable cloudmonitor
步驟二:檢查TDX的啟用狀態
異構機密計算特性基於TDX構建,建議您先檢查對應執行個體的TDX的啟用狀態,以確保該執行個體處於安全保護中。
檢查TDX的啟用狀態。
lscpu |grep -i tdx_guest下圖所示表示TDX已被正確啟用。

-
檢查TDX相關驅動安裝情況。
ls -l /dev/tdx_guest下圖所示表示已經安裝TDX相關驅動。

步驟三:檢查GPU機密計算特性狀態
單GPU卡機密執行個體
執行以下命令,查看機密計算特性狀態。
nvidia-smi conf-compute -f返回結果CC status: ON表示機密計算特性開啟;返回結果CC status: OFF表示機密計算特性關閉,說明執行個體出現異常,請提交工單。

8 GPU卡機密執行個體
執行以下命令,查看機密計算特性狀態。
nvidia-smi conf-compute -mgm返回結果Multi-GPU Mode: Protected PCIe表示多卡機密計算特性開啟;返回結果Multi-GPU Mode: None表示多卡機密計算特性關閉,說明執行個體出現異常,請提交工單。

8 GPU卡機密執行個體中,nvidia-smi conf-compute -f命令返回CC status: OFF是正常結果。
步驟四:通過本地證明驗證GPU/NVSwitch可信
單GPU卡機密執行個體
-
安裝GPU可信所需依賴。
sudo yum install -y python3.11 python3.11-devel python3.11-pip sudo alternatives --install /usr/bin/python3 python3 /usr/bin/python3.11 60 sudo alternatives --set python3 /usr/bin/python3.11 sudo python3 -m ensurepip --upgrade sudo python3 -m pip install --upgrade pip sudo python3 -m pip install nv_attestation_sdk==2.5.0.post6914366 nv_local_gpu_verifier==2.5.0.post6914366 nv_ppcie_verifier==1.5.0.post6914366 -f https://attest-public-cn-beijing.oss-cn-beijing.aliyuncs.com/repo/pip/attest.html -
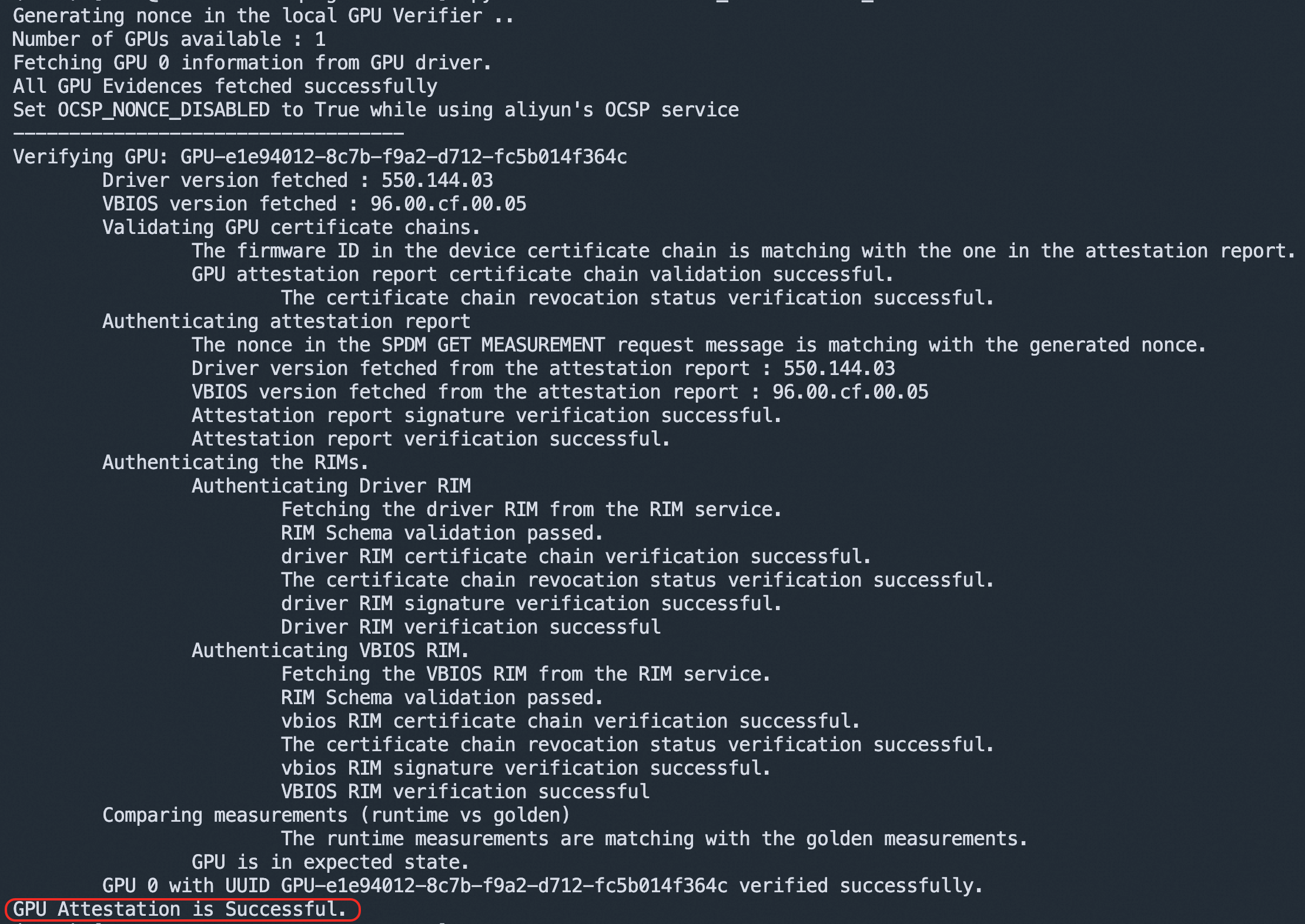
執行以下命令,驗證GPU可信狀態。
python3 -m verifier.cc_admin --user_mode回顯結果表示GPU處於機密計算狀態,且Driver、VBIOS等度量值與預期相符合:
8 GPU卡機密執行個體
-
安裝GPU可信所需依賴。
sudo yum install -y python3.11 python3.11-devel python3.11-pip sudo alternatives --install /usr/bin/python3 python3 /usr/bin/python3.11 60 sudo alternatives --set python3 /usr/bin/python3.11 sudo python3 -m ensurepip --upgrade sudo python3 -m pip install --upgrade pip sudo python3 -m pip install nv_attestation_sdk==2.5.0.post6914366 nv_local_gpu_verifier==2.5.0.post6914366 nv_ppcie_verifier==1.5.0.post6914366 -f https://attest-public-cn-beijing.oss-cn-beijing.aliyuncs.com/repo/pip/attest.html -
安裝NVSwitch相關相依元件。
wget https://developer.download.nvidia.cn/compute/cuda/repos/rhel8/x86_64/libnvidia-nscq-570-570.148.08-1.x86_64.rpm sudo rpm -ivh libnvidia-nscq-570-570.148.08-1.x86_64.rpm -
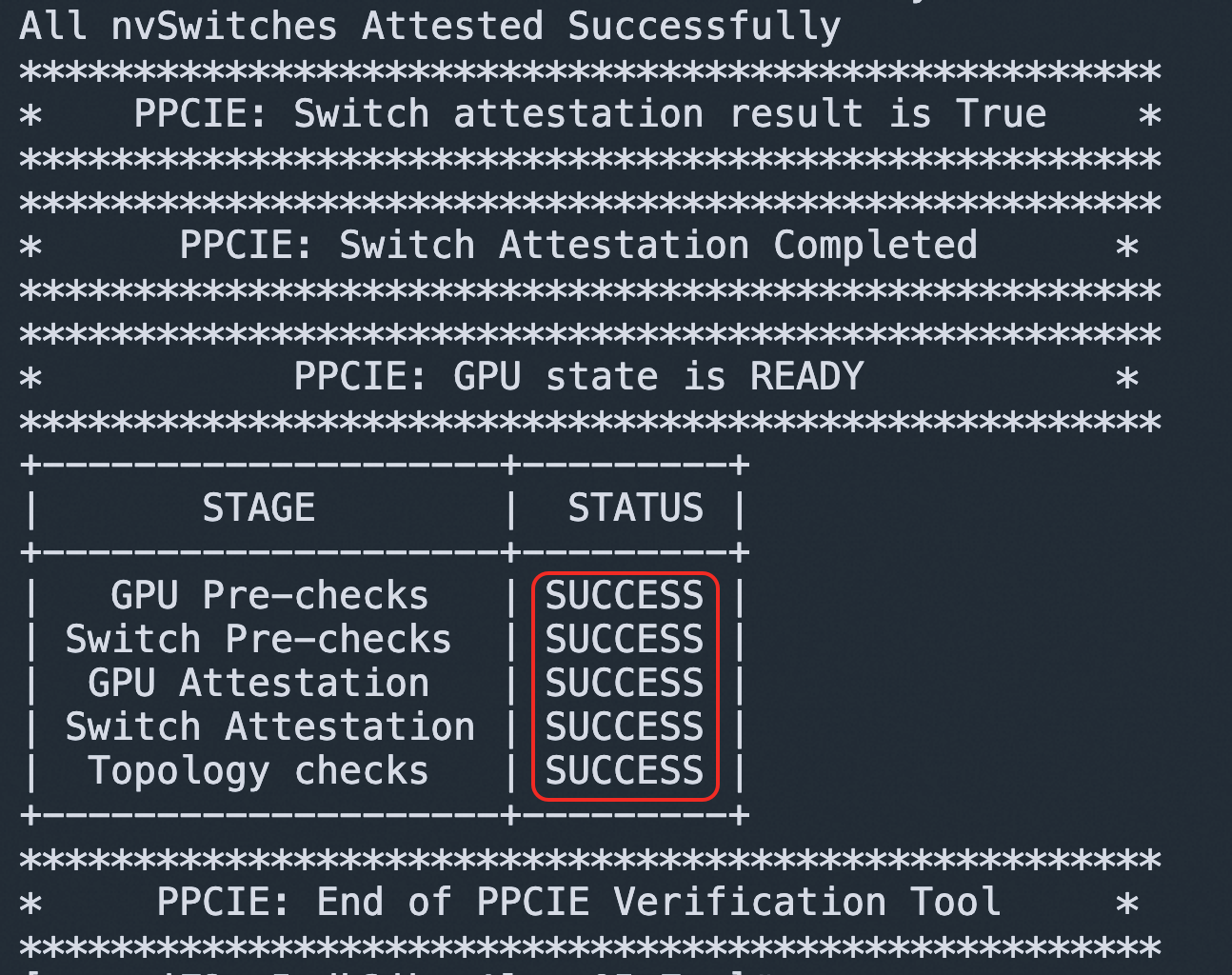
執行以下命令,驗證GPU/NVSwitch可信狀態。
python3 -m ppcie.verifier.verification --gpu-attestation-mode=LOCAL --switch-attestation-mode=LOCAL範例程式碼會分別驗證8個GPU和4個NVSwitch,最終輸出為SUCCESS表示驗證成功:
已知功能限制
-
由於異構機密計算特性基於TDX構建,TDX機密計算執行個體的功能限制對異構機密計算執行個體均適用,更多資訊,請參見TDX執行個體已知功能限制。
-
開啟GPU機密計算特性後,CPU與GPU之間的資料轉送需要加解密,因此GPU相關的效能相較異構非機密計算執行個體存在一定損失。
使用異構機密計算注意事項
-
單GPU卡執行個體使用CUDA 12.4,NVIDIA的cuBLAS庫存在已知問題,運行CUDA任務或大語言模型任務的時候可能會出錯,需要安裝特定版本的cuBLAS。
pip3 install nvidia-cublas-cu12==12.4.5.8 -
GPU開啟機密計算特性後,初始化比較慢(特別是8 GPU卡機密執行個體),Guest OS啟動後,請務必確認nvidia-persistenced服務已經啟動完成,再執行nvidia-smi或者其他命令使用GPU,檢查nvidia-persistenced服務狀態的命令為:
systemctl status nvidia-persistenced | grep "Active: "-
activating (start)表示服務正在啟動。Active: activating (start) since Wed 2025-02-19 10:07:54 CST; 2min 20s ago -
active (running)表示服務運行中。
Active: active (running) since Wed 2025-02-19 10:10:28 CST; 22s ago
-
-
任何會使用GPU的自啟動服務(例如cloudmonitor.service、nvidia-cdi-refresh.service(來自於軟體包nvidia-container-toolkit-base)、ollama.service),都需要在nvidia-persistenced.service之後啟動。
/usr/lib/systemd/system/nvidia-persistenced.service設定樣本如下:[Unit] Description=NVIDIA Persistence Daemon Wants=syslog.target Before=cloudmonitor.service nvidia-cdi-refresh.service ollama.service After=nvidia-fabricmanager.service [Service] Type=forking ExecStart=/usr/bin/nvidia-persistenced --user root --uvm-persistence-mode --verbose ExecStartPost=/usr/bin/nvidia-smi conf-compute -srs 1 ExecStopPost=/bin/rm -rf /var/run/nvidia-persistenced TimeoutStartSec=900 TimeoutStopSec=60 [Install] WantedBy=multi-user.target