Query Insights是PolarSearch的查詢分析功能,通過即時查詢監控、Top N慢查詢分析和組態管理,協助您全面瞭解叢集的查詢負載情況,快速定位和最佳化效能瓶頸。
功能入口
登入PolarSearch Dashboard,選擇OpenSearch Plugins > Query Insights,進入查詢洞察頁面。Query Insights包含以下三個功能模組:
Live queries:即時監控當前叢集正在處理的查詢負載。
Top N queries:記錄和分析過去一段時間的低效查詢。
Configuration:定義慢查詢篩選標準、統計規則和資料存放區策略。
開啟Query insights
PolarSearch中Query insights功能預設關閉。若您有相關需求,可通過Dashboard或者curl命令進行開啟。
Dashboard
在OpenSearch Plugins > Query Insights > Configuration中進行開啟,需要將Enabled按鈕關閉並儲存,然後再開啟並儲存。
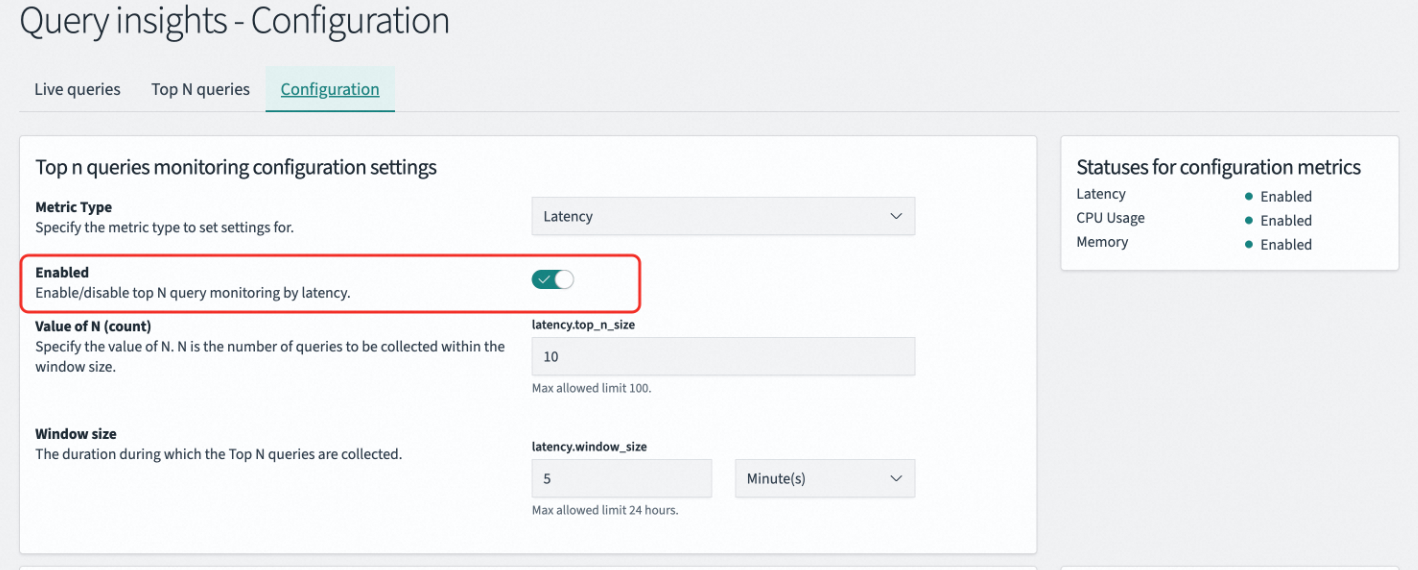
命令列
curl -XPUT "http://<endpoint>:<port>/_cluster/settings?pretty" \
--user "<user_name>:<passwd>" \
-H 'Content-Type: application/json' \
-d '{
{
"persistent": {
"search.insights.top_queries.latency.enabled": true
}
}'Live queries(即時查詢)
Live queries頁面用於即時監控當前叢集正在處理的查詢負載,展示活躍查詢的關鍵效能指標、負載分布和統計計數。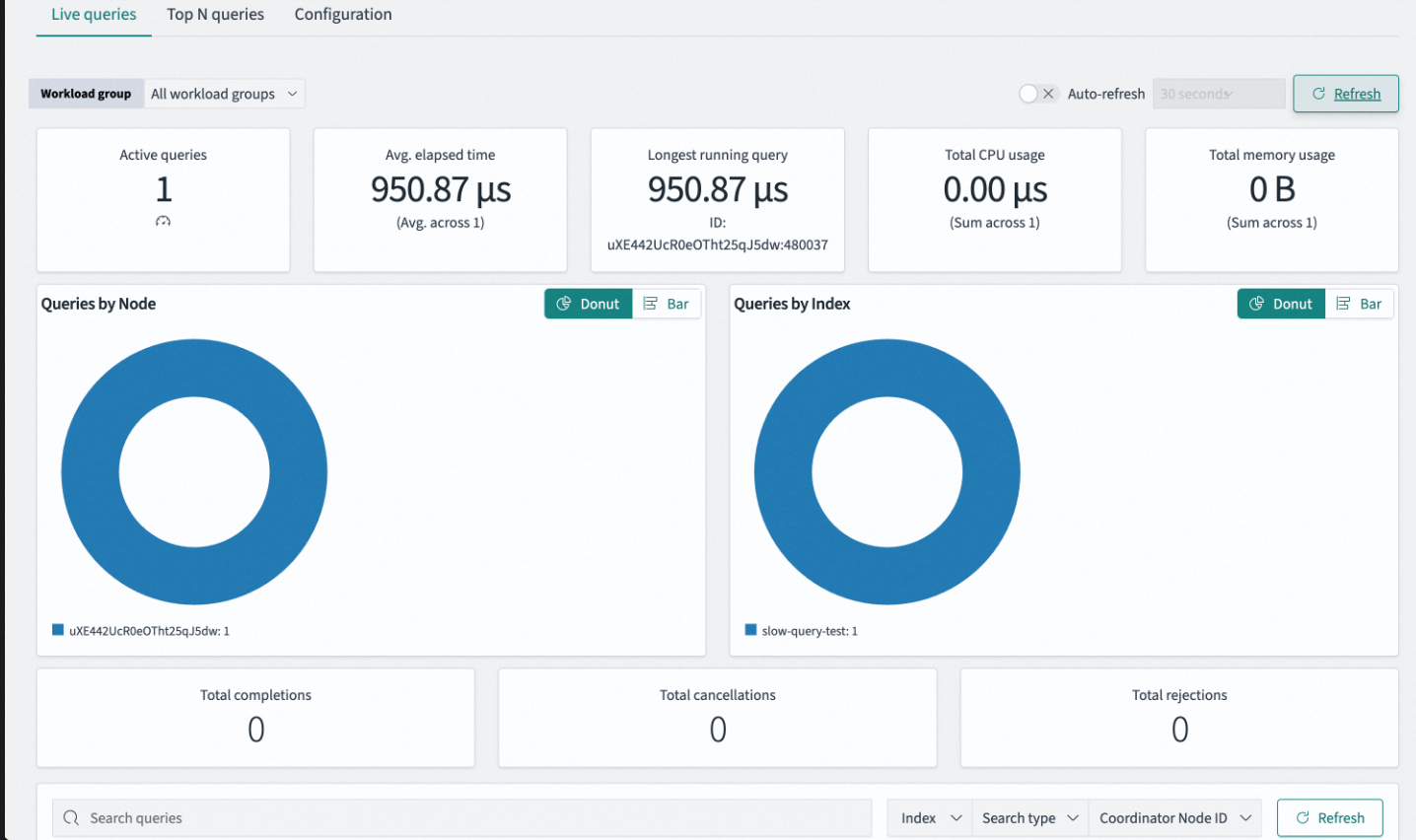
查詢指標
指標 | 說明 |
Active queries(活躍查詢數) | 當前叢集中正處於執行狀態的查詢請求總數。用於評估叢集的並發負載壓力,識別是否存在任務堆積現象。 |
Avg. elapsed time(平均耗時) | 當前所有活躍查詢自啟動至今所消耗時間的算術平均值。用於量化叢集的即時響應延遲,衡量系統擁堵程度與處理效率。 |
Longest running query(最長執行查詢) | 當前所有活躍查詢中期間最久的單個查詢所消耗的耗時。用於快速定位潛在的長尾延遲或阻塞性查詢。 |
Total CPU usage(總CPU使用率) | 當前所有活躍查詢佔用的CPU計算資源總和。用於甄別查詢是否為CPU密集型操作(如複雜彙總分析、指令碼評分計算等)。 |
Total memory usage(總記憶體使用量率) | 當前所有活躍查詢佔用的堆記憶體總量。用於監測查詢是否為記憶體密集型操作(如大規模排序、深度分頁、高基數彙總等),預警記憶體溢出(OOM)風險。 |
分布圖表
分布圖表用於直觀展示負載在叢集中的分布情況。
圖表 | 說明 |
Queries by Node(按節點分布) | 顯示當前活躍查詢在各資料節點上的分布數量。用於檢查負載平衡,識別熱點節點(Hot Spot),判斷是否存在資料扭曲或路由不均。 |
Queries by Index(按索引分布) | 顯示當前活躍查詢主要集中在哪些索引上。用於定位熱點索引,識別導致負載壓力的業務表。 |
統計計數器
統計計數器展示當前統計周期內的累計事件數目。
計數器 | 說明 |
Total completions(總完成數) | 在當前統計周期內成功執行完畢的查詢總數。 |
Total cancellations(總取消數) | 被使用者主動取消或因逾時被系統強制終止的查詢數。數值過高表明有較多查詢因響應過慢被終止。 |
Total rejections(總拒絕數) | 被線程池拒絕的查詢數。出現拒絕說明叢集處理能力已達上限,線程池隊列已滿,部分請求被丟棄。 |
如果Total rejections數值持續增長,說明叢集負載已超出承受能力,建議儘快擴容節點或最佳化高消耗查詢。
Top N queries(Top N慢查詢)
Top N queries頁面用於記錄和分析過去一段時間發生的低效查詢,協助您進行可視化分析和效能最佳化。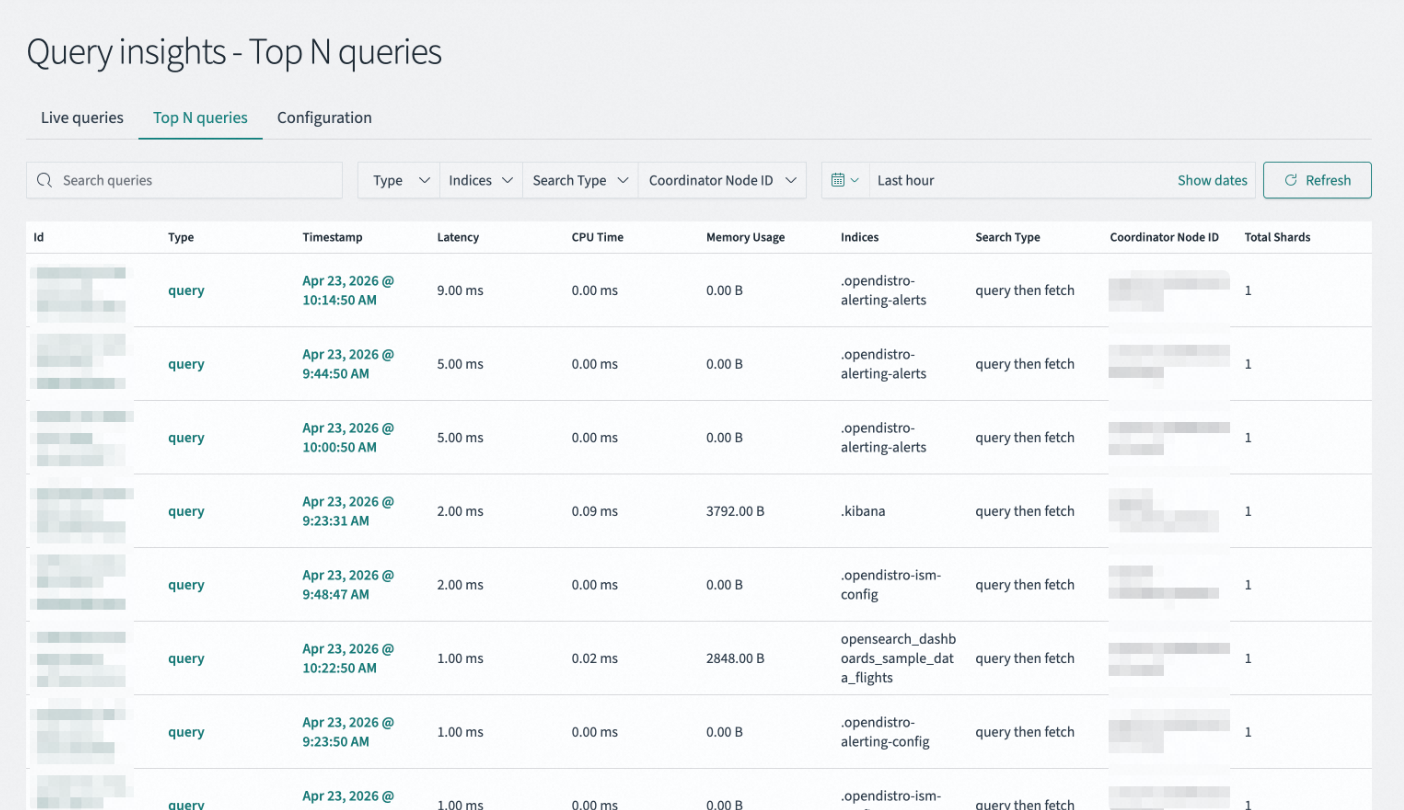
篩選與控制欄
篩選項 | 說明 |
Search queries | 通過關鍵詞(如索引名、部分查詢語句)快速檢索特定慢查詢記錄。 |
Type / Indices / Search Type / Coordinator Node ID | 多維篩選器,分別按查詢類型、涉及索引、搜尋執行策略、協調節點ID進行過濾,縮小排查範圍。 |
Last hour / Show dates | 設定查看歷史資料的時間視窗,支援選擇預設時間範圍或自訂時間段。 |
查詢詳情欄位
查詢列表展示被系統判定為Top N的查詢詳情,包含以下欄位。
欄位 | 說明 |
Id | 查詢請求的唯一識別碼。單擊可跳轉至詳細查詢頁面查看具體查詢語句。 |
Type | 請求的操作類別,例如query(標準搜尋請求)。 |
Timestamp | 查詢請求被接收並開始執行的時間點。 |
Latency | 查詢從開始到結束所消耗的總時間(單位:毫秒)。數值越高說明查詢越慢,是效能最佳化的首要關注點。 |
CPU Time | 查詢執行過程中實際佔用CPU進行計算的時間。若CPU Time接近Latency,說明是計算密集型;若遠小於Latency,說明大量時間花在I/O等待上。 |
Memory Usage | 查詢執行期間佔用的堆記憶體大小。用於識別高記憶體消耗的查詢,預防OOM風險。 |
Indices | 查詢所掃描或操作的索引名稱。用於定位熱點資料,最佳化分區策略或映射結構。 |
Search Type | 執行查詢的具體策略。不同搜尋類型有不同的效能特徵。 |
Coordinator Node ID | 接收用戶端請求並負責分發、匯總結果的協調節點標識。用於排查是否存在節點負載傾斜。 |
Total Shards | 查詢總共掃描的分區數量。掃描分區越多開銷越大,可通過最佳化路由或減少不必要的索引掃描來改善。 |
Configuration(組態管理)
Configuration是Query Insights的控制中心,用於定義慢查詢的篩選標準、統計規則和資料存放區策略。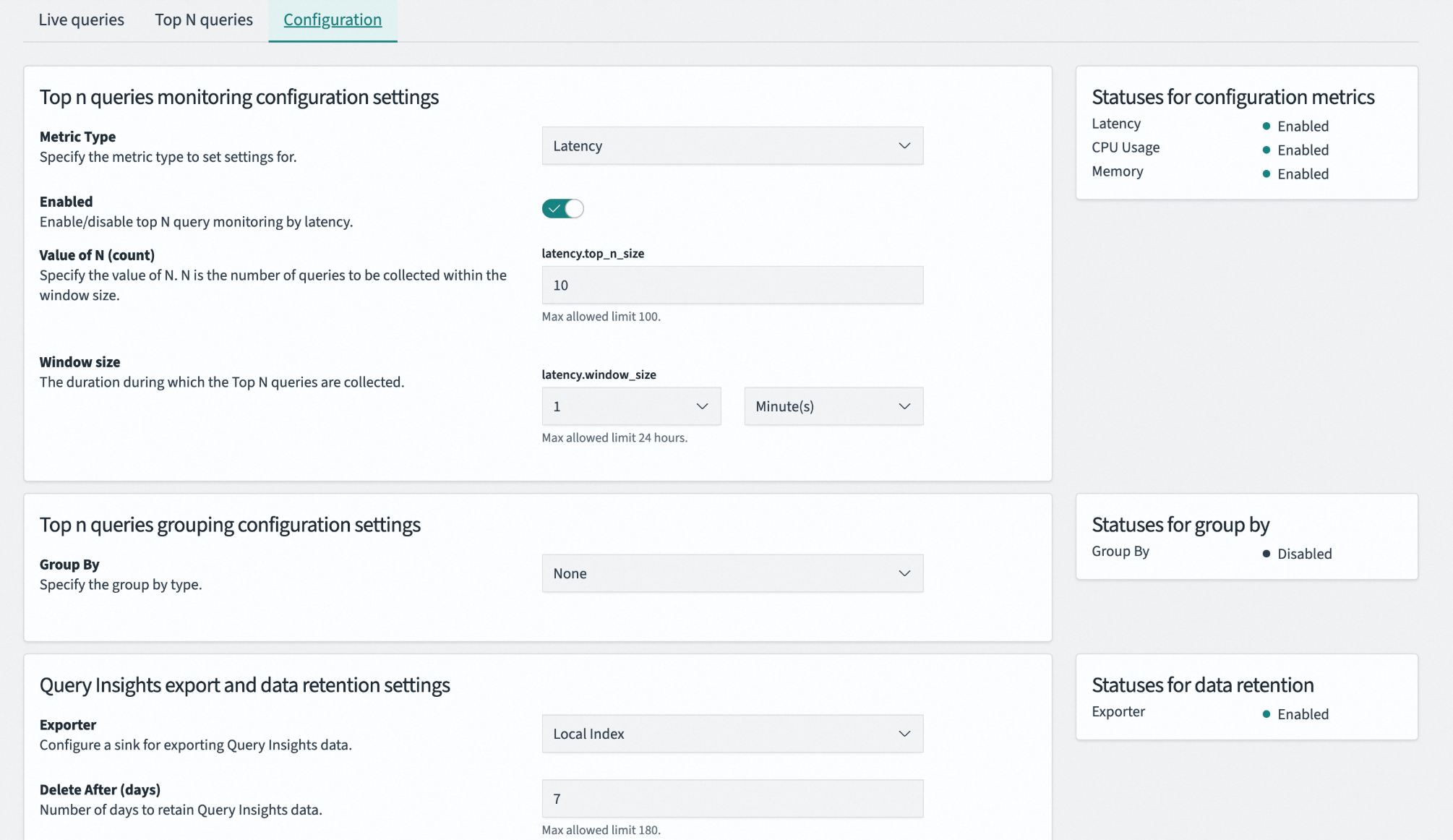
Top n queries monitoring configuration settings(Top N查詢監控配置)
定義系統如何篩選和記錄慢查詢或高資源消耗查詢。
配置項 | 說明 |
Metric Type(指標類型) | 指定用於評估查詢效能的核心度量標準。可選擇Latency(耗時)、CPU Usage(CPU佔用)或Memory(記憶體佔用)。 |
Enabled(啟用狀態) | 當前選定指標類型的Top N監控功能開關。關閉後可減少系統開銷,但會停止相關診斷資料的產生。 |
Value of N(N值) | 設定在統計時間視窗內保留的排名靠前的查詢記錄條數。數值過小可能遺漏問題,過大會增加儲存負擔。上限為100。 |
Window size(時間視窗大小) | 定義系統進行統計和排名的時間周期。較短的視窗能捕捉瞬時尖峰,較長的視窗能反映持久性負載問題。上限為24小時。 |
Top n queries grouping configuration settings(Top N查詢分組配置)
定義如何將相似的查詢進行歸類,避免榜單被大量重複的相同查詢佔據。
配置項 | 說明 |
Group By(分組依據) | 指定對查詢請求進行指紋識別和歸類的維度。開啟後,系統會將結構相同的查詢視為一類進行統計,防止單一高頻查詢刷屏,協助發現模式化的效能問題。 |
Query Insights export and data retention settings(資料匯出與留存配置)
管理監控資料的儲存位置和生命週期。
配置項 | 說明 |
Exporter(匯出器) | 指定Query Insights採集資料的儲存目標。Local Index表示儲存在叢集內部的專用索引中。 |
Delete After(資料保留天數) | 設定監控資料的最大存活時間,到期後自動刪除。設定過短會影響歷史趨勢分析,設定過長可能導致監控索引膨脹。 |
狀態面板
頁面右側的狀態面板提供配置的即時反饋(唯讀),包括以下資訊:
Statuses for configuration metrics:展示Latency、CPU Usage、Memory三項核心指標的監控啟用狀態。
Statuses for group by:顯示查詢分組功能當前的啟用或禁用狀態。
Statuses for data retention:顯示資料匯出器是否正常工作,確保資料被成功寫入儲存位置。