本文為您介紹如何使用LogStash將Elasticsearch或OpenSearch中的資料同步至PolarSearch。
準備工作
環境依賴:已準備一台可以同時訪問源庫和目標庫網路的伺服器用於運行LogStash。
許可權要求:
源庫:串連帳號需具備待同步索引的
read和read_metadata許可權。目標庫:串連帳號需具備
write、create_index等資料寫入許可權。
步驟一:準備LogStash環境
LogStash支援不同的源和目標,本文使用的目標庫為PolarSearch,源庫為Elasticsearch 7.10與PolarSearch。
下載並解壓LogStash:請根據您的環境選擇對應的安裝包。本文以Linux x86_64環境8.8.2版本為例。
說明不同版本的LogStash在使用上略有差異但核心邏輯一致。
更多LogStash版本,請參見LogStash版本列表。
安裝外掛程式:
不同的源庫與目標庫需要安裝不同的外掛程式,請根據您的實際情況選擇安裝。外掛程式倉庫地址,請參見外掛程式倉庫。
源庫外掛程式:
若源庫為Elasticsearch,則需要安裝
input-elasticsearch外掛程式。當前外掛程式已經預先安裝,您可通過命令查看是否已經安裝。# 進入 LogStash 根目錄 cd /path/to/logstash-8.8.2 # 檢查外掛程式是否已經安裝 ./bin/logstash-plugin list # 如果沒有安裝,則執行外掛程式安裝命令 ./bin/logstash-plugin install logstash-input-elasticsearch若源庫為OpenSearch,則需要安裝
input-opensearch外掛程式。# 進入 LogStash 根目錄 cd /path/to/logstash-8.8.2 # 執行外掛程式安裝命令 ./bin/logstash-plugin install logstash-input-opensearch
目標庫外掛程式:安裝
output-opensearch外掛程式,PolarSearch相容OpenSearch介面,匯入PolarSearch需安裝output-opensearch外掛程式。# 進入 LogStash 根目錄 cd /path/to/logstash-8.8.2 # 執行外掛程式安裝命令 ./bin/logstash-plugin install logstash-output-opensearch
步驟二:建立同步設定檔
在LogStash根目錄下建立synchronization.conf檔案,並根據實際環境,參考以下模板填入配置。
相關參數說明
input源庫中的index欄位支援使用萬用字元*以同步多個索引。然而,不建議使用全通配邏輯*來複製所有索引,因為這可能會導致不必要的內部索引複製。input源庫中的docinfo欄位,可以擷取原始索引名和文檔ID。output目標庫中index名字等可以通過記錄的metadata讀取,從而保持索引名等不變或在原有名字等元資訊基礎上進行定製。output目標庫中可以增加stdout調試選項可輸出調試資訊。
更多資訊,請參見同步Logstash事件至OpenSearch。
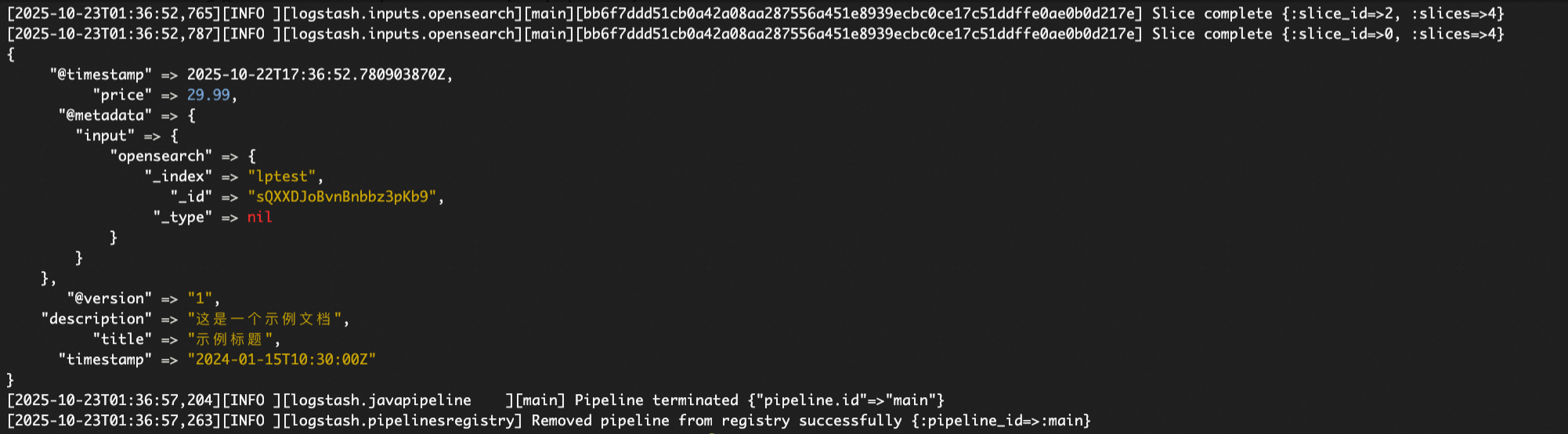
調試輸出
如下圖所示,通過該輸出可以觀察到記錄的_index等metadata及其結構層次。例如,_index欄位的結構層次表明其在output等後續流程中的提取邏輯為:[@metadata][input][opensearch][_index]。
不同input外掛程式的metadata提取邏輯存在差異。
設定檔樣本
# synchronization.conf
# 一個從 Elasticsearch/OpenSearch 向 PolarSearch 同步資料的完整配置樣本。
input {
# 如果源叢集是 Elasticsearch,請將 'opensearch' 替換為 'elasticsearch'。
# 兩個外掛程式的配置參數基本相同,但中繼資料路徑可能存在差異。
opensearch {
# 【必填】源叢集的串連地址,建議使用 HTTPS 協議。
hosts => ["https://source-cluster-endpoint:9200"]
# 【必填】源叢集的認證憑據。
user => "your_source_user"
password => "your_source_password"
# 【必填】指定需要同步的索引,支援萬用字元。
# 為避免同步不必要的內部索引(如 .kibana),不建議使用 "*" 或 ".*"。
index => "your-business-logs-*"
# --- 安全配置 ---
# 如果源叢集啟用了 SSL/TLS,請設定為 true。
ssl => true
# 如果源叢集使用自我簽署憑證,取消注釋並指定 CA 憑證路徑。
# cacert => "/path/to/source_ca.crt"
# --- 效能與中繼資料 ---
# 開啟此選項以擷取原始索引名和文檔 ID。
docinfo => true
# 設定並發讀取數,建議設定為源索引的主分區數量以最大化讀取效能。
slices => 4
# 每次批量擷取的文檔數量。
size => 1000
# 滾動查詢的存活時間,確保長任務不會因逾時而中斷。
scroll => "5m"
}
}
output {
opensearch {
# 【必填】目標 PolarSearch 叢集的串連地址。
hosts => ["https://polarsearch-cluster-endpoint:9200"]
# 【必填】目的地組群的認證憑據。
user => "your_target_user"
password => "your_target_password"
# --- 安全配置 ---
ssl => true
# 如果目的地組群使用自我簽署憑證,取消注釋並指定 CA 憑證路徑。
# cacert => "/path/to/polarsearch_ca.crt"
# --- 索引與文檔 ID ---
# 從中繼資料中動態讀取並設定索引名,以保持與源端一致。
# 注意:中繼資料路徑因 input 外掛程式而異,需通過調試輸出確認。
index => "%{[@metadata][input][opensearch][_index]}"
# 從中繼資料中讀取並設定文檔 ID,以保持文檔的唯一性。
document_id => "%{[@metadata][input][opensearch][_id]}"
}
# --- 調試輸出(可選) ---
# 在開發與測試階段,取消此段注釋可在控制台列印資料流資訊。
# 正式同步時,注釋掉此段以獲得最佳效能。
# stdout {
# codec => rubydebug {
# metadata => true
# }
# }
}步驟三:執行同步與驗證
啟動任務:在LogStash根目錄下執行以下命令啟動同步任務。
# 啟動同步任務,-f 參數指定設定檔 ./bin/logstash -f synchronization.conf對於大規模資料同步,建議使用
nohup將LogStash作為後台服務運行:nohup ./bin/logstash -f synchronization.conf &等待任務執行完成後,登入目標PolarSearch,檢查索引和資料是否成功建立和寫入。