本文介紹如何開通適配eRDMA的E-HPC Cluster(原E-HPC NEXT),並以OSU-Benchmark應用為例,提供配置運行時參數以使用eRDMA技術加速多節點HPC應用的通訊。
背景資訊
利用eRDMA技術,E-HPC Cluster(原E-HPC NEXT)中的氣候氣象、工業模擬、分子動力等HPC多節點並行任務可達到媲美線下叢集的高速網路效能,包括高頻寬和低延遲,可顯著提升數值類比、模擬的效率。同時,無需額外部署RDMA網卡,即可在現有業務組網中體驗到RDMA的優勢,實現無縫整合和便捷應用。
準備工作
單擊前往建立叢集頁面,建立一個E-HPC叢集。具體操作,請參見建立標準版叢集。
本文使用的叢集配置樣本如下:
執行個體規格:採用ecs.c7.xlarge執行個體規格,該規格配置為4 vCPU,8 GiB記憶體。
鏡像:aliyun_2_1903_x64_20G_alibase_20240628.vhd
說明osu-benchmark安裝包基於Alibaba Cloud Linux 2.1903 LTS 64位鏡像完成構建。
erdma-installer
mpich-aocc
執行個體規格:採用ecs.c7.xlarge執行個體規格,該規格配置為4 vCPU,8 GiB記憶體。
鏡像:aliyun_2_1903_x64_20G_alibase_20240628.vhd
建立一個叢集使用者,具體操作,請參見使用者管理。
配置項 | 配置 | |
叢集配置 | 地區 | 上海 |
網路及可用性區域 | 選擇可用性區域L | |
系列 | 標準版 | |
部署模式 | 公用雲叢集 | |
叢集類型 | SLURM | |
管理節點 | ||
計算節點與隊列 | 隊列節點數 | 初始節點 |
節點間互聯 | eRDMA網路 說明 僅部分節點規格支援ERI,更多資訊,請參見彈性RDMA(eRDMA)和在企業級執行個體上啟用eRDMA。 | |
執行個體規格組 | 執行個體規格:採用ecs.c8ae.xlarge或同代的其他AMD執行個體。 鏡像:aliyun_2_1903_x64_20G_alibase_20240628.vhd | |
共用檔案儲存體 | /home 叢集掛載目錄 | 預設情況下,管理節點的 |
/opt 叢集掛載目錄 | ||
軟體與服務元件 | 待安裝軟體 | |
可安裝服務元件 | 登入節點: |
檢查eRDMA環境
檢查計算節點eRDMA配置是否正確。
登入彈性高效能運算控制台,單擊目的地組群。
在頁面,選中叢集中所有計算節點,單擊發送命令。
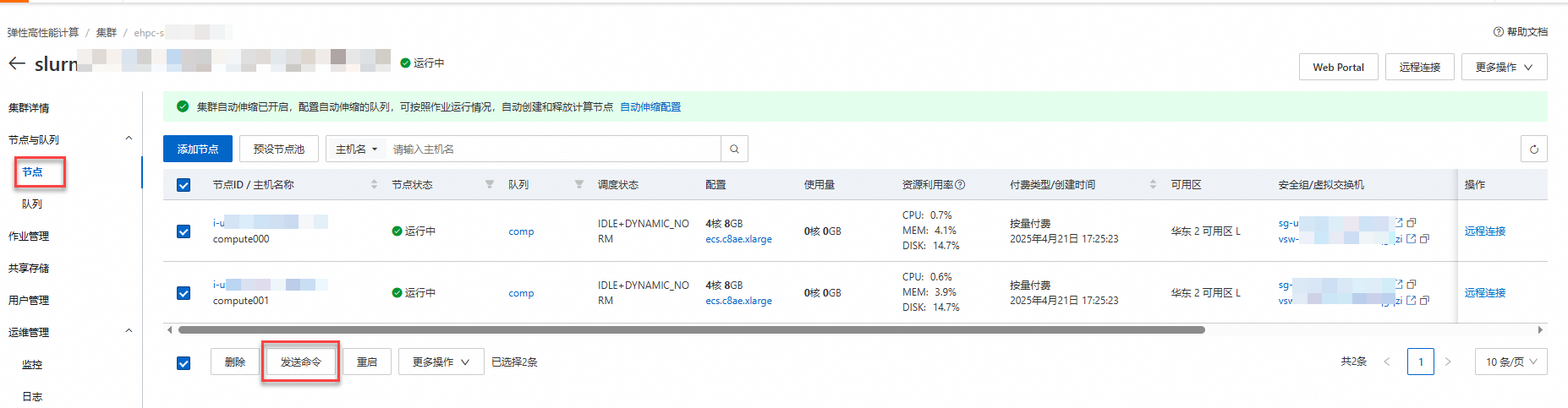
檢查計算節點的 eRDMA 網路狀態 和 RDMA 硬體/軟體支援情況。
發送如下命令到所有計算節點。
hpcacc erdma check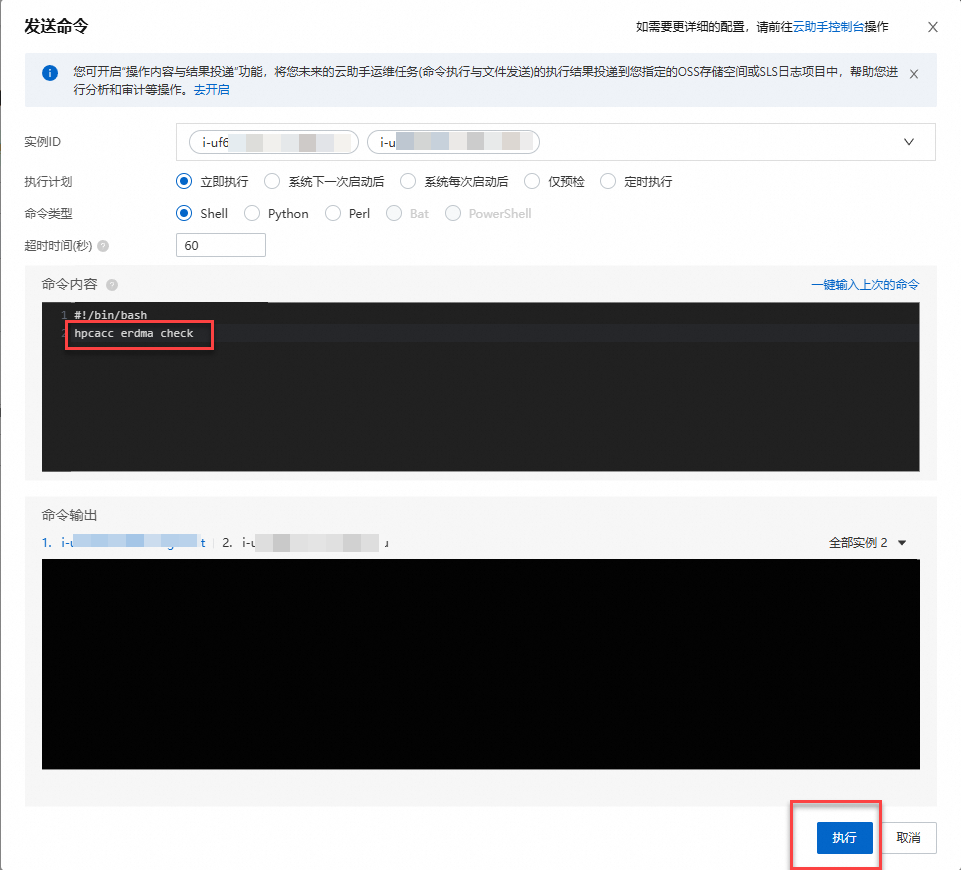
返回如下結果,表示eRDMA配置正確。
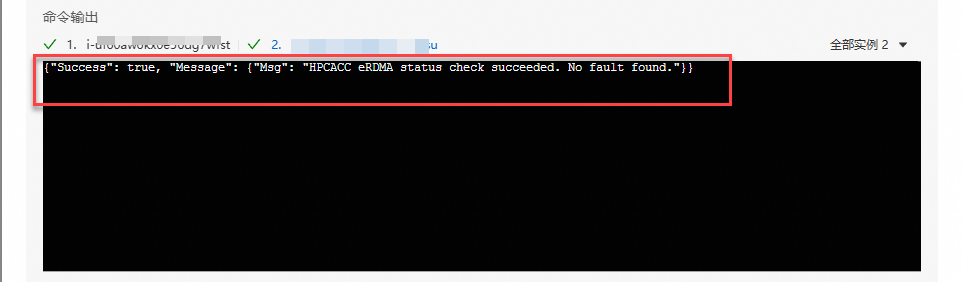
如果返回資訊異常,執行以下命令進行修複。
hpcacc erdma repair修複完成後,再次確認eRDMA配置正確即可。
OSU-Benchmark測試
OSU-Benchmark用於評估Alibaba Cloud HPC叢集和分布式系統的通訊效能。本文利用以下2個基準測試,基於不同網路通訊協定(TCP vs. RDMA)測試通訊效能:
網路延遲測試(osu_latency):測量點對點通訊的單向延遲(從進程A發送訊息到進程B的時間,不含返回時間),尤其關注小訊息(如1位元組到數KB)的通訊效率。小訊息的延遲反映了網路硬體的底層效能(如RDMA加速能力)和MPI庫的最佳化水平,是HPC系統響應能力的核心指標。例如,在即時模擬或機器學習參數同步中,低延遲能顯著減少通訊開銷。
網路頻寬測試(osu_bw):測量點對點通訊的可持續頻寬(單位時間內傳輸的資料量),關注大訊息(如數KB到數MB)的傳輸效率。頻寬效能直接影響巨量資料傳輸的效率,如科學計算中的矩陣交換或檔案I/O情境。若實測頻寬遠低於理論值,可能需最佳化MPI配置(如多線程通訊)或檢查網路設定(如MTU、流控)。
測試過程如下:
使用已經建立的使用者,串連EHPC叢集。詳細資料,請參見串連叢集。
執行以下命令,檢查依賴環境組件是否正確安裝。
module avail執行以下命令,下載並解壓已先行編譯的osu-benchmark安裝包。
cd ~ && wget https://ehpc-perf.oss-cn-hangzhou.aliyuncs.com/AMD-Genoa/osu-bin.tar.gz tar -zxvf osu-bin.tar.gz執行以下命令,進入測試工作目錄並編輯slurm作業指令碼。
cd ~/pt2pt vim slurm.job測試指令碼內容如下:
#!/bin/bash #SBATCH --job-name=osu-bench #SBATCH --ntasks-per-node=1 #SBATCH --nodes=2 #SBATCH --partition=comp #SBATCH --output=%j.out #SBATCH --error=%j.out # load env params module purge module load aocc/4.0.0 gcc/12.3.0 libfabric/1.16.0 mpich-aocc/4.0.3 # run mpi latency test: erdma echo -e "++++++ use erdma for osu_lat: START" mpirun -np 2 -ppn 1 -genv FI_PROVIDER="verbs;ofi_rxm" ./osu_latency echo -e "------ use erdma for osu_lat: END\n" # run mpi latency test: tcp echo -e "++++++ use tcp for osu_lat: START" mpirun -np 2 -ppn 1 -genv FI_PROVIDER="tcp;ofi_rxm" ./osu_latency echo -e "------ use erdma for osu_lat: END\n" # run mpi bandwidth test: erdma echo -e "++++++ use erdma for osu_bw: START" mpirun -np 2 -ppn 1 -genv FI_PROVIDER="verbs;ofi_rxm" ./osu_bw echo -e "------ use erdma for osu_bw: END\n" # run mpi bandwidth test: tcp echo -e "++++++ use tcp for osu_bw: START" mpirun -np 2 -ppn 1 -genv FI_PROVIDER="tcp;ofi_rxm" ./osu_bw echo -e "------ use tcp for osu_bw: END\n"說明-np 2:指定總的進程數量,這裡設定為2,意味著整個MPI作業將啟動兩個進程。-ppn 1:指定每個節點上的進程數,這裡設定為1,表示每個節點運行1個進程。-genv:設定環境變數,對所有進程生效。FI_PROVIDER="tcp;ofi_rxm":使用TCP 協議,並通過 RXM 架構增強通訊可靠性。FI_PROVIDER="verbs;ofi_rxm":優先使用高效能 Verbs 協議(基於 RDMA),並通過 RXM 架構最佳化訊息傳輸。本文中使用阿里雲eRDMA提供高效能彈性RDMA網路。
執行以下命令,提交測試作業。
sbatch slurm.job命令列輸出job id。

執行以下命令,查看作業運行。測試過程中,您也可以在控制台上查看E-HPC的監控資訊(包括儲存監控、作業監控、節點監控等)。詳細資料,請參見查看監控資訊。
squeue
您可以在目前的目錄下,查看job id對應的記錄檔,輸出內容如下所示:
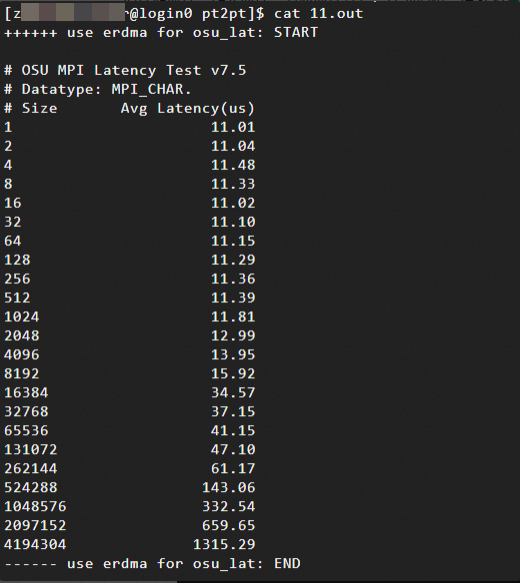
網路延遲測試結果:訊息大小(Size,單位為位元組Bytes,範圍為1B到4MB)與網路延遲(Avg Latency)的關係。本文中測試結果樣本如下:
使用Verbs 協議(基於eRDMA)
使用TCP協議
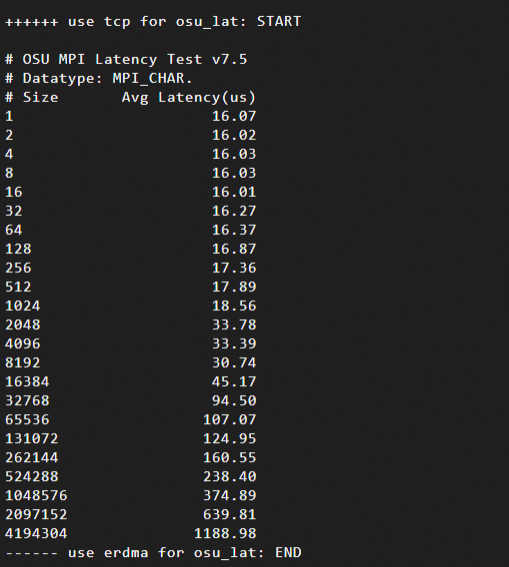
通過測試資料可以發現,對於小訊息(1B~8KB),eRDMA的延遲明顯低於TCP。
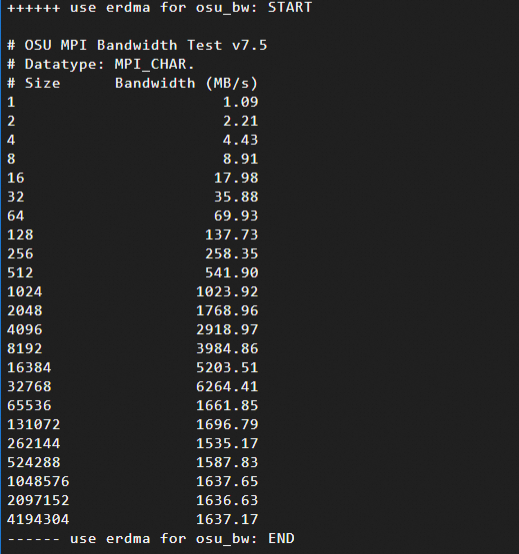
網路頻寬測試結果:訊息大小(Size,單位為位元組Bytes,範圍為1B到4MB)與頻寬(Bandwidth)的關係。本文中測試結果樣本如下:
使用Verbs 協議(基於eRDMA)
使用TCP協議
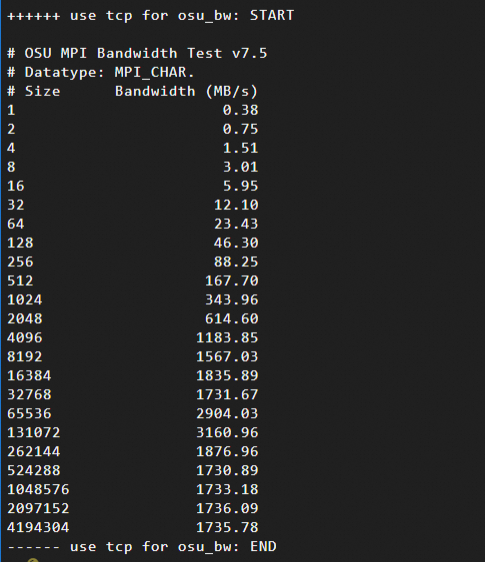
通過測試資料可以發現,在訊息大小為16KB ~ 64KB時,eRDMA充分利用了網路頻寬,而TCP的協議棧處理引入額外開銷。