本文以vLLM推理情境為例,對在ACK叢集中啟動並執行GPU容器的AI Profiling檢測結果進行分析,重點闡述如何通過線上效能檢測結果的可視化頁面,分析Python進程、CPU調用、系統調用、CUDA庫和CUDA核函數的執行過程,定位效能瓶頸,找到效能調優方向,從而提升GPU利用率和應用效率。
vLLM推理樣本
樣本環境
架構:vLLM 0.5.0
模型:Qwen2-7B
GPU:NVIDIA A10
Profiling時間長度:5s
開啟Profiling項:all
結果分析
模型載入
查看模型載入的整體流程:放大視圖可以清晰地看到整個模型的載入過程分為三個步驟:資料讀取、資料拷貝和Decoding。

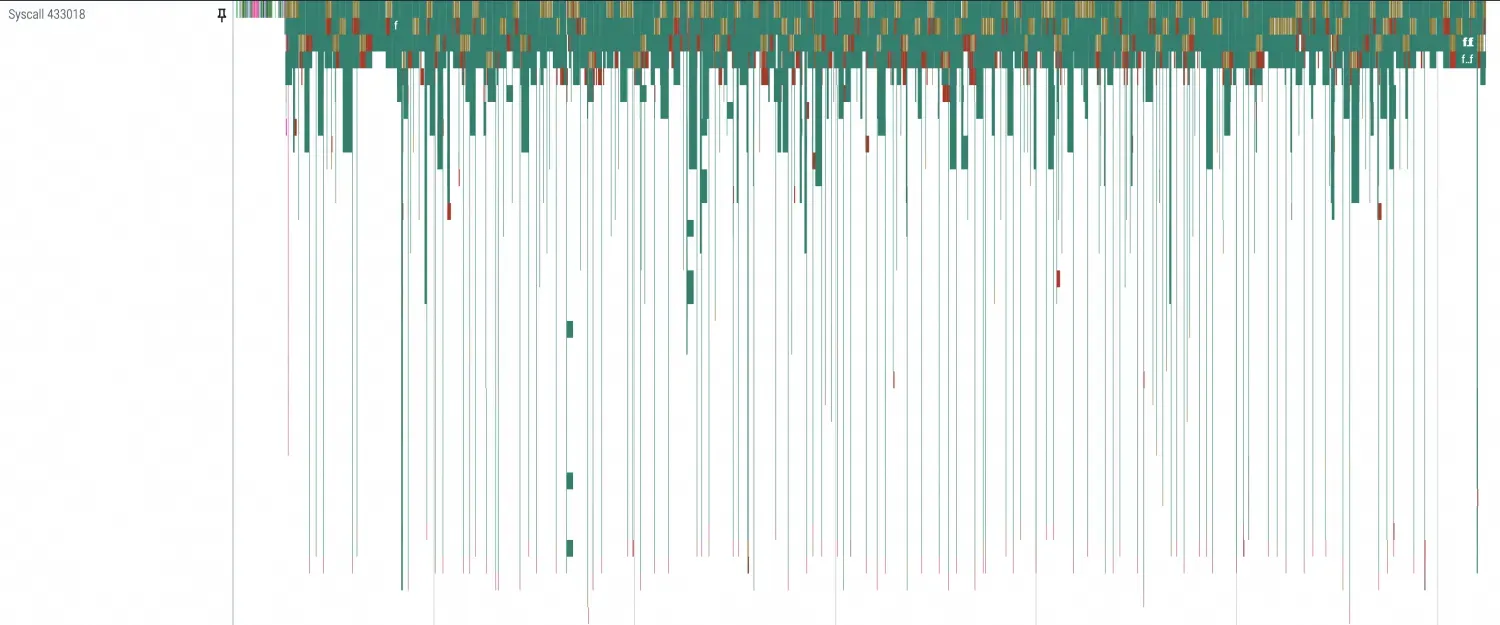 在Python profiling中可以用分隔線將其各個階段分隔開,如下圖所示。由於該樣本為初次開機,因此未使用PageCache,資料轉送所佔用的時間顯得尤為明顯。
在Python profiling中可以用分隔線將其各個階段分隔開,如下圖所示。由於該樣本為初次開機,因此未使用PageCache,資料轉送所佔用的時間顯得尤為明顯。
分別查看各個階段的Profiling項效果:放大視圖可以看到主要區別集中在這幾個系統調用中(openat、mmap、read、ioctl),都是與 I/O 相關的操作。由於讀模數型時主要使用
safetensors.torch.load_file隨機讀取,因此會頻繁出現mmap和read的調用。
通過資料轉送過程可以看到系統調用主要集中在poll、epoll、futex中,同時CPU也在頻繁地使用多核和核的切換,CUDA調用方面則是進行了和模型safetensor數量相同的cuMemcpyHtoD的傳輸。因此,可以結合vLLM的模型載入過程判斷出模型資料轉送大概的路徑(磁碟或者網路 -> 記憶體(PageCache) -> GPU顯存)。後續在圖中補充網路和磁碟IO的資料就可以更加清晰地觀察。

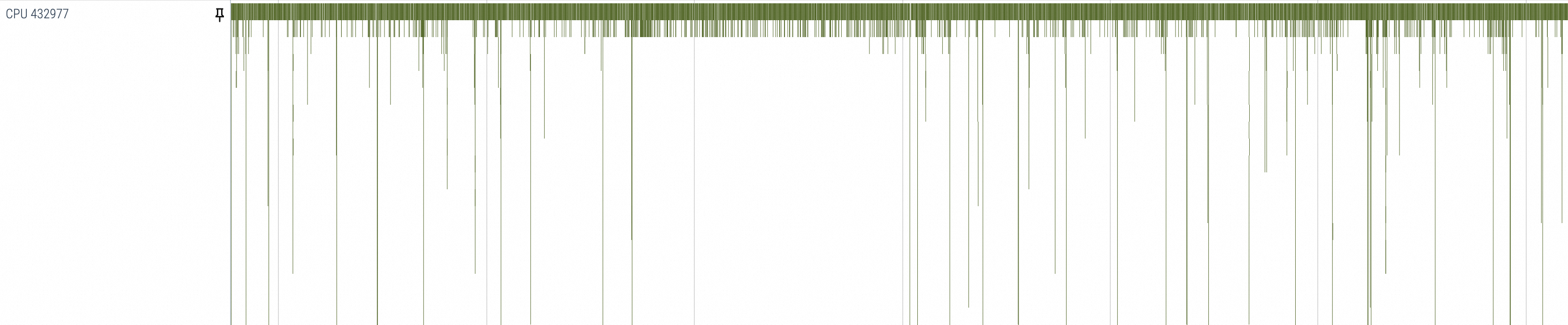
觀察Decoding的過程,重點關注GPU相關庫的調用:每個批次中執行的矩陣乘法及其上下遊調用(如 cuLaunchKernel、cuMemcpyDtoD、cublasGemmEx)呈現得較為規律,都能和對應Python的Decoding方法進行對齊,所以也是可以較為明顯的分出其所代表的階段。

模型推理
本樣本通過手動類比的NCCL-Hang來展示問題的發現與推測過程。
由於NCCL Hang通常表現為陷入核心態或NCCL層面的通訊/O阻塞,因此可以通過類比不同進程間的NCCL通訊中斷來重現情境。使用以下命令分別進行進程的掛起和恢複,類比NCCL的中斷和恢複過程。
kill -STOP <PID> kill -CONT <PID>正常無中斷的推理時間長度:

開啟了5s中斷的推理時間長度:

在進程被主動中斷的過程中,可以通過觀察以上現象得知,Demo樣本每次推理大約需要15s左右,然後類比中斷了5s左右,最終恢複後推理請求的總時間長度變為了20s左右,符合設定預期。
經過觀察,vLLM的每一次推理過程是由多個推理計算的部分組成,如下圖紅框部分,大致流程為
cuda memory copy H2D -> nccl broadcast -> cublas compute -> nccl send and recv -> cuda memory copy D2H。所以NCCL可能中斷的點為broadcast和send and recv的過程。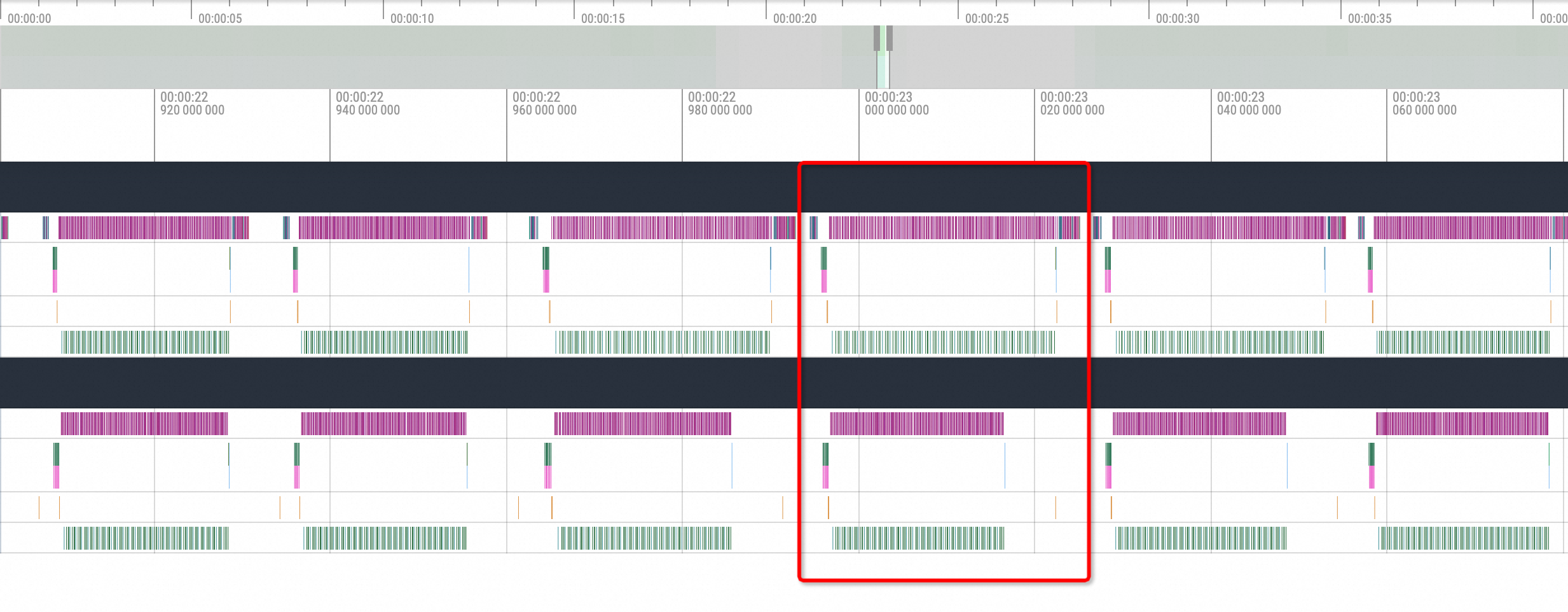
停機時間點決定了阻塞的NCCL動作,開啟60s僅GPU的Profiling,並將Profiling出的資料轉換為Chrome Tracing的格式化資料,介紹兩種NCCL被阻塞的情況:
nccl send and recv可視化結果如下所示:
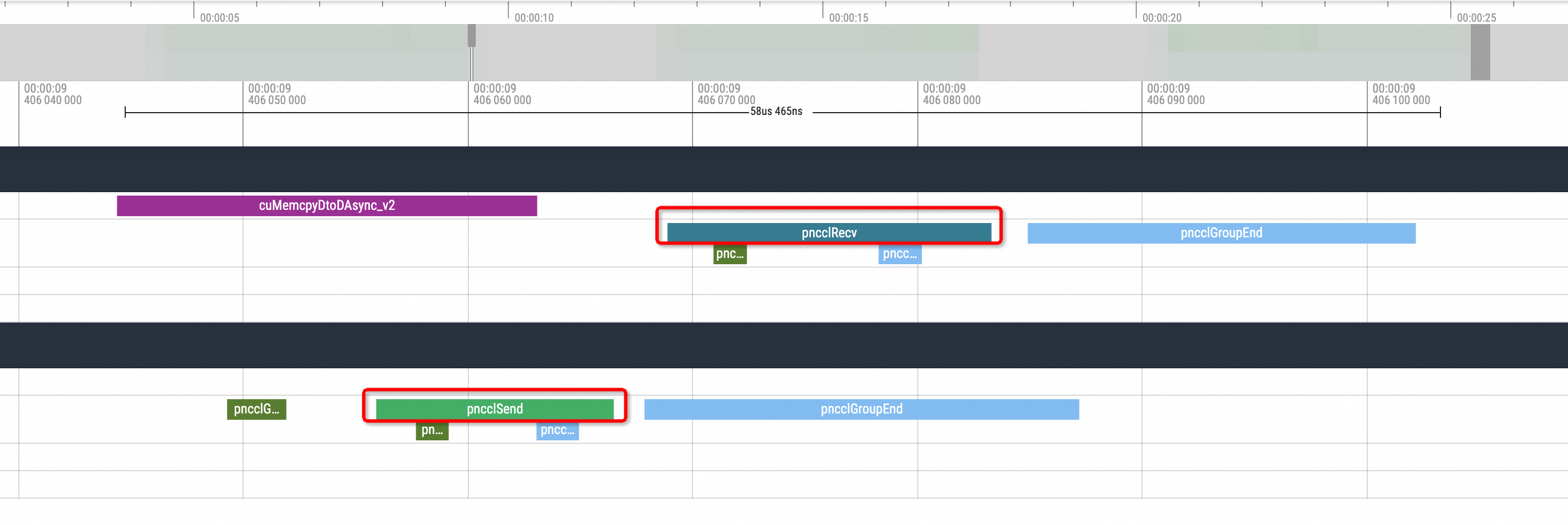
首先看正常情況,在一次推理的結尾的時間內通常在其中一個副本會有一次pnccl Send,另一個副本會有一次相對應的pnccl Recv。而在開啟了NCCL Hang類比的情況下,可以看到Profiling視圖會出現如下的情況:
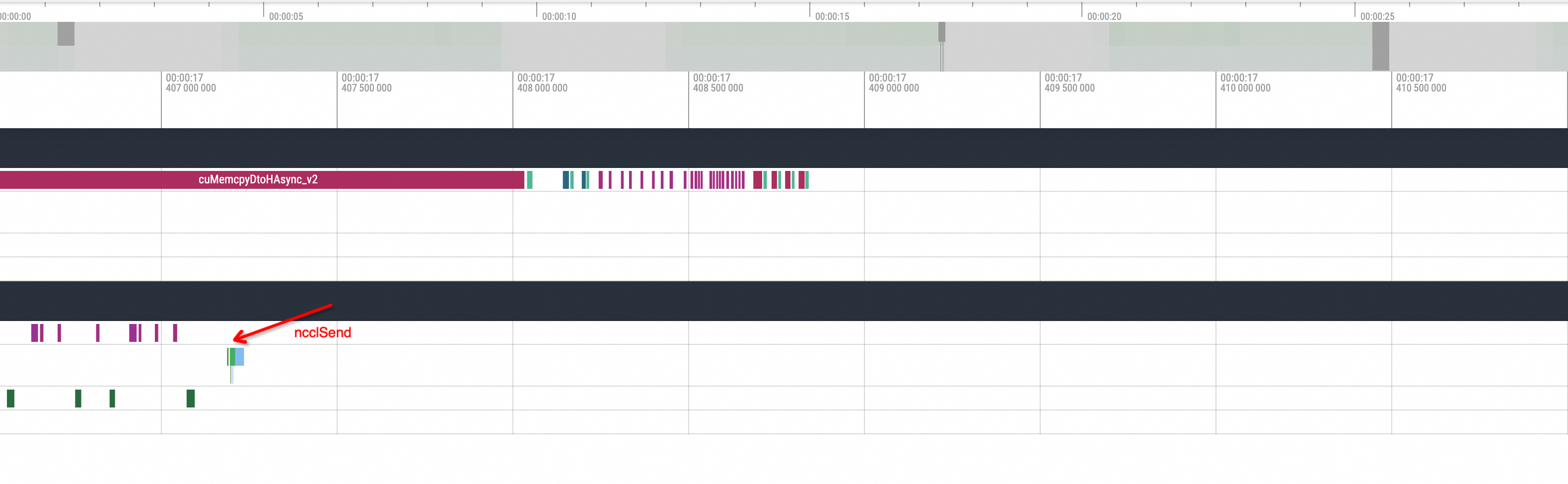
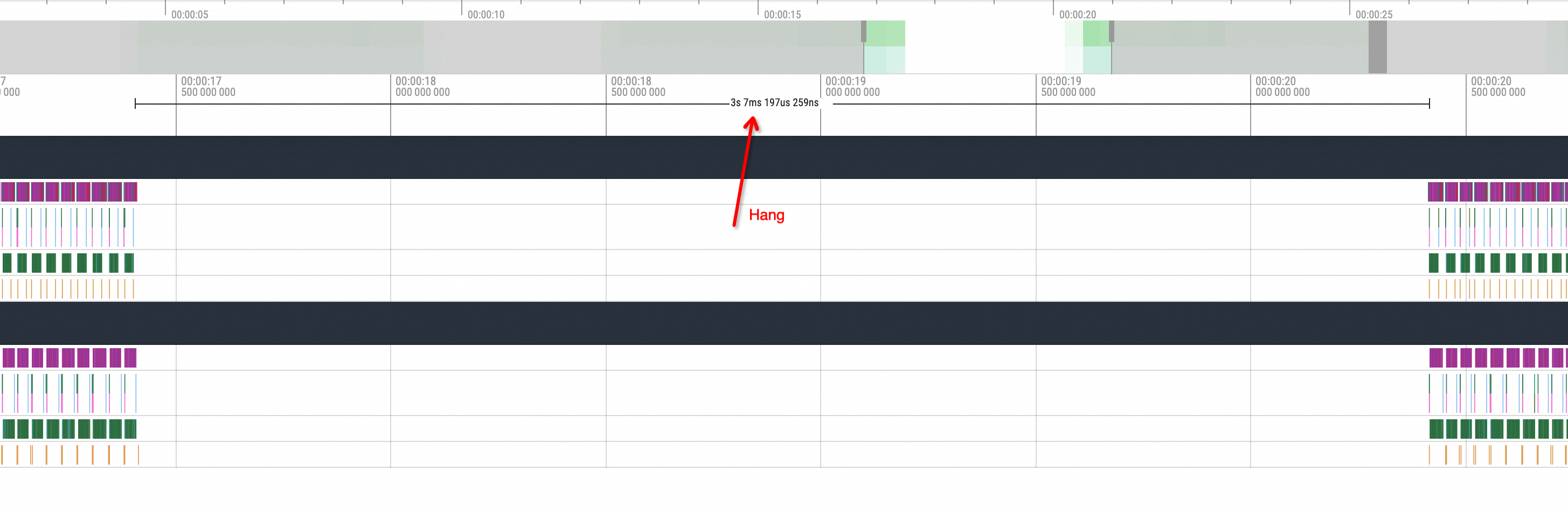
即其中的一個副本在發出ncclSend調用後,另一個副本沒有與之對應的ncclRecv動作調用發生,整個GPU相關方法的調用進入了一段時間的空閑狀態。等待進程狀態恢複後另一個副本才執行了對應的ncclRecv動作,所以在不知道其底層邏輯的情況下,大致可以推測為NCCL Hang的問題導致了這一現象。
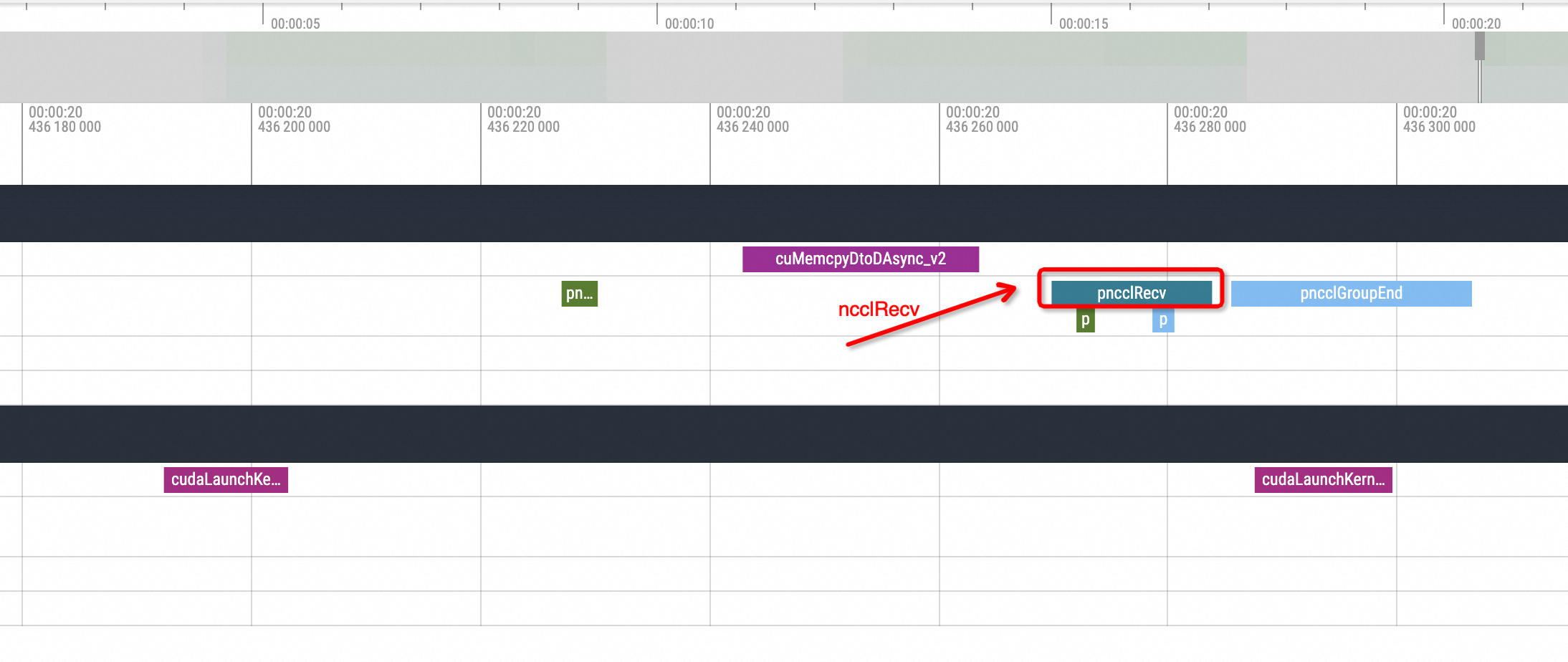
nccl broadcast以下是在
nccl broadcast之前執行Hang操作的效果圖: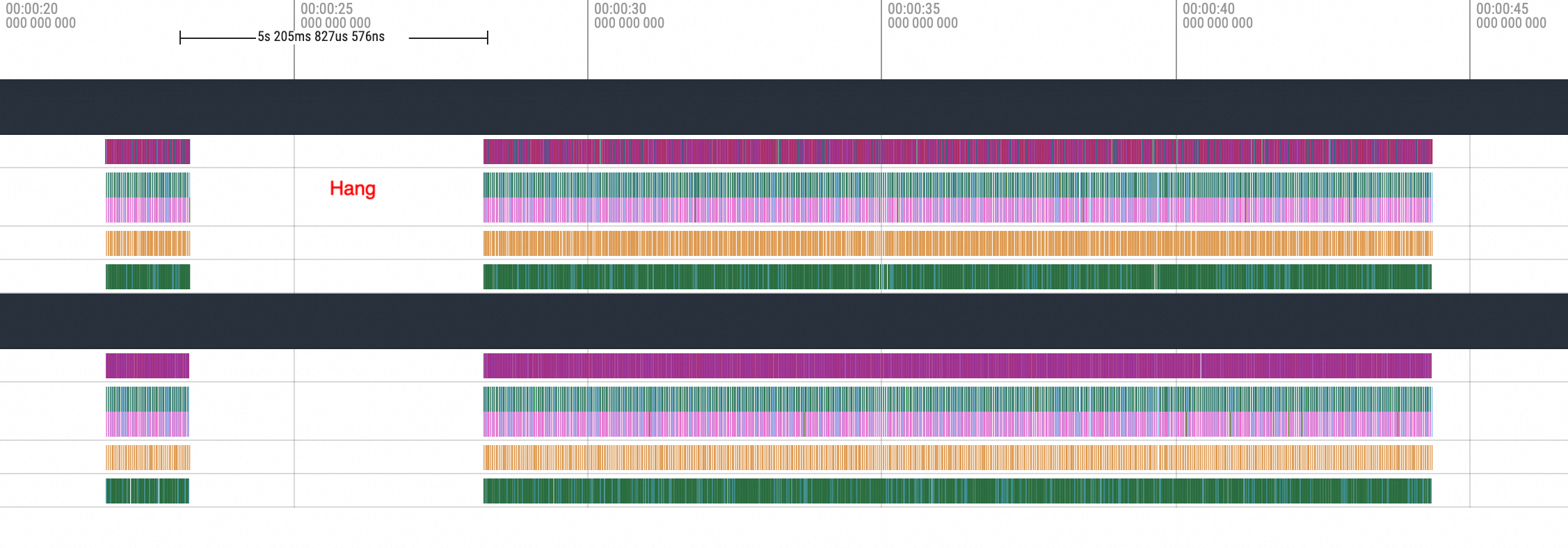
Zoom In到Hang之前所執行的方法。
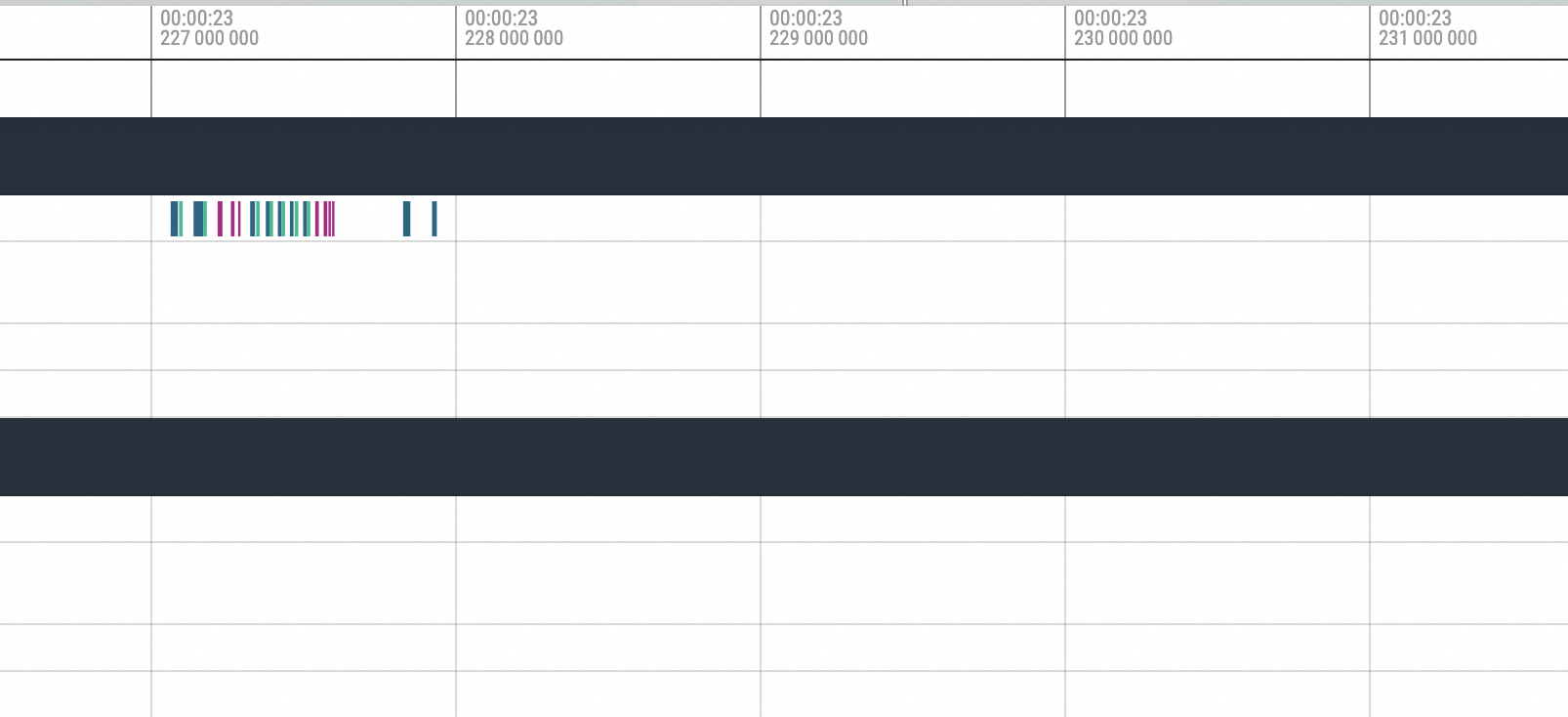
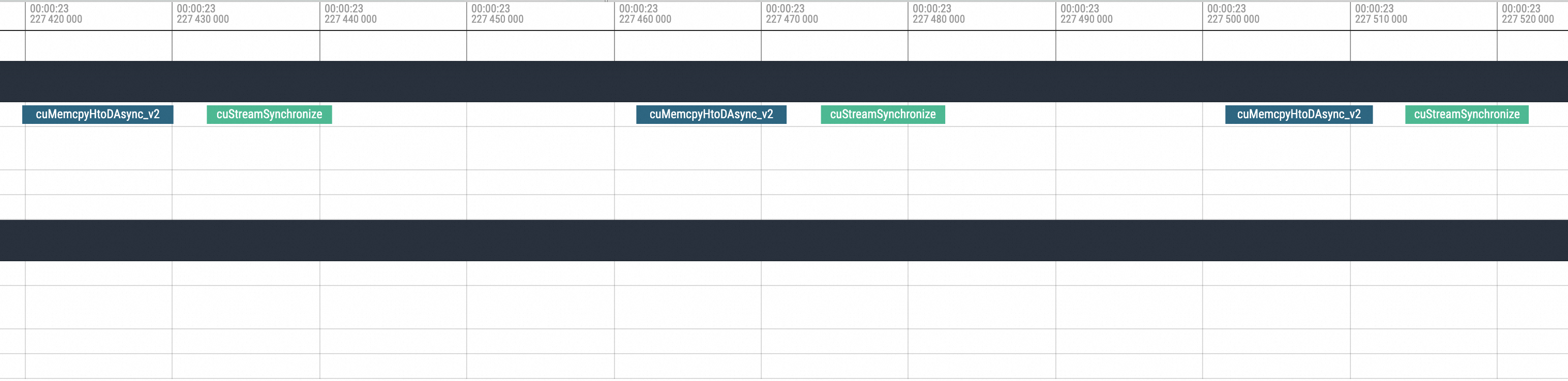
可以很明顯看到是cuMemcpyH2D的執行,執行完畢之後進程就Hang住了。接著拉到Hang恢複後的位置,如下圖所示:
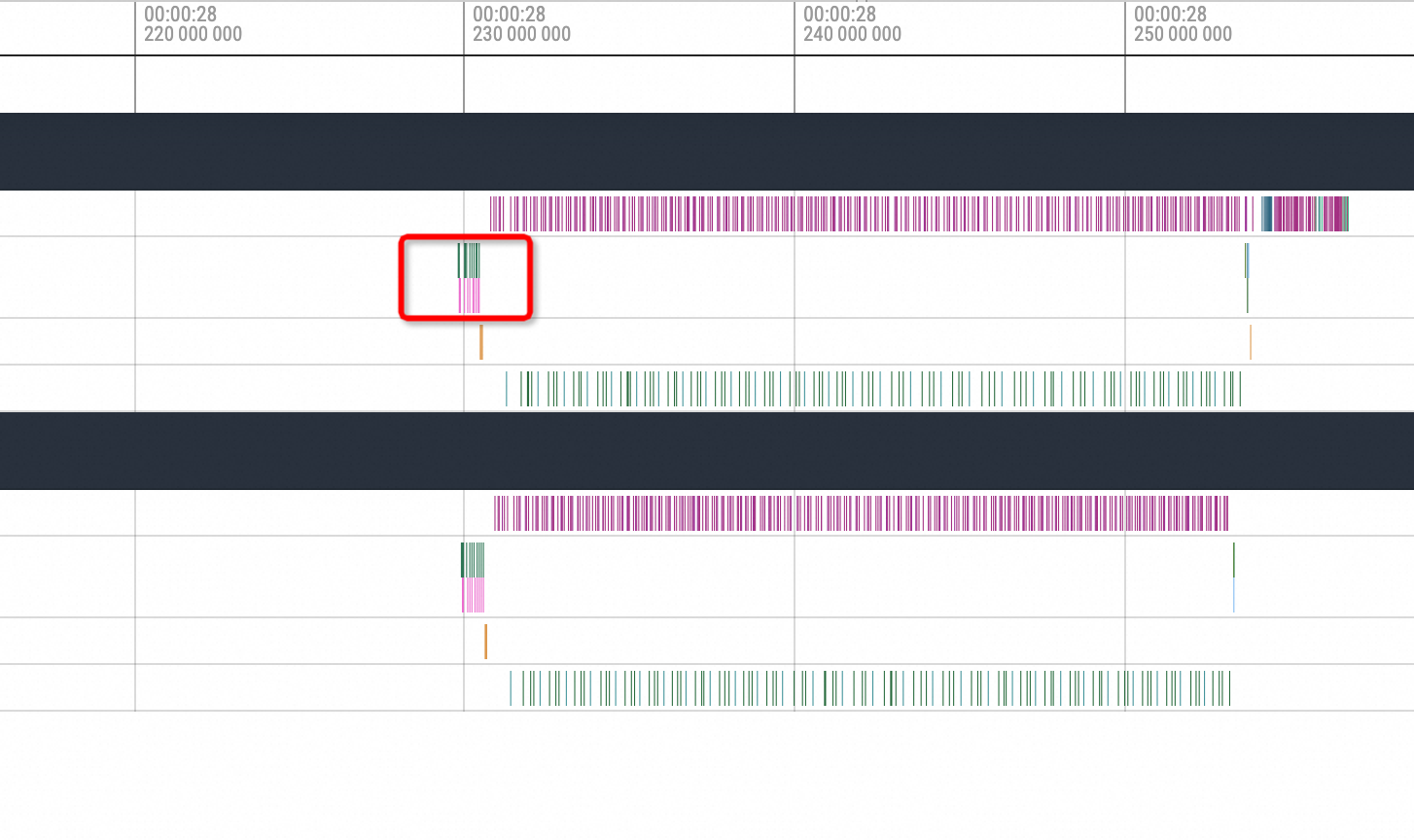
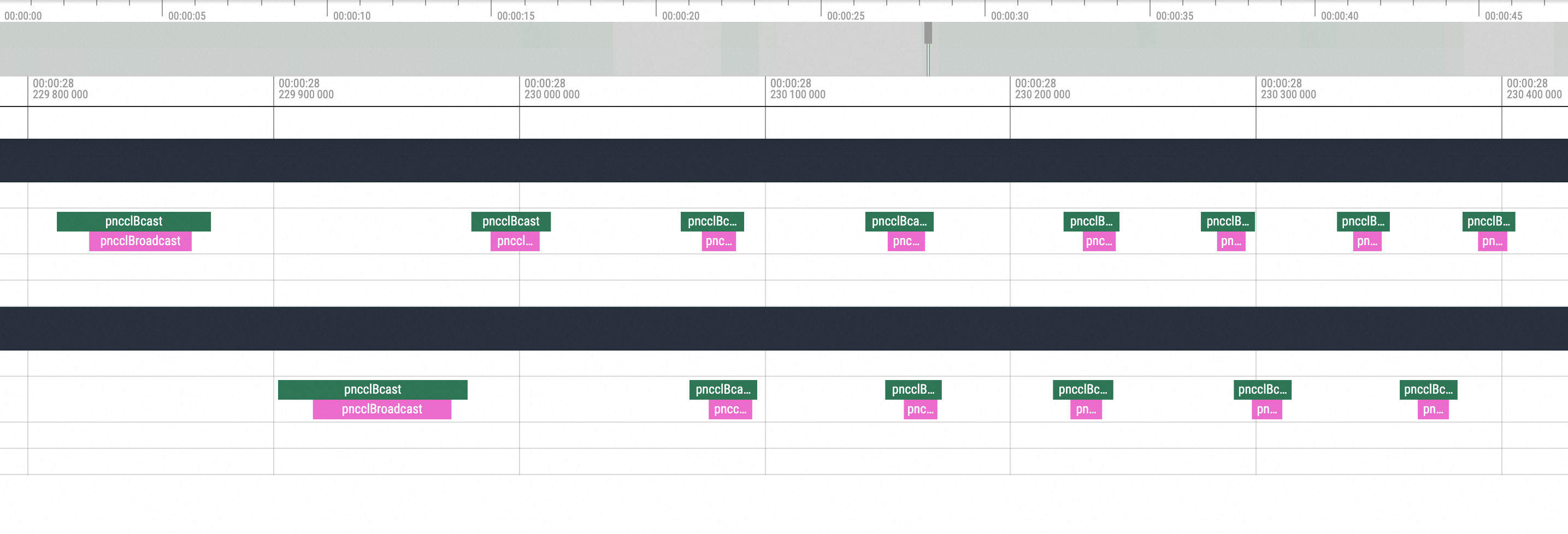
Zoom In到對應位置,可以看到Hang恢複後第一個執行的就是NCCL的broadcast動作,然後才進行後續的標準動作。所以由此現象也可以大致推斷為是NCCL Hang導致的問題。