本文介紹了PolarDB-X中DDL的執行邏輯和執行方式。
背景知識
PolarDB-X的架構如下:
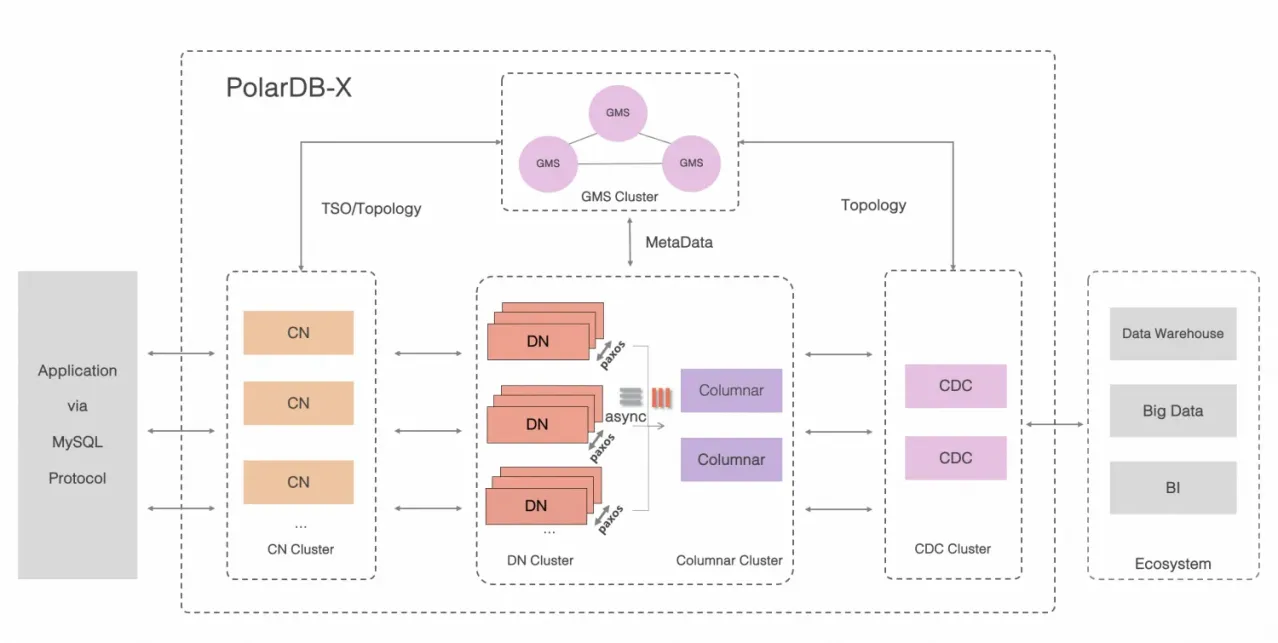
PolarDB-X在執行DDL時,幾乎各個組件都需要參與,以保證DDL的正確性。
中繼資料服務節點(GMS)維護了Table/Schema、Statistic等中繼資料資訊;
計算節點(CN)提供了分布式DDL執行、全域索引維護等能力;
儲存節點(DN)維護了所有Table/Schema的物理資料,並且具有DDL下推能力(例如ALTER TABLE等DDL操作的下推)。
為了便於說明,本文將使用者發送到PolarDB-X執行個體(由計算節點接收)的DDL稱為使用者DDL,而在使用者DDL執行過程中由計算節點下推發送到儲存節點的DDL稱為物理 DDL。
DDL執行方式
在PolarDB-X中,DDL按照執行方式主要分為兩類,物理執行的DDL和邏輯執行的DDL。
物理執行
物理執行的DDL指的是主要依賴儲存節點物理DDL下推能力完成的DDL。物理執行的DDL在執行過程中,計算節點僅維護中繼資料資訊的變化,真正的結構變更由儲存節點完成。例如Create Table、Drop Table、Create Local Index以及常用的Alter Table等。
原子性
在PolarDB-X中,一張邏輯表往往對應了多個物理表(分區),且這些分區往往分布在多個儲存節點中。在對一張邏輯表做DDL變更時,如果是物理執行方式,那麼計算節點會將使用者DDL先轉換為物理DDL,然後下推到相應的儲存節點執行,並且記錄各個分區的完成情況,在所有分區完成物理DDL變更後,計算節點再進行中繼資料的最終變更。
物理執行的DDL在執行過程中是可以並發的,因此在執行過程中,計算節點不僅會記錄各個分區的執行情況,還需要保證所有分區變更的原子性,確保所有分區可以一起完成變更,詳情請參見DDL原子性。
執行演算法
物理執行的DDL在執行過程中是否鎖表(允許並發DML)、是否需要重建表(期間長短)以及是否僅修改中繼資料(秒級完成)完全依賴儲存節點執行物理DDL的執行演算法。
儲存節點執行物理DDL的執行演算法主要有以下三種:
INSTANT演算法,僅需修改資料字典中的中繼資料,不需要修改或複製存量資料,也不需要重建物理表,物理DDL可以秒級完成;
INPLACE演算法,物理表中的資料需要複製和重建,但是複製和重建都在儲存引擎內部完成,通常允許並發讀寫訪問,對業務影響較小;
COPY演算法,需要將物理表中所有的資料複製到新表中,資料複製期間會阻塞所有寫操作(鎖表),對業務影響較大。
不同的DDL支援的執行演算法會有所不同,詳情請參見Online DDL。
邏輯執行
邏輯執行的DDL指的是主要依賴計算節點Online Schema Change能力完成的DDL。邏輯執行通常需要經歷建立新的暫存資料表,拷貝存量資料,同步增量資料,並進行中繼資料切換等步驟,一般執行時間較長,但是全程Online無需鎖表,例如:Create Global Index、Drop Global Index、Online Modify Column、Add Primary Key以及分區變更相關DDL等;也存在一些邏輯執行的DDL可以通過直接修改中繼資料並進行同步方式完成,例如:Rename Table、Rename Global Index等。
邏輯執行的DDL通常擁有以下幾個特點:
線上變更,無需鎖表,對使用者業務影響較小;
通常需要重建表,存在資料拷貝,執行時間相對較長;
保證原子性,不會出現部分分區執行成功,部分分區執行失敗的情況。
並行度調整
邏輯執行的DDL通常需要拷貝存量資料,這是一個耗時較長的過程,在計算節點和儲存節點不存在CPU、IO等瓶頸的情況下,可以調整存量資料回填的並行度以及資料回填的限速,來提升DDL執行效率。
例如,在建立全域二級索引的過程中,主表的存量資料需要回填到全域二級索引表中,如果計算節點和儲存節點的CPU、IO等資源都不存在瓶頸,可以調整資料回填的並行度以及資料回填的限速,來提升資料回填的速度。
-- 設定資料回填的全域並行度,預設值為32,根據經驗這個值一般無需調整
set global BACKFILL_PARALLELISM = 32;
-- 物理分區資料回填的並行度,預設值為4,物理分區資料量較大時推薦調整
set global PHYSICAL_TABLE_BACKFILL_PARALLELISM = 8;
-- 設定資料回填的限速,預設值為150000 rows/s
set global GSI_BACKFILL_SPEED_LIMITATION = 250000;由於不同的表結構、拓撲以及資料量都不盡相同,因此除了上面給出的參數外還有一些其他參數可以調整,詳情請參見並行DDL。
如何判斷DDL執行方式
在PolarDB-X中,可以通過explain語句來判斷DDL的執行方式。如果explain的結果與原本DDL語句類似,則為物理執行的DDL;如果explain的結果中包含類似Create Table語句,則為邏輯執行的DDL。
樣本
在PolarDB-X執行個體中,建立一張邏輯表t1,其結構如下:
+-------+--------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 |
+-------+--------------------------------------------------------------------------+使用EXPLAIN語句來判斷“給邏輯表t1添加一個局部索引”這個DDL操作是邏輯執行還是物理執行,其執行結果如下,可以看到,執行方式為物理執行。
explain alter table t1 add local index idx(b);
+----------------------------------------------------------------------------------+
| EXECUTION PLAN |
+----------------------------------------------------------------------------------+
| ALTER_TABLE( tables="t1", shardCount=16, sql="ALTER TABLE ? ADD INDEX idx (b)" ) |
| EXCLUDE_RESOURCE( wumu.t1, wumu.tg17 ) |
| SHARE_RESOURCE( wumu.t1, wumu.tg17 ) |
+----------------------------------------------------------------------------------+使用explain語句來判斷“將邏輯表t1的分區演算法修改為
partition by key(a)”這個DDL操作是邏輯執行還是物理執行,其執行結果如下,可以看到,執行方式為邏輯執行。
explain alter table t1 partition by key(a);
+----------------------------------------------------------------------------------+
| EXECUTION PLAN |
+----------------------------------------------------------------------------------+
| CREATE_TABLE( tables="t1_msfg", shardCount=16, sql="CREATE TABLE ? (
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`_drds_implicit_id_` bigint(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`_drds_implicit_id_`),
INDEX `auto_shard_key_a` USING BTREE(`a`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4" ) |
| DROP_TABLE( tables="t1_msfg", shardCount=16, sql="DROP TABLE IF EXISTS ?" ) |
| EXCLUDE_RESOURCE( wumu.t1, wumu.t1_msfg, wumu.tg17 ) |
| SHARE_RESOURCE( wumu.t1, wumu.t1_msfg, wumu.tg17 ) |
+-----------------------------------------------------------------------------------+如何非同步執行DDL
在PolarDB-X中,預設使用同步的方式執行DDL,與MySQL保持一致。在同步執行DDL時,在執行期間如果串連發生中斷可能導致DDL執行被暫停,如果預期DDL執行時間過長,可以考慮使用非同步方式執行DDL。
可以通過在要執行的DDL前添加hint的方式來開啟非同步執行DDL,樣本如下:
/*+TDDL:cmd_extra(PURE_ASYNC_DDL_MODE=true)*/ alter table t1 add global index gsi_a(a) partition by key(a);更多資訊,請參見DDL非同步執行文法擴充。