本文介紹了PolarDB-X中熱點散列的方法。
PolarDB-X作為分散式資料庫,對於分區表的各個分區會儘可能均衡的分布到不同的儲存節點,更好地利用上整體系統資源,避免出現單點效能。對於Range和List分區,分區資料是按照使用者的定義來劃分的,對於HASH策略的分區,PolarDB-X採用的是一致性HASH演算法,將分區鍵的值對應為一個具體的雜湊值,進而映射到分區所在的雜湊空間。對分區鍵分布均衡(例如分區鍵是主鍵),且採用的是HASH分區策略的資料表,PolarDB-X能保證各個分區的資料也是均衡的。反之,分區之間的資料可能就會與不均,甚至出現嚴重的資料熱點(資料扭曲)。
這裡以一張訂單表來闡述下HASH策略下的資料表是如何產生資料熱點(資料扭曲)的,該表的主鍵為自增的ID,表定義如下:
CREATE TABLE orders (
id int(11) NOT NULL AUTO_INCREMENT,
seller_id int(11) DEFAULT NULL,
PRIMARY KEY (id)
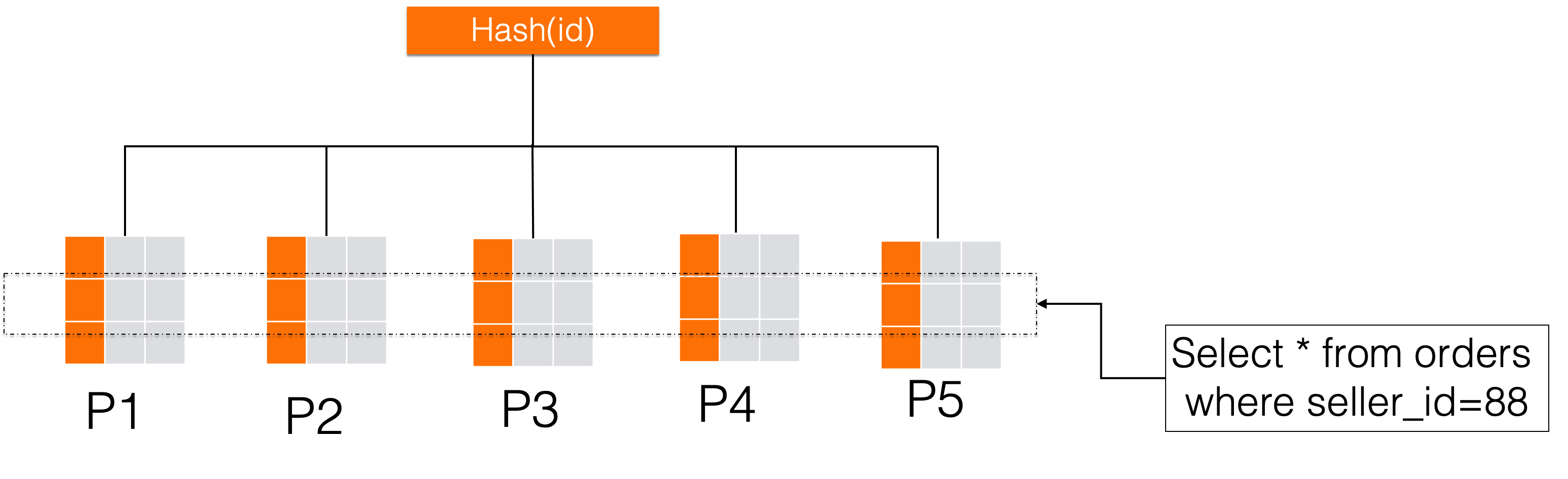
)對於這個訂單表來說,如果我們為了追求資料的分布的均勻性,拆分鍵選擇主鍵通過Hash的方式拆分,主鍵的具有唯一性,因為在PolarDB-X中,採取的是一致性Hash演算法,所以按主鍵hash之後資料一定會均勻在分布在各個分區中。但是對於業務來說,通常不是按一個自增id維度去查詢,業務更多的是需要頻繁的按照賣家維度查詢某賣家的資料,那麼如下圖所示,要查seller_id=88的資料,無法根據seller_id來做分區裁剪,就需要做一遍全分區掃描,這種查詢效率是極低的。
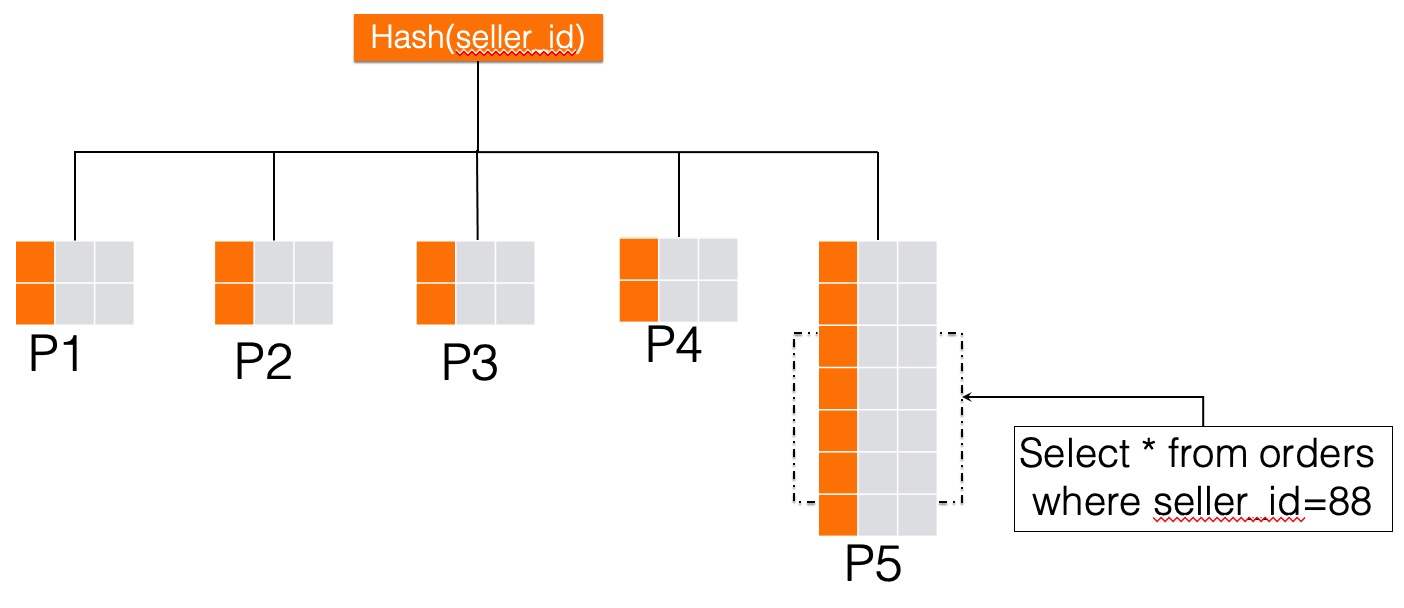
自然而然就想到更換一下我們的拆分鍵,採用seller_id通過Hash方式拆分,這種方式的好處是在按賣家維度查詢資料時,我們能在最佳化器中利用分區裁減技術,將大部分無關分區裁減掉,僅僅掃描部分分區就可以滿足業務的需求,如下圖所示。但是這種拆分方式按照賣家ID拆分,相同的賣家資料會分布到相同的分區,這就會導致大賣家所在的分區資料異常的大,資料扭曲嚴重,大賣家的資料都在一個分區(例如下圖中的P5),會導致這個分區出現嚴重的寫入熱點。
PolarDB-X是如何有效解決這類資料熱點問題的?
首先,新增一個列作為第二個拆分鍵。
alter table orders partition by key(seller_id,id) partitions 5這個拆分變更並沒有改變orders表的資料分布,沒有任何資料rehash,分區數還是5,將id作為第二個拆分鍵加進來了,僅僅修改表的分區中繼資料,代價是非常小的。此時的id列實際上並沒有參與具體的路由計算,僅僅是一個分區鍵的"預留位置"。
直觀的對比一下加入id拆分列前後orders表各個分區的hash空間情況:
增加拆分鍵前:

增加拆分鍵後:
當只有一個拆分鍵時若分區有資料熱點時,也就是大量的資料集中到一個具體的雜湊值,而不是一個範圍,無法進一步分裂。有兩個拆分鍵後,雜湊空間從一維變成了二維,這種轉換賦予了我們更多的靈活性,允許我們根據第二個拆分鍵去進一步地拆分那些資料作用區。在PolarDB-X中可以對熱點分區對熱點值按照第二個拆分鍵繼續拆分。例如對於上面例子中的orders表中seller_id=88的大賣家資料,目前都集中在P5分區,可以通過以下命令將其打散:
alter table orders split into H88_ partitions 2 by hot value(88)分裂後的效果如下圖所示:
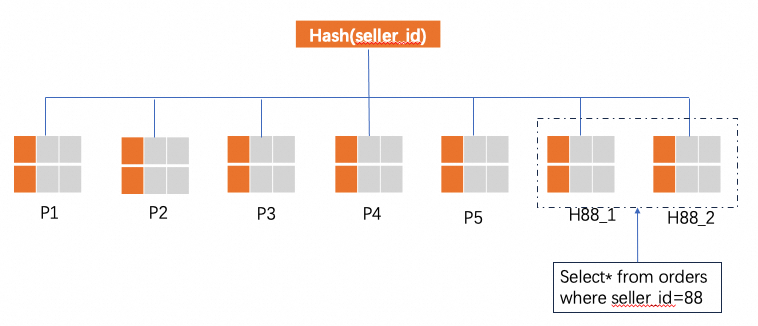
分裂的原理是對於seller_id=88的資料從P5中分裂出來並按照第二個拆分列id進一步分裂為N個分區,樣本中N=2,分裂成兩個分區H88_1和H88_2。
分裂前後非熱點資料(seller_id不等於88)並沒有發生變化,原來在P1的還在P1,在P2的還在P2,僅僅是影響到了熱點資料的,分裂前seller_id=88會自動路由到P5分區,分裂後路由到H88_1和H88_2。
限制
只有採用KEY分區策略的分區才能實現熱點散列(KEY分區是屬於HASH分區的一種)。