有層出不窮的演算法idea想要快速驗證?核心演算法模組如何快速複用到不同情境的不同模型中?如何通過排列組合構建出新的模型?組件化EasyRec架構可以協助你以“搭積木”的方式快速構建想要的模型結構,快來試一試吧!
限制說明
僅支援0.8.0或以上版本的組件化的EasyRec架構。
為何需要組件化
1. 靈活搭建模型,所思即所得
依靠動態可插拔的公用組件,以“搭積木”的方式快速構建想要的模型結構。架構提供了"膠水"文法,實現組件間的無縫銜接。
2. 實現組件複用,一次開發到處可用
很多模型之所以被稱之為一個新的模型,是因為引入了一個或多個特殊的子模組(組件),然而這些子模組並不僅只能用在該模型中,通過組合各個不同的子模組可以輕易組裝一個新的模型。
過去一個新開發的公用可選模組,比如Dense Feature Embedding Layer、SENet添加到現有模型中,需要修改所有模型的代碼才能用上新的特性,過程繁瑣易出錯。隨著模型數量和公用模組數量的增加,為所有模型整合所有公用可選模組將產生組合爆炸的不可控局面。
組件化實現了底層公用模組與上層模型的解耦。
3. 提高實驗迭代效率,好的想法值得快速驗證
為已有模型添加新特性將變得十分方便。開發一個新的模型,只需要實現特殊的新模組,其餘部分可以通過組件庫中的已有組件拼裝。
現在我們只需要為新的特徵開發一個Keras Layer類,並在指定package中添加import語句,架構就能自動識別並添加到組件庫中,不需要額外操作。新人不再需要熟悉EasyRec的方方面面就可以為架構添加功能,開發效率大大提高。
組件化的目標
不再需要實現新的模型,只需要實現新的組件! 模型通過組裝組件完成。
各個組件專註自身功能的實現,模組中代碼高度彙總,只負責一項任務,也就是常說的單一職責原則。
主幹網路
組件化EasyRec模型使用一個可配置的主幹網路作為核心組件。主幹網路是由多個組件塊組成的一個有向非循環圖(DAG),架構負責按照DAG的拓撲排序執行各組件塊關聯的代碼邏輯,構建TF Graph的一個子圖。DAG的輸出節點由concat_blocks配置項定義,各輸出組件塊的輸出tensor拼接之後輸入給一個可選的頂部MLP層,或者直接連結到最終的預測層。
案例1. Wide&Deep 模型
設定檔:wide_and_deep_backbone_on_movielens.config
model_config: {
model_name: "WideAndDeep"
model_class: "RankModel"
feature_groups: {
group_name: 'wide'
feature_names: 'user_id'
feature_names: 'movie_id'
feature_names: 'job_id'
feature_names: 'age'
feature_names: 'gender'
feature_names: 'year'
feature_names: 'genres'
wide_deep: WIDE
}
feature_groups: {
group_name: 'deep'
feature_names: 'user_id'
feature_names: 'movie_id'
feature_names: 'job_id'
feature_names: 'age'
feature_names: 'gender'
feature_names: 'year'
feature_names: 'genres'
wide_deep: DEEP
}
backbone {
blocks {
name: 'wide'
inputs {
feature_group_name: 'wide'
}
input_layer {
only_output_feature_list: true
wide_output_dim: 1
}
}
blocks {
name: 'deep_logit'
inputs {
feature_group_name: 'deep'
}
keras_layer {
class_name: 'MLP'
mlp {
hidden_units: [256, 256, 256, 1]
use_final_bn: false
final_activation: 'linear'
}
}
}
blocks {
name: 'final_logit'
inputs {
block_name: 'wide'
input_fn: 'lambda x: tf.add_n(x)'
}
inputs {
block_name: 'deep_logit'
}
merge_inputs_into_list: true
keras_layer {
class_name: 'Add'
}
}
concat_blocks: 'final_logit'
}
model_params {
l2_regularization: 1e-4
}
embedding_regularization: 1e-4
}MovieLens-1M資料集效果對比:
Model | Epoch | AUC |
Wide&Deep | 1 | 0.8558 |
Wide&Deep(Backbone) | 1 | 0.8854 |
備忘:通過組件化的方式搭建的模型效果比內建的模型效果更好是因為MLP組件有更好的初始化方法。
通過protobuf messagebackbone來定義主幹網路,主幹網路有多個積木塊(block)組成,每個block代表一個可複用的組件。
每個
block有一個唯一的名字(name),並且有一個或多個輸入和輸出。每個輸入只能是某個
feature group的name,或者另一個block的name,或者是一個block package的名字。當一個block有多個輸入時,會自動執行merge操作(輸入為list時自動合并,輸入為tensor時自動concat)。所有
block根據輸入與輸出的關係組成一個有向非循環圖(DAG),架構自動解析出DAG的拓撲關係,按照拓撲排序執行塊所關聯的模組。當
block有多個輸出時,返回一個python元組(tuple),下遊block可以配置input_slice通過python切片文法擷取到輸入元組的某個元素作為輸入,或者通過自訂的input_fn配置一個lambda運算式函數擷取元組的某個值。每個
block關聯的模組通常是一個keras layer對象,實現了一個可複用的子網路模組。架構支援載入自訂的keras layer,以及所有系統內建的keras layer。可以為
block關聯一個input_layer對輸入的feature group配置的特徵做一些額外的加工,比如執行batch normalization、layer normalization、feature dropout等操作,並且可以指定輸出的tensor的格式(2d、3d、list等)。注意:當block關聯的模組是input_layer時,必須設定feature_group_name為某個feature group的名字,當block關聯的模組不是input_layer時,block的name不可與某個feature group重名。還有一些特殊的
block關聯了一個特殊的模組,包括lambda layer、sequential layers、repeated layer和recurrent layer。這些特殊layer分別實現了自訂運算式、順序執行多個layer、重複執行某個layer、迴圈執行某個layer的功能。DAG的輸出節點名由
concat_blocks配置項指定,配置了多個輸出節點時自動執行tensor的concat操作。如果不配置
concat_blocks,架構會自動拼接DAG的所有葉子節點並輸出。可以為主幹網路設定一個可選的
MLP模組。
案例2:DeepFM 模型
設定檔:deepfm_backbone_on_movielens.config
這個Case重點關注下兩個特殊的block,一個使用了lambda運算式配置了一個自訂函數;另一個的載入了一個內建的keras layertf.keras.layers.Add。
model_config: {
model_name: 'DeepFM'
model_class: 'RankModel'
feature_groups: {
group_name: 'wide'
feature_names: 'user_id'
feature_names: 'movie_id'
feature_names: 'job_id'
feature_names: 'age'
feature_names: 'gender'
feature_names: 'year'
feature_names: 'genres'
wide_deep: WIDE
}
feature_groups: {
group_name: 'features'
feature_names: 'user_id'
feature_names: 'movie_id'
feature_names: 'job_id'
feature_names: 'age'
feature_names: 'gender'
feature_names: 'year'
feature_names: 'genres'
feature_names: 'title'
wide_deep: DEEP
}
backbone {
blocks {
name: 'wide_logit'
inputs {
feature_group_name: 'wide'
}
input_layer {
wide_output_dim: 1
}
}
blocks {
name: 'features'
inputs {
feature_group_name: 'features'
}
input_layer {
output_2d_tensor_and_feature_list: true
}
}
blocks {
name: 'fm'
inputs {
block_name: 'features'
input_slice: '[1]'
}
keras_layer {
class_name: 'FM'
}
}
blocks {
name: 'deep'
inputs {
block_name: 'features'
input_slice: '[0]'
}
keras_layer {
class_name: 'MLP'
mlp {
hidden_units: [256, 128, 64, 1]
use_final_bn: false
final_activation: 'linear'
}
}
}
blocks {
name: 'add'
inputs {
block_name: 'wide_logit'
input_fn: 'lambda x: tf.reduce_sum(x, axis=1, keepdims=True)'
}
inputs {
block_name: 'fm'
}
inputs {
block_name: 'deep'
}
merge_inputs_into_list: true
keras_layer {
class_name: 'Add'
}
}
concat_blocks: 'add'
}
model_params {
l2_regularization: 1e-4
}
embedding_regularization: 1e-4
}MovieLens-1M資料集效果對比:
Model | Epoch | AUC |
DeepFM | 1 | 0.8867 |
DeepFM(Backbone) | 1 | 0.8872 |
案例3:DCN 模型
設定檔:dcn_backbone_on_movielens.config
這個Case重點關注一個特殊的 DCNblock,用了recurrent layer實現了迴圈調用某個模組多次的效果。通過該Case還是在DAG之上添加了MLP模組。
model_config: {
model_name: 'DCN V2'
model_class: 'RankModel'
feature_groups: {
group_name: 'all'
feature_names: 'user_id'
feature_names: 'movie_id'
feature_names: 'job_id'
feature_names: 'age'
feature_names: 'gender'
feature_names: 'year'
feature_names: 'genres'
wide_deep: DEEP
}
backbone {
blocks {
name: "deep"
inputs {
feature_group_name: 'all'
}
keras_layer {
class_name: 'MLP'
mlp {
hidden_units: [256, 128, 64]
}
}
}
blocks {
name: "dcn"
inputs {
feature_group_name: 'all'
input_fn: 'lambda x: [x, x]'
}
recurrent {
num_steps: 3
fixed_input_index: 0
keras_layer {
class_name: 'Cross'
}
}
}
concat_blocks: ['deep', 'dcn']
top_mlp {
hidden_units: [64, 32, 16]
}
}
model_params {
l2_regularization: 1e-4
}
embedding_regularization: 1e-4
}上述配置對CrossLayer迴圈調用了3次,邏輯上等價於執行如下語句:
x1 = Cross()(x0, x0)
x2 = Cross()(x0, x1)
x3 = Cross()(x0, x2)MovieLens-1M資料集效果對比:
Model | Epoch | AUC |
DCN (內建) | 1 | 0.8576 |
DCN_v2 (backbone) | 1 | 0.8770 |
備忘:新實現的Cross組件對應了參數量更多的v2版本的DCN,而內建的DCN模型對應了v1版本的DCN。
案例4:DLRM 模型
設定檔:dlrm_backbone_on_criteo.config
model_config: {
model_name: 'DLRM'
model_class: 'RankModel'
feature_groups: {
group_name: "dense"
feature_names: "F1"
feature_names: "F2"
...
wide_deep:DEEP
}
feature_groups: {
group_name: "sparse"
feature_names: "C1"
feature_names: "C2"
feature_names: "C3"
...
wide_deep:DEEP
}
backbone {
blocks {
name: 'bottom_mlp'
inputs {
feature_group_name: 'dense'
}
keras_layer {
class_name: 'MLP'
mlp {
hidden_units: [64, 32, 16]
}
}
}
blocks {
name: 'sparse'
inputs {
feature_group_name: 'sparse'
}
input_layer {
output_2d_tensor_and_feature_list: true
}
}
blocks {
name: 'dot'
inputs {
block_name: 'bottom_mlp'
}
inputs {
block_name: 'sparse'
input_slice: '[1]'
}
keras_layer {
class_name: 'DotInteraction'
}
}
blocks {
name: 'sparse_2d'
inputs {
block_name: 'sparse'
input_slice: '[0]'
}
}
concat_blocks: ['sparse_2d', 'dot']
top_mlp {
hidden_units: [256, 128, 64]
}
}
model_params {
l2_regularization: 1e-5
}
embedding_regularization: 1e-5
}Criteo資料集效果對比:
Model | Epoch | AUC |
DLRM | 1 | 0.79785 |
DLRM (backbone) | 1 | 0.7993 |
備忘:DotInteraction是新開發的特徵兩兩交叉做內積運算的模組。
這個案例中'dot' block的第一個輸入是一個tensor,第二個輸入是一個list,這種情況下第一個輸入會插入到list中,合并成一個更大的list,作為block的輸入。
案例5:為 DLRM 模型添加一個新的數值特徵Embedding組件
設定檔:dlrm_on_criteo_with_periodic.config
與上一個案例相比,多了一個PeriodicEmbeddingLayer,組件化編程的靈活性與可擴充性由此可見一斑。
重點關注一下PeriodicEmbeddingLayer的參數配置方式,這裡並沒有使用自訂protobuf message的傳參方式,而是採用了內建的google.protobuf.Struct對象作為自訂Layer的參數。實際上,該自訂Layer也支援通過自訂message傳參。架構提供了一個通用的ParameterAPI 用通用的方式處理兩種傳參方式。
model_config: {
model_class: 'RankModel'
feature_groups: {
group_name: "dense"
feature_names: "F1"
feature_names: "F2"
...
wide_deep:DEEP
}
feature_groups: {
group_name: "sparse"
feature_names: "C1"
feature_names: "C2"
...
wide_deep:DEEP
}
backbone {
blocks {
name: 'num_emb'
inputs {
feature_group_name: 'dense'
}
keras_layer {
class_name: 'PeriodicEmbedding'
st_params {
fields {
key: "output_tensor_list"
value { bool_value: true }
}
fields {
key: "embedding_dim"
value { number_value: 16 }
}
fields {
key: "sigma"
value { number_value: 0.005 }
}
}
}
}
blocks {
name: 'sparse'
inputs {
feature_group_name: 'sparse'
}
input_layer {
output_2d_tensor_and_feature_list: true
}
}
blocks {
name: 'dot'
inputs {
block_name: 'num_emb'
input_slice: '[1]'
}
inputs {
block_name: 'sparse'
input_slice: '[1]'
}
keras_layer {
class_name: 'DotInteraction'
}
}
blocks {
name: 'sparse_2d'
inputs {
block_name: 'sparse'
input_slice: '[0]'
}
}
blocks {
name: 'num_emb_2d'
inputs {
block_name: 'num_emb'
input_slice: '[0]'
}
}
concat_blocks: ['num_emb_2d', 'dot', 'sparse_2d']
top_mlp {
hidden_units: [256, 128, 64]
}
}
model_params {
l2_regularization: 1e-5
}
embedding_regularization: 1e-5
}Criteo資料集效果對比:
Model | Epoch | AUC |
DLRM | 1 | 0.79785 |
DLRM (backbone) | 1 | 0.7993 |
DLRM (periodic) | 1 | 0.7998 |
案例6:使用內建的keras layer搭建DNN模型
該案例只是為了示範EasyRec可以使用TF內建的原子粒度的keras layer作為萬用群組件,實際上我們已經有了一個自訂的MLP組件,使用起來會更加方便。
該案例重點關注一個特殊的sequential block,這個組件塊內可以定義多個串聯在一起的layers,前一個layer的輸出作為後一個layer的輸入。相比定義多個普通block的方式,sequential block會更加方便。
備忘:調用系統內建的keras layer,只能通過google.proto.Struct的格式傳參。
model_config: {
model_class: "RankModel"
feature_groups: {
group_name: 'features'
feature_names: 'user_id'
feature_names: 'movie_id'
feature_names: 'job_id'
feature_names: 'age'
feature_names: 'gender'
feature_names: 'year'
feature_names: 'genres'
wide_deep: DEEP
}
backbone {
blocks {
name: 'mlp'
inputs {
feature_group_name: 'features'
}
layers {
keras_layer {
class_name: 'Dense'
st_params {
fields {
key: 'units'
value: { number_value: 256 }
}
fields {
key: 'activation'
value: { string_value: 'relu' }
}
}
}
}
layers {
keras_layer {
class_name: 'Dropout'
st_params {
fields {
key: 'rate'
value: { number_value: 0.5 }
}
}
}
}
layers {
keras_layer {
class_name: 'Dense'
st_params {
fields {
key: 'units'
value: { number_value: 256 }
}
fields {
key: 'activation'
value: { string_value: 'relu' }
}
}
}
}
layers {
keras_layer {
class_name: 'Dropout'
st_params {
fields {
key: 'rate'
value: { number_value: 0.5 }
}
}
}
}
layers {
keras_layer {
class_name: 'Dense'
st_params {
fields {
key: 'units'
value: { number_value: 1 }
}
}
}
}
}
concat_blocks: 'mlp'
}
model_params {
l2_regularization: 1e-4
}
embedding_regularization: 1e-4
}MovieLens-1M資料集效果:
Model | Epoch | AUC |
MLP | 1 | 0.8616 |
案例7:對比學習(使用組件包)
設定檔:contrastive_learning_on_movielens.config
該案例為了示範block package的使用,block package可以打包一組block,構成一個可被複用的子網路,即被打包的子網路以共用參數的方式在同一個模型中調用多次。與之相反,沒有打包的block是不能被多次調用的(但是可以多次複用結果)。
block package主要為自監督學習、對比學習等情境設計。
model_config: {
model_name: "ContrastiveLearning"
model_class: "RankModel"
feature_groups: {
group_name: 'user'
feature_names: 'user_id'
feature_names: 'job_id'
feature_names: 'age'
feature_names: 'gender'
wide_deep: DEEP
}
feature_groups: {
group_name: 'item'
feature_names: 'movie_id'
feature_names: 'year'
feature_names: 'genres'
wide_deep: DEEP
}
backbone {
blocks {
name: 'user_tower'
inputs {
feature_group_name: 'user'
}
keras_layer {
class_name: 'MLP'
mlp {
hidden_units: [256, 128]
}
}
}
packages {
name: 'item_tower'
blocks {
name: 'item'
inputs {
feature_group_name: 'item'
}
input_layer {
dropout_rate: 0.2
}
}
blocks {
name: 'item_encoder'
inputs {
block_name: 'item'
}
keras_layer {
class_name: 'MLP'
mlp {
hidden_units: [256, 128]
}
}
}
}
blocks {
name: 'contrastive_learning'
inputs {
package_name: 'item_tower'
}
inputs {
package_name: 'item_tower'
}
merge_inputs_into_list: true
keras_layer {
class_name: 'AuxiliaryLoss'
st_params {
fields {
key: 'loss_type'
value: { string_value: 'info_nce' }
}
fields {
key: 'loss_weight'
value: { number_value: 0.1 }
}
fields {
key: 'temperature'
value: { number_value: 0.2 }
}
}
}
}
blocks {
name: 'top_mlp'
inputs {
block_name: 'contrastive_learning'
ignore_input: true
}
inputs {
block_name: 'user_tower'
}
inputs {
package_name: 'item_tower'
reset_input {}
}
keras_layer {
class_name: 'MLP'
mlp {
hidden_units: [128, 64]
}
}
}
concat_blocks: 'top_mlp'
}
model_params {
l2_regularization: 1e-4
}
embedding_regularization: 1e-4
}AuxiliaryLoss是用來計算對比學習損失的layer,詳見'組件詳細參數'。
額外的input配置:
ignore_input: true 表示忽略當前這路的輸入;添加該路輸入只是為了控制拓撲結構的執行順序
reset_input: 重設本次
package調用時input_layer的配置項;可以配置與package定義時不同的參數
注意這個案例沒有為名為item_tower的package配置concat_blocks,架構會自動化佈建為DAG的葉子節點。
在當前案例中,item_tower被調用了3次,前2次調用時輸入層dropout配置生效,用於計算對比學習損失函數;最後1次調用時重設了輸入層配置,不執行dropout。 主模型的item_tower與對比學習輔助任務中的item_tower共用參數;輔助任務中的item_tower通過對輸入特徵embedding做dropout來產生augmented sample;主模型的item_tower不執行資料增強操作。
MovieLens-1M資料集效果:
Model | Epoch | AUC |
MultiTower | 1 | 0.8814 |
ContrastiveLearning | 1 | 0.8728 |
一個更複雜一點的對比學習模型案例:CL4SRec
案例8:多目標模型 MMoE
多目標模型的model_class一般配置為"MultiTaskModel",並且需要在model_params裡配置多個目標對應的Tower。model_name為任意自訂字串,僅有注釋作用。
model_config {
model_name: "MMoE"
model_class: "MultiTaskModel"
feature_groups {
group_name: "all"
feature_names: "user_id"
feature_names: "cms_segid"
...
feature_names: "tag_brand_list"
wide_deep: DEEP
}
backbone {
blocks {
name: 'all'
inputs {
feature_group_name: 'all'
}
input_layer {
only_output_feature_list: true
}
}
blocks {
name: "senet"
inputs {
block_name: "all"
}
keras_layer {
class_name: 'SENet'
senet {
reduction_ratio: 4
}
}
}
blocks {
name: "mmoe"
inputs {
block_name: "senet"
}
keras_layer {
class_name: 'MMoE'
mmoe {
num_task: 2
num_expert: 3
expert_mlp {
hidden_units: [256, 128]
}
}
}
}
}
model_params {
task_towers {
tower_name: "ctr"
label_name: "clk"
dnn {
hidden_units: [128, 64]
}
num_class: 1
weight: 1.0
loss_type: CLASSIFICATION
metrics_set: {
auc {}
}
}
task_towers {
tower_name: "cvr"
label_name: "buy"
dnn {
hidden_units: [128, 64]
}
num_class: 1
weight: 1.0
loss_type: CLASSIFICATION
metrics_set: {
auc {}
}
}
l2_regularization: 1e-06
}
embedding_regularization: 5e-05
}注意這個案例沒有為backbone配置concat_blocks,架構會自動化佈建為DAG的葉子節點。
案例9:多目標模型 DBMTL
多目標模型的model_class一般配置為"MultiTaskModel",並且需要在model_params裡配置多個目標對應的Tower。model_name為任意自訂字串,僅有注釋作用。
model_config {
model_name: "DBMTL"
model_class: "MultiTaskModel"
feature_groups {
group_name: "all"
feature_names: "user_id"
feature_names: "cms_segid"
...
feature_names: "tag_brand_list"
wide_deep: DEEP
}
backbone {
blocks {
name: "mask_net"
inputs {
feature_group_name: "all"
}
keras_layer {
class_name: 'MaskNet'
masknet {
mask_blocks {
aggregation_size: 512
output_size: 256
}
mask_blocks {
aggregation_size: 512
output_size: 256
}
mask_blocks {
aggregation_size: 512
output_size: 256
}
mlp {
hidden_units: [512, 256]
}
}
}
}
}
model_params {
task_towers {
tower_name: "ctr"
label_name: "clk"
loss_type: CLASSIFICATION
metrics_set: {
auc {}
}
dnn {
hidden_units: [256, 128, 64]
}
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
task_towers {
tower_name: "cvr"
label_name: "buy"
loss_type: CLASSIFICATION
metrics_set: {
auc {}
}
dnn {
hidden_units: [256, 128, 64]
}
relation_tower_names: ["ctr"]
relation_dnn {
hidden_units: [32]
}
weight: 1.0
}
l2_regularization: 1e-6
}
embedding_regularization: 5e-6
}DBMTL模型需要在model_params裡為每個子任務的Tower配置relation_dnn,同時還需要通relation_tower_names配置任務間的依賴關係。
這個案例同樣沒有為backbone配置concat_blocks,架構會自動化佈建為DAG的葉子節點。
案例10:MaskNet + PPNet + MMoE
model_config: {
model_name: 'MaskNet + PPNet + MMoE'
model_class: 'RankModel'
feature_groups: {
group_name: 'memorize'
feature_names: 'user_id'
feature_names: 'adgroup_id'
feature_names: 'pid'
wide_deep: DEEP
}
feature_groups: {
group_name: 'general'
feature_names: 'age_level'
feature_names: 'shopping_level'
...
wide_deep: DEEP
}
backbone {
blocks {
name: "mask_net"
inputs {
feature_group_name: "general"
}
repeat {
num_repeat: 3
keras_layer {
class_name: "MaskBlock"
mask_block {
output_size: 512
aggregation_size: 1024
}
}
}
}
blocks {
name: "ppnet"
inputs {
block_name: "mask_net"
}
inputs {
feature_group_name: "memorize"
}
merge_inputs_into_list: true
repeat {
num_repeat: 3
input_fn: "lambda x, i: [x[0][i], x[1]]"
keras_layer {
class_name: "PPNet"
ppnet {
mlp {
hidden_units: [256, 128, 64]
}
gate_params {
output_dim: 512
}
mode: "eager"
full_gate_input: false
}
}
}
}
blocks {
name: "mmoe"
inputs {
block_name: "ppnet"
}
inputs {
feature_group_name: "general"
}
keras_layer {
class_name: "MMoE"
mmoe {
num_task: 2
num_expert: 3
}
}
}
}
model_params {
l2_regularization: 0.0
task_towers {
tower_name: "ctr"
label_name: "is_click"
metrics_set {
auc {
num_thresholds: 20000
}
}
loss_type: CLASSIFICATION
num_class: 1
dnn {
hidden_units: 64
hidden_units: 32
}
weight: 1.0
}
task_towers {
tower_name: "cvr"
label_name: "is_train"
metrics_set {
auc {
num_thresholds: 20000
}
}
loss_type: CLASSIFICATION
num_class: 1
dnn {
hidden_units: 64
hidden_units: 32
}
weight: 1.0
}
}
}該案例體現了如何應用重複的群組件塊。
更多案例
兩個新的模型:
FiBiNet模型設定檔:fibinet_on_movielens.config
MaskNet模型設定檔:masknet_on_movielens.config
MovieLens-1M資料集效果:
Model | Epoch | AUC |
MaskNet | 1 | 0.8872 |
FibiNet | 1 | 0.8893 |
序列模型:
DIN模型設定檔:DIN_backbone.config
BST模型設定檔:BST_backbone.config
CL4SRec模型:CL4SRec
其他模型:
Highway Network:Highway Network
Cross Decoupling Network:CDN
DLRM+SENet:dlrm_senet_on_criteo.config
組件庫介紹
1.基礎組件
類名 | 功能 | 說明 | 樣本 |
MLP | 多層感知機 | 可定製啟用函數、initializer、Dropout、BN等 | |
Highway | 類似殘差連結 | 可用來對預訓練embedding做增量微調 | |
Gate | 門控 | 多個輸入的加權求和 | |
PeriodicEmbedding | 周期啟用函數 | 數值特徵Embedding | |
AutoDisEmbedding | 自動離散化 | 數值特徵Embedding |
備忘:Gate組件的第一個輸入是權重向量,後面的輸入拼湊成一個列表,權重向量的長度應等於列表的長度
2.特徵交叉組件
類名 | 功能 | 說明 | 樣本 |
FM | 二階交叉 | DeepFM模型的組件 | |
DotInteraction | 二階內積交叉 | DLRM模型的組件 | |
Cross | bit-wise交叉 | DCN v2模型的組件 | |
BiLinear | 雙線性 | FiBiNet模型的組件 | |
FiBiNet | SENet & BiLinear | FiBiNet模型 |
3.特徵重要度學習組件
類名 | 功能 | 說明 | 樣本 |
SENet | 建模特徵重要度 | FiBiNet模型的組件 | |
MaskBlock | 建模特徵重要度 | MaskNet模型的組件 | |
MaskNet | 多個串列或並行的MaskBlock | MaskNet模型 | |
PPNet | 參數個人化網路 | PPNet模型 |
4. 序列特徵編碼組件
類名 | 功能 | 說明 | 樣本 |
DIN | target attention | DIN模型的組件 | |
BST | transformer | BST模型的組件 | |
SeqAugment | 序列資料增強 | crop, mask, reorder |
5. 多目標學習組件
類名 | 功能 | 說明 | 樣本 |
MMoE | Multiple Mixture of Experts | MMoE模型的組件 |
6. 輔助損失函數組件
類名 | 功能 | 說明 | 樣本 |
AuxiliaryLoss | 用來計算輔助損失函數 | 常用在自監督學習中 |
各組件的詳細參數請查看“組件詳細參數”。
如何自訂群組件
在easy_rec/python/layers/keras目錄下建立一個py檔案,也可直接添加到一個已有的檔案中。我們建議目標類似的組件定義在同一個檔案中,減少檔案數量;比如特徵交叉的組件都放在interaction.py裡。
定義一個繼承tf.keras.layers.Layer的組件類,至少實現兩個方法:__init__、call。
def __init__(self, params, name='xxx', reuse=None, **kwargs):
pass
def call(self, inputs, training=None, **kwargs):
pass__init__方法的第一個參數params接收架構傳遞給當前組件的參數。支援兩種參數配置的方式:google.protobuf.Struct、自訂的protobuf message對象。params對象封裝了對這兩種格式的參數的統一讀取介面,如下:
檢查必傳參數,缺失時報錯退出:
params.check_required(['embedding_dim', 'sigma'])用點操作符讀取參數:
sigma = params.sigma;支援連續點操作符,如params.a.b:注意數值型參數的類型,
Struct只支援float類型,整型需要強制轉換:embedding_dim = int(params.embedding_dim)數群組類型也需要強制類型轉換:
units = list(params.hidden_units)指定預設值讀取,傳回值會被強制轉換為與預設值同類型:
activation = params.get_or_default('activation', 'relu')支援嵌套子結構的預設值讀取:
params.field.get_or_default('key', def_val)判斷某個參數是否存在:
params.has_field(key)【不建議,會限定傳參方式】擷取自訂的proto對象:
params.get_pb_config()讀寫
l2_regularizer屬性:params.l2_regularizer,傳給Dense層或dense函數。
【可選】如需要自訂protobuf message參數,先在easy_rec/python/protos/layer.proto添加參數message的定義, 再把參數註冊到定義在easy_rec/python/protos/keras_layer.proto的KerasLayer.params訊息體中。
__init__方法的reuse參數表示該Layer對象的權重參數是否需要被複用。開發時需要按照可複用的邏輯來實現Layer對象,推薦嚴格按照keras layer的規範來實現。 盡量在__init__方法中聲明需要依賴的keras layer對象;僅在必要時才使用tf.layers.*函數,且需要傳遞reuse參數。
提示:實現Layer對象時盡量使用原生的 tf.keras.layers.* 對象,且全部在 __init__ 方法中預先聲明好。
call方法用來實現主要的模組邏輯,其inputs參數可以是一個tenor,或者是一個tensor列表。可選的training參數用來標識當前是否是訓練模型。
最後也是最重要的一點,新開發的Layer需要在easy_rec.python.layers.keras.__init__.py檔案中匯出才能被架構識別為組件庫中的一員。例如要匯出blocks.py檔案中的MLP類,則需要添加:from .blocks import MLP。
FM layer的程式碼範例:
class FM(tf.keras.layers.Layer):
"""Factorization Machine models pairwise (order-2) feature interactions without linear term and bias.
References
- [Factorization Machines](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
Input shape.
- List of 2D tensor with shape: ``(batch_size,embedding_size)``.
- Or a 3D tensor with shape: ``(batch_size,field_size,embedding_size)``
Output shape
- 2D tensor with shape: ``(batch_size, 1)``.
"""
def __init__(self, params, name='fm', reuse=None, **kwargs):
super(FM, self).__init__(name, **kwargs)
self.reuse = reuse
self.use_variant = params.get_or_default('use_variant', False)
def call(self, inputs, **kwargs):
if type(inputs) == list:
emb_dims = set(map(lambda x: int(x.shape[-1]), inputs))
if len(emb_dims) != 1:
dims = ','.join([str(d) for d in emb_dims])
raise ValueError('all embedding dim must be equal in FM layer:' + dims)
with tf.name_scope(self.name):
fea = tf.stack(inputs, axis=1)
else:
assert inputs.shape.ndims == 3, 'input of FM layer must be a 3D tensor or a list of 2D tensors'
fea = inputs
with tf.name_scope(self.name):
square_of_sum = tf.square(tf.reduce_sum(fea, axis=1))
sum_of_square = tf.reduce_sum(tf.square(fea), axis=1)
cross_term = tf.subtract(square_of_sum, sum_of_square)
if self.use_variant:
cross_term = 0.5 * cross_term
else:
cross_term = 0.5 * tf.reduce_sum(cross_term, axis=-1, keepdims=True)
return cross_term如何搭建模型
組件塊和組件包是搭建主幹網路的核心組件,本小節將會介紹組件塊的類型、功能和配置參數;同時還會介紹專門為參數共用子網路設計的組件包。
通過組件塊和組件包搭建模型的配置方法請參考上文描述的各個案例。
組件塊的protobuf定義如下:
message Block {
required string name = 1;
// the input names of feature groups or other blocks
repeated Input inputs = 2;
optional int32 input_concat_axis = 3 [default = -1];
optional bool merge_inputs_into_list = 4;
optional string extra_input_fn = 5;
// sequential layers
repeated Layer layers = 6;
// only take effect when there are no layers
oneof layer {
InputLayer input_layer = 101;
Lambda lambda = 102;
KerasLayer keras_layer = 103;
RecurrentLayer recurrent = 104;
RepeatLayer repeat = 105;
}
}組件塊會自動合并多個輸入:
若多路輸入中某一路的輸入類型是
list,則最終結果被Merge成一個大的list,保持順序不變;若多路輸入中的每一路輸入都是tensor,預設是執行輸入tensors按照最後一個維度做拼接(concat),以下配置項可以改變預設行為:
input_concat_axis用來指定輸入tensors拼接的維度merge_inputs_into_list設為true,則把輸入合并到一個列表裡,不做concat操作
message Input {
oneof name {
string feature_group_name = 1;
string block_name = 2;
string package_name = 3;
}
optional string input_fn = 11;
optional string input_slice = 12;
}每一路輸入可以配置一個可選的
input_fn,指定一個lambda函數對輸入做一些簡單的變換。比如配置input_fn: 'lambda x: [x]'可以把輸入變成列表格式。input_slice可以用來擷取輸入元組/列表的某個切片。比如,當某路輸入是一個列表對象是,可以用input_slice: '[1]'配置項擷取列表的第二個元素值作為這一路的輸入。extra_input_fn是一個可選的配置項,用來對合并後的多路輸入結果做一些額外的變換,需要配置成lambda函數的格式。
目前總共有7種類型的組件塊,分別是空組件塊、輸入組件塊、Lambda組件塊、KerasLayer組件塊、迴圈組件塊、重複的群組件塊、序列組件塊。
1. 空組件塊
當一個block不配置任何layer時就稱之為空組件塊,空組件塊只執行多路輸入的Merge操作。
2. 輸入組件塊
輸入組件塊關聯一個input_layer,擷取、加工並返回原始的特徵輸入。
輸入組件塊比較特殊,它只能有且只有一路輸入,並且只能用feature_group_name項配置輸入為一個feature_group的name。
輸入組件塊有一個特權:它的名字可以與其輸入的feature_group同名。其他組件塊則無此殊榮。
配置樣本:
blocks {
name: 'all'
inputs {
feature_group_name: 'all'
}
input_layer {
only_output_feature_list: true
}
}InputLayer可以通過配置擷取不同格式的輸入,並且可以執行一些如dropout之類的額外操作,其參數定義的protobuf如下:
message InputLayer {
optional bool do_batch_norm = 1;
optional bool do_layer_norm = 2;
optional float dropout_rate = 3;
optional float feature_dropout_rate = 4;
optional bool only_output_feature_list = 5;
optional bool only_output_3d_tensor = 6;
optional bool output_2d_tensor_and_feature_list = 7;
optional bool output_seq_and_normal_feature = 8;
}輸入層的定義如上,配置下說明如下:
do_batch_norm是否對輸入特徵做batch normalizationdo_layer_norm是否對輸入特徵做layer normalizationdropout_rate輸入層執行dropout的機率,預設不執行dropoutfeature_dropout_rate對特徵整體執行dropout的機率,預設不執行only_output_feature_list輸出list格式的各個特徵only_output_3d_tensor輸出feature group對應的一個3d tensor,在embedding_dim相同時可配置該項output_2d_tensor_and_feature_list是否同時輸出2d tensor與特徵listoutput_seq_and_normal_feature是否輸出(sequence特徵, 常規特徵)元組
3. Lambda組件塊
Lambda組件塊可以配置一個lambda函數,執行一些較簡單的操作。樣本如下:
blocks {
name: 'wide_logit'
inputs {
feature_group_name: 'wide'
}
lambda {
expression: 'lambda x: tf.reduce_sum(x, axis=1, keepdims=True)'
}
}4. KerasLayer組件塊
KerasLayer組件塊是最核心的組件塊,負責載入、動作項目代碼邏輯。
class_name是要載入的Keras Layer的類名,支援載入自訂的類和系統內建的Layer類。st_params是以google.protobuf.Struct對象格式配置的參數;還可以用自訂的protobuf message的格式傳遞參數給載入的Layer對象。
配置樣本:
keras_layer {
class_name: 'MLP'
mlp {
hidden_units: [64, 32, 16]
}
}
keras_layer {
class_name: 'Dropout'
st_params {
fields {
key: 'rate'
value: { number_value: 0.5 }
}
}
}5. 迴圈組件塊
迴圈組件塊可以實作類別似RNN的迴圈調用結構,可以執行某個Layer多次,每次執行的輸入包含了上一次執行的輸出。在DCN網路中有迴圈組件塊的樣本,如下:
recurrent {
num_steps: 3
fixed_input_index: 0
keras_layer {
class_name: 'Cross'
}
}上述配置對CrossLayer迴圈調用了3次,邏輯上等價於執行如下語句:
x1 = Cross()(x0, x0)
x2 = Cross()(x0, x1)
x3 = Cross()(x0, x2)num_steps配置迴圈執行的次數fixed_input_index配置每次執行的多路輸入組成的列表中固定不變的元素;比如上述樣本中的x0keras_layer配置需要執行的組件
6. 重複的群組件塊
重複的群組件塊可以使用相同的輸入重複執行某個組件多次,實現multi-head的邏輯。樣本如下:
repeat {
num_repeat: 2
keras_layer {
class_name: "MaskBlock"
mask_block {
output_size: 512
aggregation_size: 2048
input_layer_norm: false
}
}
}num_repeat配置重複執行的次數output_concat_axis配置多次執行結果tensors的拼接維度,若不配置則輸出多次執行結果的列表keras_layer配置需要執行的組件input_slice配置每個動作項目的輸入切片,例如[i]擷取輸入列表的第 i 個元素作為第 i 次重複執行時的輸入;不配置時擷取所有輸入input_fn配置每個動作項目的輸入函數,例如input_fn: "lambda x, i: [x[0][i], x[1]]"
重複的群組件塊的使用案例MaskNet+PPNet+MMoE。
7. 序列組件塊
序列組件塊可以依次執行配置的多個Layer,前一個Layer的輸出是後一個Layer的輸入。序列組件塊相對於配置多個首尾相連的普通組件塊要更加簡單。樣本如下:
blocks {
name: 'mlp'
inputs {
feature_group_name: 'features'
}
layers {
keras_layer {
class_name: 'Dense'
st_params {
fields {
key: 'units'
value: { number_value: 256 }
}
fields {
key: 'activation'
value: { string_value: 'relu' }
}
}
}
}
layers {
keras_layer {
class_name: 'Dropout'
st_params {
fields {
key: 'rate'
value: { number_value: 0.5 }
}
}
}
}
layers {
keras_layer {
class_name: 'Dense'
st_params {
fields {
key: 'units'
value: { number_value: 1 }
}
}
}
}
}通過組件包實現參數共用的子網路
組件包封裝了由多個組件塊搭建的一個子網路DAG,作為整體可以被以參數共用的方式多次調用,通常用在自監督學習模型中。
組件包的protobuf訊息定義如下:
message BlockPackage {
// package name
required string name = 1;
// a few blocks generating a DAG
repeated Block blocks = 2;
// the names of output blocks
repeated string concat_blocks = 3;
}組件塊通過package_name參數配置一路輸入來調用組件包。
一個使用組件包來實現對比學習的案例如下:
model_config {
model_class: "RankModel"
feature_groups {
group_name: "all"
feature_names: "adgroup_id"
feature_names: "user"
...
feature_names: "pid"
wide_deep: DEEP
}
backbone {
packages {
name: 'feature_encoder'
blocks {
name: "fea_dropout"
inputs {
feature_group_name: "all"
}
input_layer {
dropout_rate: 0.5
only_output_3d_tensor: true
}
}
blocks {
name: "encode"
inputs {
block_name: "fea_dropout"
}
layers {
keras_layer {
class_name: 'BSTCTR'
bst {
hidden_size: 128
num_attention_heads: 4
num_hidden_layers: 3
intermediate_size: 128
hidden_act: 'gelu'
max_position_embeddings: 50
hidden_dropout_prob: 0.1
attention_probs_dropout_prob: 0
}
}
}
layers {
keras_layer {
class_name: 'Dense'
st_params {
fields {
key: 'units'
value: { number_value: 128 }
}
fields {
key: 'kernel_initializer'
value: { string_value: 'zeros' }
}
}
}
}
}
}
blocks {
name: "all"
inputs {
name: "all"
}
input_layer {
only_output_3d_tensor: true
}
}
blocks {
name: "loss_ctr"
merge_inputs_into_list: true
inputs {
package_name: 'feature_encoder'
}
inputs {
package_name: 'feature_encoder'
}
inputs {
package_name: 'all'
}
keras_layer {
class_name: 'LOSSCTR'
st_params{
fields {
key: 'cl_weight'
value: { number_value: 1 }
}
fields {
key: 'au_weight'
value: { number_value: 0.01 }
}
}
}
}
}
model_params {
l2_regularization: 1e-5
}
embedding_regularization: 1e-5
}真實案例
在工業級推薦系統中,物品獲得的使用者反饋行為通常遵循長尾分布,少量頭部物品獲得了絕大部分的使用者行為(點擊、收藏、轉化等),剩餘的大量中長尾物品獲得的反饋資料卻很少。基於長尾分布的使用者行為日誌訓練的推薦模型會越來越偏好頭部物品,這在導致“富者越富”的同時傷害中長尾物品的曝光機會和使用者滿意度。
我們在業務效果最佳化的過程中,觀察到如下現象:
召回擴量(增加召回數量或新的召回類型)很多時候不能帶來總體大盤指標的提升;
召回結果過濾掉“精品池”之外的物品通常能夠帶來效果指標的提升;
添加粗排模型,粗排覆蓋率指標提升,但不一定能帶來總體業務指標的提升;
本質上,越能夠保持“獨立同分布”假設的最佳化越能夠帶來大盤指標的提升,而越偏離“獨立同分布”假設的最佳化通常都不能帶來理想的效果。這裡的“獨立同分布”假設是指精排模型的訓練集資料和測試集資料(通常是生產環境獲得的截斷後的召回或粗排結果)應遵循同一資料分布。精排模型是在高度傾斜的長尾行為資料上訓練出來的,因而會在頭部物品上產生“過擬合”現象,而在中長尾物品上產生“欠擬合”現象。
“精品池”過濾進一步強化了召回的物品滿足行為的長尾分布,匹配精排模型的“獨立同分布”要求,最終也帶來了業務指標的提升;
召回擴量、添加粗排模型是在讓長尾分布變得平滑,試圖增加中長尾物品的數量,偏離了精排模型的“獨立同分布”要求,最終往往無法達成期望的效果提升。
通過分析精排模型的特徵重要度,我們發現重要度較高的特徵主要集中在少量的“記憶性”特徵上,而大量的中長尾特徵的重要度都很低。“記憶性”特徵指的是沒有泛化能力的特徵,如物品ID、使用者對物品ID在過去一段時間上的行為統計,在這些特徵上無法學到能夠遷移到其他物品的知識。常規的模型結構會產生特徵重要度的長尾分布,最終帶來了模型偏好物品的長尾分布。
基於以上分析,亟需設計一種更加合理的模型結構,讓模型能夠在“記憶”能力之外學習到更多“泛化”能力。Cross Decoupling Network (CDN) 為上述問題提出了一個可行的解決方案,它引入一個基於物品分布的門控機制,讓頭部的物品主要擬合“記憶特徵”,中長尾物品主要擬合“泛化特徵”。通過加權求和的方式在各個特徵上學習到的表徵特徵,再去擬合最終的營運目標。
我們在一個真實的業務情境設計了如下圖的模型結構,並基於組件化EasyRec輕鬆搭建了模型。
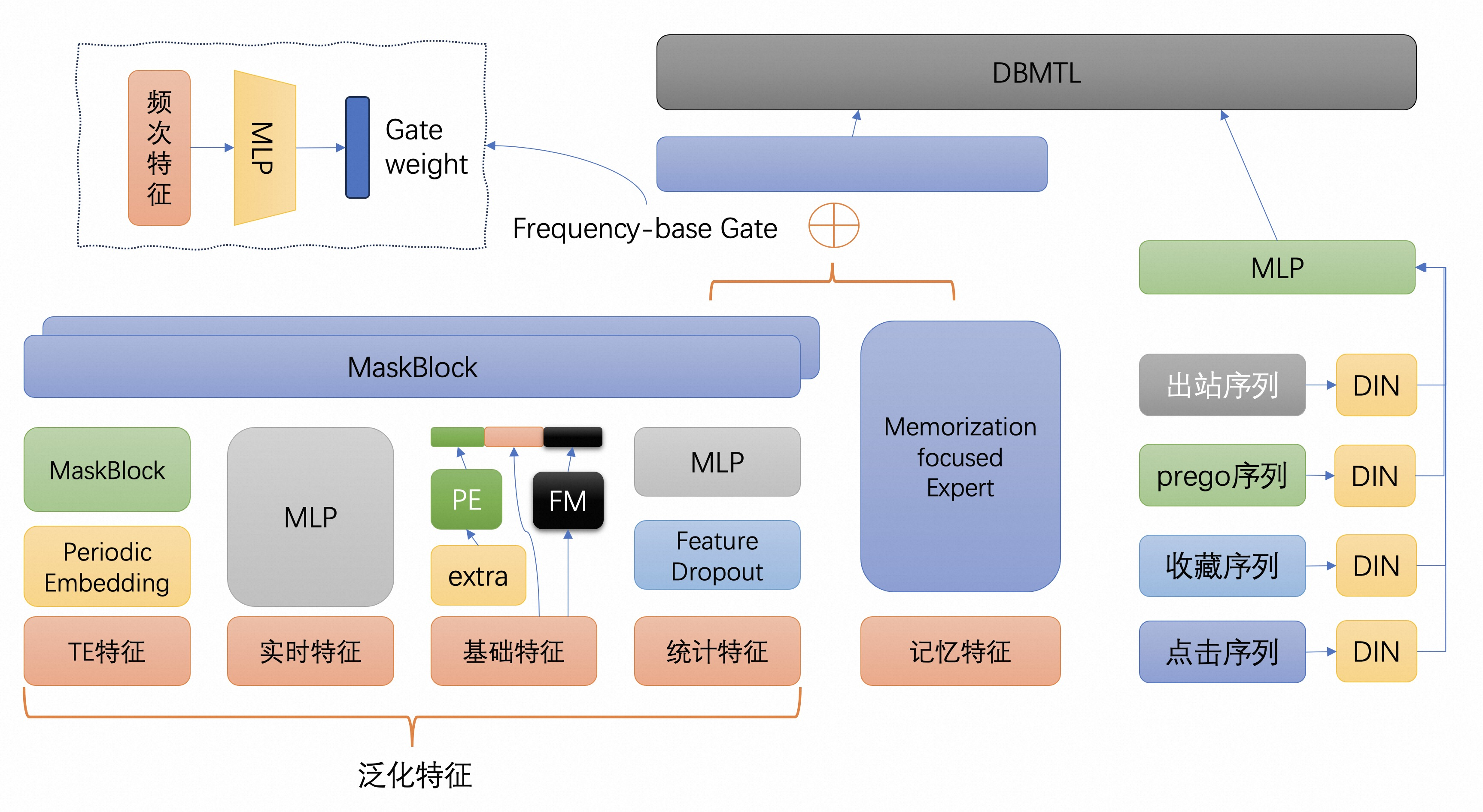
該案例的配置請查看文檔:基於組件化EasyRec搭建深度推薦演算法模型
組件化EasyRec詳細使用文檔:https://easyrec.readthedocs.io/en/latest/component/backbone.html