DataWorks Notebook 提供一個互動式、模組化的資料分析與開發環境。您可以使用 Python、SQL 和 Markdown 儲存格,串連 MaxCompute、EMR、AnalyticDB 等多種計算引擎,實現從資料處理、探索性分析、可視化到模型開發的全鏈路任務。本文檔將指導您如何高效使用 Notebook 完成資料開發與調度任務。
快速入門:5分鐘運行您的第一個Notebook
本節將引導您完成一個最簡流程:建立一個 Notebook,使用 Python 傳遞參數給 SQL,並查詢 MaxCompute 表資料。
開始前,請確保您已滿足以下條件:
當前工作空間已開通並使用新版資料開發(Data Studio)。
已建立Serverless 資源群組。Notebook在生產環境運行需要依賴Serverless資源群組。
已建立個人開發環境執行個體。如果您使用包含Python儲存格的Notebook,在開發環境調試運行時需要依賴個人開發環境執行個體。
如果您尚未建立,請參見建立個人開發環境執行個體。
操作步驟:
建立 Notebook 節點
進入 Data Studio,在資料開發的專案目錄下,建立 Notebook 節點。
為 Notebook 命名(例如
hello_notebook)並提交。
選擇個人開發環境
在頂部導航處單擊個人開發環境,從下拉式清單中選擇您已建立的個人開發環境執行個體。
編寫 Python 儲存格以定義參數
添加一個Python儲存格,並輸入以下代碼。此步驟定義一個城市變數,用於後續的 SQL 查詢。
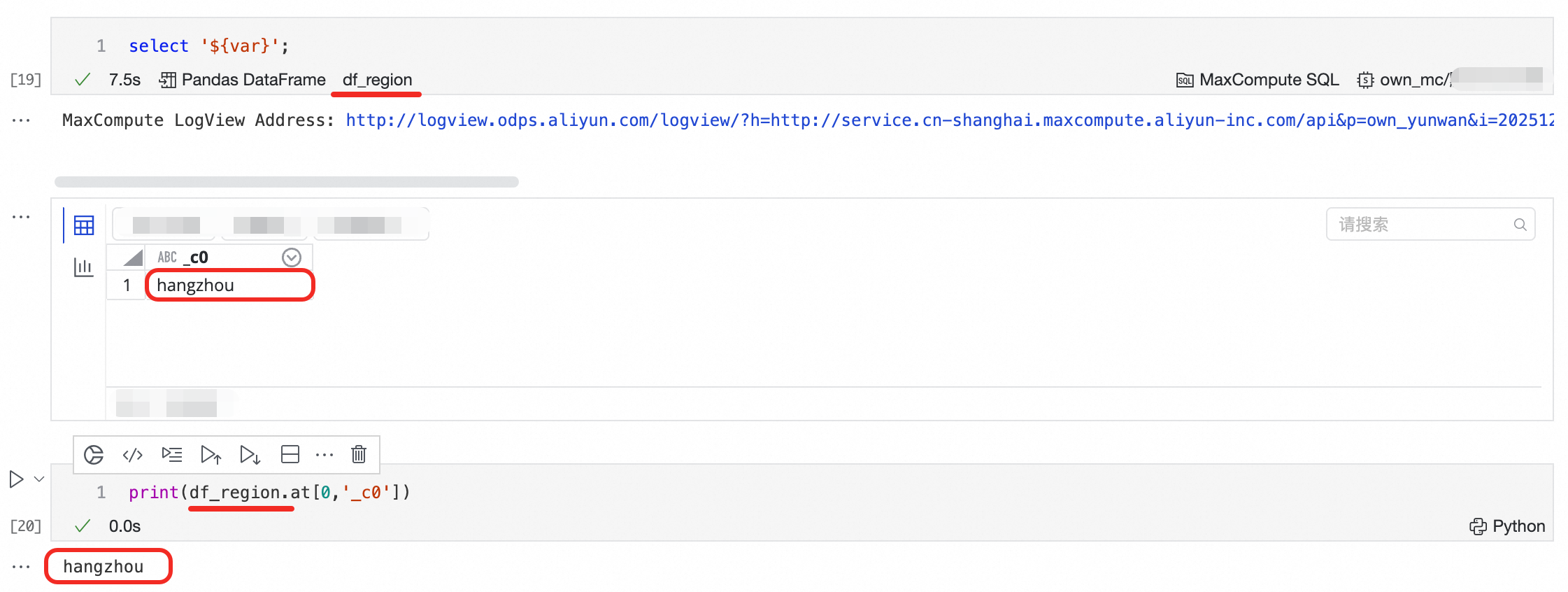
# 定義一個變數,用於後續SQL查詢 city = 'Beijing' print(f"已定義城市變數 city = {city}")編寫 SQL 儲存格以查詢資料
在第一個儲存格下方,新增一個 SQL 儲存格。
在儲存格右下角,將 SQL 類型切換為
MaxCompute SQL。輸入以下 SQL 代碼。代碼通過
${city}文法引用了上一步 Python 儲存格中定義的city變數。-- 使用Python中定義的變數進行查詢 SELECT '${city}' AS city;
運行並查看結果
單擊 Notebook 上方工具列的全部運行按鈕。
觀察每個儲存格的運行情況:
Python 儲存格下方會輸出
已定義城市變數 city = Beijing。SQL 儲存格下方會顯示查詢結果的表格。
至此,您已成功建立並運行一個包含 Python 和 SQL 互動的 Notebook。
核心概念
理解以下核心概念,是確保 Notebook 在開發和生產環境中行為一致的關鍵。
Notebook 模式
DataWorks Notebook 支援兩種使用模式:
純SQL和Markdown模式:僅包含 SQL 和 Markdown 儲存格,適用於純資料查詢和文檔編寫情境。此模式下,無論是開發環境還是生產環境,都僅需 Serverless 資源群組即可運行,不依賴個人開發環境執行個體。預設情況下為此模式,Notebook右上方顯示為SQL核心。
完整模式(Python + SQL + Markdown):支援 Python、SQL 和 Markdown 儲存格的混合使用,適用於需要資料處理、分析和可視化的複雜情境。在開發環境調試運行時,需要依賴個人開發環境執行個體來執行 Python 代碼。請您選擇個人開發環境後,Notebook右上方將顯示為
 (Python版本僅供參考)。
(Python版本僅供參考)。
開發環境 vs. 生產環境
對比項 | 開發環境 | 生產環境 |
運行載體 | 個人開發環境執行個體 | 調度配置中指定的資源群組和鏡像 |
核心差異 | 對於包含 Python 儲存格的 Notebook,使用個人獨佔的開發執行個體,您可以在其中自由安裝 Python 庫進行調試。 對於僅包含 SQL 和 Markdown 儲存格的 Notebook,僅需 Serverless 資源群組即可運行。 | 無論是通過營運中心周期性調度,還是在 Data Studio 中手動觸發工作流程運行,任務都會在調度配置中指定的資源群組上運行。其環境(如依賴庫、網路等)完全由您選擇的鏡像和資源群組配置決定。 |
如何保障一致 | 如果您在個人開發環境執行個體中通過 pip install 等方式進行了Python包的安裝,為確保生產環境具備與開發環境相同的依賴,您需將個人開發環境製作DataWorks鏡像,並在調度配置中選用該自訂鏡像。 重要 網路連通情況說明:個人開發環境不綁定VPC時,預設綁定一個頻寬有限的隨機公網IP,可直接連通公網;但發布至生產環境的Notebook節點網路是跟隨調度配置裡配置的資源群組。建議在個人開發環境中綁定調度配置的資源群組,此時兩者環境保持網路一致。 | |
計算資源與核心
在 DataWorks Notebook 中,代碼的執行由計算資源和核心兩個核心概念共同決定。
計算資源:計算資源是負責最終執行和處理資料任務的後端計算引擎。它定義了任務啟動並執行環境、計算能力和所遵循的執行邏輯。
定義:一個獨立的、可被調度的計算服務執行個體。例如:MaxCompute 專案、EMR Serverless Spark 叢集等。
作用:為 SQL 查詢、Spark 作業等提供實際的算力。
選擇:您需要在執行任務時,明確將其綁定到一個具體的計算資源上。
核心:核心是 Notebook 環境中負責解析並執行使用者在代碼儲存格內所編寫代碼的組件。它決定了該儲存格接受的程式設計語言。
Python 核心:
功能:執行 Python 語言編寫的代碼,支援資料處理、演算法實現、任務調度等複雜邏輯。
互動模式:在 Python 核心中,可以通過
Magic Command(如%sql) 或 SDK 庫,將封裝好的計算任務(如一段 SQL 陳述式)提交給指定的計算資源執行,並能擷取其返回結果用於進一步分析。
SQL 核心:
功能:直接解釋和提交 SQL 語言編寫的查詢。
互動模式:使用 SQL 核心時,它將 SQL 陳述式直接轉寄給使用者為該儲存格指定的後端計算資源(例如 EMR Spark SQL 或 MaxCompute SQL Session)來執行。
Markdown 核心:
功能:用於渲染 Markdown 格式的富文字文件,不執行任何計算邏輯。
關係總結:
核心是前端的語言解譯器,決定“寫什麼”(Python 或 SQL)。
計算資源是後端的執行引擎,決定代碼“在哪裡運行”(在 MaxCompute 還是 Spark 上)。
目錄類型與適用情境
您建立 Notebook 的位置決定其協作模式、許可權和發布流程。
目錄類型 | 適用情境 | 協作與發布 |
專案目錄 | 團隊協作與周期性生產任務。此目錄下的節點是工作空間共用的,遵循標準的開發、提交、發布流程。 | 允許多人協作開發。節點需要發布到生產環境,才能被周期性調度。 |
個人目錄 | 個人開發與調試。此目錄對其他工作空間成員不可見,用於存放個人指令碼和臨時任務。 | 僅自己可見。若要被調度,需先提交到專案目錄,再進行發布。 |
開發與調試 Notebook
Data Studio預設不自動儲存,建議您開發過程及時手動儲存,避免丟失代碼。您也可在Data Studio的編輯器設定 > Files: Auto Save中,設定為自動儲存。
若運行過程中卡頓或長時間無反應,可點擊上方工具列的重啟按鈕重啟Notebook核心。
儲存格管理
添加儲存格:將滑鼠移至上方在現有儲存格的上方或下方邊緣,單擊出現的+ SQL等按鈕。也可以使用頂部工具列的按鈕。
切換儲存格類型:單擊儲存格右下角的類型標識(如
Python),在彈出的菜單中選擇新的類型,如SQL、Markdown。切換類型時,儲存格內的代碼內容會保留,您需要手動修改以適應新類型。移動儲存格:將滑鼠移至上方在儲存格左側的藍色豎線上,按住並拖動即可調整順序。
運行儲存格:
運行單個:單擊儲存格左側的運行按鈕。
運行全部:單擊 Notebook 頂部工具列的全部運行按鈕。
參數傳遞
Python 變數傳遞至 SQL
在 Python 儲存格中定義的變數,可以在後續的 SQL 儲存格中通過 ${變數名} 的格式直接引用。
樣本:
Python 儲存格
table_name = "dwd_user_info_d" limit_num = 10SQL 儲存格
SELECT * FROM ${table_name} LIMIT ${limit_num};
SQL 結果傳遞至 Python
當一個 SQL 儲存格執行SELECT 查詢後,其結果會自動產生一個 DataFrame 變數,可供後續的 Python 儲存格使用。
若存在多個SQL語句,僅會將最後一條SQL語句的結果存入DataFrame變數。
變數命名:預設變數名為
df_開頭,您可以單擊 SQL 儲存格左下角的變數名進行重新命名。變數類型:
若支援多種變數類型,點擊左下角DataFrame也切換類型。
對於 MaxCompute SQL,支援
Pandas DataFrame和MaxCompute MaxFrame對象。對於ADB Spark SQL,支援
Pandas DataFrame和PySpark MaxFrame對象。對於其他 SQL 類型,產生的是
Pandas DataFrame對象。
樣本:
Copilot 輔助編程
DataWorks Copilot 是內建的智能編程助手,可以協助您產生和解釋代碼。
喚起方式:
在選擇的儲存格左上方單擊 Copilot
 表徵圖。
表徵圖。在SQL儲存格內右鍵,選擇 Copilot。
使用快速鍵
Cmd+I(Mac) 或Ctrl+I(Windows)。
調度與發布 Notebook
為了讓 Notebook 能夠按計劃周期性運行,您需要進行調度配置並將其發布到生產環境。
1、配置調度參數(參數化調度)
如需每次調度運行時,Notebook 中的參數能動態變化(例如,按天處理不同分區的資料),可以設定參數化調度。
標記參數儲存格: 在包含核心參數定義的 Python 儲存格中,單擊右上方的
...菜單,選擇 Mark Cell as Parameters。該儲存格會被添加一個parameters標籤,表明它是調度任務的參數入口。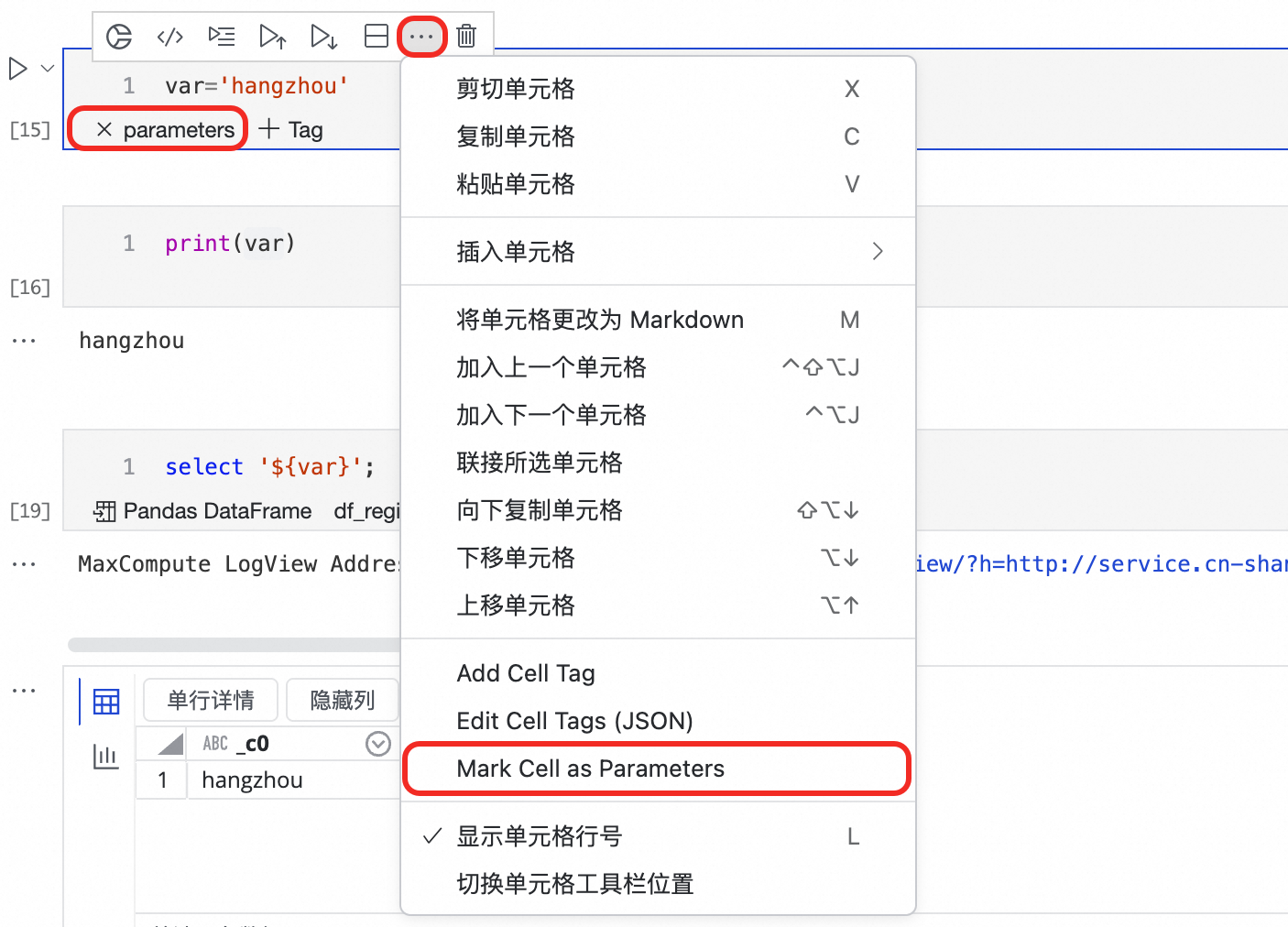
配置調度參數:
在 Notebook 右側面板,單擊調度配置。
在調度參數地區,為您在代碼中定義的變數(如
var)賦值。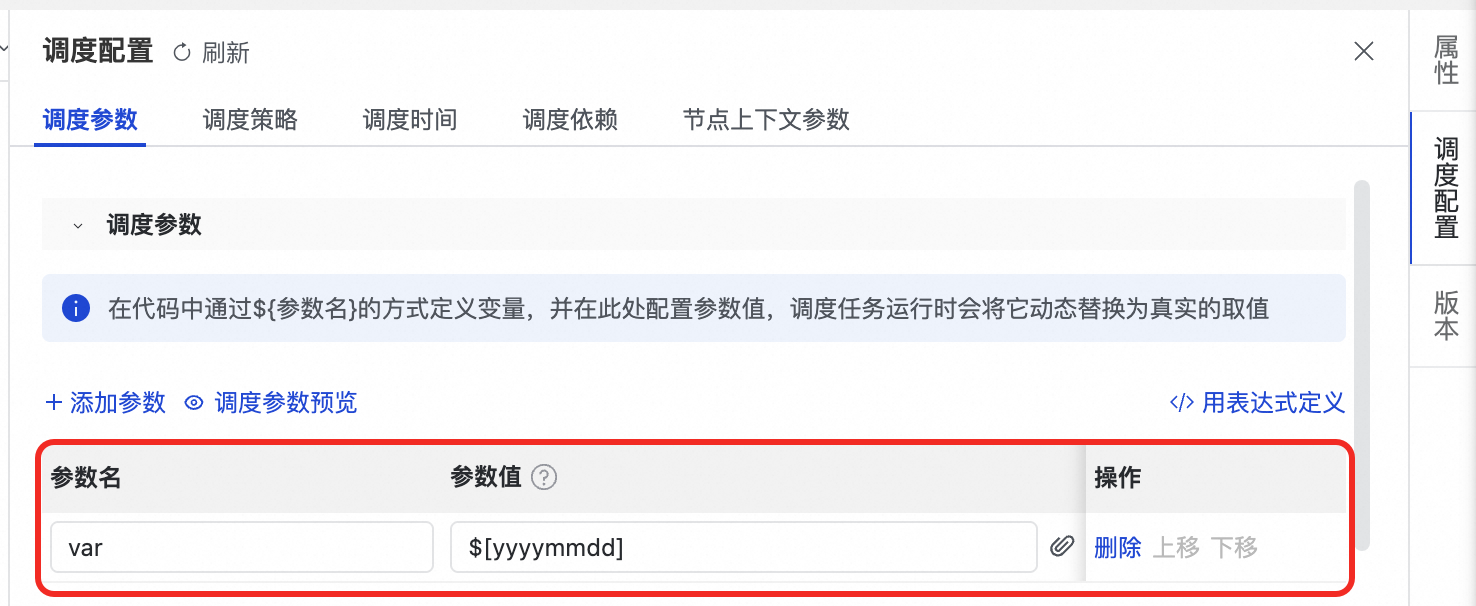
當任務被調度系統自動執行時,代碼中 var 參數的實際值,將由在調度參數中配置的值動態替換。
2、配置運行環境與資源
配置鏡像:在調度配置中,選擇一個包含 Notebook 運行所需全部依賴的鏡像。這是確保生產環境成功啟動並執行關鍵。
重要如果您在個人開發環境執行個體中通過 pip install 等方式進行了Python包的安裝,為確保生產環境具備與開發環境相同的依賴,您需將個人開發環境製作DataWorks鏡像,並在調度配置中選用該自訂鏡像。
配置資源群組:選擇用於執行任務的資源群組。對於 Serverless 資源群組,建議配置不超過
16CU,以避免因資源不足導致任務啟動失敗。單個任務最大支援64CU。配置關聯角色:如需進行細粒度的許可權管控,可以為節點關聯一個特定的 RAM角色,使其以該角色的身份運行。詳情請參見配置節點關聯角色。
3、發布節點
只有專案目錄下的節點才能被發布和周期性調度。
對於專案目錄下的 Notebook:完成配置後,單擊頂部工具列的發布按鈕。
對於個人目錄下的 Notebook:需先單擊儲存按鈕,將其提交到專案目錄,然後再執行發佈動作。
發布成功後,您可以在營運中心的周期任務頁面監控和管理您的 Notebook 任務。
常見問題
Q:為什麼My Code在開發時能訪問公網,但調度運行時卻失敗了?
A:這是因為開發環境和生產環境的網路原則不同。
開發環境 (個人開發環境):為了方便調試,個人開發環境執行個體在未設定VPC的情況下,預設會提供有限的公網訪問能力,讓您可以臨時安裝包或調用API。
生產環境 (周期調度任務): 出於安全和穩定考慮,預設在專用網路中運行,不能直接存取公網。任務的網路設定由您在調度配置中選擇的資源群組決定。如果該資源群組所在VPC沒有配置NAT Gateway,則無法訪問公網。
解決方案: 確保個人開發環境執行個體和Serverless資源群組設定相同的VPC專用網路。
Q:為什麼My Code在開發環境時成功運行,但調度運行時卻找不到三方包?
A:請確保已將所有依賴包(如Python庫)提前製作成自訂鏡像,並在調度配置中指定該鏡像。詳情請參見個人開發環境製作DataWorks鏡像。
Q:我如何更換Python核心版本?
A:可在個人開發環境的終端
 手動安裝需要Python版本,然後在Notebook工具列右側單擊
手動安裝需要Python版本,然後在Notebook工具列右側單擊 按鈕,切換其他Python核心版本。不推薦使用額外安裝Python核心,因為建立版本不具備SQL儲存格需要的依賴,無法正常使用。
按鈕,切換其他Python核心版本。不推薦使用額外安裝Python核心,因為建立版本不具備SQL儲存格需要的依賴,無法正常使用。