在傳統的資料工作流程中,處理像使用者評論、產品描述、客服日誌等非結構化文本資料一直是一項挑戰。您現在可以直接在DataWorks的工作流程中,利用強大的大語言模型(LLM)能力,通過自然語言指令,輕鬆完成文本摘要、情感分析、內容分類、資訊提取等複雜的AI任務。這極大地簡化資料處理流程,讓資料工程師和分析師無需編寫複雜的演算法,即可將AI能力無縫整合到現有的ETL(資料幫浦、轉換、載入)鏈路中。
準備工作
在DataWorks中部署大模型服務,詳情請參見部署模型。
大模型節點配置
只需簡單配置即可實現大模型節點運行。
|
配置項 |
說明 |
|
模型服務 |
在準備工作中部署的大模型服務。 |
|
模型名稱 |
預設選擇大模型服務中的模型。 |
|
系統Prompt |
定義大模型的系統行為,包含角色、能力和管理辦法等。 支援通過${param}格式擷取參數。 |
|
使用者Prompt |
輸入具體問題或需求。DataWorks預設提供4種模板,可快速選擇。 支援通過 ${param} 格式擷取參數。
例如,Prompt寫成:請挑選出符合 |
簡單樣本
通過一個簡單例子,示範大模型在工作流程中的使用以及上下遊參數傳遞。
-
登入DataWorks大模型服務,建立一個基於Qwen3-1.7B的大模型服務。資源群組,選擇已綁定到當前工作空間的資源群組。
-
進入新版資料開發,建立如下工作流程和相應節點。
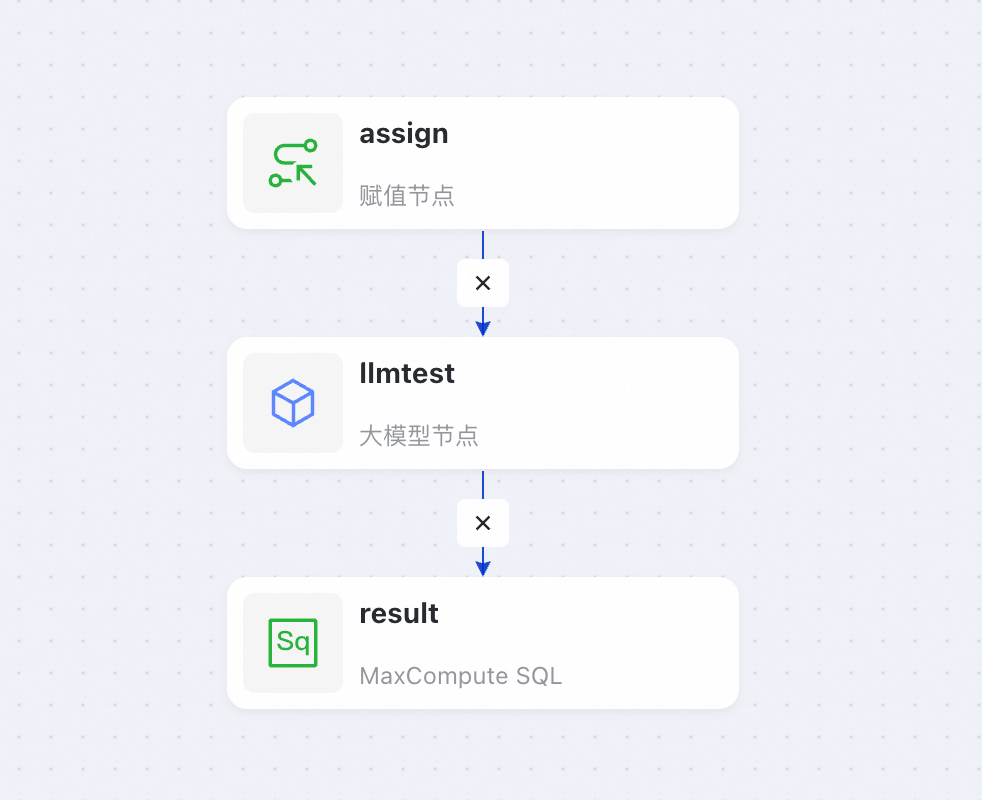
-
配置 賦值節點 的語言模式為 Shell (右下角工具列),並編寫如下代碼。
若找不到,可參見賦值節點的詳細說明。
echo 'DataWorks'; -
配置大模型節點。
-
選擇上述配置好的大模型服務以及模型名稱。
-
配置使用者Prompt如下:
寫一篇關於${title}的介紹,字數限制為${length}。 -
在右側配置面板的,修改資源群組為建立大模型服務時選中的資源群組。
-
在右側配置面板的,添加參數title為上遊節點的輸出和length為固定值300。
在參數值輸入框右側點擊
 進行上遊參數的綁定。
進行上遊參數的綁定。
-
-
配置MaxCompute SQL節點,輸出大模型結果。
重要配置MaxCompute SQL節點需要綁定MaxCompute計算資源。若無,可選擇Shell節點代替,僅示範輸出結果。
-
配置代碼如下:
select '${content}'; -
在右側配置面板的,修改資源群組為建立大模型服務時選中的資源群組。
-
在右側,添加參數 content 為 上遊節點的輸出 。
在參數值輸入框右側點擊
進行上遊參數的綁定。
綁定完成後,參數值顯示為 已綁定節點 llmtest 的輸出參數 outputs。
-
-
回到工作流程,點擊上方運行按鈕,在彈窗中填寫本次運行參數。
-
運行成功後,最終MaxCompute SQL節點輸出類似如下大語言模型結果。
DataWorks 是阿里雲推出的一款企業級資料開發與管理平台,支援資料擷取、清洗、整合、調度和可視化,適用於大規模資料處理情境。 它提供可視化開發介面,支援多種資料來源接入,具備強大的任務調度能力和資料品質監控功能。 DataWorks 支援即時資料流處理和批處理,可協助企業實現資料資產化管理,提升資料利用效率。 通過統一的資料開發流程,DataWorks 有助於構建高效、可靠的資料管道,支援企業級資料治理與智能化分析。