本案例指導您完成購房群體分析,協助您掌握DataWorks的資料開發與資料分析流程。
案例介紹
本案例基於使用者買房資料,分析不同群體的購房情況。通過DataWorks進行資料開發和資料分析。將本機資料通過DataWorks上傳至MaxCompute的bank_data表,通過MaxCompute SQL任務節點分析使用者群體,得到result_table表。基於result_table表做簡單可視化展示分析,得到群體畫像。
本案例基於類比資料示範功能,實際應用中需要結合業務資料進行調整。
本案例的資料流轉和資料開發的商務程序圖如下所示。
完成資料分析之後,您將從購房資料中得到如下群體分析畫像:貸款買房單身人士的受教育水平以university.degree和high.school為主。

準備工作
開通DataWorks
本教程以華東2(上海)地區為例,介紹DataWorks快速入門,您需要登入DataWorks管理主控台,切換至華東2(上海)地區,查看該地區是否開通DataWorks。
本教程以華東2(上海)為例,在實際使用中,請根據實際業務資料所在位置確定開通地區:
如果您的業務資料位元於阿里雲的其他雲端服務,請選擇與其相同的地區。
如果您的業務在本地,需要通過公網訪問,請選擇與您實際地理位置較近的地區,以降低訪問延遲。
全新使用者
如果您為新使用者,首次使用DataWorks,將顯示如下內容,表示當前地區尚未開通DataWorks,需要單擊0元組合購買。
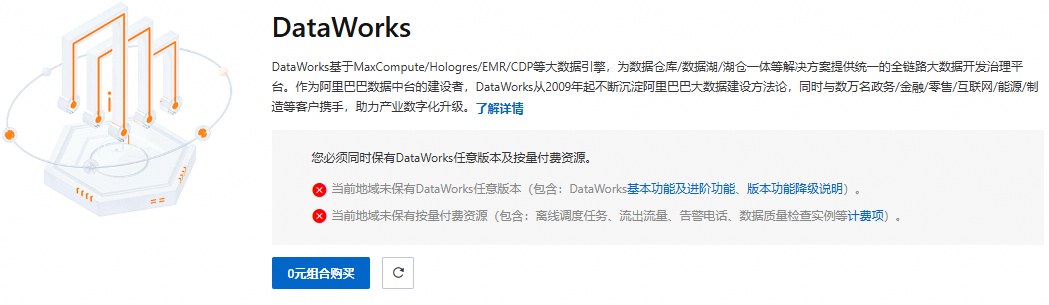
配置組合購買頁相關參數。
參數
說明
樣本
地區
選擇需要開通DataWorks的地區。
華東2(上海)
DataWorks版本
選擇需要購買的DataWorks版本。
說明本教程以基礎版為例,所有版本均可體驗本教程所涉及的功能,您可以參考DataWorks各版本功能詳情,根據實際業務需要,選擇合適的DataWorks版本。
基礎版
單擊確認訂單並支付,完成後續支付。
開通過但已到期
如果您在華東2(上海)地區曾經開通過DataWorks,但DataWorks版本已到期,則會出現如下提示,需要單擊購買版本。
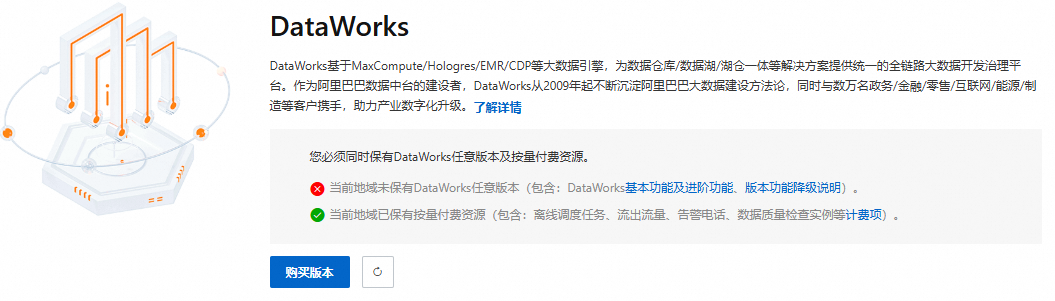
配置購買頁相關參數。
參數
說明
樣本
版本
選擇需要購買的DataWorks版本。
說明本教程以基礎版為例,所有版本均可體驗本教程所涉及的功能,您可以參考DataWorks各版本功能詳情,根據實際業務需要,選擇合適的DataWorks版本。
基礎版
地區
選擇需要開通DataWorks的地區。
華東2(上海)
單擊立即購買,完成後續支付。
您在購買DataWorks版本後,如未找到相關DataWorks版本,可進行以下操作:
等待幾分鐘重新整理頁面,系統更新可能會有延遲。
查看所在地區是否與購買DataWorks版本地區一致,防止因地區選擇問題,未找到相關DataWorks版本。
已開通
如果您在華東2(上海)地區已開通DataWorks,將會進入DataWorks概覽頁,可直接進行下一步。
建立工作空間
建立資源群組並綁定工作空間
建立並綁定MaxCompute計算資源
操作步驟
在本案例中,您將通過DataWorks將本教程提供的測試資料上傳至MaxCompute專案,並在DataWorks的資料開發中產生工作流程,對測試資料進行基本的清洗和寫入操作。同時,您還將對工作流程進行調試運行,並通過SQL查詢驗證運行結果等操作。
一、建立表
上傳測試資料前,通過DataWorks的資料目錄在MaxCompute專案中建立用來儲存上傳資料的bank_data表。
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入Data Studio。
在資料開發頁面單擊左側導覽列的
 按鈕,進入資料目錄頁面。
按鈕,進入資料目錄頁面。(可選)若您的MaxCompute專案未添加至資料目錄,則需單擊MaxCompute目錄後的
 按鈕,進入DataWorks 資料來源頁簽,將已添加為計算資源或資料來源的MaxCompute專案,添加至MaxCompute目錄下。
按鈕,進入DataWorks 資料來源頁簽,將已添加為計算資源或資料來源的MaxCompute專案,添加至MaxCompute目錄下。單擊開啟MaxCompute目錄,選擇需要建立MaxCompute計算資源的專案,在表檔案夾下建立MaxCompute表。
說明若您的MaxCompute開啟了schema,則需在選擇建立MaxCompute計算資源的專案後,開啟目標schema後,才可在表檔案夾下建立MaxCompute表。
本樣本以標準模式工作空間為例,且僅在開發環境調試,所以僅需在開發環境對應的MaxCompute專案下建立
bank_data表,若您使用的是簡單模式工作空間,則只需在生產環境對應的MaxCompute專案下建立bank_data表即可。
單擊表目錄右側的
 按鈕,添加並進入建立表的編輯頁面。
按鈕,添加並進入建立表的編輯頁面。在表編輯頁面右側DDL模組鍵入以下SQL代碼,系統將自動產生所有表資訊。
CREATE TABLE IF NOT EXISTS bank_data ( age BIGINT COMMENT '年齡', job STRING COMMENT '工作類型', marital STRING COMMENT '婚否', education STRING COMMENT '教育程度', `default` STRING COMMENT '是否有信用卡', housing STRING COMMENT '房貸', loan STRING COMMENT '貸款', contact STRING COMMENT '聯絡途徑', month STRING COMMENT '月份', day_of_week STRING COMMENT '星期幾', duration STRING COMMENT '期間', campaign BIGINT COMMENT '本次活動聯絡的次數', pdays DOUBLE COMMENT '與上一次聯絡的時間間隔', previous DOUBLE COMMENT '之前與客戶聯絡的次數', poutcome STRING COMMENT '之前行銷活動的結果', emp_var_rate DOUBLE COMMENT '就業變化速率', cons_price_idx DOUBLE COMMENT '消費者物價指數', cons_conf_idx DOUBLE COMMENT '消費者信心指數', euribor3m DOUBLE COMMENT '歐元存款利率', nr_employed DOUBLE COMMENT '職工人數', y BIGINT COMMENT '是否有定期存款' );在編輯頁面,單擊發布按鈕,在開發環境對應MaxCompute專案中建立
bank_data表。完成
bank_data表建立後,即可在資料目錄下單擊表名,查看錶的詳細資料。
二、上傳資料
下載banking.csv檔案至本地,通過DataWorks的使用限制功能將檔案上傳至MaxCompute專案建立的bank_data中。
進行檔案上傳前,須保證已為資料上傳功能指定調度資源群組與Data Integration資源群組,詳情可參見資料上傳使用限制。
單擊左上方
 表徵圖,在彈出頁面中單擊,進入上傳與下載頁面。
表徵圖,在彈出頁面中單擊,進入上傳與下載頁面。單擊最近上傳模組的資料上傳按鈕,進入資料上傳配置頁面,可參考以下配置。
參數
描述
資料來源
本地檔案。
指定待上傳資料
選擇檔案
上傳已下載至本地的
banking.csv檔案。設定目標表
目標引擎
MaxCompute
MaxCompute專案名稱
選擇
bank_data表所在的MaxCompute專案。選擇目標表
選擇
bank_data表作為目標表。上傳檔案資料預覽
單擊按順序映射,完成檔案資料與
bank_data表欄位對應。說明本地檔案支援上傳
.csv,.xls,.xlsx,.json類型的檔案。表格檔案預設上傳檔案的第一個Sheet。
.csv檔案最大支援5GB,其他檔案最大支援100MB。
單擊資料上傳,將下載的CSV檔案內的資料上傳至MaxCompute計算資源內的
bank_data表中。確認資料上傳成功。
在資料上傳成功後,您可通過SQL查詢(舊版)來確認
bank_data表中是否已寫入資料。單擊左上方
表徵圖,在彈出頁面中單擊。在我的檔案後單擊
 > 建立檔案,自訂檔案名稱後單擊確定。
> 建立檔案,自訂檔案名稱後單擊確定。在SQL查詢頁面,配置如下SQL。
SELECT * FROM bank_data limit 10;在右上方選擇
bank_data表所在的工作空間和MaxCompute資料來源後單擊確定。說明本樣本以標準模式工作空間為例,且
bank_data表僅在開發環境建立,選擇資料來源時,必須選擇開發環境的MaxCompute資料來源。若您使用的是簡單模式工作空間,選擇生產環境的MaxCompute資料來源即可。單擊頂部的運行按鈕,在成本預估頁面,單擊運行,運行成功之後,在頁面下方您將獲得bank_data的前10條記錄。此時,表示您成功上傳本機資料至bank_data表。

三、加工資料
使用MaxCompute SQL節點將上傳至bank_data表的資料進行過濾,獲得單身人士貸款買房的受教育水平分布數量資料,並將資料寫入新的result_table表中。
搭建資料加工鏈路
單擊左上方的
 表徵圖,選擇,進入資料開發頁面。
表徵圖,選擇,進入資料開發頁面。在頁面頂部切換至本教程建立好的工作空間,在左側導覽列單擊
 ,進入資料開發。
,進入資料開發。在專案目錄地區,單擊
 ,選擇建立工作流程,設定工作流程名稱,本教程設定為
,選擇建立工作流程,設定工作流程名稱,本教程設定為dw_basic_case,單擊確認儲存工作流程,進入工作流程編排頁面。進入工作流程編排頁面後,從左側拖拽虛擬節點和MaxCompute SQL節點至畫布中,分別設定節點名稱。
本教程節點名稱樣本及作用如下:
節點類型
節點名稱
節點作用
 虛擬節點
虛擬節點workshop_start用於統籌管理整個購房群體分析簡單教程,可使資料流轉路徑更清晰。該節點為空跑任務,無須編輯代碼。
 MaxCompute SQL
MaxCompute SQLddl_result_table用於建立result_table,用來寫入清洗後的bank_data表資料。
MaxCompute SQLinsert_result_table用於將bank_data資料進行過濾後寫入result_table表。
手動拖拽連線,配置各節點的上遊節點。最終效果如下:

在節點工具列單擊儲存。
配置資料加工節點
四、調試運行
工作流程配置完成後,需要您在dw_basic_case工作流程編排頁面,單擊 按鈕,調試運行整個工作流程,驗證工作流程是否可以正常運行。若運行失敗,則可根據調試作業記錄進行排查。
按鈕,調試運行整個工作流程,驗證工作流程是否可以正常運行。若運行失敗,則可根據調試作業記錄進行排查。

五、資料查詢與展示
您已經將上傳至MaxCompute計算資源的資料,經過資料開發處理,在SQL查詢(舊版)中可查詢result_table資料,並且進行分析。
單擊左上方
表徵圖,在彈出頁面中單擊。在我的檔案後單擊
> 建立檔案,自訂檔案名稱後單擊確定。在SQL查詢頁面,配置如下SQL。
SELECT * FROM result_table;在右上方選擇
result_table表所在的工作空間和MaxCompute資料來源後單擊確定。說明本樣本以標準模式工作空間為例,且
result_table表僅在開發環境建立,未發布至生產環境,所以選擇資料來源時,必須選擇開發環境的MaxCompute資料來源。若您使用的是簡單模式工作空間,選擇生產環境的MaxCompute資料來源即可。單擊頂部的運行按鈕,在成本預估頁面,單擊運行。
在查詢結果中單擊
 ,查看可視化圖表結果,您可以單擊圖表右上方的
,查看可視化圖表結果,您可以單擊圖表右上方的 自訂圖表樣式。
自訂圖表樣式。您也可以單擊圖表右上方儲存,將圖表儲存為卡片,然後在左側導覽列單擊卡片(
 )查看。
)查看。
下一步
本教程中各模組的更多操作細節及參數解釋,請參見資料開發(Data Studio)(新版)、資料分析。
除本教程介紹的模組外,DataWorks還支援資料建模、資料品質、資料保護傘、資料服務、Data Integration、節點調度配置等多個模組,為您提供一站式資料監控與營運。
您還可以體驗更多DataWorks實踐教程,具體內容,請參見更多情境案例/教程。
附錄:資源釋放與清理
如果您需要釋放本次教程所建立的資源,具體操作步驟如下:
停止周期任務。
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入營運中心。
在中,勾選所有之前建立的周期任務(工作空間root節點無需下線),然後在底部單擊。
刪除資料開發節點並解除綁定MaxCompute計算資源。
進入DataWorks工作空間列表頁,在頂部切換至目標地區,找到目標工作空間,單擊操作列的,進入Data Studio。
在Data Studio左側導覽列單擊
 ,進入資料開發頁面,然後在專案目錄地區找到已建立好的工作流程,右鍵工作流程,單擊刪除。
,進入資料開發頁面,然後在專案目錄地區找到已建立好的工作流程,右鍵工作流程,單擊刪除。在左側導覽列,單擊
 > 計算資源管理,找到已綁定的MaxCompute計算資源,單擊解除綁定。在確認視窗中勾選選項後按照指引完成解除綁定。
> 計算資源管理,找到已綁定的MaxCompute計算資源,單擊解除綁定。在確認視窗中勾選選項後按照指引完成解除綁定。
刪除MaxCompute專案。
前往MaxCompute專案管理頁面,找到已建立的MaxCompute專案,單擊操作列的刪除,按照指引完成刪除。
刪除DataWorks工作空間。
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的工作空間,在工作空間列表找到需刪除的DataWorks空間,單擊操作列的
 按鈕,選擇刪除工作空間。
按鈕,選擇刪除工作空間。在刪除工作空間彈窗內,單擊確認刪除工作空間。