文檔概述
在查看相關問題時,您可以通過匹配關鍵字來尋找常見相似問題及其對應的解決方案。
網路通訊問題
為什麼資料來源測試連通性成功,但是離線同步任務執行報錯資料來源串連失敗?
如果您之前測試連通性通過,請重新測試連通性,確認資源群組與資料庫當前是可連通狀態(確認資料庫端無變更)。
請檢查測試連通性成功的資源群組和任務執行所用的資源群組是否是同一個。
查看任務運行資源:
任務運行在預設的資源群組上,日誌中會出現如下資訊。running in Pipeline[basecommon_ group_xxxxxxxxx]
任務運行在獨享Data Integration資源上,日誌中會出現如下資訊。running in Pipeline[basecommon_S_res_group_xxx]
任務運行在Serverless資源群組上,日誌中會出現如下資訊。running in Pipeline[basecommon_Serverless_res_group_xxx]
如果淩晨任務調度時偶爾失敗,但重跑又能成功,請檢查資料庫在報錯時間點的負載情況。
離線同步任務執行偶爾成功偶爾失敗
出現離線同步任務偶爾執行失敗的情況,可能是因為白名單配置不全導致的,您需要檢查資料庫白名單是否配置完全。
使用獨享Data Integration資源群組時:
適用Serverless資源群組時:可參考添加白名單檢查資源群組的白名單配置,確保網路設定正確。
如果白名單無異常,請確認資料庫負載是否過高導致串連中斷。
資源設定問題
離線同步任務,運行報錯:[TASK_MAX_SLOT_EXCEED]:Unable to find a gateway that meets resource requirements. 20 slots are requested, but the maximum is 16 slots.
可能原因:
設定並發數太大導致沒有足夠的資源。
解決方案:
離線同步任務,運行報錯:OutOfMemoryError: Java heap space
出現上述報錯後,您需要:
如果外掛程式配置支援的參數中有batchsize或者maxfilesize,可以調小對應的值。
您可以查看各外掛程式是否支援上述參數,進入支援的資料來源與讀寫外掛程式文檔後,單擊對應外掛程式查看參數詳情。
調小並發數。
如果是檔案同步,例如同步OSS檔案等,請減少讀取的檔案數。
在任務配置的運行資源中,適當調大任務的資源佔用(CU)的值。請注意合理設定CU大小,避免影響到其他任務運行。
執行個體運行衝突
離線任務,運行報錯:Duplicate entry 'xxx' for key 'uk_uk_op'
報錯現象:Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Duplicate entry 'cfc68cd0048101467588e97e83ffd7a8-0' for key 'uk_uk_op'。
可能原因:Data Integration同步任務不允許同一時間運行相同節點的不同執行個體(即相同JSON配置的同步任務不能同一時間運行多個,例如5分鐘為周期的同步任務,由於上遊延遲,在0點5分時調起了原本0點0分的執行個體和0點5分的執行個體,這樣會導致其中一個執行個體無法調起,或者任務執行個體在運行時又進行了補資料、重跑等操作)。
解決方案:錯開執行個體已耗用時間,如果為小時分鐘任務建議設定自依賴,即等待上一周期的執行個體運行完成後才開始運行本次執行個體,舊版資料開發設定方式:自依賴,新版資料開發設定方式:調度依賴方式選擇(跨周期依賴)
運行逾時
離線同步任務,源端為MongoDB,運行報錯:MongoDBReader$Task - operation exceeded time limitcom.mongodb.MongoExecutionTimeoutException: operation exceeded time limit.
離線同步任務,資料來源為MySQL,運行報錯連線逾時:Communications link failure
讀取報錯
問題現象:
讀取資料時,報錯如下:Communications link failure The last packet successfully received from the server was 7,200,100 milliseconds ago. The last packet sent successfully to the server was 7,200,100 milliseconds ago. - com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
可能原因:
資料庫執行SQL查詢速度慢,導致MySQL讀逾時。
解決方案:
排查是否設定了where過濾條件,以確保篩選欄位已添加索引。
排查來源資料表的資料是否太多。如果資料太多,建議拆分為多個任務。
查詢日誌找到執行阻塞的SQL,諮詢資料庫管理員解決問題。
寫入報錯
問題現象:
寫入資料時,報錯如下:Caused by: java.util.concurrent.ExecutionException: ERR-CODE: [TDDL-4614][ERR_EXECUTE_ON_MYSQL] Error occurs when execute on GROUP 'xxx' ATOM 'dockerxxxxx_xxxx_trace_shard_xxxx': Communications link failure The last packet successfully received from the server was 12,672 milliseconds ago. The last packet sent successfully to the server was 12,013 milliseconds ago. More...
可能原因:
慢查詢導致SocketTimeout。TDDL預設串連資料的SocketTimeout是12秒,如果一個SQL在MySQL端執行超過12秒仍未返回,會報4614的錯誤。當資料量較大或服務端繁忙時,會偶爾出現該錯誤。
解決方案:
建議資料庫穩定後,重新運行同步任務。
聯絡資料庫管理員調整該逾時時間。
如何排查離線同步任務已耗用時間長的問題?
可能原因2:等待Data Integration任務執行資源
解決方案2:若日誌出現長時間WAIT狀態,說明當前任務運行所使用的獨享Data Integration資源群組剩餘可啟動並執行並發數不足以運行當前任務。具體原因及解決方案詳情請參見:為什麼Data Integration任務一直顯示wait?。
說明 由於離線同步任務通過調度資源群組下發到Data Integration執行資源組上執行,所以一個離線同步任務將同時耗費一個調度資源,若離線同步任務長時間運行未釋放資源,除了阻塞其他離線任務運行外,可能還將阻塞其他類型的調度任務運行。
資料同步任務where條件沒有索引,導致全表掃描同步變慢
情境樣本
執行的SQL如下所示。
SELECT bid,inviter,uid,createTime FROM `relatives` WHERE createTime>='2016-10-2300:00:00' AND reateTime<'2016-10-24 00:00:00';
從2016-10-25 11:01:24.875開始執行,到2016-10-25 11:11:05.489開始返回結果。同步程式在等待資料庫返回SQL查詢結果,MaxCompute需等待很久才能執行。
分析原因
where條件查詢時,createTime列沒有索引,導致查詢全表掃描。
解決方案
建議where條件使用與索引相關的列,提高效能,索引也可以補充添加。
切換資源群組
如何切換離線同步任務的執行資源組?
舊版資料開發:
您可以在DataStudio的離線同步任務詳情介面修改調試所用的資源群組;也支援在運維中心修改任務調度時所使用的Data Integration任務執行資源組。配置詳情參見:切換Data Integration資源群組。
新版資料開發:
您可以在DataStudio修改Data Integration任務調試所用的資源群組;也支援在運維中心修改任務調度時所使用的Data Integration任務執行資源組。配置詳情請參見:資源群組營運。
髒資料
髒資料如何排查和定位?
髒資料定義:單條資料寫入目標資料來源過程中發生了異常,則此條資料為髒資料。 因此只要是寫入失敗的資料均被歸類於髒資料。
髒資料影響:髒資料將不會成功寫入目的端。您可以控制是否允許髒資料產生,並且支援控制髒資料條數,Data Integration預設允許髒資料產生,您可以在同步任務配置時指定髒資料產生條數。詳情可參考:嚮導模式配置。
髒資料即時情境分析:
情境一:
報錯現象:{"message":"寫入 ODPS 目的表時遇到了髒資料: 第[3]個欄位的資料出現錯誤,請檢查該資料並作出修改或者您可以增大閾值,忽略這條記錄.","record":[{"byteSize":0,"index":0,"type":"DATE"},{"byteSize":0,"index":1,"type":"DATE"},{"byteSize":1,"index":2,"rawData":0,"type":"LONG"},{"byteSize":0,"index":3,"type":"STRING"},{"byteSize":1,"index":4,"rawData":0,"type":"LONG"},{"byteSize":0,"index":5,"type":"STRING"},{"byteSize":0,"index":6,"type":"STRING"}]}。
如何處理:該日誌中可以看出髒資料的欄位,第三個欄位異常。
髒資料是writer端報的,要檢查下writer端的建表語句。ODPS端該表欄位指定的欄位大小小於MySQL端該欄位資料大小 。
資料同步原則:來源端資料來源的資料要能寫入目的端資料來源(來源端和目的端類型需要匹配,欄位定義的大小需要匹配),即源端資料類型需要與寫端資料類型匹配,源端是VARCHAR類型的資料不可寫入INT類型的目標列中;目標端的資料類型定義的大小需要能夠接收源端映射欄位實際資料大小,源端是LONG、VARCHAR 、DOUBLE等類型的資料,目的端均可用string、text等大範圍類型接納。
髒資料報錯不清晰時,需要複製列印出的髒資料的一整條,觀察其中的資料,並與目的端資料類型比較,看哪一條或哪一些不符合規範。
比如:
{"byteSize":28,"index":25,"rawData":"ohOM71vdGKqXOqtmtriUs5QqJsf4","type":"STRING"}
byteSize:位元組數;index:25,第26個欄位;rawData:具體值(即value);type:資料類型。
情境二:
離線同步傳輸資料時,髒資料超出限制,已同步的資料是否會保留?
任務執行期間會累計遇到的髒資料數量。一旦該數量超過設定的“髒資料限制”閾值,任務將立即中止。
如何處理編碼格式設定/亂碼問題導致的髒資料報錯?
報錯現象:
如果資料中包括Emoji,在同步過程中可能會報錯髒資料:[13350975-0-0-writer] ERROR StdoutPluginCollector - 髒資料 {"exception":"Incorrect string value: '\\xF0\\x9F\\x98\\x82\\xE8\\xA2...' for column 'introduction' at row 1","record":[{"byteSize":8,"index":0,"rawData":9642,"type":"LONG"}],"type":"writer"} 。
可能原因:
解決方案:
針對產生亂碼的不同原因,選擇相應的解決方案:
您可以嘗試以下操作:
JDBC格式添加的資料來源修改utf8mb4:jdbc:mysql://xxx.x.x.x:3306/database?com.mysql.jdbc.faultInjection.serverCharsetIndex=45。
執行個體ID形式添加資料來源:在資料庫名後拼接,格式為database?com.mysql.jdbc.faultInjection.serverCharsetIndex=45。
修改資料庫相關的編碼格式為utf8mb4。例如,在RDS控制台修改RDS的資料庫編碼格式。
說明 設定RDS資料來源編碼格式命令:set names utf8mb4。查看RDS資料庫編碼格式命令:show variables like 'char%'。
源表預設值是否保留
源表有預設值,通過Data Integration建立的目標表,預設值、非空屬性等會保留嗎?
建立目標表的時候,DataWorks只會保留源表的列名、資料類型、注釋等資訊,不會保留源表的預設值、約束(包含非空約束、索引等)。
切分鍵
離線整合任務配置切分鍵時,聯合主鍵是否可以作為切分鍵?
資料缺失
資料同步完成,目標表中的資料與源端表資料不一致
資料同步完成後,若出現資料品質問題,可參考文檔:離線同步資料品質排查進行詳細排查。
SSRF攻擊
任務存在SSRF攻擊Task have SSRF attacks如何處理?
Q: 任務報錯“存在SSRF攻擊 (Task have SSRF attacks)”如何處理?
原因:為保障雲上安全,DataWorks禁止任務通過公網IP直接存取雲環境的內部網路地址。當在外掛程式配置中(如HTTP Reader)填寫的URL指向內部IP或VPC網域名稱時,會觸發此安全攔截。
正確做法:
解決方案:基於內網資料來源啟動並執行任務,取消使用公用資源群組,更換為安全可靠的Serverless資源群組(推薦)或獨享Data Integration資源群組。
日期寫入
日期時間類型資料寫入文本時,如何保留毫秒或者指定自訂日期時間格式?
同步任務轉指令碼模式後,在配置任務頁面的setting部分增加以下配置項:
"common": {
"column": {
"dateFormat": "yyyyMMdd",
"datetimeFormatInNanos": "yyyyMMdd HH:mm:ss.SSS"
}
}
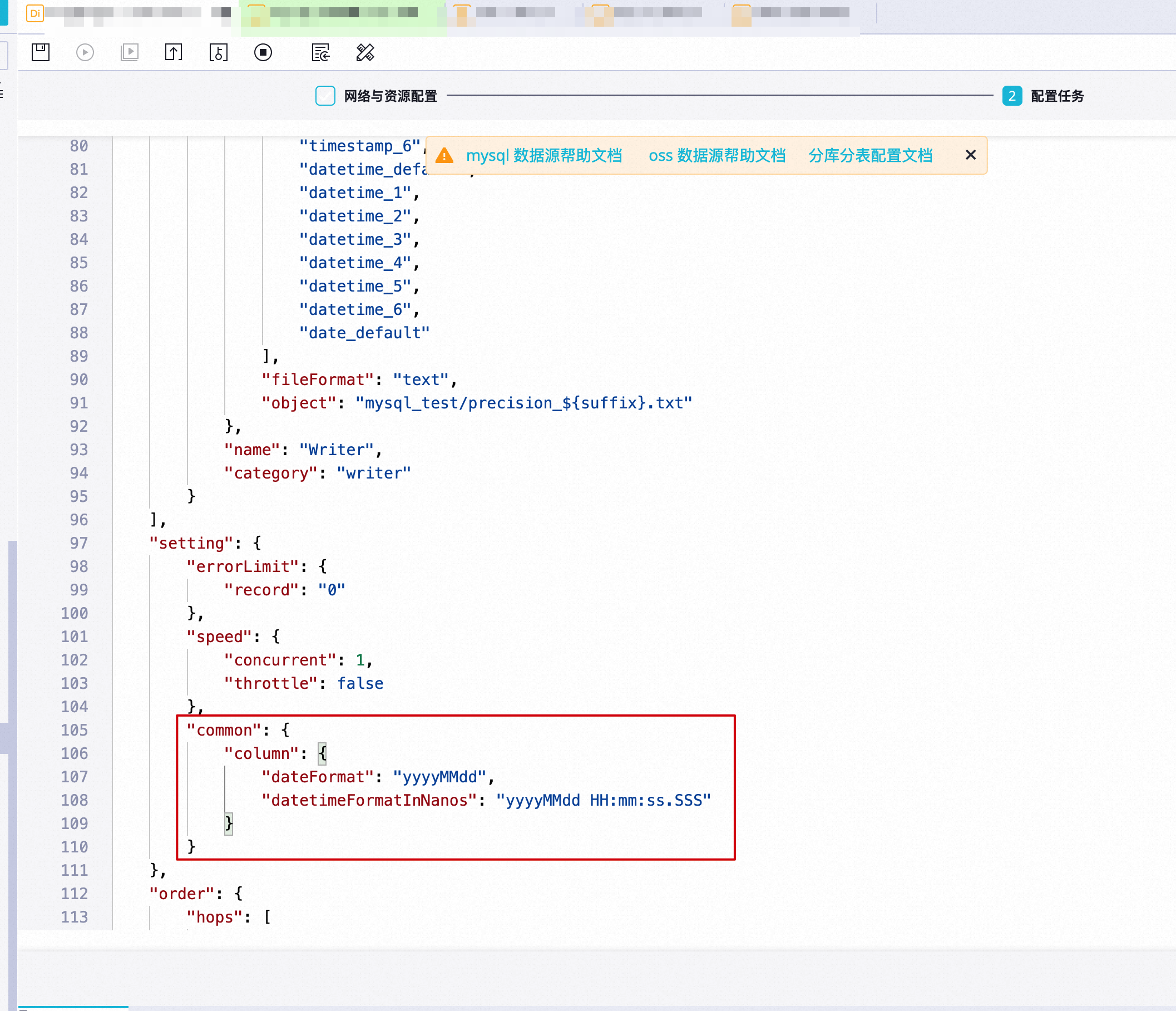
其中:
MaxCompute
讀取MaxCompute(ODPS)表資料時,欄位對應源表欄位「添加一行」或「添加欄位」注意事項
可以輸入常量,輸入的值需要使用英文單引號括起來,例如'abc'、'123'等。
可以配合調度參數使用,如'${bizdate}' 等,調度參數具體使用請參考文檔調度參數支援的格式。
可以輸入您要同步的分區列,如分區列有pt等。
如果您輸入的值無法解析,則類型顯示為'自訂'。
不支援配置ODPS函數。
如果您手工編輯添加的列顯示自訂(例如添加了MaxCompute分區列,LogHub資料預覽未預覽到的列),不會影響實際任務執行。
讀取MaxCompute(ODPS)表資料時,如何同步分區欄位?
在欄位對應列表的源表欄位下單擊添加一行或添加字段,輸入分區列名,如pt,並與目標表欄位配置映射關係。

讀取MaxCompute(ODPS)表資料時,如何同步多個分區資料?
例如,分區表test包含pt=1,ds=hangzhou、pt=1,ds=shanghai、pt=2,ds=hangzhou、pt=2,ds=beijing四個分區,則讀取不同分區資料的配置如下:
如果您需要讀取pt=1,ds=hangzhou分區的資料,則分區資訊的配置為"partition":"pt=1,ds=hangzhou"。
如果您需要讀取pt=1中所有分區的資料,則分區資訊的配置為"partition":"pt=1,ds=*"。
如果您需要讀取整個test表所有分區的資料,則分區資訊的配置為"partition":"pt=*,ds=*"。
此外,您還可以根據實際需求設定分區資料的擷取條件(以下操作需要轉指令碼模式配置任務):
如果您需要指定最大分區,則可以添加/*query*/ ds=(select MAX(ds) from DataXODPSReaderPPR)配置資訊。
如果需要按條件過濾,則可以添加相關條件/*query*/ pt+運算式配置。例如/*query*/ pt>=20170101 and pt<20170110表示擷取pt分區中,20170101日期之後(包含20170101日期),至20170110日期之前(不包含20170110日期)的所有資料。
說明 /*query*/表示將其後填寫的內容識別為一個where條件。
MaxCompute如何?列篩選、重排序和補空等
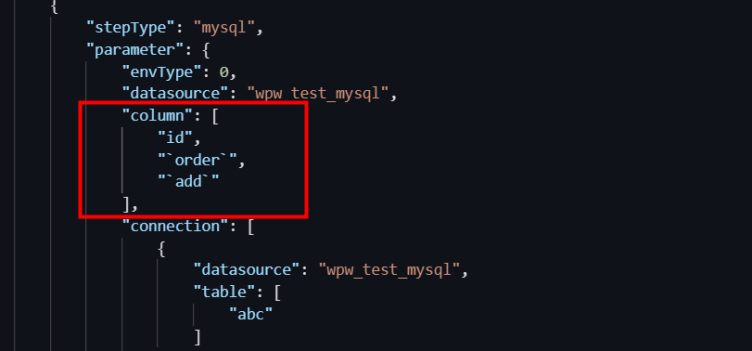
通過配置MaxCompute Writer,可以實現MaxCompute本身不支援的列篩選、重排序和補空等操作。例如,當需要匯入的欄位列表為全部欄位時,可以配置為"column": ["*"]。
MaxCompute表有a、b和c三個欄位,您只同步c和b兩個欄位,可以將列配置為"column": ["c","b"],表示會把Reader的第一列和第二列匯入MaxCompute的c欄位和b欄位,而MaxCompute表中新插入的a欄位會被置為null。
MaxCompute列配置錯誤的處理
為保證寫入資料的可靠性,避免多餘列資料丟失造成資料品質故障。對於寫入多餘的列,MaxCompute Writer將報錯。例如MaxCompute表欄位為a、b和c,如果MaxCompute Writer寫入的欄位多於三列,MaxCompute Writer將報錯。
MaxCompute分區配置注意事項
MaxCompute Writer僅提供寫入到最後一級分區的功能,不支援按照某個欄位進行分區路由等功能。假設表一共有三級分區,在分區配置中必須明確寫入至某個三級分區。例如,寫入資料至一個表的第三級分區,可以配置為pt=20150101, type=1, biz=2,但不能配置為pt=20150101, type=1或者pt=20150101。
MaxCompute任務重跑和failover
MaxCompute Writer通過配置"truncate": true,保證寫入的等冪性。即當出現寫入失敗再次運行時,MaxCompute Writer將清理前述資料,並匯入新資料,以保證每次重跑之後的資料都保持一致。如果在運行過程中,因為其他的異常導致任務中斷,便不能保證資料的原子性,資料不會復原也不會自動重跑,需要您利用等冪性的特點進行重跑,以確保資料的完整性。
說明 truncate為true的情況下,會將指定分區或表的資料全部清理,請謹慎使用。
讀取MaxCompute(ODPS)表資料報錯:The download session is expired.
報錯現象:
Code:DATAX_R_ODPS_005:讀取ODPS資料失敗, Solution:[請聯絡ODPS管理員]. RequestId=202012091137444331f60b08cda1d9, ErrorCode=StatusConflict, ErrorMessage=The download session is expired.
可能原因:
離線同步讀取MaxCompute資料時,使用的是MaxCompute的tunnel命令來進行上傳下載資料。Tunnel的Session在服務端的生命週期為24小時,所以離線同步任務如果執行超過24小時會失敗退出,關於tunnel介紹詳情請參見使用說明。
解決方案:
您可以適當調大離線同步任務並發數,合理規劃同步的資料量,以確保任務在24小時內同步完成。
寫入MaxCompute(ODPS)報錯block失敗:Error writing request body to server
MySQL
MySQL分庫分表如何將分表同步到一張MaxCompute中
目的端MySQL表字元集為utf8mb4時,同步到MySQL中的中文字元出現亂碼時,如何處理?
選擇通過串連串的方式添加資料來源,建議JDBC格式修改為:jdbc:mysql://xxx.x.x.x:3306/database?com.mysql.jdbc.faultInjection.serverCharsetIndex=45,詳情請參見配置MySQL資料來源。
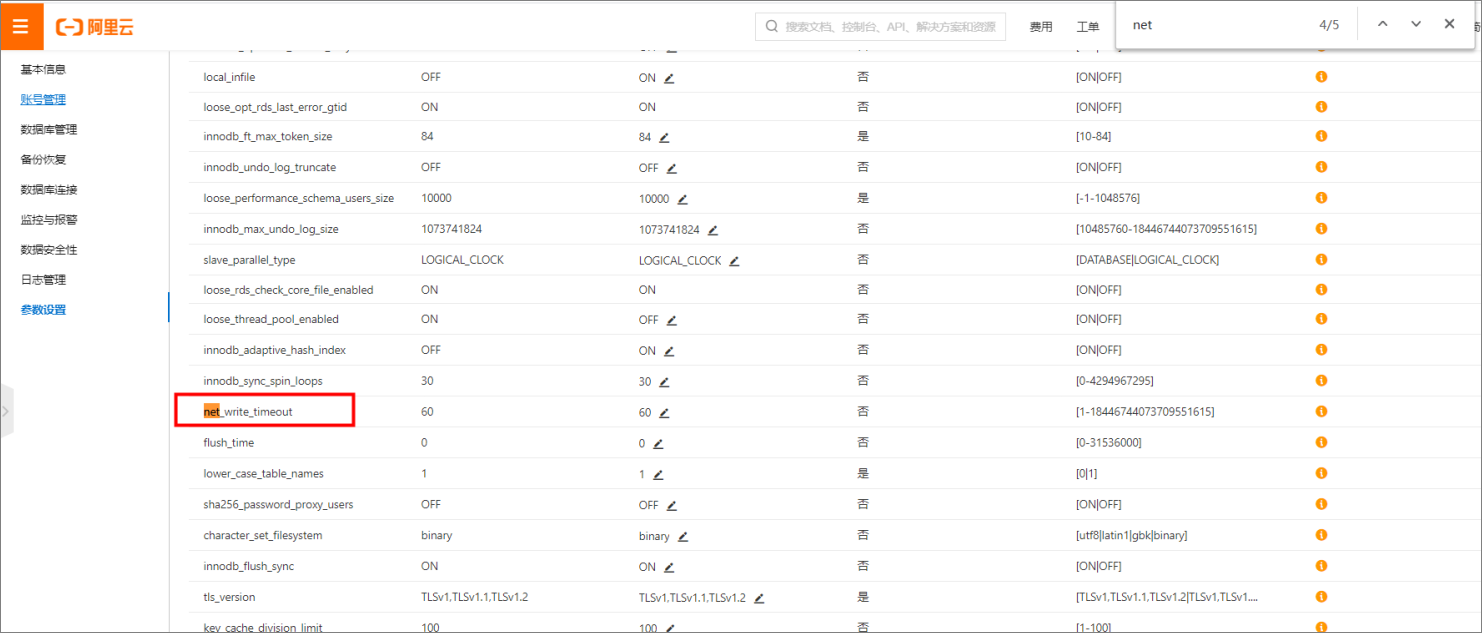
寫入/讀取MySQL報錯:Application was streaming results when the connection failed. Consider raising value of 'net_write_timeout/net_read_timeout' on the server.
例如:jdbc:mysql://192.168.1.1:3306/lizi?useUnicode=true&characterEncoding=UTF8&net_write_timeout=72000
離線同步至MySQL報錯:[DBUtilErrorCode-05]ErrorMessage: Code:[DBUtilErrorCode-05]Description:[往您配置的寫入表中寫入資料時失敗.]. - com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: No operations allowed after connection closed
報錯原因:
MySQL中參數wait_timeout預設時間為8小時,當達到預設時間時,如果仍然在擷取資料,會導致同步任務中斷。
解決方案:
修改MySQL的設定檔my.cnf(Windows系統下是my.ini),在MySQL模組下面加上參數單位(秒),設定為:wait_timeout=2592000 interactive_timeout=2592000,再重啟登入MySQL,輸入如下語句:show variables like '%wait_time%',查看是否設定成功。
讀取MySQL資料庫報錯:The last packet successfully received from the server was 902,138 milliseconds ago
CPU使用正常,記憶體使用量較高可能導致串連被斷開。
如果您確認可以自動重跑的話,建議您設定任務出錯自動重跑,詳情參考文檔:時間屬性配置
PostgreSQL
讀取PostgreSQL資料報錯:org.postgresql.util.PSQLException: FATAL: terminating connection due to conflict with recovery
問題情境:離線同步工具同步PostgreSQL資料時,報錯如下:org.postgresql.util.PSQLException: FATAL: terminating connection due to conflict with recovery
可能原因:出現該情況的原因是從資料庫中拉取資料的時間較長,請增加max_standby_archive_delay和max_standby_streaming_delay的參數值,詳情請參見Standby Server Events。
RDS
離線同步源端是亞馬遜的RDS時報錯:Host is blocked
串連亞馬遜的RDS返回Host is blocked時,您需要關閉亞馬遜負載平衡健全狀態檢查,關閉後就不會再報出block問題。
MongoDB
添加MongoDB資料來源時,使用root使用者時報錯
使用root使用者添加MongoDB資料來源時報錯,是因為添加MongoDB資料來源時,必須使用需要同步的表所在的資料庫建立的使用者名稱,不可以使用root使用者。
例如需要匯入name表,name表在test庫,則此處資料庫名稱為test,需要使用test資料庫中建立的使用者的使用者名稱。
讀取MongoDB時,如何在query參數中使用timestamp實現增量同步處理?
可以使用賦值節點先對date類型時間處理成timestamp,將該值作為MongoDB資料同步的入參,詳情請參考文檔:MongoDB時間戳記類型欄位如何?增量同步處理?
MongoDB同步至資料目的端資料來源後,時區加了8個小時,如何處理?
你需要在MongoDB Reader配置中設定時區,詳情請參見MongoDB Reader。
讀取MongoDB資料期間,源端有更新記錄,但未同步至目的端,如何處理?
您可以間隔一段時間後重啟任務,query條件不變,即將同步任務的執行時間延遲,配置不變。
MongoDB Reader是否大小寫敏感?
在資料讀取時,使用者配置的Column.name為大小寫敏感,如配置有誤,會導致讀取的資料為null。例如:
則由於同步任務的配置與來源資料大小寫不一致,會導致資料讀取異常。
怎麼配置MongoDB Reader逾時時間長度?
逾時時間長度的配置參數為cursorTimeoutInMs,預設為600000ms(10分鐘),參數含義為MongoDB Server執行Query總耗時,不包含資料轉送時間長度。若全量讀取的資料較大,可能導致報錯:MongoDBReader$Task - operation exceeded time limitcom.mongodb.MongoExecutionTimeoutException: operation exceeded time limit。
讀取MongoDB報錯:no master
目前DataWorks同步任務暫不支援從庫讀取資料, 如果您配置從庫讀取,將會報該錯誤:no master。
讀取MongoDB報錯:MongoExecutionTimeoutException: operation exceeded time limit
分析原因:
遊標逾時引起。
解決方案:
調大參數cursorTimeoutInMs的值。
離線同步讀取MongoDB報錯:DataXException: operation exceeded time limit
需要通過增大任務並發數和讀取的BatchSize數量。
MongoDB同步任務運行報錯:no such cmd splitVector
MongoDB離線同步報錯:After applying the update, the (immutable) field '_id' was found to have been altered to _id: "2"
Redis
寫入Redis使用hash模式儲存資料時,報錯:Code:[RedisWriter-04], Description:[Dirty data]. - source column number is in valid!
產生原因:
Redis在使用hash模式儲存時,hash的attribute和value要成對出現。例如:odpsReader: "column":[ "id", "name", "age", "address" ],目標端在配置RedisWriter: "keyIndexes":[ 0, 1],在Redis中,id和name將作為key,age將作為attribute,address將作為value存到Redis中的hash類型中,如果odps源端只配置了兩列,則不可以使用hash模式去儲存Redis緩衝,會報該異常。
解決方案:
假如只想用兩列,那就配置Redis的String模式去存資訊,如果必須要用hash存,源端至少配置三列。
OSS
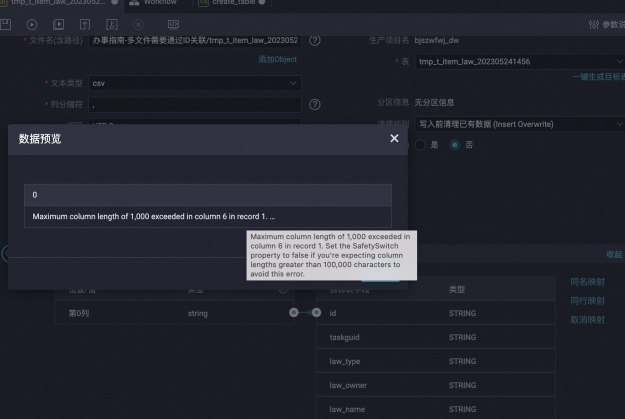
讀取多分隔字元的CSV檔案,出現髒資料如何處理?
問題現象:
在配置離線同步任務從OSS、FTP等檔案儲存體讀取資料時,如果檔案是CSV格式,並且使用了多個字元作為資料行分隔符號(例如 |,、##、;; 等),任務可能會因“髒資料”錯誤而失敗。在任務的作業記錄中,您會看到類似的IndexOutOfBoundsException(數組越界)錯誤,併產生髒資料。
原因分析:
DataWorks內建的 csv 讀取器 ("fileFormat": "csv") 在處理由多個字元組成的分隔字元時存在限制,導致對資料行的列拆分不準確。
解決方案:
嚮導模式:將文本類型切換為text,並明確指定您的多字元分隔字元。
指令碼模式:將"fileFormat": "csv"調整為"fileFormat": "text",並正確設定分隔字元: "fieldDelimiter":"<多分隔字元>", "fieldDelimiterOrigin":"<多分隔字元>"。
讀取OSS檔案是否有檔案數限制?
離線同步本身不限制OSS reader外掛程式讀取檔案的個數,對檔案讀取的限制主要來自任務本身佔用的資源CU,若一次性讀取的檔案太多,容易導致記憶體溢出。因此不建議將object參數配置為:*,防止出現OutOfMemoryError: Java heap space 報錯。
寫入OSS,檔案名稱出現隨機字串如何去除?
OSS Writer寫入的檔案名稱,OSS使用檔案名稱類比目錄的實現。OSS對於Object的名稱有以下限制:使用"object": "datax",寫入的Object以datax開頭,尾碼添加隨機字串。檔案數由實際切分的任務數決定。
如果不需要尾碼隨機UUID,建議配置"writeSingleObject" : "true",詳情請參見OSS資料來源文檔的writeSingleObject說明。
讀取OSS資料報錯:AccessDenied The bucket you access does not belong to you.
Hive
離線同步資料至本地Hive報錯:Could not get block locations.
DataHub
寫入DataHub時,一次性寫入資料超限導致寫入失敗如何處理?
報錯現象:
ERROR JobContainer - Exception when job runcom.alibaba.datax.common.exception.DataXException: Code:[DatahubWriter-04], Description:[寫資料失敗.]. - com.aliyun.datahub.exception.DatahubServiceException: Record count 12498 exceed max limit 10000 (Status Code: 413; Error Code: TooLargePayload; Request ID: 20201201004200a945df0bf8e11a42)
可能原因:
報錯原因為DataX一次性提交到DataHub的資料量超過DataHub的限制。影響提交到DataHub資料量的配置參數主要為:
maxCommitSize:表示DataX累積的buffer資料,待積累的資料大小達到maxCommitSize 大小(單位MB)時,批量提交到目的端。預設是 1MB,即 1,048,576位元組。
batchSize:DataX-On-Flume積累的Buffer資料條數,待積累的資料條數達到batchSize大小(單位條數)時,批量提交至目的端。
解決方案:
調小maxCommitSize和batchSize的參數值。
LogHub
讀取LogHub同步某欄位有資料但是同步過來為空白
此外掛程式欄位大小寫敏感,請檢查LogHub reader的column配置。
讀取LogHub同步少資料
Data Integration取的是資料進入LogHub的時間,請在LogHub控制台檢查資料中繼資料欄位receive_time是否在任務配置的時間區間內。
為什麼配置了起止時間,但讀到的__time__不在這個範圍內,或控制台同一時間範圍內的記錄數和同步任務讀取條數不一致?
離線同步任務配置的開始時間和結束時間,會被Reader用於調用SLS GetCursor定位起止遊標。該時間用於按SLS服務端接收時間定位讀取範圍,任務實際讀取的是遊標範圍內的資料;它不等價於按輸出欄位__time__過濾。
輸出欄位__time__來自每條Log的log.getTime(),表示日誌自身的日誌時間。SLS控制台查詢通常按查詢時間範圍、查詢語句和索引欄位統計,常見口徑是日誌時間__time__。因此,即使同步任務和控制台選擇了相同的時間值,只要兩邊使用的時間口徑不同,讀到的__time__範圍或記錄條數就可能不一致。
常見情境如下:
日誌採集或投遞存在延遲、歷史日誌補傳、用戶端時間不準等情況時,日誌時間__time__可能早於或晚於SLS服務端接收時間。同步任務按服務端接收時間定位遊標,控制台按__time__查詢時,兩邊結果可能不同。
通過SLS資料加工寫入另一個LogStore時,如果加工語句未顯式設定__time__,目標日誌的__time__通常仍沿用源日誌時間,而不是加工任務執行時間。此時,同步任務可能在加工寫入目標LogStore的時間範圍內讀取到這批資料;但在目標LogStore控制台按加工執行時間或目前時間範圍查詢時,可能查不到這批日誌,需要按日誌實際__time__所在的時間範圍查詢。
控制台查詢語句、索引欄位、時間範圍和同步任務中的規則過濾語句(SPL)不一致時,即使時間口徑一致,記錄數也可能不同。
排查建議:
確認控制台查詢時間範圍、查詢語句、索引欄位和同步任務中的起止時間、規則過濾語句(SPL)是否一致;
在column中同時輸出__time__(日誌時間)和__tag__:__receive_time__(SLS服務端接收時間口徑的可觀測欄位,需日誌tag中存在該欄位),對比日誌時間與服務端接收時間;
如果資料來自SLS資料加工,確認加工語句是否顯式設定了__time__,並在目標LogStore中按實際__time__調整控制台查詢時間範圍;
如果下遊需要嚴格按日誌時間對賬,可在寫入目標端後按__time__再做過濾或統計。
樣本:源日誌的__time__為2026-06-01 10:00:00,SLS資料加工任務在2026-06-12 10:00:00將該日誌寫入目標LogStore,且加工語句未顯式修改__time__。此時,目標日誌的__time__仍為2026-06-01 10:00:00。如果同步任務配置的起止時間覆蓋2026-06-12 10:00:00,任務可能會讀取到這條日誌;但在控制台查詢目標LogStore時,如果選擇2026-06-12 10:00:00附近的時間範圍,並且控制台按__time__篩選,則可能查不到該日誌。此時應將控制台查詢時間調整到2026-06-01 10:00:00附近,或在資料加工時根據業務需要顯式設定目標日誌的__time__。
為什麼LogHub控制台查詢某欄位有值,但同步出來為空白?
Reader會按column配置,從實際拉取到的Log內容欄位、Reader內建元欄位對應和LogTag中匹配欄位名;欄位名大小寫敏感,未命中時輸出null,不會報錯。
常見原因包括:
column中配置的欄位名與原始日誌欄位key大小寫不一致;
控制台展示的是查詢分析後的別名、索引欄位或JSON展開欄位,與Reader實際拿到的原始日誌key不同;
欄位實際來自LogTag,需要按__tag__:<tagKey>配置;
配置了規則過濾語句(SPL)或加工配置後,加工後的輸出欄位名與column不完全一致。
排查時,可先通過可視化頁面的“源表欄位”和“資料預覽”確認Reader實際識別到的欄位;指令碼模式下也可臨時將column配置為["*"],觀察Reader實際拿到的普通日誌內容欄位key,再按原始key配置column。
Lindorm
使用lindorm bulk方式寫入資料,是否每次都會替換掉歷史資料?
和API方式寫入邏輯一致,同行同列會被覆蓋,其他資料不變。
Elasticsearch
如何查詢一個ES索引下的所有欄位?
通過curl命令擷取ES索引Mapping,從Mapping中提取所有欄位。
查詢Shell命令:
//es7
curl -u username:password --request GET 'http://esxxx.elasticsearch.aliyuncs.com:9200/indexname/_mapping'
//es6
curl -u username:password --request GET 'http://esxxx.elasticsearch.aliyuncs.com:9200/indexname/typename/_mapping'
結果擷取欄位:
{
"indexname": {
"mappings": {
"typename": {
"properties": {
"field1": {
"type": "text"
},
"field2": {
"type": "long"
},
"field3": {
"type": "double"
}
}
}
}
}
}
返回結果中properties下就是索引所有的欄位和屬性定義。如上索引包含field1、field2、field3三個欄位。
資料從ES離線同步至其他資料來源中時,每天同步的索引名稱不一樣,如何配置?
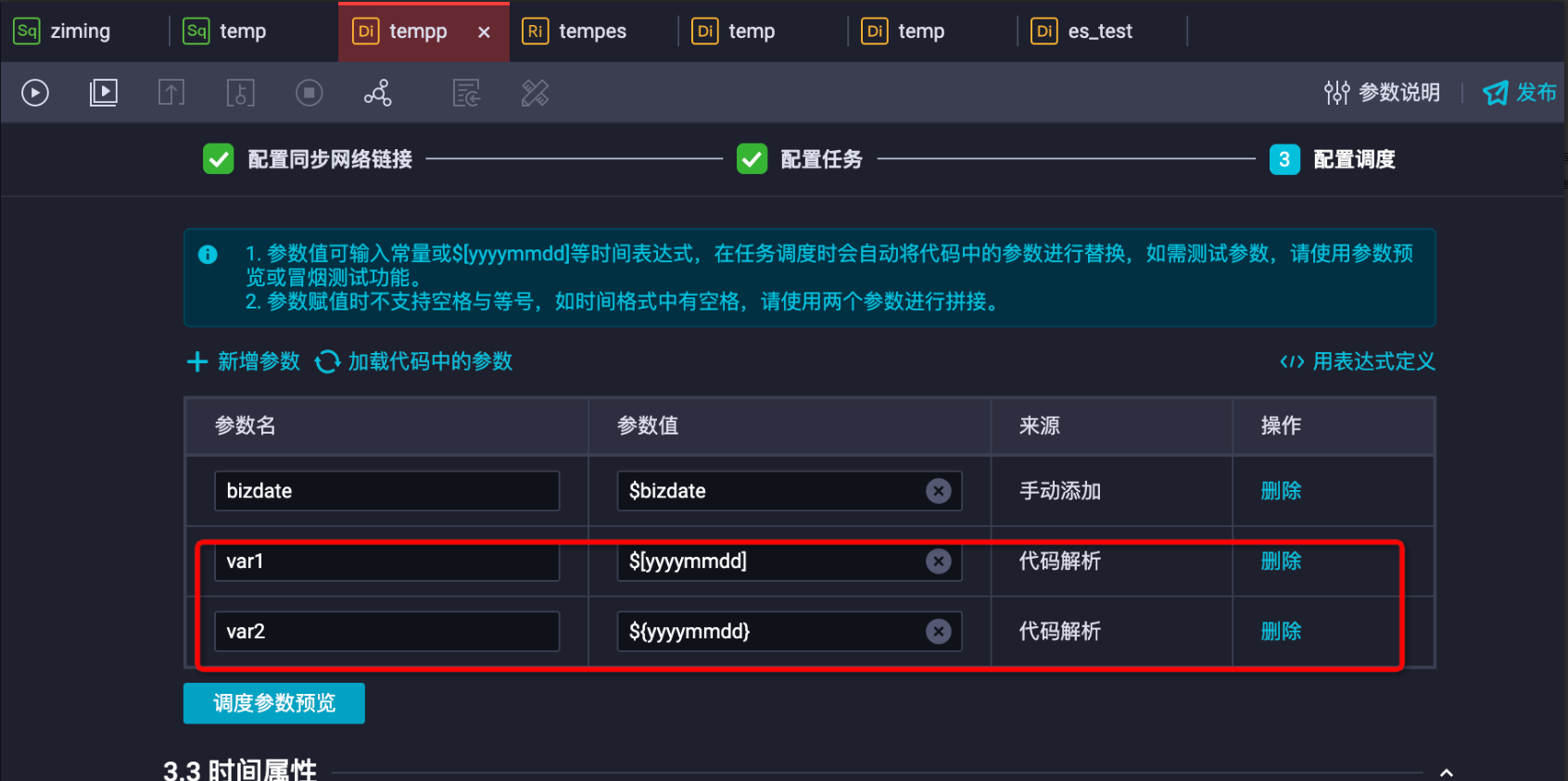
索引配置時可以加入日期調度變數,根據不同的日期計算出索引字串,實現Elasticsearch Readers索引名的自動變化,配置過程包含如下三步:定義日期變數、配置索引變數、任務發布與執行。
定義日期變數:在同步任務的調度配置中,選擇新增參數定義日期變數。如下var1配置表示任務執行時間(當天),var2表示任務的業務日期(前一天)。
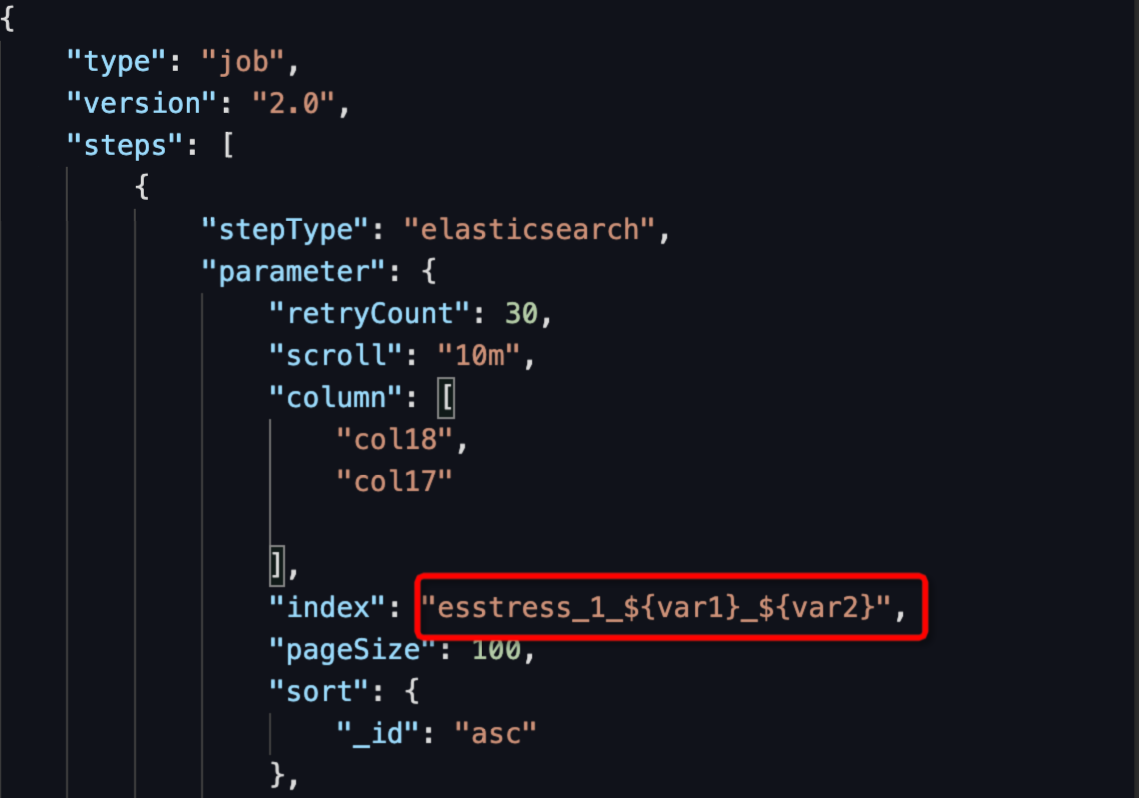
配置索引變數:將任務轉為指令碼模式,配置Elasticsearch Readers的索引,配置方式為:${變數名},如下圖所示。
任務發布與執行:執行驗證後,將任務提交發布至營運中心,以周期調度或補資料的方式運行。
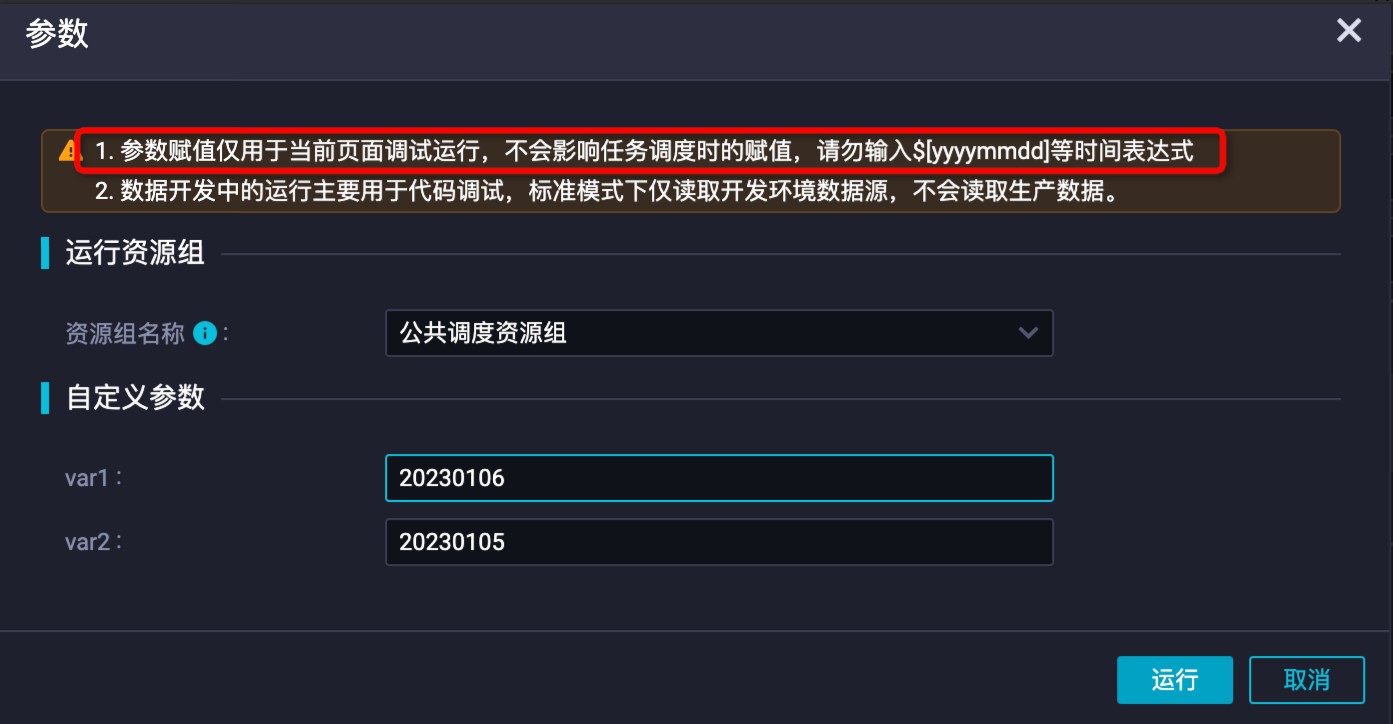
單擊帶參運行按鈕直接運行任務進行驗證,帶參運行會將任務配置中使用的調度系統參數進行替換,執行後查看日誌同步索引是否符合預期。
說明 注意在帶參運行時直接輸入參數值進行替換測試。
如果上一步驗證符合預期,則任務配置已經完成,此時可以依次單擊保存和提交按鈕將同步任務提交到生產環境。
如果是標準專案,需要單擊發布按鈕進入發布中心才能將同步任務發布到生產環境。
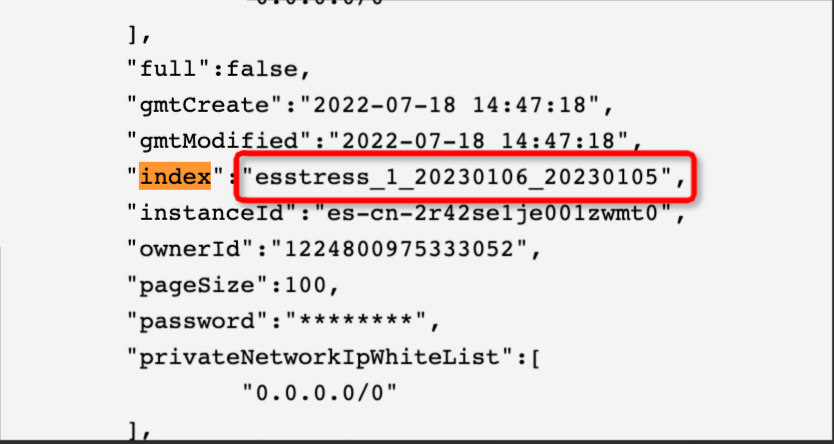
結果:如下是配置與實際啟動並執行索引結果。
指令碼索引配置為:"index": "esstress_1_${var1}_${var2}"。
運行索引替換為:esstress_1_20230106_20230105。
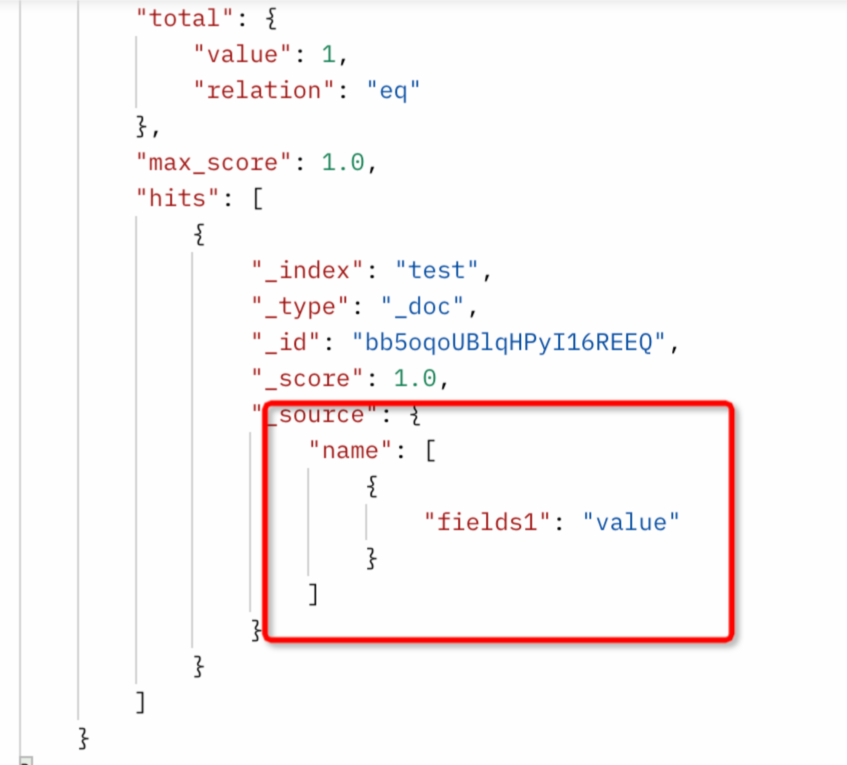
Elasticsearch Reader如何同步對象Object或Nested欄位的屬性?(例如同步object.field1)
需要同步對象欄位屬性,只支援使用指令碼模式,指令碼模式下配置如下multi,column按屬性.子屬性進行配置。
"multi":{
"multi":true
}
可以參照如下範例進行配置:
#例子:
##es內的資料
"hits": [
{
"_index": "mutiltest_1",
"_type": "_doc",
"_id": "7XAOOoMB4GR_1Dmrrust",
"_score": 1.0,
"_source": {
"level1": {
"level2": [
{
"level3": "testlevel3_1"
},
{
"level3": "testlevel3_2"
}
]
}
}
}
]
##reader配置
"parameter": {
"column": [
"level1",
"level1.level2",
"level1.level2[0]"
],
"multi":{
"multi":true
}
}
##寫端結果:1行資料3列,列順序同reader配置,
COLUMN VALUE
level1: {"level2":[{"level3":"testlevel3_1"},{"level3":"testlevel3_2"}]}
level1.level2: [{"level3":"testlevel3_1"},{"level3":"testlevel3_2"}]
level1.level2[0]: {"level3":"testlevel3_1"}
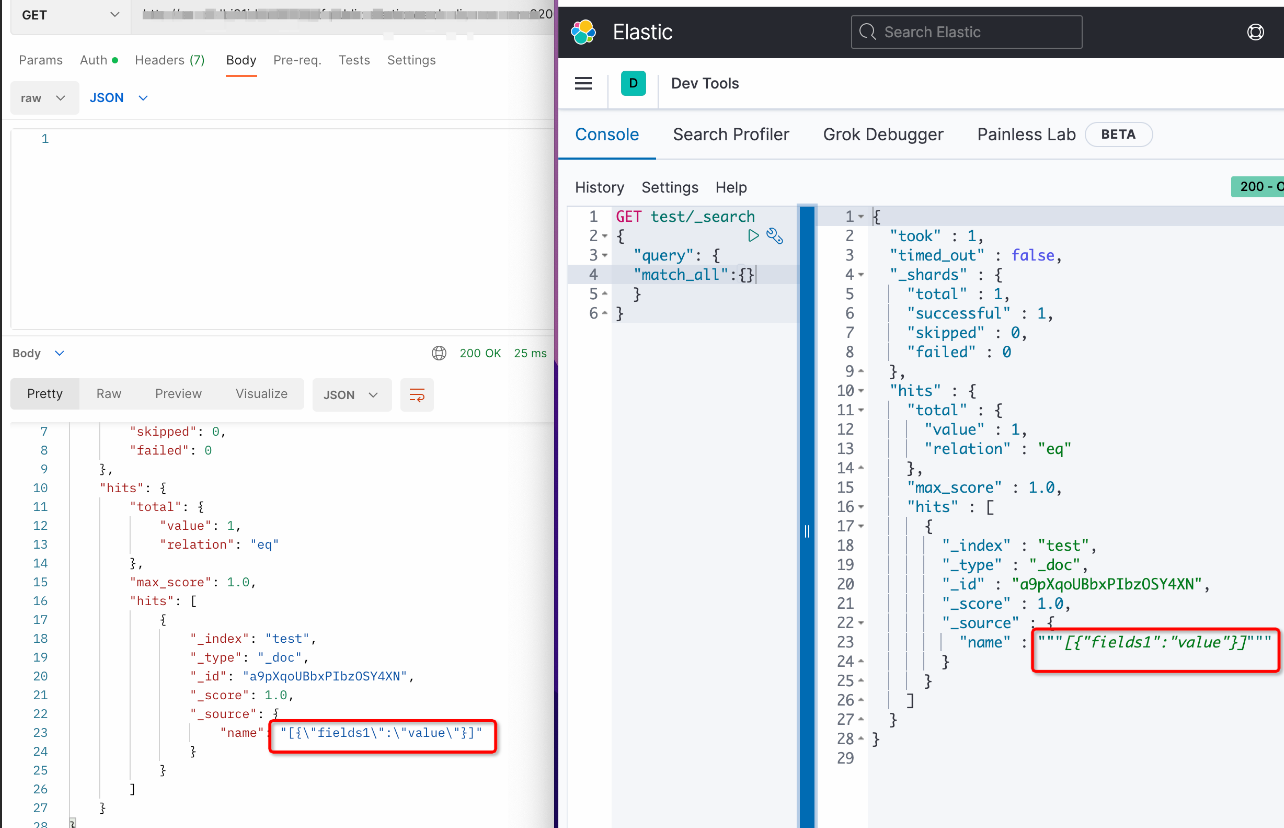
儲存在ODPS的string類型同步至ES後,兩側缺少引號,如何處理?源端JSON類型的string是否可以同步為ES中的NESTED對象?
顯示字元前後多兩個雙引號為“Kibana”工具顯示問題,實際資料並沒有前後雙引號,請使用curl命令或Postman查看實際資料情況。擷取資料curl命令如下:
//es7
curl -u username:password --request GET 'http://esxxx.elasticsearch.aliyuncs.com:9200/indexname/_mapping'
//es6
curl -u username:password --request GET 'http://esxxx.elasticsearch.aliyuncs.com:9200/indexname/typename/_mapping'
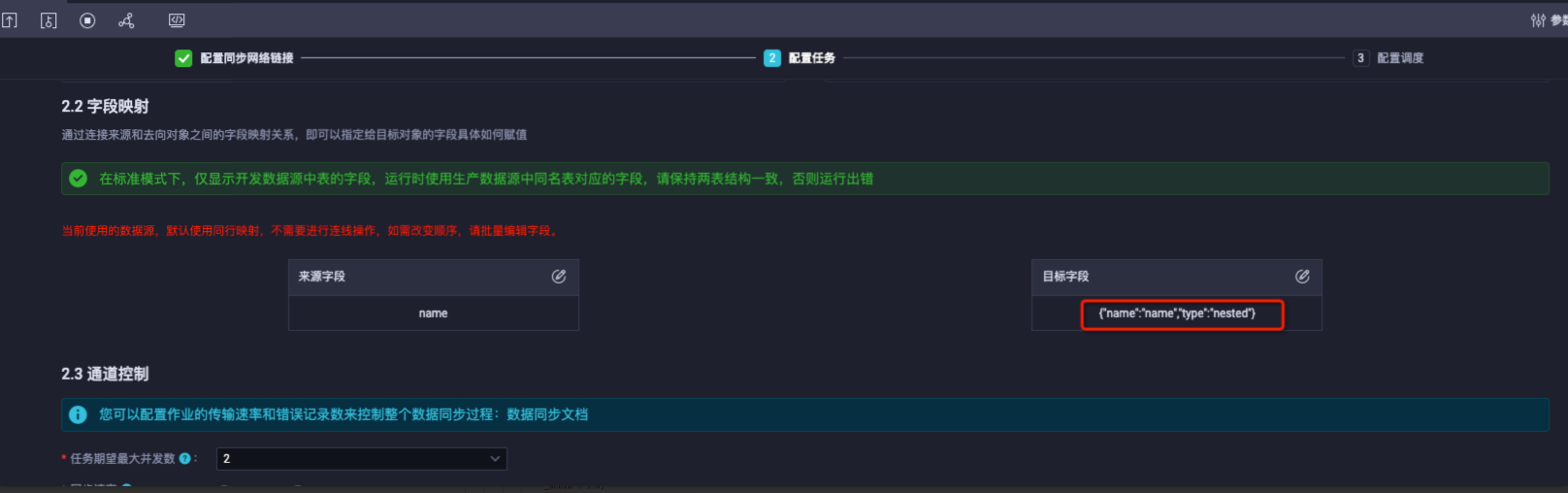
可以配置ES寫入欄位type為nested類型,以同步ODPS中JSON類型的string資料至ES儲存為nested形式。如下同步name欄位到ES中為nested格式。
同步配置:配置name的type為nested。
同步結果:name是nested物件類型。
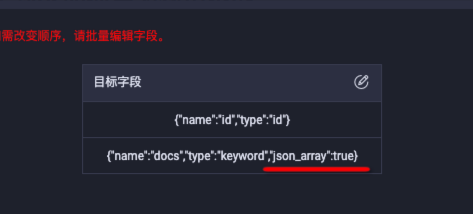
源端資料為string "[1,2,3,4,5]",如何以數組形式同步至ES中儲存?
ES期望寫入數群組類型有兩種配置方式,您可以按照源端資料形式,選擇對應的同步方式進行配置。
寫入ES為數群組類型以JSON格式解析源端資料。例如,源端資料為"[1,2,3,4,5]",配置json_array=true解析源端資料,以數組形式寫入ES欄位,配置ColumnList為json_array=true。
寫入ES為數群組類型以分隔字元解析源端資料。例如,源端資料為“1,2,3,4,5”,配置分隔字元splitter=“,”以數組形式解析並寫入ES欄位。
限制:
一個任務僅支援配置一種分隔字元,分隔字元(splitter)全域唯一,不支援多Array欄位配置不同的分隔字元,例如,源端列col1="1,2,3,4,5" , col2="6-7-8-9-10",splitter無法針對每列單獨配置使用。
splitter可以配置為正則,例如,源端列值為"6-,-7-,-8+,*9-,-10",可以配置splitter:".,.",支援嚮導模式。
嚮導模式配置:splitter: 預設為"-,-"
指令碼模式配置:
"parameter" : {
"column": [
{
"name": "col1",
"array": true,
"type": "long"
}
],
"splitter":","
}
向ES寫入資料時,會做一次無使用者名稱的提交,但仍需驗證使用者名稱,導致提交失敗,因此提交的所有請求資料都被記錄,導致審計日誌每天都會有很多,如何處理?
如何同步至ES中為Date日期類型?
有如下兩種方式配置日期寫入,您可以按需進行選擇。
根據reader端讀取欄位的內容直接寫入ES Date欄位:
配置origin:true,讀取內容直接寫入ES。
配置"format"表示在通過ES寫入建立Mapping時,欄位需要設定的format屬性。
"parameter" : {
"column": [
{
"name": "col_date",
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"origin": true
}
]
}
時區轉換:如果需要Data Integration協助您進行時區轉換,則添加Timezone參數。
"parameter" : {
"column": [
{
"name": "col_date",
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"Timezone": "UTC"
}
]
}
Elasticsearch Writer指定外部version導致寫入失敗,如何處理?
配置了type:version,目前ES不支援指定外部version功能。
"column":[
{
"name":"id",
"type":"version"
},
]
解決方案:
需要取消type":"version"配置,Elasticsearch Writer暫不支援外部version指定。
離線同步讀取Elasticsearch報錯:ERROR ESReaderUtil - ES_MISSING_DATE_FORMAT, Unknown date value. please add "dataFormat". sample value:
離線同步讀取Elasticsearch報錯:com.alibaba.datax.common.exception.DataXException: Code:[Common-00].
離線同步寫入Elasticsearch報錯:version_conflict_engine_exception.
離線同步寫入Elasticsearch報錯:illegal_argument_exception.
分析原因:
Column欄位在配置similarity、properties等進階屬性時,需要other_params才能讓外掛程式識別。
解決方案:
Column裡配置other_params,other_params裡增加similarity,如下所示:
{"name":"dim2_name",...,"other_params":{"similarity":"len_similarity"}}
ODPS Array欄位類型資料離線同步至Elasticsearch報錯:dense_vector
分析原因:
目前離線同步寫入Elasticsearch暫不支援dense_vector類型,僅支援如下類型:
ID,PARENT,ROUTING,VERSION,STRING,TEXT,KEYWORD,LONG,
INTEGER,SHORT,BYTE,DOUBLE,FLOAT,DATE,BOOLEAN,BINARY,
INTEGER_RANGE,FLOAT_RANGE,LONG_RANGE,DOUBLE_RANGE,DATE_RANGE,
GEO_POINT,GEO_SHAPE,IP,IP_RANGE,COMPLETION,TOKEN_COUNT,OBJECT,NESTED;
解決方案:
針對Elasticsearch writer不支援的類型,處理方式如下:
Elasticsearch writer配置了Settings,為什麼在建立索引時不生效?
問題原因:
#錯誤配置
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
#正確配置
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
解決方案:
Settings設定只在建立索引時才會生效,建立索引包括:索引不存在和cleanup=true兩種情況,當cleanup=true時,Settings的配置不需要使用“index”。
自建的索引中nested的屬性類型type為keyword,為什麼自動產生之後類型會變成 keyword?(自動產生是指配置cleanup=true執行同步任務)
#原來mappings
{
"name":"box_label_ret",
"properties":{
"box_id":{
"type":"keyword"
}
}
#cleanup=true重建之後,變成了
{
"box_label_ret": {
"properties": {
"box_id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}}}}
}
分析原因:
對於nested類型,Elasticsearch Writer在處理的時候只採用最上層的mappings,使ES自適應下面的複合類型,屬性type改成text ,添加fields:keyword 是ES自適應行為,不會影響ES的使用。如果在意這個mappings的格式,可參見Data Integration側同步任務能力說明。
解決方案:
您需要在同步前先建立預期的ES索引mappings,再將ES同步任務cleanup設定為false後執行同步任務。
Kafka
讀取kafka配置了endDateTime來指定所要同步的資料的截止範圍,但是在目的資料來源中發現了超過這個時間的資料
Kafka Reader在讀資料的時候,是以batch的形式進行的,在讀到的一批資料中,如果有超過endDateTime的資料,則停止同步,但是超出endDateTime的這部分資料也會被寫入到目的端資料來源。
Kafka中資料量少,但是任務出現長時間不讀取資料也不結束,一直運行中的現象是為什嗎?
分析原因:
資料量少或資料分布不均導致部分 Kafka 分區無新資料進入或新資料未達到指定讀取結束位點。由於任務的允出準則是所有分區均需達到指定讀取結束位點,這些“空閑”分區無法滿足條件,從而阻塞了整個任務的正常結束。
解決辦法:
這種情況下可以將同步結束策略設定為:1分鐘讀取不到新資料(指令碼模式下設定參數stopWhenPollEmpty 為 true 以及 stopWhenReachEndOffset 為 true),讓任務在讀取所有分區最新位點資料後直接退出,避免空跑。但是要注意如果在任務結束後分區中有時間戳記小於任務設定的讀取結束位點的記錄寫入,這部分記錄將無法被消費。
RestAPI
RestAPI Writer報錯:通過path:[]找到的JSON串格式不是數群組類型
RestAPI Writer提供兩種寫入模式,當同步多條資料的時候需要將dataMode配置為multiData,詳情請參見RestAPI Writer,同時需要在RestAPI Writer指令碼中新增參數dataPath:"data.list"。
重要 配置Column時不需要加“data.list ”首碼。
OTS Writer配置
向包含主鍵自增列的目標表寫入資料,需要如何配置OTS Writer?
OTS Writer的配置中必須包含以下兩條:
"newVersion": "true",
"enableAutoIncrement": "true",
OTS Writer中不需要配置主鍵自增列的列名。
OTS Writer中配置的primaryKey條數+column條數需要等於上遊OTS Reader資料的列數。
時序模型配置
在時序模型的配置中,如何理解_tag和is_timeseries_tag兩個欄位?
樣本:某條資料共有三個標籤,標籤為:【手機=小米,記憶體=8G,鏡頭=萊卡】。
資料匯出樣本(OTS Reader)
如果想將上述標籤合并到一起作為一列匯出,則配置為:
"column": [
{
"name": "_tags",
}
],
DataWorks會將標籤匯出為一列資料,形式如下:
["phone=xiaomi","camera=LEICA","RAM=8G"]
如果希望匯出phone標籤和camera標籤,並且每個標籤單獨作為一列匯出,則配置為:
"column": [
{
"name": "phone",
"is_timeseries_tag":"true",
},
{
"name": "camera",
"is_timeseries_tag":"true",
}
],
DataWorks會匯出兩列資料,形式如下:
xiaomi, LEICA
資料匯入樣本(OTS Writer)
現在上遊資料來源(Reader)有兩列資料:
現希望將這兩列資料都添加到標籤裡面,預期的在寫入後標籤欄位格式如下所示:則配置為:
"column": [
{
"name": "_tags",
},
{
"name": "price",
"is_timeseries_tag":"true",
},
],
第一列配置將["phone=xiaomi","camera=LEICA","RAM=8G"]整體匯入標籤欄位。
第二列配置將price=6499單獨匯入標籤欄位。
自訂表格名
離線同步任務如何自訂表格名?
如果您表名較規律,例如orders_20170310、orders_20170311和orders_20170312,按天區分表名稱,且表結構一致。您可以結合調度參數指令碼模式配置自訂表格名,實現每天淩晨自動從來源資料庫讀取前一天表資料。
例如,今天是2017年3月15日,自動從來源資料庫中讀取orders_20170314的表的資料匯入,以此類推。
在指令碼模式中,修改來源表的表名為變數,例如orders_${tablename}。由於按天區分表名稱,且需要每天讀取前一天的資料,所以在任務的參數配置中,為變數賦值為tablename=${yyyymmdd}。
表修改加列
離線同步源表有加列(修改)如何處理?
進入同步任務配置頁面,修改欄位的映射後,即可將變化的欄位更新在任務配置中,完成後,您需要重新提交執行任務,才能使變更生效。
任務配置問題
配置離線同步節點時,無法查看全部的表,該如何處理?
您在配置離線同步節點時,選擇來源地區僅預設顯示所選資料來源中的前25張表。如果數量過大,您可以輸入表名進行搜尋或使用指令碼模式開發。
欄位對應
離線任務,運行報錯:plugin xx does not specify column
出現上述報錯,有可能是因為同步任務的欄位對應配置不正確,或者是外掛程式沒有正確配置column。
檢查是否有做欄位對應。
檢查外掛程式是否有正確配置column。
非結構化資料來源,單擊資料預覽欄位無法映射,如何處理?
修改TTL
同步的資料表,是否只能使用Alter方式來修改TTL?
函數彙總
使用API方式同步的時候,支援使用來源端的(例如MaxCompute)函數做彙總嗎?例如源表有a、b兩列作為Lindorm的主鍵
API方式同步不支援使用來源端函數,需要先在來源端函數上處理好後再匯入資料。

 按鈕。將任務修改為指令碼模式。
按鈕。將任務修改為指令碼模式。


 splitter: 預設為"-,-"
splitter: 預設為"-,-"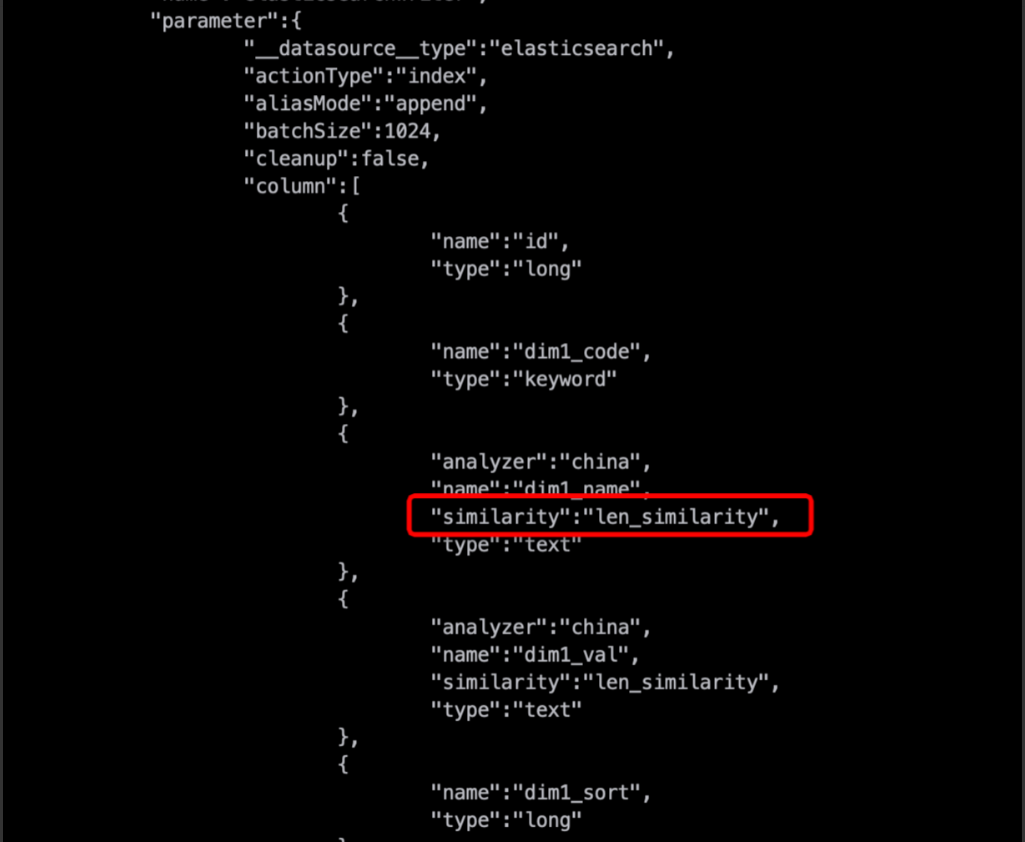

 則配置為:
則配置為: