本文介紹如何建立MySQL Source Connector,通過DataWorks將資料從阿里雲資料庫RDS MySQL版匯出至雲訊息佇列 Kafka 版執行個體的Topic。
前提條件
- 為雲訊息佇列 Kafka 版執行個體開啟Connector。更多資訊,請參見開啟Connector。重要 請確保您的雲訊息佇列 Kafka 版執行個體部署在華南1(深圳)、西南1(成都)、華北2(北京)、華北3(張家口)、華東1(杭州)、華東2(上海)或新加坡地區。
- 建立RDS MySQL執行個體。
- 建立資料庫和帳號。
- 建立資料庫表。常見的SQL語句,請參見常用語句。
- 阿里雲帳號和RAM使用者均須授予DataWorks訪問您彈性網卡ENI資源的許可權。授予許可權,請訪問雲資源訪問授權。重要 如果您使用的是RAM使用者,請確保您的帳號有以下許可權:
- AliyunDataWorksFullAccess:DataWorks所有資源的系統管理權限。
- AliyunBSSOrderAccess:購買阿里雲產品的許可權。
如何為RAM使用者添加權限原則,請參見步驟二:為RAM使用者添加許可權。
- 請確保您是阿里雲資料庫RDS MySQL版執行個體(資料來源)和雲訊息佇列 Kafka 版執行個體(資料目標)的所有者,即建立者。
- 請確保阿里雲資料庫RDS MySQL版執行個體(資料來源)和雲訊息佇列 Kafka 版執行個體(資料目標)所在的VPC網段沒有重合,否則無法成功建立同步任務。
背景資訊
您可以在雲訊息佇列 Kafka 版控制台建立資料同步任務,將您在阿里雲資料庫RDS MySQL版資料庫表中的資料同步至雲訊息佇列 Kafka 版的Topic。該同步任務將依賴阿里雲DataWorks產品實現,流程圖如下所示。
如果您在雲訊息佇列 Kafka 版控制台成功建立了資料同步任務,那麼阿里雲DataWorks會自動為您開通DataWorks產品基礎版服務(免費)、建立DataWorks專案(免費)、並建立Data Integration獨享資源群組(需付費),資源群組規格為4c8g,購買模式為訂用帳戶,時間長度為1個月並自動續約。阿里雲DataWorks的計費詳情,請參見DataWorks計費概述。
此外,DataWorks會根據您資料同步任務的配置,自動為您產生雲訊息佇列 Kafka 版的目標Topic。資料庫表和Topic是一對一的關係,對於有主鍵的表,預設6分區;無主鍵的表,預設1分區。請確保執行個體剩餘Topic數和分區數充足,不然任務會因為建立Topic失敗而導致異常。
Topic的命名格式為<配置的首碼>_<資料庫表名>,底線(_)為系統自動添加的字元。詳情如下圖所示。
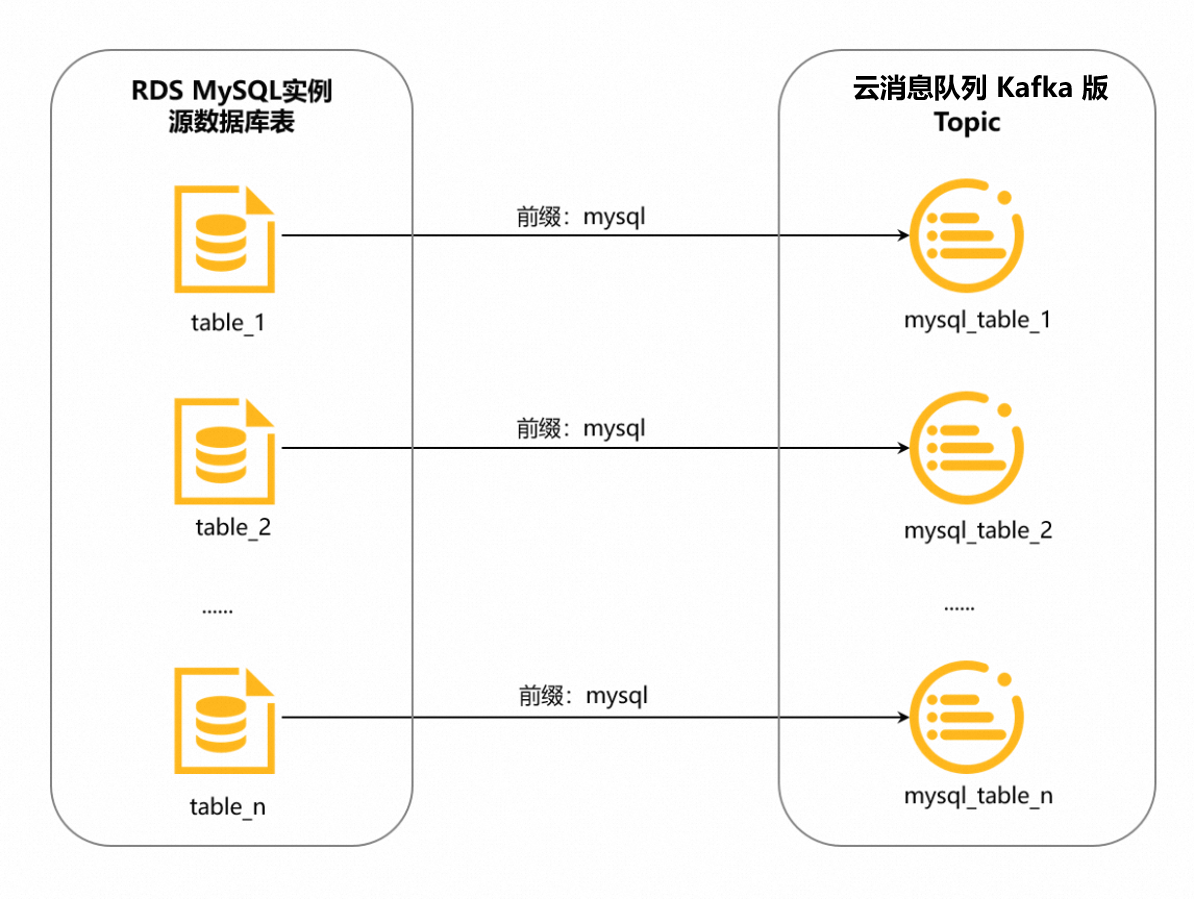
例如,您將首碼配置為mysql,需同步的資料庫表名為table_1,那麼DataWorks會自動為您產生專用Topic,用來接收table_1同步過來的資料,該Topic的名稱為mysql_table_1;table_2的專用Topic名稱為mysql_table_2,以此類推。
注意事項
- 地區說明
- 如果資料來源和目標執行個體位於不同地區,請確保您使用的帳號擁有雲企業網執行個體,且雲企業網執行個體已掛載資料來源和目標執行個體所在的VPC,並配置好流量頻寬完成網路打通。
否則,可能會建立雲企業網執行個體,並將目標執行個體和獨享資源群組ECS全部掛載到雲企業網執行個體來打通網路。這樣的雲企業網執行個體沒有配置頻寬,所以頻寬流量很小,可能導致建立同步任務過程中的網路訪問出錯,或者同步任務建立成功後,在運行過程中出錯。
- 如果資料來源和目標執行個體位於同一地區,建立資料同步任務會自動在其中一個執行個體所在VPC建立ENI,並綁定到獨享資源群組ECS上,以打通網路。
- 如果資料來源和目標執行個體位於不同地區,請確保您使用的帳號擁有雲企業網執行個體,且雲企業網執行個體已掛載資料來源和目標執行個體所在的VPC,並配置好流量頻寬完成網路打通。
- DataWorks獨享資源群組說明
- DataWorks的每個獨享資源群組可以運行最多3個同步任務。建立資料同步任務時,如果DataWorks發現您的帳號名下有資源群組的歷史購買記錄,並且啟動並執行同步任務少於3個,將使用已有資源群組運行建立的同步任務。
- DataWorks的每個獨享資源群組最多綁定兩個VPC的ENI。如果DataWorks發現已購買的資源群組綁定的ENI與需要新綁定的ENI有網段衝突,或者其他技術限制,導致使用已購買的資源群組無法建立出同步任務,此時,即使已有的資源群組啟動並執行同步任務少於3個,也將建立資源群組確保同步任務能夠順利建立。
建立並部署MySQL Source Connector
在概览頁面的资源分布地區,選擇地區。
在左側導覽列,單擊Connector 任务列表。
在Connector 任务列表頁面,從选择实例的下拉式清單選擇Connector所屬的執行個體,然後單擊创建 Connector。
- 在创建 Connector設定精靈中,完成以下操作。
- 在配置基本信息頁簽的名稱文字框,輸入Connector名稱,然後單擊下一步。
參數 描述 樣本值 名称 Connector的名稱。命名規則: - 可以包含數字、小寫英文字母和短劃線(-),但不能以短劃線(-)開頭,長度限制為48個字元。
- 同一個雲訊息佇列 Kafka 版執行個體內保持唯一。
Connector的資料同步任務必須使用名稱為connect-任務名稱的Group。如果您未手動建立該Group,系統將為您自動建立。
kafka-source-mysql 实例 預設配置為執行個體的名稱與執行個體ID。 demo alikafka_post-cn-st21p8vj**** - 在配置源服务頁簽,選擇資料來源為雲資料庫RDS MySQL版,配置以下參數,然後單擊下一步。
參數 描述 樣本值 RDS 实例所在地域 從下拉式清單中,選擇阿里雲資料庫RDS MySQL版執行個體所在的地區。 華南1(深圳) 云数据库 RDS 实例 ID 需要同步資料的阿里雲資料庫RDS MySQL版的執行個體ID。 rm-wz91w3vk6owmz**** 数据库名称 需要同步的阿里雲資料庫RDS MySQL版執行個體資料庫的名稱。 mysql-to-kafka 数据库账号 需要同步的阿里雲資料庫RDS MySQL版執行個體資料庫帳號。 mysql_to_kafka 数据库账号密码 需要同步的阿里雲資料庫RDS MySQL版執行個體資料庫帳號的密碼。 無 数据库表 需要同步的阿里雲資料庫RDS MySQL版執行個體資料庫表的名稱,多個表名以英文逗號(,)分隔。 資料庫表和目標Topic是一對一的關係。
mysql_tbl 自动添加数据表 大量新增資料庫中的其他表。當建立的新表匹配成功時,也可被識別並同步資料。 格式為Regex。例如,輸入.*,表示匹配資料庫中的所有表。
.* Topic 前缀 阿里雲資料庫RDS MySQL版資料庫表同步到雲訊息佇列 Kafka 版的Topic的命名首碼,請確保首碼全域唯一。 mysql 重要請確保阿里雲資料庫RDS MySQL版資料庫帳號有以下最小許可權:- SELECT
- REPLICATION SLAVE
- REPLICATION CLIENT
授權命令樣本:GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO '同步帳號'@'%'; //授予資料庫帳號的SELECT、REPLICATION SLAVE和REPLICATION CLIENT許可權。 - 在配置目标服务頁簽,顯示資料將同步到目標雲訊息佇列 Kafka 版執行個體,確認資訊無誤後,單擊创建。
- 在配置基本信息頁簽的名稱文字框,輸入Connector名稱,然後單擊下一步。
- 建立完成後,在Connector 任务列表頁面,找到建立的Connector ,單擊其操作列的部署。在Connector 任务列表頁面,您可以看到建立的任務状态為运行中,則說明任務建立成功。說明 如果建立失敗,請再次檢查本文前提條件中的操作是否已全部完成。
如需配置同步任務,單擊其操作列的任务配置,跳轉至DataWorks控制台完成操作。
驗證結果
- 向阿里雲資料庫RDS MySQL版資料庫表插入資料。樣本如下。
更多SQL語句,請參見常用語句。INSERT INTO mysql_tbl (mysql_title, mysql_author, submission_date) VALUES ("mysql2kafka", "tester", NOW()) - 使用雲訊息佇列 Kafka 版提供的訊息查詢功能,驗證資料能否被匯出至雲訊息佇列 Kafka 版目標Topic。查詢的具體步驟,請參見訊息查詢。雲資料庫RDS MySQL版資料庫表匯出至雲訊息佇列 Kafka 版Topic的資料樣本如下。訊息結構及各欄位含義,請參見附錄:訊息格式。
{ "schema":{ "dataColumn":[ { "name":"mysql_id", "type":"LONG" }, { "name":"mysql_title", "type":"STRING" }, { "name":"mysql_author", "type":"STRING" }, { "name":"submission_date", "type":"DATE" } ], "primaryKey":[ "mysql_id" ], "source":{ "dbType":"MySQL", "dbName":"mysql_to_kafka", "tableName":"mysql_tbl" } }, "payload":{ "before":null, "after":{ "dataColumn":{ "mysql_title":"mysql2kafka", "mysql_author":"tester", "submission_date":1614700800000 } }, "sequenceId":"1614748790461000000", "timestamp":{ "eventTime":1614748870000, "systemTime":1614748870925, "checkpointTime":1614748870000 }, "op":"INSERT", "ddl":null }, "version":"0.0.1" }