如果您需要以互動式方式執行Spark SQL,可以指定Spark Interactive型資源群組作為執行查詢的資源群組。資源群組的資源量會在指定範圍內自動擴縮容,在滿足您互動式分析需求的同時還可以降低使用成本。本文為您詳細介紹如何通過控制台、Hive JDBC、PyHive、Beeline、DBeaver等用戶端工具實現Spark SQL互動式分析。
前提條件
叢集的產品系列為企業版、基礎版或湖倉版。
叢集與OSS儲存空間位於相同地區。
已建立資料庫帳號。
如果是通過阿里雲帳號訪問,只需建立高許可權帳號。
如果是通過RAM使用者訪問,需要建立高許可權帳號和普通帳號並且將RAM使用者綁定到普通帳號上。
已安裝Java 8開發環境和Python 3.9開發環境,以便後續運行Java應用、Python應用、Beeline等用戶端。
已將用戶端IP地址添加至AnalyticDB for MySQL叢集白名單中。
注意事項
如果Spark Interactive型資源群組處於停止狀態,在執行第一個Spark SQL時叢集會重新啟動Spark Interactive型資源群組,第一個Spark SQL可能會處於較長時間的排隊等待狀態。
Spark無法讀寫INFORMATION_SCHEMA和MYSQL資料庫,因此請不要將這些資料庫作為初始串連的資料庫。
請確保提交Spark SQL作業的資料庫帳號已具有訪問目標資料庫的許可權,否則會導致查詢失敗。
準備工作
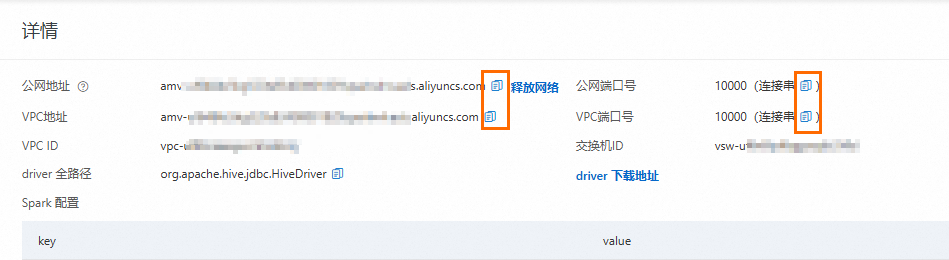
擷取Spark Interactive型資源群組的串連地址。
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊集群清單,然後單擊目的地組群ID。
在左側導覽列,單擊,單擊資源組管理頁簽。
單擊對應資源群組操作列的詳情,查看內網串連地址和公網串連地址。您可單擊串連地址後
 按鈕複製串連地址,或連接埠號碼括弧內的按鈕,複製JDBC串連串。
按鈕複製串連地址,或連接埠號碼括弧內的按鈕,複製JDBC串連串。以下兩種情況,您需要單擊公網地址後的申請網路,手動申請公網串連地址。
提交Spark SQL作業的用戶端工具部署在本地或外部伺服器。
提交Spark SQL作業的用戶端工具部署在ECS上,且ECS與AnalyticDB for MySQL不屬於同一VPC。
互動式分析
控制台
若您是自建HiveMetastore,使用控制台開發Spark SQL作業時,請在AnalyticDB for MySQL中建立一個名為default的資料庫,並選擇它作為執行Spark SQL的資料庫。
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊集群清單,然後單擊目的地組群ID。
在左側導覽列單擊。
選擇Spark引擎和建立的Spark Interactive型資源群組,執行如下Spark SQL:
SHOW DATABASES;
SDK調用
通過調用SDK的方法執行Spark SQL時,查詢結果會以檔案的形式寫入指定的OSS中,後續您可以在OSS控制台上查詢資料,或將結果檔案下載到本地查看。下文以Python語言調用SDK為例。
執行以下語句,安裝SDK。
pip install alibabacloud-adb20211201依次執行以下語句,安裝環境依賴。
pip install oss2 pip install loguru串連並執行Spark SQL。
# coding: utf-8 import csv import json import time from io import StringIO import oss2 from alibabacloud_adb20211201.client import Client from alibabacloud_adb20211201.models import ExecuteSparkWarehouseBatchSQLRequest, ExecuteSparkWarehouseBatchSQLResponse, \ GetSparkWarehouseBatchSQLRequest, GetSparkWarehouseBatchSQLResponse, \ ListSparkWarehouseBatchSQLRequest, CancelSparkWarehouseBatchSQLRequest, ListSparkWarehouseBatchSQLResponse from alibabacloud_tea_openapi.models import Config from loguru import logger def build_sql_config(oss_location, spark_sql_runtime_config: dict = None, file_format = "CSV", output_partitions = 1, sep = "|"): """ 構建ADB SQL執行的配置 :param oss_location: OSS存放SQL執行結果的路徑 :param spark_sql_runtime_config: Spark SQL社區的原生配置 :param file_format: SQL執行結果的檔案格式, 預設為CSV :param output_partitions: SQL執行結果的分區數, 如果需要輸出大量結果, 必須增加輸出時的分區數避免單個檔案過大 :param sep: CSV檔案的分隔字元, 非CSV檔案忽略 :return: SQL執行的配置 """ if oss_location is None: raise ValueError("oss_location is required") if not oss_location.startswith("oss://"): raise ValueError("oss_location must start with oss://") if file_format != "CSV" and file_format != "PARQUET" and file_format != "ORC" and file_format != "JSON": raise ValueError("file_format must be CSV, PARQUET, ORC or JSON") runtime_config = { # sql output config "spark.adb.sqlOutputFormat": file_format, "spark.adb.sqlOutputPartitions": output_partitions, "spark.adb.sqlOutputLocation": oss_location, # csv config "sep": sep } if spark_sql_runtime_config: runtime_config.update(spark_sql_runtime_config) return runtime_config def execute_sql(client: Client, dbcluster_id: str, resource_group_name: str, query: str, limit = 10000, runtime_config: dict = None, schema="default" ): """ 在Spark Interactive型資源群組中執行SQL :param client: 阿里雲用戶端 :param dbcluster_id: 叢集的ID :param resource_group_name: 叢集的資源群組,要求必須是Spark Interactive資源群組 :param schema: SQL執行的預設的資料庫名稱, 不填寫為default :param limit: SQL執行的結果的行數限制 :param query: 執行的SQL語句, 使用分號分隔多個SQL語句 :return: """ # 組裝請求體 req = ExecuteSparkWarehouseBatchSQLRequest() # 叢集ID req.dbcluster_id = dbcluster_id # 資源群組名稱 req.resource_group_name = resource_group_name # SQL執行逾時時間 req.execute_time_limit_in_seconds = 3600 # 執行SQL的資料庫名稱 req.schema = schema # SQL業務代碼 req.query = query # 返回結果行數 req.execute_result_limit = limit if runtime_config: # SQL執行的配置 req.runtime_config = json.dumps(runtime_config) # 執行SQL並擷取query_id resp: ExecuteSparkWarehouseBatchSQLResponse = client.execute_spark_warehouse_batch_sql(req) logger.info("Query execute submitted: {}", resp.body.data.query_id) return resp.body.data.query_id def get_query_state(client, query_id): """ 查詢SQL執行的狀態 :param client: 阿里雲用戶端 :param query_id: SQL執行的ID :return: SQL執行的狀態和結果 """ req = GetSparkWarehouseBatchSQLRequest(query_id=query_id) resp: GetSparkWarehouseBatchSQLResponse = client.get_spark_warehouse_batch_sql(req) logger.info("Query state: {}", resp.body.data.query_state) return resp.body.data.query_state, resp def list_history_query(client, db_cluster, resource_group_name, page_num): """ 查詢Spark Interactive資源群組中執行的SQL的歷史 :param client: 阿里雲用戶端 :param db_cluster: 叢集的ID :param resource_group_name: 資源群組名稱 :param page_num: 分頁查詢的頁數 :return: 是否有SQL, 有的話代表可以進入下一頁查詢 """ req = ListSparkWarehouseBatchSQLRequest(dbcluster_id=db_cluster, resource_group_name=resource_group_name, page_number = page_num) resp: ListSparkWarehouseBatchSQLResponse = client.list_spark_warehouse_batch_sql(req) # 如果沒有查詢到SQL, 返回false. 否則返回true. 預設每頁10條 if resp.body.data.queries is None: return True # 列印查詢到的SQL for query in resp.body.data.queries: logger.info("Query ID: {}, State: {}", query.query_id, query.query_state) logger.info("Total queries: {}", len(resp.body.data.queries)) return len(resp.body.data.queries) < 10 def list_csv_files(oss_client, dir): for obj in oss_client.list_objects_v2(dir).object_list: if obj.key.endswith(".csv"): logger.info(f"reading {obj.key}") # read oss file content csv_content = oss_client.get_object(obj.key).read().decode('utf-8') csv_reader = csv.DictReader(StringIO(csv_content)) # Print the CSV content for row in csv_reader: print(row) if __name__ == '__main__': logger.info("ADB Spark Batch SQL Demo") # AccessKey ID,請填寫實際值 _ak = "LTAI****************" # AccessKey Serect,請填寫實際值 _sk = "yourAccessKeySecret" # 地區ID,請填寫實際值 _region= "cn-shanghai" # 叢集ID,請填寫實際值 _db = "amv-uf6485635f****" # 資源群組名稱,請填寫實際值 _rg_name = "testjob" # client config client_config = Config( # Alibaba Cloud AccessKey ID access_key_id=_ak, # Alibaba Cloud AccessKey Secret access_key_secret=_sk, # The endpoint of the ADB service # adb.ap-southeast-1.aliyuncs.com is the endpoint of the ADB service in the Singapore region # adb-vpc.ap-southeast-1.aliyuncs.com used in the VPC scenario endpoint=f"adb.{_region}.aliyuncs.com" ) # 建立阿里雲用戶端 _client = Client(client_config) # SQL執行的配置 _spark_sql_runtime_config = { "spark.sql.shuffle.partitions": 1000, "spark.sql.autoBroadcastJoinThreshold": 104857600, "spark.sql.sources.partitionOverwriteMode": "dynamic", "spark.sql.sources.partitionOverwriteMode.dynamic": "dynamic" } _config = build_sql_config(oss_location="oss://testBucketName/sql_result", spark_sql_runtime_config = _spark_sql_runtime_config) # 需要執行的SQL _query = """ SHOW DATABASES; SELECT 100; """ _query_id = execute_sql(client = _client, dbcluster_id=_db, resource_group_name=_rg_name, query=_query, runtime_config=_config) logger.info(f"Run query_id: {_query_id} for SQL {_query}.\n Waiting for result...") # 等待SQL執行完成 current_ts = time.time() while True: query_state, resp = get_query_state(_client, _query_id) """ query_state 有如下幾種狀態: - PENDING: 在服務隊列排隊中, 此時Spark Interactive型資源群組正在啟動 - SUBMITTED: 提交到了Spark Interactive型資源群組 - RUNNING: SQL正在執行 - FINISHED: SQL執行完成, 沒有報錯 - FAILED: SQL執行失敗 - CANCELED: SQL執行被取消 """ if query_state == "FINISHED": logger.info("query finished success") break elif query_state == "FAILED": # 列印失敗資訊 logger.error("Error Info: {}", resp.body.data) exit(1) elif query_state == "CANCELED": # 列印取消資訊 logger.error("query canceled") exit(1) else: time.sleep(2) if time.time() - current_ts > 600: logger.error("query timeout") # 執行時間超過10分鐘, 取消SQL執行 _client.cancel_spark_warehouse_batch_sql(CancelSparkWarehouseBatchSQLRequest(query_id=_query_id)) exit(1) # 一個Query可以包含多個語句, 列舉所有的語句 for stmt in resp.body.data.statements: logger.info( f"statement_id: {stmt.statement_id}, result location: {stmt.result_uri}") # 查看結果的範例程式碼 _bucket = stmt.result_uri.split("oss://")[1].split("/")[0] _dir = stmt.result_uri.replace(f"oss://{_bucket}/", "").replace("//", "/") oss_client = oss2.Bucket(oss2.Auth(client_config.access_key_id, client_config.access_key_secret), f"oss-{_region}.aliyuncs.com", _bucket) list_csv_files(oss_client, _dir) # 查詢在Spark Interactive資源群組中執行的所有的SQL,可以分頁查詢 logger.info("List all history query") page_num = 1 no_more_page = list_history_query(_client, _db, _rg_name, page_num) while no_more_page: logger.info(f"List page {page_num}") page_num += 1 no_more_page = list_history_query(_client, _db, _rg_name, page_num)參數說明:
_ak:阿里雲帳號或具備AnalyticDB for MySQL存取權限的RAM使用者的AccessKey ID。如何擷取AccessKey ID和AccessKey Secret,請參見帳號與許可權。
_sk:阿里雲帳號或具備AnalyticDB for MySQL存取權限的RAM使用者的AccessKey Secret。如何擷取AccessKey ID和AccessKey Secret,請參見帳號與許可權。
region:AnalyticDB for MySQL叢集所屬地區ID。
_db:AnalyticDB for MySQL叢集ID。
_rg_name:Spark Interactive型資源群組的名稱。
oss_location(可選):查詢結果檔案儲存的OSS路徑。
若不填寫該參數,您僅可以在頁面,對應SQL查詢語句的日誌中,查看到5行資料。
應用程式
Hive JDBC
在pom.xml中配置Maven依賴。
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.3.9</version> </dependency>建立串連並執行Spark SQL。
public class java { public static void main(String[] args) throws Exception { Class.forName("org.apache.hive.jdbc.HiveDriver"); String url = "<串連地址>"; Connection con = DriverManager.getConnection(url, "<使用者名稱>", "<密碼>"); Statement stmt = con.createStatement(); ResultSet tables = stmt.executeQuery("show tables"); List<String> tbls = new ArrayList<>(); while (tables.next()) { System.out.println(tables.getString("tableName")); tbls.add(tables.getString("tableName")); } } }參數說明:
串連地址:準備工作擷取的Spark Interactive型資源群組JDBC串連串。其中
default需替換成實際串連的資料庫名稱。使用者名稱:AnalyticDB for MySQL的資料庫帳號。
密碼:AnalyticDB for MySQL資料庫帳號的密碼。
PyHive
安裝Python Hive用戶端。
pip install pyhive建立串連並執行Spark SQL。
from pyhive import hive from TCLIService.ttypes import TOperationState cursor = hive.connect( host='<串連地址>', port=<連接埠號碼>, username='<資源群組名稱>/<使用者名稱>', password='<密碼>', auth='CUSTOM' ).cursor() cursor.execute('show tables') status = cursor.poll().operationState while status in (TOperationState.INITIALIZED_STATE, TOperationState.RUNNING_STATE): logs = cursor.fetch_logs() for message in logs: print(message) # If needed, an asynchronous query can be cancelled at any time with: # cursor.cancel() status = cursor.poll().operationState print(cursor.fetchall())參數說明:
串連地址:準備工作擷取的Spark Interactive型資源群組串連地址。
連接埠號碼:Spark Interactive型資源群組的連接埠號碼,固定為10000。
資源群組名稱:Spark Interactive型資源群組的名稱。
使用者名稱:AnalyticDB for MySQL的資料庫帳號。
密碼:AnalyticDB for MySQL資料庫帳號的密碼。
用戶端
除了在本文中詳細介紹的Beeline、DBeaver、DBVisualizer、Datagrip用戶端外,您還可以在Airflow、Azkaban、DolphinScheduler等工作流程調度工具中執行互動式分析。
Beeline
串連Spark Interactive型資源群組。
命令格式如下:
!connect <串連地址> <使用者名稱> <密碼>串連地址:準備工作擷取的Spark Interactive型資源群組JDBC串連串。其中
default需替換成實際串連的資料庫名稱。使用者名稱:AnalyticDB for MySQL的資料庫帳號。
密碼:AnalyticDB for MySQL資料庫帳號的密碼。
樣本:
!connect jdbc:hive2://amv-bp1c3em7b2e****-spark.ads.aliyuncs.com:10000/adb_test spark_resourcegroup/AdbSpark14**** Spark23****返回結果:
Connected to: Spark SQL (version 3.2.0) Driver: Hive JDBC (version 2.3.9) Transaction isolation: TRANSACTION_REPEATABLE_READ執行Spark SQL。
SHOW TABLES;
DBeaver
開啟DBeaver用戶端,單擊。
在串連到資料庫頁面,選擇Apache Spark,單擊下一步。
配置Hadoop/Apache Spark 串連設定,參數說明如下:
參數
說明
串連方式
串連方式選擇為URL。
JDBC URL
請填寫準備工作中擷取的JDBC串連串。
重要串連串中的
default需替換為實際的資料庫名。使用者名稱
AnalyticDB for MySQL的資料庫帳號。
密碼
AnalyticDB for MySQL資料庫帳號的密碼。
上述參數配置完成後,單擊測試連接。
重要首次測試連接時,DBeaver會自動擷取需要下載的驅動資訊,擷取完成後,請單擊下載,下載相關驅動。
測試連接成功後,單擊完成。
在資料庫導航頁簽下,展開對應資料來源的子目錄,單擊對應資料庫。
在右側代碼框中輸入SQL語句,並單擊
 按鈕運行。
按鈕運行。SHOW TABLES;返回結果如下:
+-----------+-----------+-------------+ | namespace | tableName | isTemporary | +-----------+-----------+-------------+ | db | test | [] | +-----------+-----------+-------------+
DBVisualizer
在Driver Manage頁面,選擇Hive,單擊
 按鈕。
按鈕。在Driver Settings頁簽下,配置如下參數:
參數
說明
Name
Hive資料來源名稱,您可以自訂名稱。
URL Format
請填寫準備工作中擷取的JDBC串連串。
重要串連串中的
default需替換為實際的資料庫名。Driver Class
Hive驅動,固定選擇為org.apache.hive.jdbc.HiveDriver。
重要參數配置完成後,請單擊Start Download,下載對應驅動。
驅動下載完成後,單擊。
在Create Database Connection from Database URL對話方塊中填寫以下參數:
參數
說明
Database URL
請填寫準備工作中擷取的JDBC串連串。
重要串連串中的
default需替換為實際的資料庫名。Driver Class
選擇步驟3建立的Hive資料來源。
在Connection頁面配置以下串連參數,並單擊Connect。
參數
說明
Name
預設與步驟3建立的Hive資料來源同名,您可以自訂名稱。
Notes
備忘資訊。
Driver Type
選擇Hive。
Database URL
請填寫準備工作中擷取的JDBC串連串。
重要串連串中的
default需替換為實際的資料庫名。Database Userid
AnalyticDB for MySQL的資料庫帳號。
Database Password
AnalyticDB for MySQL資料庫帳號的密碼。
說明其他參數無需配置,使用預設值即可。
串連成功後,在Database頁簽下,展開對應資料來源的子目錄,單擊對應資料庫。
在右側代碼框中輸入SQL語句,並單擊
 按鈕運行。
按鈕運行。SHOW TABLES;返回結果如下:
+-----------+-----------+-------------+ | namespace | tableName | isTemporary | +-----------+-----------+-------------+ | db | test | false | +-----------+-----------+-------------+
Datagrip
開啟Datagrip用戶端,單擊,建立專案。
添加資料來源。
單擊
 按鈕,選擇。
按鈕,選擇。在彈出的Data Sources and Drivers對話方塊中配置如下參數後,單擊OK。
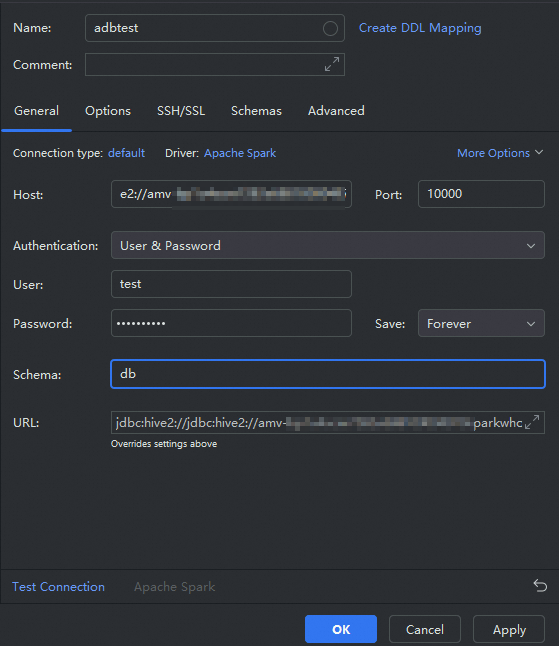
參數
說明
Name
資料來源名稱,您可以自訂。本文樣本為
adbtest。Host
請填寫準備工作中擷取的JDBC串連串。
重要串連串中的
default需替換為實際的資料庫名。Port
Spark Interactive型資源群組的連接埠號碼,固定為10000。
User
AnalyticDB for MySQL的資料庫帳號。
Password
AnalyticDB for MySQL資料庫帳號的密碼。
Schema
AnalyticDB for MySQL叢集的資料庫名稱。
執行Spark SQL。
在資料來源列表中,右擊步驟2建立的資料來源,選擇。
在右側Console面板中執行Spark SQL。
SHOW TABLES;