AnalyticDB for MySQLPaging Cache功能,通過緩衝機制提高了使用LIMIT、OFFSET和ORDER BY的巨量資料量分頁查詢效率,可以解決深分頁查詢的效能問題和資源瓶頸。本文介紹了如何在分頁查詢中使用Paging Cache功能。
前提條件
叢集的核心版本為3.2.3及以上版本。
請在雲原生資料倉儲AnalyticDB MySQL控制台集群資訊頁面的配寘資訊地區,查看和升級核心版本。
什麼是Paging Cache
Paging Cache,即深分頁效能最佳化,是AnalyticDB for MySQL為瞭解決深分頁的效能問題推出的一種緩衝策略。首次發起某個分頁查詢請求時,會從資料庫查詢資料並將查詢結果儲存在暫存資料表中,後續相同Pattern的分頁查詢可以直接讀取緩衝表,避免了重複執行排序操作。這不僅有效解決了深分頁查詢的效能問題,還避免了因ORDER BY引發的記憶體溢出問題。此外,AnalyticDB for MySQL還會根據淘汰策略自動清理不再被使用的 Paging Cache,確保資源得到合理利用。
適用於以下情境。
使用方法
配置快取資料庫
使用Paging Cache功能緩衝查詢結果前,建議先指定一個資料庫來儲存分頁查詢的臨時緩衝表。若未指定資料庫,則會在當前串連的內部資料庫下儲存臨時緩衝表。臨時緩衝表會在Paging Cache啟用時自動產生。
快取資料庫不能設定為外部資料庫(External Database)。
以下樣本指定資料庫paging_cache作為快取資料庫。您也可以指定其他任意資料庫。
SET ADB_CONFIG PAGING_CACHE_SCHEMA=paging_cache;在分頁查詢中啟用Paging Cache功能
當多個分頁查詢具有相同的查詢模式(Pattern)時,可以通過在查詢語句前添加Hint來利用Paging Cache功能以提高效能。首次發起某個分頁查詢請求時,添加Hint,會產生一個臨時緩衝表來儲存分頁查詢結果。後續相同Pattern的分頁查詢,只需在查詢語句前添加相同的Hint,即可直接從緩衝表中讀取資料,無需再次訪問資料庫。
限制條件
去掉LIMIT和OFFSET子句後,分頁查詢的資料行數需少於1億行。
若查詢的資料行數超過1億行,請提交工單聯絡支援人員調整資料行數限制。
啟用方法
通過以下任意一種Hint為查詢啟用Paging Cache功能。
paging_id=<paging_id>paging_id用來標識一組相關的分頁查詢(即一組Pattern相同,僅LIMIT和OFFSET參數不同的分頁查詢)。用戶端需產生一個Unique ID來唯一標識一組分頁查詢的緩衝。當查詢的
paging_id不存在時,會產生緩衝。當查詢的
paging_id存在,且查詢Pattern與paging_id對應的查詢Pattern匹配時,查詢會命中緩衝;當查詢的
paging_id存在,但查詢Pattern與paging_id對應的查詢Pattern不匹配時,查詢會報錯。您可以通過查詢已有的緩衝確認paging_id是否已被使用。
說明paging_id命名規則:以字母或底線(_)開頭,可包含字母、數字以及底線(_),長度為1到127個字元。不能包含引號、驚嘆號(!)和空格,不能是SQL保留字。以下樣本表示使用Paging Cache功能分頁查詢結果的ID是
paging123。/*paging_id=paging123*/ SELECT * FROM t_order ORDER BY id LIMIT 0, 100;paging_cache_enabled=true採用這種方式,不需要頻繁修改Hint。服務端基於SQL語句的Pattern,在去除
LIMIT和OFFSET子句後,自動產生一個paging_id來標識是否屬於同一組分頁查詢。由於該方法依賴於Pattern匹配,其靈活性會受到一定限制。如果相同Pattern(排除LIMIT和OFFSET子句)的查詢快取不存在,則會產生緩衝。如果相同Pattern(排除LIMIT和OFFSET子句)的查詢已產生緩衝,則會直接查詢快取。
樣本如下:
/*paging_cache_enabled=true*/ SELECT * FROM t_order ORDER BY id LIMIT 0, 100;
如果遇到緩衝產生失敗,則必須先清理分頁查詢快取,再重新發起分頁查詢請求以產生新的快取資料。
查詢已有的緩衝
擷取當前叢集中所有的分頁緩衝資訊,包括但不限於paging_id、緩衝大小、緩衝狀態等。
SELECT * FROM INFORMATION_SCHEMA.KEPLER_PAGING_CACHE_STATUS_MERGED;設定緩衝最大個數
緩衝的最大個數,預設值為100。
SET ADB_CONFIG PAGING_CACHE_MAX_TABLE_COUNT=100;總個數超限後,再建立緩衝系統會報錯。報錯資訊如下:
Paging cache count exceeds the limit. Please clean up unused caches or increase the related parameter using SET ADB_CONFIG PAGING_CACHE_MAX_TABLE_COUNT=xxx.請根據報錯提示資訊清理不再使用的緩衝或調整緩衝的最大數量。
設定緩衝有效時間
您可以設定緩衝有效時間。超過有效時間後,緩衝失效,後續同一Pattern的查詢會重新訪問資料庫查詢資料,並更新緩衝表。緩衝有效時間的單位為秒(s),通常應用在報表並發控制情境中。
以paging_cache_validity_interval=300為例,標識了緩衝有效時間為300秒,即緩衝在產生300秒之後失效。樣本如下:
/*paging_cache_enabled=true, paging_cache_validity_interval=300*/ SELECT * FROM t_order ORDER BY id LIMIT 0, 100;清理分頁查詢快取
在使用Paging Cache緩衝分頁查詢結果時,快取資料會儲存在AnalyticDB for MySQL熱儲存空間中。如果不再使用緩衝,可以清理緩衝以節省儲存空間。
手動清理
指定Pattern的分頁查詢快取
設定
paging_cache_enabled=true,invalidate_paging_cache=true,清理SQL Pattern對應分頁查詢的緩衝結果。樣本如下:
/*paging_cache_enabled=true,invalidate_paging_cache=true*/ SELECT * FROM t_order ORDER BY id LIMIT 0, 100;指定
paging_id的分頁查詢快取指定
paging_id,刪除該paging_id標識的分頁查詢快取。樣本如下:
CLEAN_PAGING_CACHE paging123;說明paging_id可以通過查詢已有的緩衝擷取。
自動清理
指定緩衝的到期時間閾值,刪除指定時間內未訪問的分頁查詢快取。到期時間閾值的預設值為600,單位為秒(s),即10分鐘未被訪問則會被自動清除。
SET ADB_CONFIG PAGING_CACHE_EXPIRATION_TIME=600;全域關閉Paging Cache功能
關閉該功能後,所有Paging Cache相關Hint都將失效,分頁查詢將直接使用原始查詢鏈路處理。
SET ADB_CONFIG PAGING_CACHE_ENABLE=false;關閉Paging Cache功能後,可通過SHOW ADB_CONFIG KEY=PAGING_CACHE_ENABLE; 查詢配置是否生效。
常見報錯
Paging cache prepare failed, and cache is not available
完整報錯樣本如下:
Paging cache prepare failed, and cache is not available. Please use /*paging_cache_enabled=true,invalidate_paging_cache=true*/ to clean the unavailable cache or set a specific pagingId with /*paging_id=xxx*/ to gen a new cache. Note that the old and new cache data may be inconsistent.報錯原因:使用Paging Cache功能查詢過程中,可能會遇到一些異常情況,例如節點重啟、節點擴縮容等。如果分頁查詢命中了產生失敗的緩衝,服務端預設不會重新查詢資料庫,也不會自動重建新的緩衝,而是會拋出異常。
解決方案:如果遇到此異常,重建緩衝後並不保證資料一致性。資料匯出情境下,建議清理已經匯出的資料和停用緩衝後,重建緩衝。其他情境下,建議清理停用緩衝或指定新的paging_id,重建緩衝。
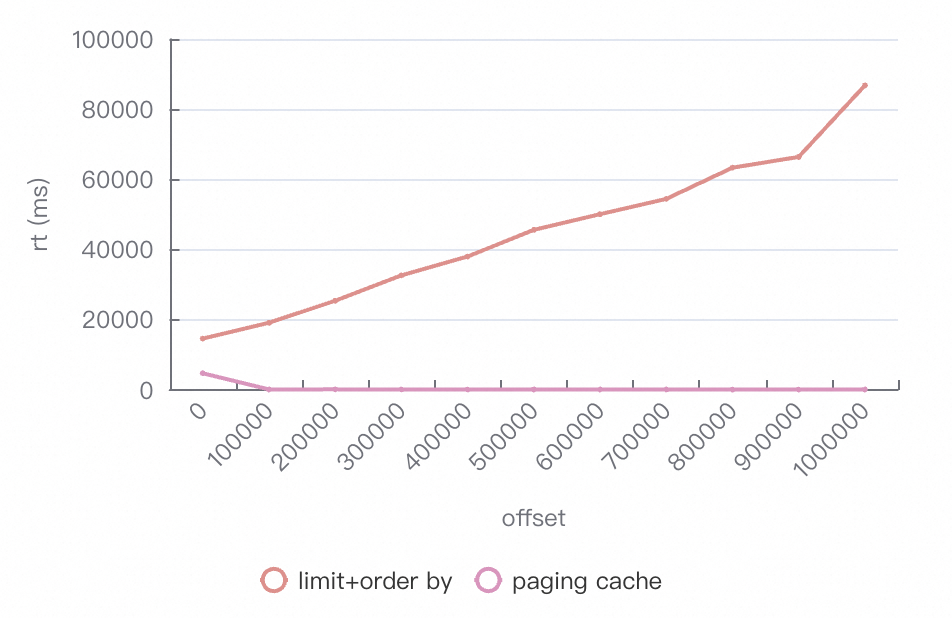
效能對比
基於TPC-H 100G的資料集,評估資料匯出情境中Paging Cache對分頁查詢的最佳化效果。
本次測試匯出資料100萬條,每頁10萬條資料,第一頁的分頁SQL如下:
-- 普通分頁查詢,不使用Paging Cache功能
SELECT * FROM lineitem ORDER BY l_orderkey,l_linenumber LIMIT 0,100000;
-- 分頁查詢,使用了Paging Cache功能(本例是在資料匯出情境,去掉了本身並不是業務必須的ORDER BY)
/*paging_cache_enabled=true*/ SELECT * FROM lineitem LIMIT 0,100000;測試結果:
單並發執行,整個匯出過程,普通分頁查詢平均RT為54391ms。開啟Paging Cache深分頁效能最佳化後,平均RT在525ms。效能提升約103倍,同時CPU和記憶體使用量率大幅降低。
該結果說明使用Paging Cache深分頁效能最佳化,不僅極大地縮短了資料匯出過程中的平均回應時間,而且有效地降低了系統的CPU和記憶體負擔。