本文適用於已安裝共用GPU基礎版的叢集。本文介紹如何解決共用GPU專業版叢集升級後共用GPU調度失效的問題。
問題描述
升級ACK中的共用GPU專有版叢集後,kube-scheduler組件中關於ack-cgpu應用的extender配置會丟失,導致叢集的GPU共用調度無法正常工作。
問題原因
ACK中的共用GPU專有版叢集升級時,現有配置將被預設配置覆蓋,導致extender配置丟失。
解決方案
請參考下列步驟進行處理。
步驟一:檢查extender配置
依次登入所有Master節點。
依次檢查Master節點中的文檔
/etc/kubernetes/manifests/kube-scheduler.yaml,查看是否存在類似下圖中與scheduler-extender-config.json相關的配置。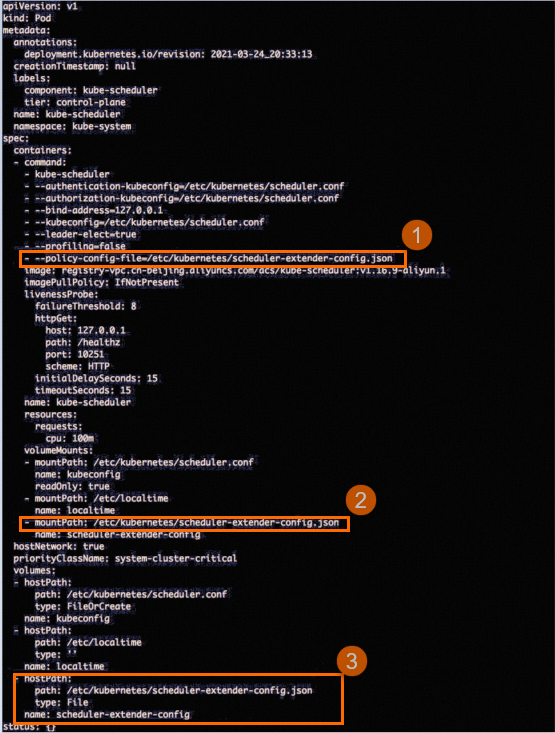
如果不存在上圖中相關的配置,請執行步驟二進行修複。如果存在,則說明extender配置未丟失,無需進行修複,請加入釘群(釘群號:30421250),聯絡產品技術專家進行諮詢。
步驟二:運行修複程式
登入任意一個Master節點。
在Master節點上執行以下命令,下載修複工具。
sudo wget http://aliacs-k8s-cn-beijing.oss-cn-beijing.aliyuncs.com/gpushare/extender-config-update-linux -O /usr/local/bin/extender-config-update執行以下命令,為修複工具添加可執行許可權。
sudo chmod +x /usr/local/bin/extender-config-update執行以下命令,運行修複工具。
sudo extender-config-update執行以下命令,檢查kube-scheduler的運行狀態,確認其已重啟,並且目前狀態為運行(Running)狀態。
kubectl get po -n kube-system -l component=kube-scheduler系統顯示類似如下,其中AGE為14s,表示組件剛剛重啟,說明修複工具已生效。
NAME READY STATUS RESTARTS AGE kube-scheduler-cn-beijing.192.168.8.37 1/1 Running 0 14s kube-scheduler-cn-beijing.192.168.8.38 1/1 Running 0 14s kube-scheduler-cn-beijing.192.168.8.39 1/1 Running 0 14s參考步驟一:檢查extender配置,確認
kube-scheduler.yaml檔案中extender相關配置已經複原,然後執行步驟三。
步驟三:結果驗證
登入到任意一個Master節點。
建立檔案/tmp/cgpu-test.yaml用於測試。
將以下內容寫入
/tmp/cgpu-test.yaml檔案。apiVersion: batch/v1 kind: Job metadata: name: tensorflow-mnist spec: parallelism: 1 template: metadata: labels: app: tensorflow-mnist spec: containers: - name: tensorflow-mnist image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - python - tensorflow-sample-code/tfjob/docker/mnist/main.py - --max_steps=100000 - --data_dir=tensorflow-sample-code/data resources: limits: aliyun.com/gpu-mem: 3 # 總共申請3GiB顯存 workingDir: /root restartPolicy: Never執行以下命令,建立任務。
kubectl create -f /tmp/cgpu-test.yaml執行以下命令,確認Pod處於運行狀態。
kubectl get po -l app=tensorflow-mnist系統顯示如下。
NAME READY STATUS RESTARTS AGE tensorflow-mnist-5htxh 1/1 Running 0 4m32s執行以下命令,檢查上述Pod實際被分配的顯存,確認其與/tmp/cgpu-test.yaml檔案中指定的顯存一致。
kubectl logs tensorflow-mnist-5htxh | grep "totalMemory"系統顯示如下。
totalMemory: 3.15GiB freeMemory: 2.85GiB執行以下命令,檢查上述Pod實際被分配的顯存,確認其與/tmp/cgpu-test.yaml檔案中指定的顯存一致。
kubectl exec -ti tensorflow-mnist-5htxh -- nvidia-smi系統顯示如下,該Pod實際被分配3226 MiB顯存,符合預期,說明GPU共用調度恢複正常。如果GPU共用調度未生效,容器被分配的顯存等於宿主機的GPU顯存容量。
Mon Apr 13 11:52:25 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 33C P0 56W / 300W | 629MiB / 3226MiB | 1% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+