阿里雲Container ServiceKubernetes版(ACK)通過託管的Prometheus,可以提升GPU資源管理的可見度。通過共用GPU方案,能夠實現多個應用調度到同一張GPU卡上,並對卡上的每個應用實現顯存隔離與算力分割。本文以實際樣本介紹如何通過託管的Prometheus查看叢集的GPU顯存使用,以及驗證共用GPU方案。
適用情境
本文樣本適用於已開通GPU共用調度功能的ACK專有版叢集及ACK Pro版叢集。
前提條件
-
已建立GPU專有版叢集,且Kubernetes版本不低於1.16。具體操作,請參見建立專有GPU叢集。
-
已開通ARMS。具體操作,請參見開通ARMS。
-
已開啟阿里雲Prometheus監控。具體操作,請參見開啟阿里雲Prometheus監控。
-
GPU硬體為Tesla P4、Tesla P100、 Tesla T4或Tesla V100(16 GB)。
背景資訊
推動人工智慧不斷向前的動力來自於強大的算力、海量的資料和最佳化的演算法,而NVIDIA GPU是最流行的異構算力提供者,是高效能深度學習的基石。GPU的價格不菲,從使用率的角度來看,模型預測情境下,應用獨佔GPU模式會造成計算資源的浪費。共用GPU模式可以提升資源使用率,但需要考慮如何達到成本和QPS平衡的最優,以及如何保障應用的SLA。
通過託管Prometheus監控獨享GPU
-
登入ARMS控制台。
-
在左側導覽列中,單擊Prometheus 監控。
-
在Prometheus 監控頁面中,選擇叢集所在地區,然後單擊目的地組群操作列的安裝。
-
在確認對話方塊中,單擊確認。
外掛程式安裝過程需要2分鐘左右。安裝外掛程式完畢後,已安装大盘列中將顯示全部已安裝的外掛程式。
-
通過命令列部署以下樣本應用,詳情請參見通過命令管理應用。
apiVersion: apps/v1 kind: StatefulSet metadata: name: app-3g-v1 labels: app: app-3g-v1 spec: replicas: 1 serviceName: "app-3g-v1" podManagementPolicy: "Parallel" selector: # define how the deployment finds the pods it manages matchLabels: app: app-3g-v1 updateStrategy: type: RollingUpdate template: # define the pods specifications metadata: labels: app: app-3g-v1 spec: containers: - name: app-3g-v1 image: registry.cn-hangzhou.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - cuda_malloc - -size=4096 resources: limits: nvidia.com/gpu: 1部署成功後,執行以下命令,查看應用的狀態,可以得出應用的名稱是app-3g-v1-0。
kubectl get pod預期輸出:
NAME READY STATUS RESTARTS AGE app-3g-v1-0 1/1 Running 1 2m56s -
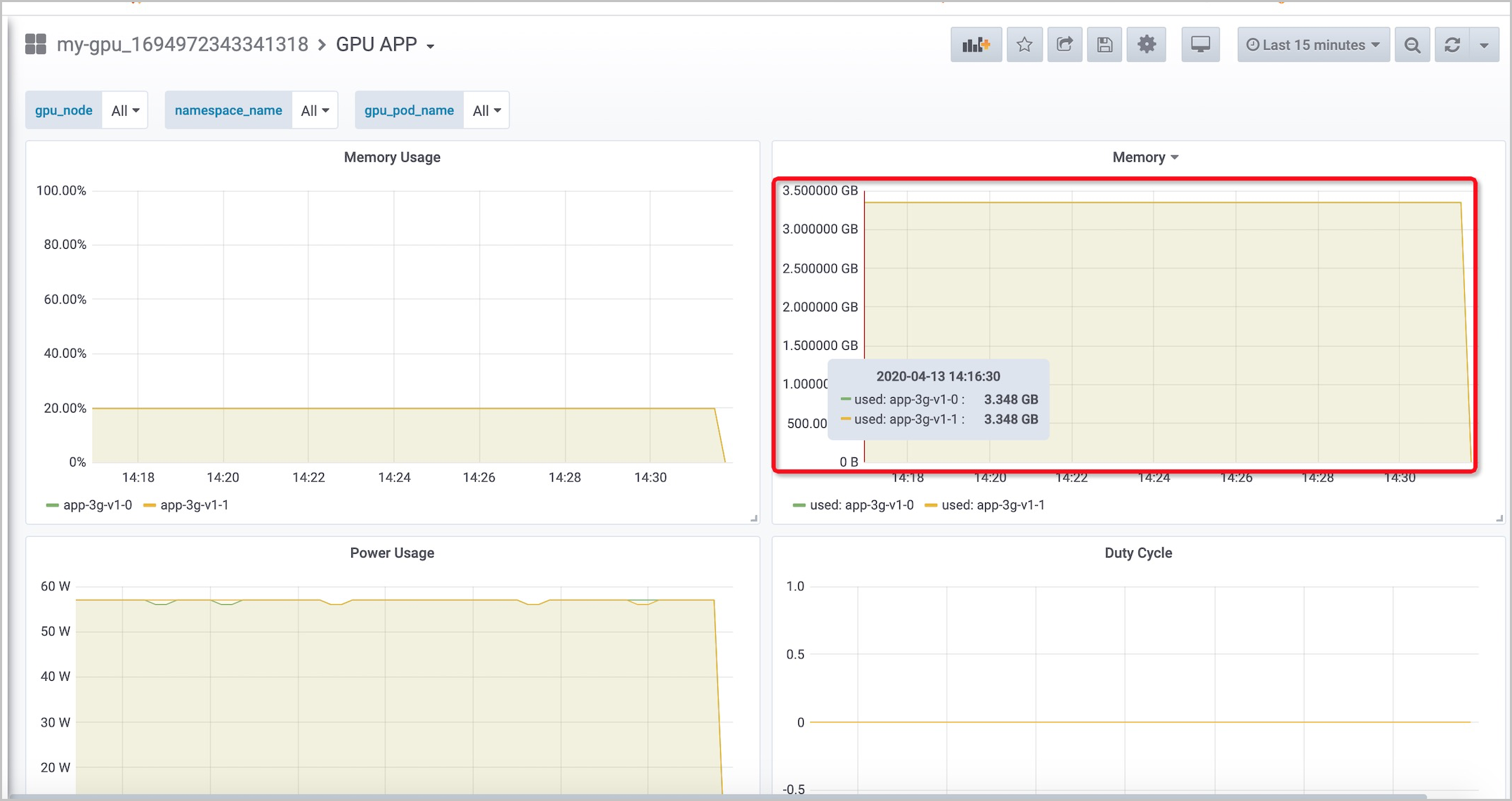
單擊目的地組群,在目的地組群的大盘列表頁面,單擊名稱列的GPU APP。
可以看到該應用的GPU顯存佔用率僅為20%,存在80%的浪費。而它使用的顯存穩定在3.4 GB左右,而總顯存為16 GB左右。因此一個應用獨佔一張GPU卡的模式比較浪費,可以考慮通過使用cGPU(container GPU)將多個應用部署在同一張GPU卡上。
實現多容器共用同一張GPU卡
-
為帶有GPU裝置的節點打標籤。
-
在控制台左側導覽列,單擊叢集。
-
在叢集列表頁面,單擊目的地組群名稱或者目的地組群右側操作列下的應用管理。
-
在叢集管理頁左側導覽列,選擇。
-
在節點管理頁面,單擊右上方標籤與汙點管理。
-
在標籤與汙點管理頁面中,批量選擇Worker節點,然後單擊添加標籤。
-
在添加對話方塊中,填寫指定的標籤名稱和值(標籤的名稱為cgpu,值為true),單擊確定。
重要如果某個Worker節點設定了標籤為cgpu=true,那麼該節點將不再擁有獨享GPU資源nvidia.com/gpu;如果該節點需要關閉GPU共用功能,請設定標籤cgpu的值為false,同時該節點將重新擁有獨享GPU資源nvidia.com/gpu。
-
安裝cGPU相關組件。
-
在控制台左側導覽列,選擇。
-
在應用目錄頁面搜尋ack-cgpu,然後單擊ack-cgpu。
-
在右側的建立面板中選擇前提條件中建立的叢集和命名空間,並單擊建立。
-
登入Master節點並執行以下命令查看GPU資源。
登入Master節點相關步驟,請參見通過kubectl工具串連叢集。
kubectl inspect cgpu預期輸出:
NAME IPADDRESS GPU0(Allocated/Total) GPU Memory(GiB) cn-hangzhou.192.168.2.167 192.168.2.167 0/15 0/15 ---------------------------------------------------------------------- Allocated/Total GPU Memory In Cluster: 0/15 (0%)說明此時可以發現該節點的GPU資源維度已經從GPU顯卡變成GPU顯存。
-
部署共用GPU的工作負載。
-
修改之前部署應用的YAML檔案。
-
將執行個體的副本數從1改為2,這樣可以指定部署兩個負載。而在原有GPU獨享的配置下,單個GPU卡只能調度單個容器;修改配置後,可以部署兩個Pod執行個體。
-
將資源維度從
nvidia.com/gpu變為aliyun.com/gpu-mem,單位也從個變成了GB。
apiVersion: apps/v1 kind: StatefulSet metadata: name: app-3g-v1 labels: app: app-3g-v1 spec: replicas: 2 serviceName: "app-3g-v1" podManagementPolicy: "Parallel" selector: # define how the deployment finds the pods it manages matchLabels: app: app-3g-v1 template: # define the pods specifications metadata: labels: app: app-3g-v1 spec: containers: - name: app-3g-v1 image: registry.cn-hangzhou.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - cuda_malloc - -size=4096 resources: limits: aliyun.com/gpu-mem: 4 #每個Pod申請4 GB顯存,因為replicas值為2,所以該應用總共申請8 GB顯存 -
-
按照GPU顯存維度調度重新建立工作負載。
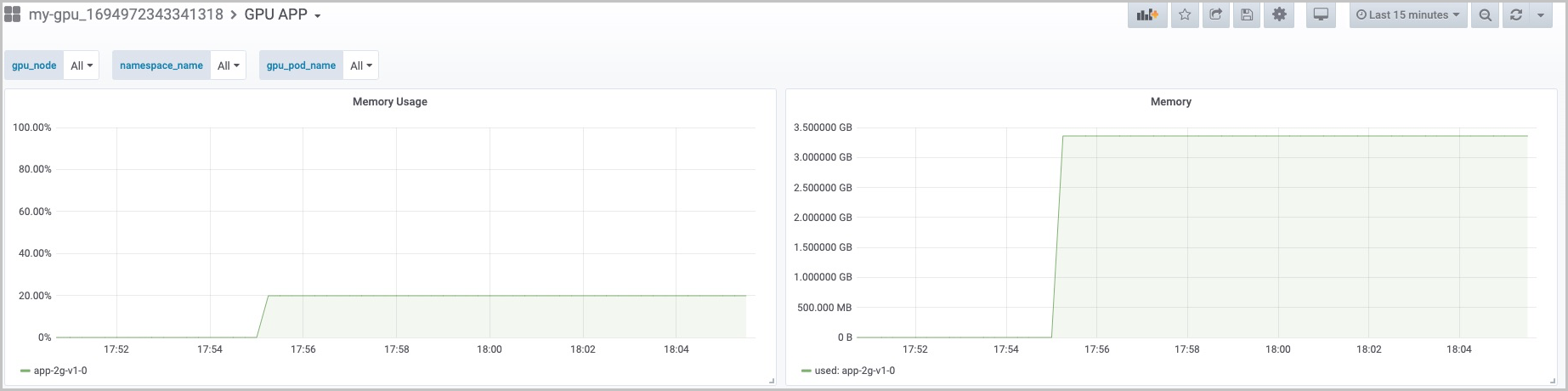
從運行結果看,兩個Pod都運行在同一個GPU裝置上。
kubectl inspect cgpu -d預期輸出:
NAME: cn-hangzhou.192.168.2.167 IPADDRESS: 192.168.2.167 NAME NAMESPACE GPU0(Allocated) app-3g-v1-0 default 4 app-3g-v1-1 default 4 Allocated : 8 (53%) Total : 15 -------------------------------------------------------- Allocated/Total GPU Memory In Cluster: 8/15 (53%) -
執行以下命令,分別登入到兩個容器。
可以看到各自GPU顯存的上限已經設定為4301 MiB, 也就是在容器內使用的GPU顯存不會超過此上限。
-
執行以下命令登入app-3g-v1-0容器。
kubectl exec -it app-3g-v1-0 nvidia-smi預期輸出:
Mon Apr 13 01:33:10 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 37C P0 57W / 300W | 3193MiB / 4301MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+ -
執行以下命令登入app-3g-v1-1容器。
kubectl exec -it app-3g-v1-1 nvidia-smi預期輸出:
Mon Apr 13 01:36:07 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 38C P0 57W / 300W | 3193MiB / 4301MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+
-
-
登入到節點,查看GPU的使用方式。
可以看到該GPU被使用的顯存資源為兩個容器之和,即6396 MiB,因此cGPU資源已經實現了按容器隔離的效果。如果此時登入到容器內嘗試申請更多的GPU資源,會直接報出顯存分配失敗的錯誤。
-
執行以下命令,登入到節點。
kubectl exec -it app-3g-v1-1 bash -
執行以下命令, 查看GPU的使用方式。
cuda_malloc -size=1024預期輸出:
gpu_cuda_malloc starting... Detected 1 CUDA Capable device(s) Device 0: "Tesla V100-SXM2-16GB" CUDA Driver Version / Runtime Version 10.1 / 10.1 Total amount of global memory: 4301 MBytes (4509925376 bytes) Try to malloc 1024 MBytes memory on GPU 0 CUDA error at cgpu_cuda_malloc.cu:119 code=2(cudaErrorMemoryAllocation) "cudaMalloc( (void**)&dev_c, malloc_size)"
-
-
您可以通過ARMS控制台,從應用和節點兩個維度來監控GPU的使用量。
-
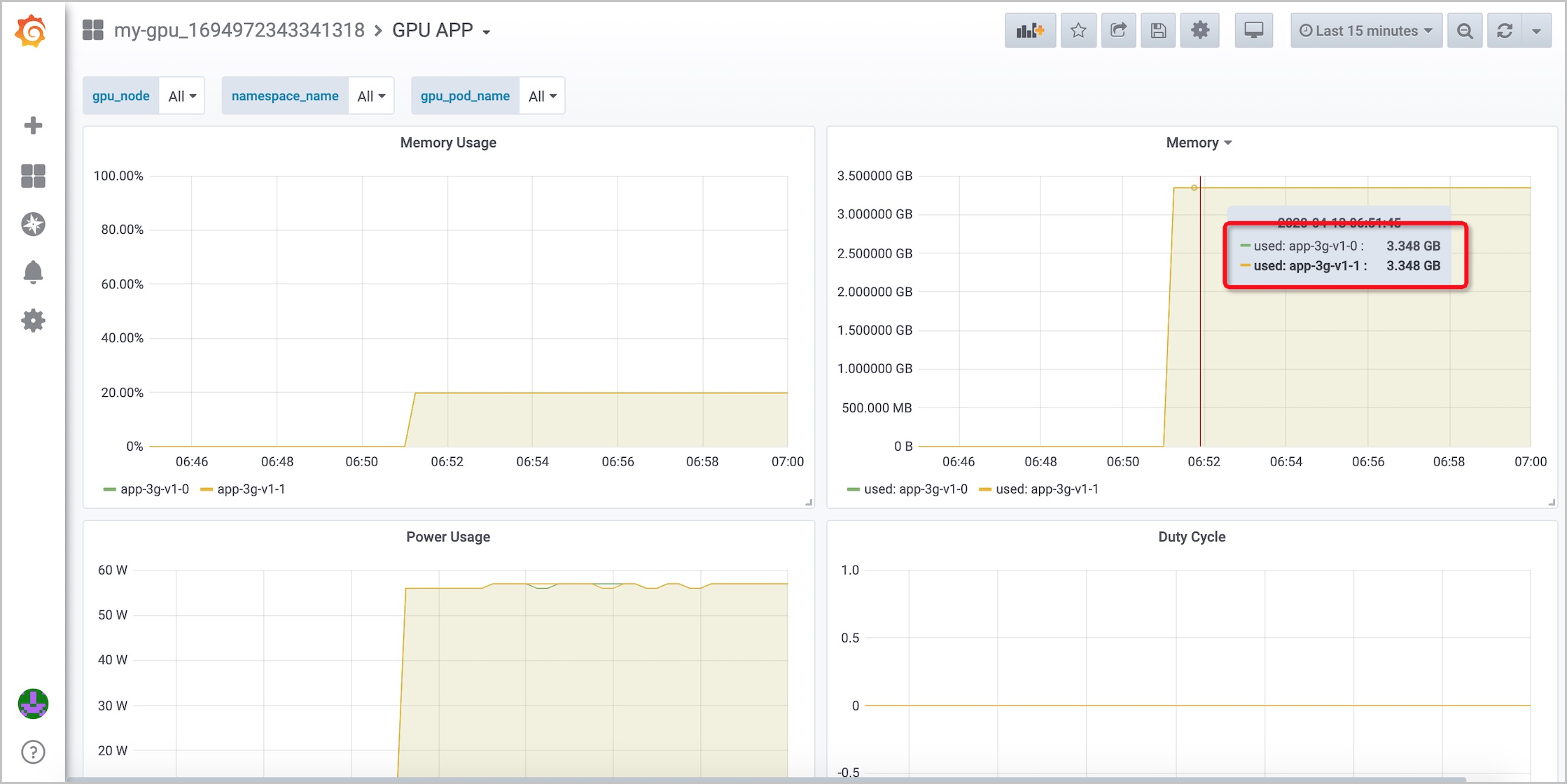
GPU APP:可以查看每個應用的GPU顯存用量和佔比。
-
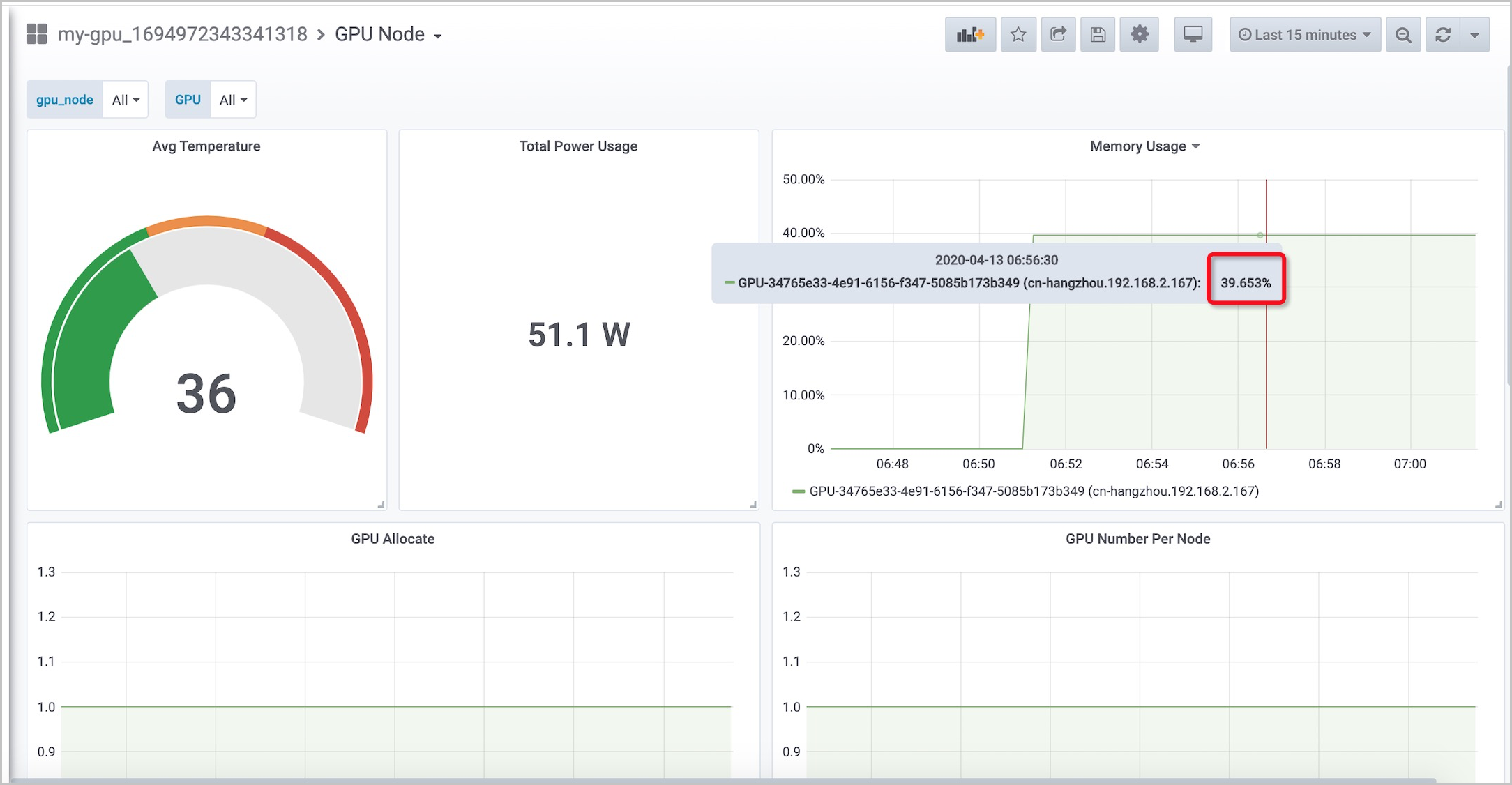
GPU Node:可以查看GPU卡的顯存使用量。
使用託管Prometheus來監控共用GPU
當某個應用聲明的GPU顯存使用量超過了資源上限後,共用GPU方案中的GPU顯存隔離模組可以確保其他應用不受影響。
-
部署一個新的GPU應用。
該應用聲明使用的GPU顯存是4 GB,但是它實際使用的GPU顯存為6 GB。
apiVersion: apps/v1 kind: StatefulSet metadata: name: app-6g-v1 labels: app: app-6g-v1 spec: replicas: 1 serviceName: "app-6g-v1" podManagementPolicy: "Parallel" selector: # define how the deployment finds the pods it manages matchLabels: app: app-6g-v1 template: # define the pods specifications metadata: labels: app: app-6g-v1 spec: containers: - name: app-6g-v1 image: registry.cn-shanghai.aliyuncs.com/tensorflow-samples/cuda-malloc:6G resources: limits: aliyun.com/gpu-mem: 4 #每個Pod申請了4 GB顯存,副本數為1,該應用總共申請4 GB顯存 -
執行以下命令,查看Pod的狀態。
新應用的pod一直處於CrashLoopBackOff,而之前兩個Pod還是正常啟動並執行狀態。
kubectl get pod預期輸出:
NAME READY STATUS RESTARTS AGE app-3g-v1-0 1/1 Running 0 7h35m app-3g-v1-1 1/1 Running 0 7h35m app-6g-v1-0 0/1 CrashLoopBackOff 5 3m15s -
執行以下命令,查看容器的日誌報錯。
可以看到報錯是由於cudaErrorMemoryAllocation造成的。
kubectl logs app-6g-v1-0預期輸出:
CUDA error at cgpu_cuda_malloc.cu:119 code=2(cudaErrorMemoryAllocation) "cudaMalloc( (void**)&dev_c, malloc_size)" -
通過託管Prometheus的GPU APP組件來查看容器狀態。
可以看到之前的容器一直處於平穩運行之中,並沒有受到新部署應用的影響。