Kubernetes原生ResourceQuota的靜態資源分配機制可能導致叢集資源使用率較低。為此,ACK基於Scheduling Framework擴充機制,通過彈性配額組提供了Capacity Scheduling功能,在保障使用者資源配額的同時支援資源共用,有效提升叢集資源使用率。
前提條件
已建立1.20及以上版本的ACK託管叢集Pro版。如需升級叢集,請參見建立ACK託管叢集。
Capacity Scheduling核心功能
在多使用者叢集環境中,為保障不同使用者的可用資源充足,管理員會將叢集資源進行固定分配。傳統模式通過Kubernetes原生的ResourceQuota進行資源的靜態分配。但由於使用者資源使用存在時間和模式差異,可能導致部分使用者資源緊張,而部分使用者配額閑置,繼而造成整體資源使用率降低。
為此,ACK基於Scheduling Framework的擴充機制,在調度側實現了Capacity Scheduling的功能,在確保使用者的資源分派的基礎上通過資源共用的方式來提升整體資源的利用率。Capacity Scheduling具體功能如下。
支援定義不同層級的資源配額:根據業務情況(例如公司的組織圖)配置多個層級的彈性配額。彈性配額組的葉子節點可以對應多個Namespace,但同一個Namespace只能歸屬於一個葉子節點。
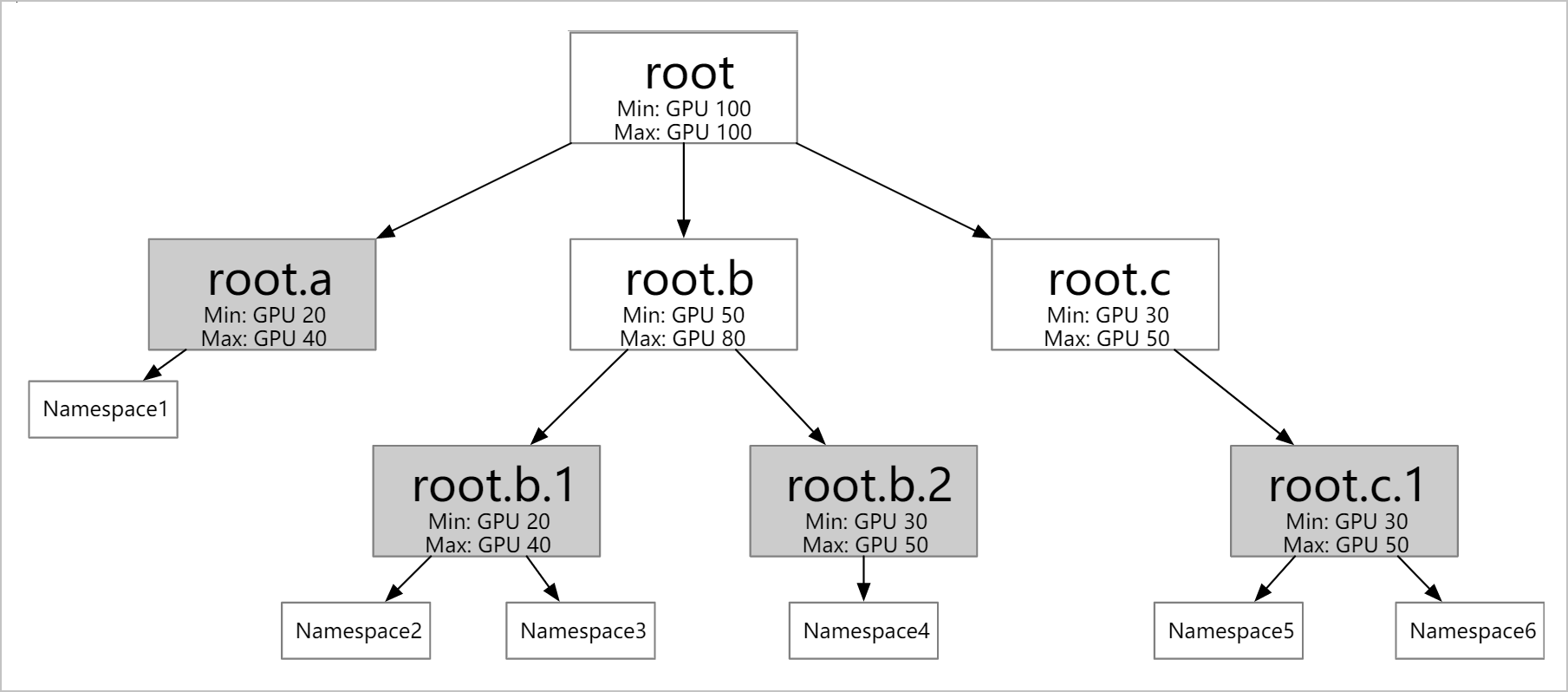
支援不同彈性配額之間的資源借用和回收。
Min:定義可使用的保障資源(Guaranteed Resource)。當整個叢集資源緊張時,所有使用者使用的Min總和需要小於叢集的總資源量。
Max:定義可使用的資源上限。
工作負載可借用其他使用者的閑置資源額度,但借用後可使用的資源總量依然不超過Max;未使用的Min資源配額支援借用,但當原使用者需要使用時可搶佔回收。
支援多種資源的配置:除CPU和記憶體資源外,也支援配置GPU等任何Kubernetes支援的擴充資源(Extended Resource)。
支援配額綁定節點:使用ResourceFlavor選擇節點,並將ResourceFlavor與ElasticQuotaTree中的某個配額關聯,關聯後該彈性配額中的Pod只能被調度到ResourceFlavor選中的節點中。
Capacity scheduling配置樣本
本樣本叢集中,節點為1台ecs.sn2.13xlarge機器(56 vCPU 224 GiB)。
建立如下Namespace。
kubectl create ns namespace1 kubectl create ns namespace2 kubectl create ns namespace3 kubectl create ns namespace4參見以下YAML,建立相應的彈性配額組。
根據以上YAML配置,在
namespaces欄位配置對應的命名空間,在children欄位配置對應子級的彈性配額。配置時,需要滿足以下要求。同一個彈性配額中的Min≤Max。
子級彈性配額的Min之和≤父級的Min。
Root節點的Min=Max≤叢集總資源。
Namespace只與彈性配額的葉子節點有一對多的對應關係,且同一個Namespace只能歸屬於一個葉子節點。
查看彈性配額組是否建立成功。
kubectl get ElasticQuotaTree -n kube-system預期輸出:
NAME AGE elasticquotatree 68s
閑置資源的借用
參見以下YAML,在
namespace1中部署服務,Pod的副本數為5個,每個Pod請求CPU資源量為5核。查看叢集Pod的部署情況。
kubectl get pods -n namespace1預期輸出:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-52dbg 1/1 Running 0 70s nginx1-744b889544-6l4s9 1/1 Running 0 70s nginx1-744b889544-cgzlr 1/1 Running 0 70s nginx1-744b889544-w2gr7 1/1 Running 0 70s nginx1-744b889544-zr5xz 0/1 Pending 0 70s由於當前叢集存在閑置資源(
root.max.cpu=40),當在namespace1下的Pod申請CPU資源量超過root.a.1設定的min.cpu=10時,還可以繼續借用其他閑置資源。最多可以申請使用root.a.1設定的配額max.cpu=20。當Pod申請CPU資源量超過
max.cpu=20時,再申請的Pod會處於Pending狀態。因此,申請的5個Pod中,4個處於Running狀態,1個處於Pending狀態。
參見以下YAML,在
namespace2中部署服務,其中Pod的副本數為5個,每個Pod請求CPU資源量為5核。查看叢集Pod的部署情況。
kubectl get pods -n namespace1預期輸出:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-52dbg 1/1 Running 0 111s nginx1-744b889544-6l4s9 1/1 Running 0 111s nginx1-744b889544-cgzlr 1/1 Running 0 111s nginx1-744b889544-w2gr7 1/1 Running 0 111s nginx1-744b889544-zr5xz 0/1 Pending 0 111skubectl get pods -n namespace2預期輸出:
NAME READY STATUS RESTARTS AGE nginx2-556f95449f-4gl8s 1/1 Running 0 111s nginx2-556f95449f-crwk4 1/1 Running 0 111s nginx2-556f95449f-gg6q2 0/1 Pending 0 111s nginx2-556f95449f-pnz5k 1/1 Running 0 111s nginx2-556f95449f-vjpmq 1/1 Running 0 111s同
nginx1一致。由於當前叢集存在閑置資源(root.max.cpu=40),當在namespace2下Pod申請CPU資源量超過root.a.2設定的min.cpu=10時,還可以繼續借用其他閑置資源。最多可以申請使用root.a.2設定的配額max.cpu=20。當Pod申請CPU資源量超過
max.cpu=20時,再申請的Pod處於Pending狀態。因此,申請的5個Pod中,4個處於Running狀態,1個處於Pending狀態。此時,叢集中
namespace1和namespace2中的Pod所佔用的資源已經為root設定的root.max.cpu=40。
借用資源的歸還
參見以下YAML,在
namespace3中部署服務,其中Pod的副本數為5個,每個Pod請求CPU資源量為5核。執行以下命令,查看叢集Pod的部署情況。
kubectl get pods -n namespace1預期輸出:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-52dbg 1/1 Running 0 6m17s nginx1-744b889544-cgzlr 1/1 Running 0 6m17s nginx1-744b889544-nknns 0/1 Pending 0 3m45s nginx1-744b889544-w2gr7 1/1 Running 0 6m17s nginx1-744b889544-zr5xz 0/1 Pending 0 6m17skubectl get pods -n namespace2預期輸出:
NAME READY STATUS RESTARTS AGE nginx2-556f95449f-crwk4 1/1 Running 0 4m22s nginx2-556f95449f-ft42z 1/1 Running 0 4m22s nginx2-556f95449f-gg6q2 0/1 Pending 0 4m22s nginx2-556f95449f-hfr2g 1/1 Running 0 3m29s nginx2-556f95449f-pvgrl 0/1 Pending 0 3m29skubectl get pods -n namespace3預期輸出:
NAME READY STATUS RESTARTS AGE nginx3-578877666-msd7f 1/1 Running 0 4m nginx3-578877666-nfdwv 0/1 Pending 0 4m10s nginx3-578877666-psszr 0/1 Pending 0 4m11s nginx3-578877666-xfsss 1/1 Running 0 4m22s nginx3-578877666-xpl2p 0/1 Pending 0 4m10snginx3的彈性配額root.b.1的min設定為10,為了保障其設定的min資源,調度器會將root.a下之前借用root.b的Pod資源歸還,使得nginx3能夠至少得到配額min.cpu=10的資源量,保證其運行。調度器會綜合考慮
root.a下作業的優先順序、可用性以及建立時間等因素,選擇相應的Pod歸還之前搶佔的資源(10核)。因此,nginx3得到配額min.cpu=10的資源量後,有2個Pod處於Running狀態,其他3個仍處於Pending狀態。參見以下YAML,在
namespace4中部署服務nginx4,其中Pod的副本數為5個,每個Pod請求CPU資源量為5核。執行以下命令,查看叢集Pod的部署情況。
kubectl get pods -n namespace1預期輸出:
NAME READY STATUS RESTARTS AGE nginx1-744b889544-cgzlr 1/1 Running 0 8m20s nginx1-744b889544-cwx8l 0/1 Pending 0 55s nginx1-744b889544-gjkx2 0/1 Pending 0 55s nginx1-744b889544-nknns 0/1 Pending 0 5m48s nginx1-744b889544-zr5xz 1/1 Running 0 8m20skubectl get pods -n namespace2預期輸出:
NAME READY STATUS RESTARTS AGE nginx2-556f95449f-cglpv 0/1 Pending 0 3m45s nginx2-556f95449f-crwk4 1/1 Running 0 9m31s nginx2-556f95449f-gg6q2 1/1 Running 0 9m31s nginx2-556f95449f-pvgrl 0/1 Pending 0 8m38s nginx2-556f95449f-zv8wn 0/1 Pending 0 3m45skubectl get pods -n namespace3預期輸出:
NAME READY STATUS RESTARTS AGE nginx3-578877666-msd7f 1/1 Running 0 8m46s nginx3-578877666-nfdwv 0/1 Pending 0 8m56s nginx3-578877666-psszr 0/1 Pending 0 8m57s nginx3-578877666-xfsss 1/1 Running 0 9m8s nginx3-578877666-xpl2p 0/1 Pending 0 8m56skubectl get pods -n namespace4預期輸出:
nginx4-754b767f45-g9954 1/1 Running 0 4m32s nginx4-754b767f45-j4v7v 0/1 Pending 0 4m32s nginx4-754b767f45-jk2t7 0/1 Pending 0 4m32s nginx4-754b767f45-nhzpf 0/1 Pending 0 4m32s nginx4-754b767f45-tv5jj 1/1 Running 0 4m32s同理,
nginx4的彈性配額root.b.2的min設定為10,為了保障其設定的min資源,調度器會將root.a下之前借用root.b的Pod資源歸還,使得nginx4能夠至少得到配額min.cpu=10的資源量,保證其運行。調度器會綜合考慮
root.a下作業的優先順序、可用性以及建立時間等因素,選擇相應的Pod歸還之前搶佔的資源(10核)。因此,nginx4得到配額min.cpu=10資源量後,有2個Pod處於Running狀態,其他3個仍處於Pending狀態。此時,叢集所有的彈性配額都使用其
min設定的保障資源(Guaranteed Resource)。
ResourceFlavor配置樣本
前提條件
已參見ResourceFlavorCRD安裝ResourceFlavor(ACK Scheduler預設未安裝)。
ResourceFlavor資源中僅nodeLabels欄位有效。
調度器版本高於6.9.0。組件變更記錄,請參見kube-scheduler;組件升級入口,請參見組件。
ResourceFlavor作為一種Kubernetes自訂資源(CRD),通過定義節點標籤(NodeLabels)建立彈性配額與節點的綁定關係。當將其與特定彈性配額關聯後,該配額下的Pod既受配額資源總量的限制,又僅能調度至匹配NodeLabels的目標節點。
ResourceFlavor樣本
一個ResourceFlavor的簡單樣本如下。
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: "spot"
spec:
nodeLabels:
instance-type: spot關聯彈性配額樣本
為了將彈性配額與ResourceFlavor進行關聯,需在ElasticQuotaTree中通過attributes欄位進行聲明,例如如下所示。
apiVersion: scheduling.sigs.k8s.io/v1beta1
kind: ElasticQuotaTree
metadata:
name: elasticquotatree
namespace: kube-system
spec:
root:
children:
- attributes:
resourceflavors: spot
max:
cpu: 99
memory: 40Gi
nvidia.com/gpu: 10
min:
cpu: 99
memory: 40Gi
nvidia.com/gpu: 10
name: child
namespaces:
- default
max:
cpu: 999900
memory: 400000Gi
nvidia.com/gpu: 100000
min:
cpu: 999900
memory: 400000Gi
nvidia.com/gpu: 100000
name: root提交後,屬於Quota child的Pod將只能調度到帶有instance-type: spot標籤的節點上。
相關文檔
kube-scheduler發布記錄,請參見kube-scheduler。
Kube-scheduler支援Gang scheduling的能力,強制關聯Pod組必須同時調度成功(否則都不會被調度),適用於Spark、Hadoop等巨量資料處理任務情境,詳情請參見使用Gang scheduling。