本文介紹關於DNS解析異常的診斷流程、排查思路、常見解決方案和排查方法。
診斷流程
注意事項
由於網路架構的多層性和動態性,Kubernetes環境中的DNS問題排查較為複雜。除CoreDNS與NodeLocal DNSCache組件的錯誤外,還有以下原因會導致DNS解析錯誤的現象。
DNS最佳實務針對不同情境提供了DNS使用建議,這些建議可以協助您更合理地配置DNS,從而減少遭遇DNS相關問題的可能性。
-
網路架構負載
DNS的解析鏈路涉及多個模組,包含CoreDNS/kube-dns、kube-proxy、CNI外掛程式等,任意一層故障均可能導致問題,因此需要逐層排查多個環節才能確定問題源頭。完整的排查鏈路,請參見排查DNS鏈路中其他模組的問題。
-
服務發現機制與命名空間的隱蔽性
-
FQDN依賴:跨命名空間訪問需使用完整網域名稱(如 service.namespace.svc.cluster.local),在網域名稱中未指定命名空間時,DNS僅在當前命名空間中尋找服務,跨命名空間訪問失敗但無明確報錯。
-
Headless Services的特殊性:Headless Services直接返回Pod IP,若配置不當會導致DNS記錄不完整或缺失。
-
-
網路原則的限制
-
隱性阻斷:若Pod NetworkPolicy未允許存取DNS連接埠(預設 53/UDP、TCP),Pod將無法與CoreDNS通訊。
-
VPC安全性群組幹擾:主機防火牆或安全性群組規則可能丟棄DNS流量,尤其是VPC安全性群組配置。
-
排查思路:檢查kube-system命名空間下CoreDNS Pod的網路連通性,驗證策略是否允許進出。
-
-
調試工具與日誌的局限性
-
工具缺失:容器鏡像預設不包含dig、nslookup,需手動安裝或使用臨時調試容器。
-
日誌分散性:CoreDNS 日誌需手動開啟Debug模式(添加 log 外掛程式),且分散在多個副本執行個體中。
-
調試技巧:通過臨時Pod執行快速DNS測試:
kubectl run -it --rm debug --image=nicolaka/netshoot -- dig或使用:
nslookup <目標網域名稱>
-
基本概念
-
叢集內部網域名稱:CoreDNS會將叢集中的服務暴露為叢集內部網域名稱,預設以
.cluster.local結尾,這類網域名稱的解析通過CoreDNS內部緩衝完成,不會從上遊DNS伺服器查詢。 -
叢集外部網域名稱:在第三方DNS服務商、阿里雲DNS雲解析、PrivateZone等產品註冊的權威解析,這類網域名稱由CoreDNS的上遊DNS伺服器負責解析,CoreDNS僅做解析請求轉寄。
-
業務Pod:您部署在Kubernetes叢集中的容器Pod,不包含Kubernetes自身系統組件的容器。
-
接入CoreDNS的業務Pod:容器內DNS伺服器指向了CoreDNS的業務Pod。
-
接入NodeLocal DNSCache的業務Pod:叢集中安裝了NodeLocal DNSCache外掛程式後,通過自動或手動方式注入DNSConfig的業務Pod。這類Pod在解析網域名稱時,會優先訪問本機快取組件。如果訪問本機快取組件不通時,會訪問CoreDNS提供的kube-dns服務。
CoreDNS與NodeLocal DNSCache異常診斷流程
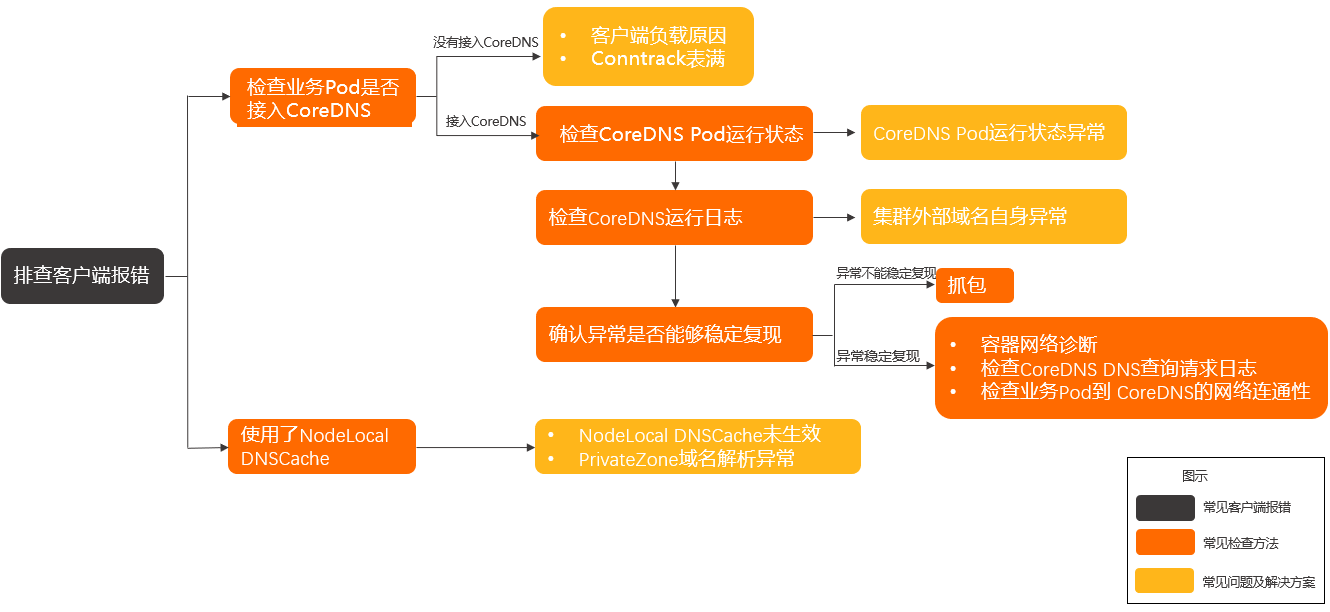
-
判斷當前的異常原因。具體資訊,請參見常見用戶端報錯。
-
如果以上排查無果,請按以下步驟排查。
-
檢查業務Pod的DNS配置,是否已經接入CoreDNS。具體操作,請參見檢查業務Pod的DNS配置。
-
如果沒有接入CoreDNS,則考慮是用戶端負載原因或Conntrack表滿導致解析失敗。具體操作,請參見用戶端負載原因導致解析失敗和Conntrack表滿。
-
如果接入了CoreDNS,則按以下步驟排查。
-
通過檢查CoreDNS Pod運行狀態進行診斷。具體操作,請參見檢查CoreDNS Pod運行狀態和CoreDNS Pod運行狀態異常。
-
通過檢查CoreDNS作業記錄進行診斷。具體操作,請參見檢查CoreDNS作業記錄和叢集外部網域名稱解析異常。
-
確認異常是否能夠穩定複現。
-
如果異常穩定複現,請參見檢查CoreDNS DNS查詢請求日誌和檢查業務Pod到CoreDNS的網路連通性。
-
如果異常不能穩定複現,請參見抓包。
-
-
-
-
如果使用了NodeLocal DNSCache,請參見NodeLocal DNSCache未生效和PrivateZone網域名稱解析異常。
-
常見用戶端報錯
|
用戶端 |
報錯日誌 |
可能異常 |
|
ping |
|
網域名稱不存在或無法串連網域名稱伺服器。如果解析延遲大於5秒,一般是無法串連網域名稱伺服器。 |
|
curl |
|
|
|
PHP HTTP用戶端 |
|
|
|
Golang HTTP用戶端 |
|
網域名稱不存在。 |
|
dig |
|
|
|
Golang HTTP用戶端 |
|
無法串連網域名稱伺服器。 |
|
dig |
|
排查DNS鏈路中其他模組的問題
下方展示了DNS解析的整體鏈路,除CoreDNS及NodeLocal DNSCache以外,DNS鏈路中其他模組都有可能導致DNS解析錯誤:
-
DNS Resolver:在例如Go這樣的程式設計語言,以及glibc、musl這樣的庫中,它們對DNS解析的實現可能包含一定的缺陷,在小機率情況下導致DNS解析故障。
-
/etc/resolv.conf檔案:容器中的DNS設定檔,其中包含了DNS伺服器的IP和DNS搜尋域。對此檔案的錯誤配置會導致DNS解析失敗。
-
kube-proxy:kube-proxy使用IPVS/Iptables轉寄請求,如果在CoreDNS配置發生變更時,kube-proxy沒有及時更新,會導致無法訪問CoreDNS,出現偶發的DNS解析失敗。
-
Upstream DNS Servers:CoreDNS僅解析叢集內的網域名稱,對於不符合
clusterDomain的網域名稱,CoreDNS將會詢問更上級DNS伺服器,例如VPC內網DNS。如果上級DNS伺服器中配置出錯,會導致Pod訪問非叢集網域名稱時出錯。
排查思路
|
排查思路 |
排查依據 |
問題及解決方案 |
|
按解析異常的網域名稱類型排查 |
叢集內外網域名稱都異常 |
|
|
僅叢集外部網域名稱異常 |
||
|
僅PrivateZone 、vpc-proxy網域名稱解析異常 |
||
|
僅Headless類型服務網域名稱異常 |
||
|
按解析異常出現頻次排查 |
完全無法解析 |
|
|
異常僅出現在業務高峰時期 |
||
|
異常出現頻次非常高 |
||
|
異常出現頻次非常低 |
||
|
異常僅出現在節點擴縮容或CoreDNS縮容時 |
常見檢查方法
檢查業務Pod的DNS配置
-
命令
#查看foo容器的YAML配置,並確認DNSPolicy欄位是否符合預期。 kubectl get pod foo -o yaml #當DNSPolicy符合預期時,可以進一步進入Pod容器中,查看實際生效的DNS配置。 #通過bash命令進入foo容器,若bash不存在可使用sh代替。 kubectl exec -it foo bash #進入容器後,可以查看DNS配置,nameserver後面為DNS伺服器位址。 cat /etc/resolv.conf -
DNS Policy配置說明
DNS Policy配置樣本如下,根據情境選擇對應的配置:
樣本1:預設情境下的DNS Policy配置
apiVersion: v1 kind: Pod metadata: name: <pod-name> namespace: <pod-namespace> spec: containers: - image: <container-image> name: <container-name> dnsPolicy: ClusterFirst securityContext: {} serviceAccount: default serviceAccountName: default terminationGracePeriodSeconds: 30樣本2:使用NodeLocal DNSCache時的DNS Policy配置
apiVersion: v1 kind: Pod metadata: name: <pod-name> namespace: <pod-namespace> spec: containers: - image: <container-image> name: <container-name> dnsPolicy: None dnsConfig: nameservers: - 169.254.20.10 - 172.21.0.10 options: - name: ndots value: "3" - name: timeout value: "1" - name: attempts value: "2" searches: - default.svc.cluster.local - svc.cluster.local - cluster.local securityContext: {} serviceAccount: default serviceAccountName: default terminationGracePeriodSeconds: 30DNSPolicy欄位值
使用的DNS伺服器
Default
只適用於不需要訪問叢集內部服務的情境。Pod建立時會從ECS節點/etc/resolv.conf檔案繼承DNS伺服器列表。
ClusterFirst
此為DNSPolicy預設值,Pod會將CoreDNS提供的kube-dns服務IP作為DNS伺服器。開啟HostNetwork的Pod,如果選擇ClusterFirst模式,效果等同於Default模式。
ClusterFirstWithHostNet
開啟HostNetwork的Pod,如果選擇ClusterFirstWithHostNet模式,效果等同於ClusterFirst。
None
配合DNSConfig欄位,可用於自訂DNS伺服器和參數。在NodeLocal DNSCache開啟注入時,DNSConfig會將DNS伺服器指向本機快取IP及CoreDNS提供的kube-dns服務IP。
檢查CoreDNS Pod運行狀態
命令
-
執行以下命令,查看容器組資訊。
kubectl -n kube-system get pod -o wide -l k8s-app=kube-dns預期輸出:
NAME READY STATUS RESTARTS AGE IP NODE coredns-xxxxxxxxx-xxxxx 1/1 Running 0 25h 172.20.6.53 cn-hangzhou.192.168.0.198 -
執行以下命令,查看Pod的即時資源使用方式。
kubectl -n kube-system top pod -l k8s-app=kube-dns預期輸出:
NAME CPU(cores) MEMORY(bytes) coredns-xxxxxxxxx-xxxxx 3m 18Mi -
如果Pod不處於Running狀態,可以通過
kubectl -n kube-system describe pod <CoreDNS Pod名稱>命令,查詢問題原因。
檢查CoreDNS作業記錄
命令
執行以下命令,檢查CoreDNS作業記錄。
kubectl -n kube-system logs -f --tail=500 --timestamps coredns-xxxxxxxxx-xxxxx|
參數 |
描述 |
|
|
持續輸出。 |
|
|
輸出最後500行日誌。 |
|
|
同時顯示日誌列印的時間。 |
|
|
CoreDNS Pod副本的名稱。 |
檢查CoreDNS DNS查詢請求日誌
命令
DNS查詢請求日誌僅會在開啟CoreDNS的Log外掛程式後,才會列印到容器日誌中。關於開啟Log外掛程式的具體操作,請參見非託管CoreDNS配置說明。
命令與檢查CoreDNS作業記錄相同,請參見檢查CoreDNS作業記錄。
檢查CoreDNS Pod的網路連通性
您可以使用控制台或命令列方式檢查CoreDNS Pod的網路連通性。
控制台
您可以通過叢集下提供的網路診斷能力進行診斷。
-
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
-
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
-
在故障診斷頁面,單擊網絡診斷,然後單擊頁面左上方診斷按鈕。
-
在網絡診斷頁面單擊診斷,然後在訪問資訊面板,根據以下內容填寫診斷參數:
-
源地址:輸入CoreDNS Pod的IP。
-
目標地址:輸入上遊DNS伺服器位址,預設可選100.100.2.136或100.100.2.138。
-
連接埠:
53 -
協議:
udp
填寫完成後仔細閱讀注意事項,選中我已知曉並同意,然後單擊發起診斷。
-
-
在診斷結果頁面,能夠查看網路診斷結果,並且在訪問全圖地區,會呈現出本次診斷訪問鏈路的全景。
本樣本中,診斷結果提示"沒有發現明顯問題,請結合診斷項結果進一步判斷,也可以向我們提交工單",訪問鏈路依次為 kube-system/coredns Pod → ECS 節點(cn-hangzhou.172.xxx.xxx.240)→ 目標 DNS 伺服器(100.100.2.136)。
命令列
操作步驟
-
登入CoreDNS Pod所在叢集節點。
-
執行
ps aux | grep coredns,查詢CoreDNS的進程ID。 -
執行
nsenter -t <pid> -n -- <相關命令>,進入CoreDNS所在容器網路命名空間,其中pid為上一步得到的coredns進程ID。 -
測試網路連通性。
-
運行
telnet <apiserver_clusterip> 6443,測試Kubernetes API Server的連通性。其中
apiserver_clusterip為default命名空間下Kubernetes服務的IP地址。 -
運行
dig <domain> @<upstream_dns_server_ip>,測試CoreDNS Pod到上遊DNS伺服器的連通性。其中
domain為測試網域名稱,upstream_dns_server_ip為上遊DNS伺服器位址,預設為100.100.2.136和100.100.2.138。
-
常見問題
|
現象 |
原因 |
處理方案 |
|
CoreDNS無法連通Kubernetes API Server |
APIServer異常、機器負載高、kube-proxy 沒有正常運行等。 |
可提交工單排查。 |
|
CoreDNS無法連通上遊DNS伺服器 |
機器負載高、CoreDNS配置錯誤、專線路由問題等。 |
可提交工單排查。 |
檢查業務Pod到CoreDNS的網路連通性
您可以使用控制台或命令列方式檢查業務Pod到CoreDNS的網路連通性。
控制台
-
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
-
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
-
在故障診斷頁面,單擊網絡診斷,然後單擊頁面左上方診斷按鈕。
-
在網絡診斷頁面單擊診斷,然後在訪問資訊面板,根據以下內容填寫診斷參數:
-
源地址:輸入業務Pod的IP。
-
目標地址:輸入CoreDNS執行個體的PodIP或者ClusterIP。
-
連接埠:
53 -
協議:
udp
填寫完成後仔細閱讀注意事項,選中我已知曉並同意,然後單擊發起診斷。
-
-
在診斷結果頁面,能夠查看網路診斷結果,並且在訪問全圖地區,會呈現出本次診斷訪問鏈路的全景。
診斷結果顯示一條 FATAL 層級記錄,節點為 cn-hangzhou.172.xx.0.240,診斷內容為路由無效:
invalid route "0.0.0.0/0 dev eth1 via 172.16.3.253 scope universe type unicast" for packet (src=172.16.1.45, dst=172.16.1.3),期望路由為dev: calibb5fee8d7c0 scope: link type: unicast。訪問全圖地區的網路拓撲展示從 nginx Pod 經過紅色高亮的故障節點 cn-hangzhou.172.xx.0.240,分別串連到兩個 coredns Pod 的訪問鏈路,直觀標識出 FATAL 故障所在位置。
命令列
操作步驟
-
選擇以下任意一種方式,進入用戶端Pod容器網路。
-
方法一:使用
kubectl exec命令。 -
方法二:
-
登入業務Pod所在叢集節點。
-
執行
ps aux | grep <業務進程名>命令,查詢業務容器的進程ID。 -
執行
nsenter -t <pid> -n bash命令,進入業務Pod所在容器網路命名空間。其中
pid為上一步得到的進程ID。
-
-
方法三:如果頻繁重啟,請按以下步驟操作。
-
登入業務Pod所在叢集節點。
-
執行
docker ps -a | grep <業務容器名>命令,查詢k8s_POD_開頭的沙箱容器,記錄容器ID。 -
執行
docker inspect <沙箱容器 ID> | grep netns命令,查詢/var/run/docker/netns/xxxx的容器網路命名空間路徑。 -
執行
nsenter -n<netns 路徑> bash命令,進入容器網路命名空間。其中
netns 路徑為上一步得到的路徑。說明-n和<netns 路徑>之間不加空格。
-
-
-
測試網路連通性。
-
執行
dig <domain> @<kube_dns_svc_ip>命令,測試業務Pod到CoreDNS服務kube-dns解析查詢的連通性。其中
<domain>為測試網域名稱,<kube_dns_svc_ip>為kube-system命名空間中kube-dns的服務IP。 -
執行
ping <coredns_pod_ip>命令,測試業務Pod到CoreDNS容器副本的連通性。其中
<coredns_pod_ip>為kube-system命名空間中CoreDNS Pod的IP。 -
執行
dig <domain> @<coredns_pod_ip>命令,測試業務Pod到CoreDNS容器副本解析查詢的連通性。其中
<domain>為測試網域名稱,<coredns_pod_ip>為kube-system命名空間中CoreDNS Pod的IP。
-
常見問題
|
現象 |
原因 |
處理方案 |
|
業務Pod無法通過CoreDNS服務kube-dns解析 |
機器負載高、kube-proxy沒有正常運行、安全性群組沒有放開UDP協議53連接埠等。 |
檢查安全性群組是否放開UDP 53連接埠,若已放開請提交工單排查。 |
|
業務Pod無法連通CoreDNS容器副本 |
容器網路異常或安全性群組沒有放開ICMP。 |
檢查安全性群組是否放開ICMP,若已放開請提交工單排查。 |
|
業務Pod無法通過CoreDNS容器副本解析 |
機器負載高、安全性群組沒有放開UDP協議53連接埠等。 |
檢查安全性群組是否放開UDP 53連接埠,若已放開請提交工單排查。 |
抓包
當無法定位問題時,需要抓包進行輔助診斷。
-
登入出現異常的業務Pod、CoreDNS Pod所在節點。
-
在ECS(非容器內)執行以下命令,可以將最近所有的53連接埠資訊抓取到檔案中。
tcpdump -i any port 53 -C 20 -W 200 -w /tmp/client_dns.pcap -
結合業務日誌的報錯定位到精準的報錯時間的報文資訊。
說明-
在正常情況下,抓包對業務無影響,僅會增加小部分的CPU負載和磁碟寫入。
-
以上命令會對抓取到的包進行rotate,最多可以寫200個20MB的.pcap檔案。
-
叢集外部網域名稱解析異常
問題現象
業務Pod可以正常解析叢集內部網域名稱,但無法解析某些叢集外部網域名稱。
問題原因
上遊伺服器網域名稱解析返回異常。
解決方案
檢查CoreDNS DNS查詢請求日誌。
常見請求日誌
CoreDNS接收到請求並回複用戶端後會列印一行日誌,樣本如下:
# 其中包含狀態代碼RCODE NOERROR,代表解析結果正常返回。
[INFO] 172.20.2.25:44525 - 36259 "A IN redis-master.default.svc.cluster.local. udp 56 false 512" NOERROR qr,aa,rd 110 0.000116946s常見返回碼RCODE
關於返回碼RCODE定義的具體資訊,請參見規範。
|
返回碼RCODE |
含義 |
原因 |
|
NXDOMAIN |
網域名稱不存在 |
容器內請求網域名稱時,會被拼接上search尾碼,若拼接的結果網域名稱不存在,則會出現該請求碼。如果確認日誌中請求的網域名稱內容存在,則說明存在異常。 |
|
SERVFAIL |
上遊伺服器異常 |
常見於無法串連上遊DNS伺服器等情況。 |
|
REFUSED |
拒絕應答 |
常見於CoreDNS配置或叢集節點/etc/resolv.conf檔案指向的上遊DNS伺服器無法處理該網域名稱的情況,請排查CoreDNS設定檔。 |
當CoreDNS DNS查詢請求日誌中顯示叢集外部網域名稱返回為NXDOMAIN、SERVFAIL、REFUSED時,說明CoreDNS的上遊DNS伺服器返回異常。
預設情況下,叢集中CoreDNS的上遊DNS伺服器是VPC提供的DNS伺服器(100.100.2.136 和 100.100.2.138)。您可以提交工單至Elastic Compute Service產品。提交工單時請註明以下資訊。
|
欄位 |
含義 |
樣本 |
|
受損網域名稱 |
CoreDNS日誌中返回碼RCODE異常的叢集外部網域名稱 |
www.aliyun.com |
|
解析返回碼RCODE |
具體解析報錯(NXDOMAIN、SERVFAIL、REFUSED) |
NXDOMAIN |
|
受損時間 |
日誌出現的時間(精確到秒) |
2022-12-22 20:00:03 |
|
受損ECS |
CoreDNS各副本Pod所處的ECS執行個體ID |
i-xxxxx i-yyyyy |
新增Headless類型網域名稱無法解析
問題現象
接入CoreDNS的業務Pod無法解析新增的Headless類型網域名稱。
問題原因
1.7.0以前版本CoreDNS會在API Server抖動時異常退出,導致Headless網域名稱停止更新。
解決方案
升級CoreDNS至1.7.0以上。具體操作,請參見【組件升級】CoreDNS升級公告。
Headless類型網域名稱解析失敗
問題現象
接入CoreDNS的業務Pod無法解析Headless類型的網域名稱。使用dig解析時,返回中顯示tc標誌,表示響應訊息過大。
問題原因
當Headless類型的網域名稱對應的IP條目數量過多時,用戶端通過UDP方式發送DNS請求可能會超出UDP DNS報文的大小限制,導致解析失敗。
解決方案
為了避免解析失敗,您可以將用戶端業務調整為使用TCP方式進行DNS查詢。CoreDNS同時支援TCP和 UDP查詢,以下是根據不同業務情境的修改方式:
-
使用glibc相關的解析器。
如果您的用戶端業務使用的是glibc相關的Resolve解析器,可以在
dnsConfig中增加use-vc配置使用TCP進行DNS查詢。這些設定將在/etc/resolv.conf中的映射到相應的options配置。關於options配置詳細說明請參見Linux man pages。dnsConfig: options: - name: use-vc -
Golang實現的業務代碼邏輯
如果您使用Golang進行開發,可以參考以下代碼,使用TCP進行DNS查詢。
package main import ( "fmt" "net" "context" ) func main() { resolver := &net.Resolver{ PreferGo: true, Dial: func(ctx context.Context, network, address string) (net.Conn, error) { return net.Dial("tcp", address) }, } addrs, err := resolver.LookupHost(context.TODO(), "example.com") if err != nil { fmt.Println("Error:", err) return } fmt.Println("Addresses:", addrs) }
升級CoreDNS後Headless類型網域名稱無法解析
問題現象
部分較低版本開源組件(低版本etcd、nacos、kafka等)在K8s 1.20及以上版本和 CoreDNS 1.8.4及以上版本的環境中無法正常工作。
問題原因
1.8.4及以上版本的CoreDNS優先使用EndpointSlice API同步K8s內服務IP資訊。一些開源組件在初始化階段會使用Endpoint API 提供的註解service.alpha.kubernetes.io/tolerate-unready-endpoints來發布尚未就緒的服務。該註解在EndpointSlice API中已經廢棄,並被publishNotReadyAddresses所替代。因此CoreDNS升級後,無法發布未就緒的服務,導致這些組件無法進行服務發現。
解決方案
檢查開源組件的YAML或Helm Chart中是否包含service.alpha.kubernetes.io/tolerate-unready-endpoints註解,如果包含則可能無法正常工作,您需要升級開源組件或諮詢開源組件社區。
StatefulSets Pod網域名稱無法解析
問題現象
Headless服務無法通過Pod網域名稱解析。
問題原因
StatefulSets Pod YAML中ServiceName必須和其暴露的SVC名字一致,否則無法訪問Pod網域名稱(例如pod.headless-svc.ns.svc.cluster.local),只能訪問到服務網域名稱(例如headless-svc.ns.svc.cluster.local)。
解決方案
修改StatefulSets Pod YAML中ServiceName名稱。
安全性群組、交換器ACL配置錯誤
問題現象
部分節點或全部節點上接入CoreDNS的業務,Pod解析網域名稱持久性失敗。
問題原因
修改了ECS或容器使用的安全性群組(或交換器ACL),攔截了UDP協議下53連接埠的通訊。
解決方案
恢複安全性群組、交換器ACL的配置,放開其以UDP協議對53連接埠的通訊。
容器網路連通性異常
問題現象
部分節點或全部節點上接入CoreDNS的業務,Pod解析網域名稱持久性失敗。
問題原因
由於容器網路或其它原因導致的UDP協議53連接埠持續不通。
解決方案
您可以使用網路診斷對業務Pod和CoreDNS地址直接的網路連通性進行診斷。
CoreDNS Pod負載高
問題現象
-
部分節點或全部節點接入CoreDNS的業務,Pod解析網域名稱的延遲增加,出現機率性或持久性失敗。
-
檢查CoreDNS Pod運行狀態發現各副本CPU、Memory使用量接近其資源限制。
問題原因
由於CoreDNS副本數不足、業務請求量高等情況導致的CoreDNS負載高。
解決方案
-
考慮採用NodeLocal DNSCache緩衝方案,提升DNS解析效能,降低CoreDNS負載。具體操作,請參見使用NodeLocal DNSCache組件。
-
適當擴充CoreDNS副本數,使每個Pod的峰值CPU始終低於節點空閑CPU數量。
CoreDNS Pod負載不均
問題現象
-
部分接入CoreDNS的業務Pod解析網域名稱的延遲增加,出現機率性或持久性失敗。
-
檢查CoreDNS Pod運行狀態發現各副本CPU使用量負載不均衡。
-
CoreDNS副本數少於兩個,或多個CoreDNS副本位於同節點上。
問題原因
由於CoreDNS副本調度不均、Service親和性設定導致CoreDNS Pod負載不均衡。
解決方案
-
擴容並打散CoreDNS副本到不同的節點上。
-
負載不均衡時,可禁用kube-dns服務的親和性屬性。具體操作,請參見非託管CoreDNS自動升級。
CoreDNS Pod運行狀態異常
問題現象
-
部分接入CoreDNS的業務Pod解析網域名稱的延遲增加,出現機率性或持久性失敗。
-
CoreDNS副本狀態Status不處於Running狀態,或重啟次數RESTARTS持續增加。
-
CoreDNS作業記錄中出現異常。
問題原因
由於CoreDNS YAML模板、設定檔等導致CoreDNS運行異常。
解決方案
檢查CoreDNS Pod運行狀態和作業記錄。
常見異常日誌及處理方案
|
日誌中字樣 |
原因 |
處理方案 |
|
|
設定檔和CoreDNS不相容, |
從kube-system命名空間中CoreDNS配置項中刪除ready外掛程式,其它報錯同理。 |
|
|
日誌出現時間段內,API Server中斷。 |
如果是日誌出現時間和異常不吻合,可以排除該原因,否則請檢查CoreDNS Pod網路連通性。具體操作,請參見檢查CoreDNS Pod的網路連通性。 |
|
|
日誌出現時間段內,CoreDNS無法串連到上遊DNS伺服器。 |
用戶端負載原因導致解析失敗
問題現象
業務高峰期間或突然偶發的解析失敗,ECS監控顯示機器網卡重傳率、CPU負載異常。
問題原因
接入CoreDNS的業務Pod所在ECS負載達到100%等情況導致UDP報文丟失。
解決方案
建議採用NodeLocal DNSCache緩衝方案,提升DNS解析效能,降低CoreDNS負載。具體操作,請參見使用NodeLocal DNSCache組件。
Conntrack表滿
問題現象
-
部分節點或全部節點上接入CoreDNS的業務,Pod解析網域名稱在業務高峰時間段內出現大批量網域名稱解析失敗,高峰結束後失敗消失。
-
運行
dmesg -H,滾動到問題對應時段的日誌,發現出現conntrack full字樣的報錯資訊。
問題原因
Linux內Conntrack表條目有限,無法進行新的UDP或TCP請求。
解決方案
增加Conntrack表限制。具體操作,請參見如何提升Linux串連跟蹤Conntrack數量限制?。
AutoPath外掛程式異常
問題現象
-
解析叢集外部網域名稱時,機率性出現解析失敗或解析到錯誤的IP地址,解析叢集內部網域名稱無異常。
-
高頻建立容器時,叢集內部服務網域名稱解析到錯誤的IP地址。
問題原因
CoreDNS處理缺陷導致AutoPath無法正常工作。
解決方案
按照以下步驟,關閉AutoPath外掛程式。
-
執行
kubectl -n kube-system edit configmap coredns命令,開啟CoreDNS設定檔。 -
刪除
autopath @kubernetes一行後儲存退出。 -
檢查CoreDNS Pod運行狀態和作業記錄,作業記錄中出現
reload字樣後說明修改成功。
A記錄和AAAA記錄並發解析異常
問題現象
-
接入CoreDNS的業務Pod解析網域名稱機率性失敗。
-
從抓包或檢查CoreDNS DNS查詢請求日誌可以發現,A和AAAA通常在同一時間的出現,並且請求的源連接埠一致。
問題原因
-
並發A和AAAA的DNS請求觸發Linux核心Conntrack模組缺陷,導致UDP報文丟失。
-
低版本的libc(<2.33)在ARM機型上同時發起A和AAAA請求時存在並發問題,導致請求逾時重傳,請參見GLIBC#26600。
解決方案
-
考慮採用NodeLocal DNSCache緩衝方案,提升DNS解析效能,降低CoreDNS負載。具體操作,請參見使用NodeLocal DNSCache組件。
-
CentOS、Ubuntu等使用libc的基礎鏡像,升級libc版本到2.33或以上版本避免A和AAAA並發解析問題。
-
CentOS、Ubuntu等基礎鏡像,可以通過
options timeout:2 attempts:3 rotate single-request-reopen等參數最佳化。 -
如果容器鏡像是以Alpine製作的,建議更換基礎鏡像。更多資訊,請參見Alpine。
-
PHP類應用短串連解析問題較多,如果使用的是PHP Curl的調用,可以使用
CURL_IPRESOLVE_V4參數僅發送IPv4解析。更多資訊,請參見函數說明。
IPVS模式下CoreDNS Pod異常後可能出現DNS解析失敗的情況
問題現象
IPVS模式下CoreDNS Pod在某些特定情況,可能出現機率性DNS解析失敗,通常時間長度在五分鐘左右。
問題原因
在某些特定情況,DNS解析請求會被發送到出於非正常狀態的CoreDNS Pod上,導致解析失敗。
例如,CoreDNS Pod所在的節點被移除後,節點資源會被立即釋放,Pod隨即無法正常工作。但叢集需要約1分鐘檢測到節點的狀態更新並將其標記為NotReady狀態。在節點狀態更新前,此Pod仍舊會被認為是正常狀態而接受DNS解析請求,導致叢集中出現機率性DNS解析失敗。
節點被標記為NotReady後,此節點上的CoreDNS Pod會被立即從CoreDNS Service的後端移除,不再接收新的串連。而如果叢集的kube-proxy負載平衡模式為IPVS,IPVS UDP的會話保持策略會導致仍有部分DNS請求發送到Pod上,直到到達UDP逾時時間,因此會導致叢集中更長時間的DNS解析失敗情況。
此問題可能會發生在核心版本小於4.19.91-25.1.al7.x86_64的CentOS、Alibaba Cloud Linux 2節點上。
解決方案
-
考慮採用NodeLocal DNSCache緩衝方案,可以容忍IPVS丟包。具體操作,請參見使用NodeLocal DNSCache組件。
-
最佳化IPVS UDP逾時時間。具體操作,請參見配置IPVS類型叢集的UDP逾時時間。
NodeLocal DNSCache未生效
問題現象
NodeLocal DNSCache沒有流量進入,所有請求仍在CoreDNS上。
問題原因
-
未配置DNSConfig注入,業務Pod實際仍配置了CoreDNS kube-dns服務IP作為DNS伺服器位址。
-
業務Pod採用Alpine作為基礎鏡像,Alpine基礎鏡像會並發請求所有nameserver,包括本機快取和CoreDNS。
解決方案
-
配置DNSConfig自動注入。具體操作,請參見使用NodeLocal DNSCache組件。
-
如果容器鏡像是以Alpine製作的,建議更換基礎鏡像。更多資訊,請參見Alpine。
PrivateZone網域名稱解析異常
問題現象
對於接入NodeLocal DNSCache的業務,Pod無法解析PrivateZone上註冊的網域名稱,或無法解析包含vpc-proxy字樣的阿里雲雲產品API網域名稱,或解析結果不正確。
問題原因
PrivateZone不支援TCP協議,需要使用UDP協議訪問。
解決方案
在CoreDNS中配置prefer_udp。具體操作,請參見非託管CoreDNS配置說明。
突發大流量導致的DNS解析問題
問題現象
流量出現突發增長後,部分DNS請求解析失敗。
問題原因
突發大流量導致DNS請求數量激增,進出CoreDNS的流量過高,可能會導致CoreDNS的CPU使用被限流,從而導致解析異常。您可以通過下列方式核實是否是這種情況:
-
在CoreDNS Pod所處的節點上執行檢查。
在節點上執行以下命令。
nsenter -t <coredns-pid> -n -- netstat -su查看是否有相關
send或者recv buffer error資訊,如果有說明存在UDP丟包,例如:Udp: 1090421 packets received 850 packets to unknown port received 15662 packet receive errors 5607627 packets sent 15662 receive buffer errors 0 send buffer errors -
查看CoreDNS Pod的CPU Throttled監控。
若CoreDNS CPU被限流,有可能會出現DNS偶發解析失敗或者DNS響應延遲變高的問題,可以結合第一點是否有丟包一起來確認問題。
說明因為CPU使用率的採樣和計算周期問題(15s),可能存在CPU使用率不高,但CPU被限流的情況。更多資訊,請參見啟用CPU Burst效能最佳化策略。
在 Prometheus 監控頁面,選擇應用監控 > 叢集Pod監控,篩選 Namespace 為 kube-system,選擇對應的 CoreDNS Pod,在 CPU Resource 地區關注 CPU Throttled Percent 折線圖。若該指標接近 0%,則表示未發生 CPU 限流。
-
無論您採用Arms Promtheus還是採用自建Prometheus方案,建議總是採集CoreDNS指標,並結合CoreDNS大盤來查看相關監控是否異常,並找到問題時間點。您可登入Container Service管理主控台後,通過中的網絡監控頁簽找到CoreDNS組件監控。

解決方案
-
配置NodeSelector,調度CoreDNS Pod到單獨的節點池,使CoreDNS Pod獨佔節點部署,且不配置CPU資源限制。
-
若CoreDNS Pod配置了CPU資源限制 ,建議同時啟用CPU Burst效能最佳化策略 。
-
安裝NodeLocal DNSCache組件,並配置Pod使DNS緩衝生效。具體操作,請參見使用NodeLocal DNSCache組件。