仮想カラム機能を使用すると、多次元インデックスのスキーマを変更したり、多次元インデックスを作成して新しいフィールドや新しいフィールドタイプのデータをクエリしたりできます。Tablestore テーブルのストレージスキーマやデータを変更する必要はありません。
機能概要
仮想カラム機能を使用すると、多次元インデックスの作成時に、テーブル内の列を多次元インデックス内の仮想カラムにマッピングできます。仮想カラムのタイプは、テーブル内の列のタイプと異なっていてもかまいません。これにより、テーブルスキーマやデータを変更することなく列を作成できます。新しい列は、クエリの高速化や、異なるトークナイゼーションメソッドの設定に使用できます。
テーブル内の同じフィールドにマッピングされている Text フィールドに対して、異なるトークナイゼーションメソッドを設定できます。
単一の String 列を、多次元インデックスの複数の Text 列にマッピングできます。異なる Text 列では、さまざまなビジネス要件を満たすために異なるトークナイゼーションメソッドが使用されます。
クエリの高速化
データをクレンジングしたり、テーブルスキーマを再作成したりする必要はありません。必要なテーブルの列を多次元インデックスの列にマッピングするだけで済みます。テーブルと多次元インデックスの間で列のタイプが異なっていてもかまいません。たとえば、数値タイプを Keyword タイプにマッピングして term クエリのパフォーマンスを向上させたり、String タイプを数値タイプにマッピングして範囲クエリのパフォーマンスを向上させたりできます。
注意事項
次の表に、仮想カラムとテーブル内の列との間のデータの型変換を示します。
データテーブルのフィールドタイプ
仮想カラムのフィールドタイプ
String
Keyword および Keyword 配列
FuzzyKeyword および FuzzyKeyword 配列
Text および Text 配列
Long および Long 配列
Double および Double 配列
Date および Date 配列
IP および IP 配列
Geo-point および Geo-point 配列
Long
Keyword
FuzzyKeyword
Text
Double
Keyword
FuzzyKeyword
Text
仮想カラムはクエリ文でのみ使用でき、`ColumnsToGet` で列の値を返すために使用することはできません。列の値を返すには、仮想カラムがマッピングされている列を指定する必要があります。
利用方法
仮想カラム機能は、Tablestore コンソールまたは Tablestore SDK を使用して利用できます。この機能を使用する前に、次の準備が完了していることを確認してください。
Tablestore を管理する権限を持つ Alibaba Cloud アカウントまたは RAM ユーザーが作成されていること。RAM ユーザーに Tablestore の管理権限を付与する方法の詳細については、「RAM ポリシーを使用して RAM ユーザーに権限を付与」をご参照ください。
Tablestore SDK を使用して仮想カラム機能を利用する場合は、Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey ペアが作成されていること。詳細については、「AccessKey ペアの作成」をご参照ください。
データテーブルが作成されていること。詳細については、「データテーブルの操作」をご参照ください。
Tablestore SDK を使用して仮想カラム機能を利用する場合は、OTSClient インスタンスが初期化されていること。詳細については、「Tablestore クライアントの初期化」をご参照ください。
Tablestore コンソールでの仮想カラム機能の利用
Tablestore コンソールで多次元インデックスを作成する際にフィールドを仮想カラムとして指定した後、その仮想カラムを使用してデータをクエリします。
[インデックス] タブに移動します。
Tablestore コンソールにログインします。
上部のナビゲーションバーで、リージョンとリソースグループを選択します。
[概要] ページで、管理するインスタンスの名前をクリックするか、インスタンスの [操作] 列にある [インスタンスの管理] をクリックします。
[インスタンス詳細] タブの [テーブル] セクションで、多次元インデックスを作成するデータテーブルの名前をクリックします。[テーブルの管理] ページで、[インデックス] をクリックします。または、データテーブルの [操作] 列にある [インデックス] をクリックすることもできます。
[インデックス] タブで、[多次元インデックスの作成] をクリックします。
[インデックスの作成] ダイアログボックスで、多次元インデックスを作成する際に仮想カラムを指定します。

デフォルトでは、システムが多次元インデックスの名前を生成します。多次元インデックスの名前を自分で指定することもできます。
[スキーマ生成タイプ] パラメーターを設定します。
[スキーマ生成タイプ] を [手動] に設定した場合は、追加する各フィールドのフィールド名を入力し、フィールドタイプと配列を有効にするかどうかを指定します。
[スキーマ生成タイプ] を [自動生成] に設定した場合は、システムが自動的にデータテーブルのプライマリキー列と属性列をインデックスフィールドとして使用します。ビジネス要件に基づいて、システムが自動的に追加した各フィールドのフィールドタイプと配列を有効にするかどうかを指定します。
説明[フィールド名] と [フィールドタイプ] の値は、データテーブルの値と一致する必要があります。データテーブルのフィールドタイプと多次元インデックスのフィールドタイプのマッピングについては、「データの型」をご参照ください。
仮想カラムを作成します。
重要仮想カラムを作成するには、データテーブルにソースフィールドが含まれている必要があり、ソースフィールドのデータの型が仮想カラムのデータの型と一致している必要があります。
 アイコンをクリックします。
アイコンをクリックします。 [フィールド名] と [フィールドタイプ] パラメーターを設定します。
フィールドの [仮想フィールド] を有効にし、[インデックスフィールド名] の値を指定します。
多次元インデックスのルーティングキー、生存時間 (TTL)、または事前ソートメソッドを指定する場合は、[詳細設定] を有効にします。詳細については、「多次元インデックスの作成」をご参照ください。
[OK] をクリックします。
多次元インデックスを作成した後、[インデックス] タブで多次元インデックスの [操作] 列にある [インデックス詳細] をクリックします。[インデックス詳細] ページで、[基本インデックス情報]、[インデックスメトリック]、[ルーティングキー]、[インデックスフィールド]、[事前ソート] の各セクションのパラメーター設定を表示します。
仮想カラムを使用してデータをクエリします。
多次元インデックスの [操作] 列にある [データの管理] をクリックします。
[検索] ダイアログボックスで、パラメーターを設定します。
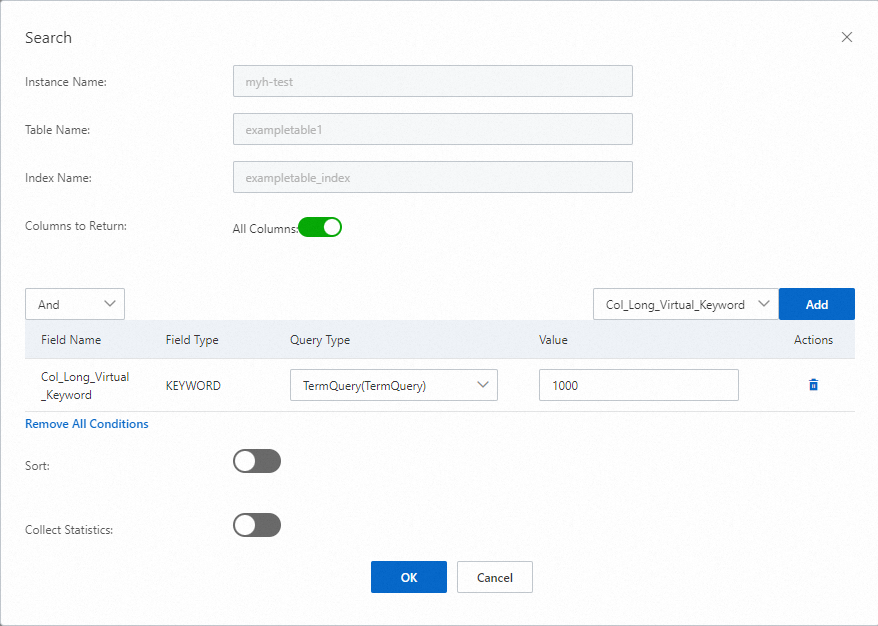
デフォルトでは、システムはすべての属性列を返します。特定の属性列を返すには、[すべての列] を無効にし、返したい属性列を指定します。属性列はカンマ (,) で区切ります。
インデックスフィールドを選択し、[追加] をクリックしてインデックスフィールドをクエリ条件として追加します。インデックスフィールドのクエリタイプと値を指定します。このステップを繰り返して、ビジネス要件に基づいてクエリ条件を追加します。
デフォルトでは、ソート機能は無効になっています。ソートを有効にするには、[ソート] を有効にし、クエリ結果のソート基準となるインデックスフィールドを追加して、ソートメソッドを設定します。
デフォルトでは、集約機能は無効になっています。特定のフィールドの統計を収集する場合は、[統計の収集] を有効にし、統計を収集するフィールドを指定してから、統計の収集に必要な情報を設定します。
[OK] をクリックします。
クエリ条件を満たすデータが、[インデックス] タブで指定された順序で表示されます。