Tablestore は、インターネットアプリケーションアーキテクチャ、データレイクアーキテクチャ、モノのインターネット (IoT) アーキテクチャという 3 つの異なるアーキテクチャでよく使用されます。インターネットアプリケーションアーキテクチャは、階層型データベースアーキテクチャと構造化データ用の分散アーキテクチャにさらに分類できます。このトピックでは、これらのアーキテクチャにおける Tablestore のアプリケーションシナリオについて説明します。
インターネットアプリケーションアーキテクチャ
今日の世界では、インターネットは私たちの生活に不可欠な一部となっています。私たちはインターネットで買い物をしたり、交流したり、楽しんだりしています。これは、さまざまなインターネットアプリケーションによって可能になり、注文履歴、インスタントメッセージング (IM)、フィードストリームなどのサービスによって支えられています。これらのサービスは、インターネットアプリケーションアーキテクチャを通じて Tablestore で簡単に構築できます。
注文履歴
注文システムは、今日ではさまざまな業界で使用されている非常に一般的なシステムです。たとえば、e コマースプラットフォームでは注文の保存、銀行では取引記録の保存、通信事業者では請求書の保存に使用されています。データがますます重要になるにつれて、注文に関するより多くのデータを永続的に保存する必要があります。リレーショナルデータベースは、強力なデータ整合性が必要なトランザクションを特徴とするオンラインワークロードに適しています。ただし、注文の量が増えると、これらのデータベースは非効率になり、注文とそのデータの関係の保存が困難になります。これは、階層型ストレージアーキテクチャによって解決できます。
注文履歴アプリケーションには、次の重要な要件があります。
オンラインデータ同期: リアルタイムデータと履歴データは異なる階層に保存する必要があり、リアルタイムデータのオンライン同期がサポートされている必要があります。
履歴データの保存: 大量の履歴データを費用対効果の高い方法で保存する必要があります。ストレージソリューションは、このデータに対する低レイテンシクエリもサポートする必要があります。
データ分析: 履歴データは、統計分析によく使用されます。ストレージソリューションは、計算機能を提供するか、計算機能と互換性がある必要があります。
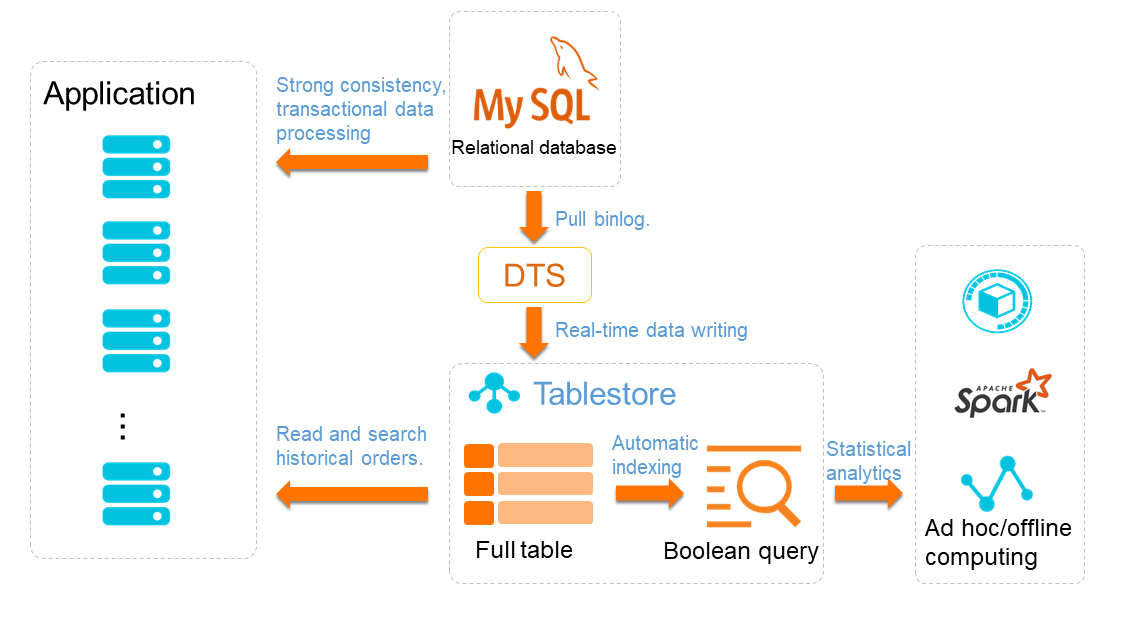
Tablestore の階層型データベースアーキテクチャを使用して、注文データを保存できます(次の図を参照)。
リレーショナルデータベースの補足として、Tablestore は注文データの永続ストレージとして使用されます。このデータは、DTS を介して Tablestore にリアルタイムで同期できます。Tablestore はブール型クエリもサポートしており、ストリームおよびバッチコンピューティングエンジンと組み合わせて統計分析を実行できます。
IM
IM は、すべてのインターネットビジネスの基本コンポーネントになり、ソーシャル化、ゲーム、ライブストリーミングなどのアプリケーションで広く使用されています。IM は、大規模で急速に増加するデータ量とリアルタイムのデータストレージを特徴としています。これらの特性により、ストレージシステムは大量のデータの保存、同期、および取得をサポートする必要があります。
IM アプリケーションには、次の重要な要件があります。
メッセージ履歴ライブラリ: 会話履歴を保存します。データの増加速度が速いため、ストレージソリューションは迅速かつ簡単に拡張できる必要があります。
メッセージ同期ライブラリ: 受信者別に同期されたメッセージを保存します。ストレージシステムは、高並列書き込みとリアルタイムプル (書き込みファンアウト) をサポートする必要があります。
メッセージのインデックス作成: データの取得を容易にし、データの更新と同期をサポートする必要があります。
Tablestore の構造化データ用の分散ストレージアーキテクチャを使用して、IM アプリケーションのメッセージを保存できます(次の図を参照)。
Tablestore は、IM アプリケーションとフィードストリーム用の軽量メッセージモデルであるタイムラインモデルを提供します。Tablestore は、数百 TB サイズのメッセージ同期テーブルと PB サイズのデータテーブルを保存できます。Tablestore は、1 秒あたり数百万件のメッセージのファンアウトと、ミリ秒単位のパフォーマンスでの同期データベースプルもサポートしています。

フィードストリーム
フィードストリームは、WeChat Moments、Weibo、TopBuzz などのソーシャルメディアアプリケーションにおけるコンテンツ配信の標準的な方法になっています。フィードストリームの典型的な読み取り/書き込み比率は 100:1 で、プッシュモードがよく使用されます。したがって、ストレージシステムは、自動インクリメント主キー列に基づく高並列メッセージ書き込みをサポートする必要があります。
フィードストリームアプリケーションには、次の重要な要件があります。
パブリッシャーのホームページ情報の保存: 履歴メッセージを保存し、パブリッシャーに基づいてソートする必要があり、ストレージシステムは大規模なデータの保存とクエリをサポートする必要があります。
フォロワー情報の保存: メッセージはフォロワーに基づいて保存する必要もあります。ストレージシステムは、高並列書き込みとリアルタイムプル (書き込みファンアウト) をサポートする必要があります。
関係リストの保存: パブリッシャーとフォロワーの関係は、ユーザーがコンテンツを表示または公開するたびに使用する必要があるため、保存する必要があります。関係の迅速な更新とクエリもサポートする必要があります。
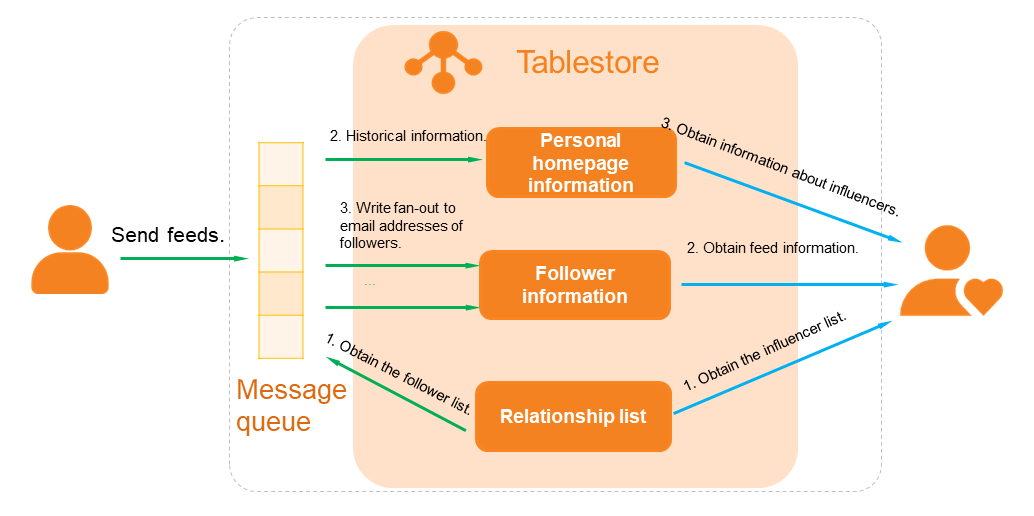
Tablestore の構造化データ用の分散アーキテクチャを使用して、フィードストリームのデータを保存できます(次の図を参照)。
Tablestore は、IM アプリケーションとフィードストリーム用の軽量メッセージモデルであるタイムラインモデルを提供します。Tablestore は、数百 TB サイズのメッセージ同期テーブルと PB サイズのデータテーブルを保存できます。Tablestore は、1 秒あたり数百万件のメッセージのファンアウトと、ミリ秒単位のパフォーマンスでの同期データベースプルもサポートしています。
ビッグデータ
ビッグデータアプリケーションは、膨大な速度で生成される大量の異種データを集約および分析します。増え続けるデータ量を費用対効果の高い方法で保存およびマイニングして価値を得ることが、すべてのビッグデータアプリケーションの重要な焦点となっています。Tablestore のデータレイクアーキテクチャは、これらの問題を解決できます。ビッグデータにおける Tablestore の典型的なアプリケーションシナリオには、レコメンデーション、世論分析、リスク管理などがあります。
レコメンデーションシステム
レコメンデーションシステムは、e コマース、ショートビデオストリーミング、メディアなどのシナリオで顧客のビジネスを改善するのに役立ちます。レコメンデーションシステムは、リアルタイムで生成される大量のデータを処理してパーソナライズされたレコメンデーションを提供するため、大量のメッセージデータの保存とリアルタイムおよびオフラインの処理機能をサポートするストレージソリューションが必要です。
レコメンデーションシステムには、次の重要な要件があります。
行動ログの保存: クライアントによって書き込まれたデータをリアルタイムで保存する必要があります。ストレージシステムは、ストリームコンピューティングシステムと連携して、高並列書き込みとリアルタイム分析をサポートする必要があります。
履歴データの保存: コールドデータは、オブジェクトストレージサービス (OSS) のデータレイクに同期されます。これには、階層型ストレージのために OSS にデータを送信する必要があります。
ユーザタグの保存: 分析タグとレコメンデーション情報を保存する必要があります。したがって、属性列のスケールアウトと効率的な取得をサポートする必要があります。
Tablestore のデータレイクアーキテクチャを使用して、レコメンデーションシステムのデータを保存できます(次の図を参照)。

世論分析とリスク管理 (データクローリング)
コメント、ニュース記事、アンケートなどの世論に関するデータを分析することにより、顧客は市場に関する洞察を効果的に得ることができます。ただし、これには、ストレージシステムが多様なデータの高並列書き込みと、効率的な計算と分析のための迅速なデータ転送をサポートする必要があります。
世論分析とリスク管理のシナリオには、次の重要な要件があります。
生データの保存: データは多数のデータクローラーによって書き込まれます。したがって、高並列データ書き込みと PB レベルの容量をサポートする必要があります。
さまざまな種類のデータの保存: 幅広い種類のデータがクローリングされ、タグが生成されます。これには、スキーマフリーの書き込みが必要です。
データ分析: データは前処理されて、構造化タグが生成および保存されます。これには、ストレージシステムがリアルタイムコンピューティングとオフラインコンピューティングシステムをサポートする必要があります。
Tablestore のデータレイクアーキテクチャを使用して、このシナリオでデータを保存できます(次の図を参照)。

IoT
システム O&M および IoT シナリオで環境と人員を追跡することは、企業が情報を理解し、情報に基づいた意思決定を行うのに役立ちます。これには、多数の異なるデバイスからの高並列書き込みと効率的なデータ分析をサポートするストレージソリューションが必要です。
システム O&M および IoT アプリケーションには、次の重要な要件があります。
高並列データ書き込み: ストレージシステムは、さまざまなデバイスやシステムを含む数百万のソースからのリアルタイムデータ書き込みをサポートする必要があります。
リアルタイムデータ集約: 生データは事前に集約および前処理されます。データは、リアルタイムでストリームコンピューティングシステムに同期する必要があります。
データストレージ: データは長期間保存する必要があるため、大規模なテーブルを費用対効果の高い方法でサポートするストレージソリューションが必要です。
Tablestore の IoT アーキテクチャは、システム O&M および IoT シナリオで使用できます(次の図を参照)。
