k最近傍(KNN)ベクトルクエリ機能を使用して、ベクトルに基づいて近似最近傍探索を実行できます。これにより、大規模なデータセットにおいて、クエリ対象のベクトルと最も類似性の高いデータ項目を見つけることができます。この機能は、レコメンデーションシステム、画像および動画検索、自然言語処理(NLP)、セマンティック検索など、さまざまなシナリオに適しています。
KNNベクトルクエリ機能の詳細については、概要を参照してください。
使用上の注意
KNNベクトルクエリ機能を使用するには、データテーブルでVectorフィールドがマッピングされている列のタイプがStringである必要があります。検索インデックスを作成する際には、String列がマッピングされているフィールドのタイプをVectorに設定する必要があります。次に、Vectorフィールドの次元数とデータ型、およびベクトル間の距離を測定するために使用するアルゴリズムを指定します。
SQLステートメントを実行してKNNベクトルクエリ機能を使用するには、データテーブル用に作成された検索インデックスのマッピングテーブルを作成する必要があります。検索インデックスのマッピングテーブルの作成方法については、検索インデックスのマッピングテーブルの作成を参照してください。
データ型マッピング
テーブルのデータ型 | 検索インデックスのデータ型 | SQLのSQLデータ |
String | Vector型。Vectorフィールドの次元数とデータ型、およびベクトル間の距離を測定するために使用されるアルゴリズムが指定されます。 | VARCHAR (主キー) |
MEDIUMTEXT (事前定義列) |
検索インデックスのマッピングテーブルの作成
CREATE TABLEステートメントを実行して検索インデックスのマッピングテーブルを作成する場合、Vectorフィールドの作成方法は、他の型のフィールドの作成方法と同じです。Vectorフィールドには、有効な名前とデータ型を指定するだけで済みます。検索インデックスのマッピングテーブルを作成する際には、Vector型のフィールドのSQLでマッピングされたデータ型としてMEDIUMTEXT型を指定することをお勧めします。
次のSQLステートメントの例は、Vector型のフィールドを含む検索インデックスのマッピングテーブルを作成する方法を示しています。
CREATE TABLE `test_table__test_table_index`(
`col_vector` MEDIUMTEXT
)
ENGINE='searchindex'
ENGINE_ATTRIBUTE='{"index_name":"test_table_index", "table_name":"test_table"}';KNNベクトルクエリの実行
VECTOR_QUERY_FLOAT32
VECTOR_QUERY_FLOAT32関数を使用して、ベクトルに基づいて近似最近傍探索を実行できます。
SQL式
VECTOR_QUERY_FLOAT32(fieldName, float32QueryVector,topk, filter)パラメータ
パラメータ
型
必須
説明
fieldName
string
はい
一致させるフィールドの名前。KNNベクトルクエリを実行するには、検索インデックスでフィールドの型がVectorである必要があります。
float32QueryVector
string
はい
類似性をクエリするベクトル。
重要次元数は、検索インデックスのVectorフィールドの次元数と一致している必要があります。
topK
int
はい
クエリ対象のベクトルと最も類似性の高い上位K件のクエリ結果。検索インデックスの制限で、topKパラメータの最大値について確認してください。
重要Kの値が大きいほど、再現率、クエリレイテンシ、およびコストが高くなります。
topKパラメータの値がSQLステートメントのlimitパラメータの値よりも小さい場合、サーバーは自動的にlimitパラメータの値をtopKパラメータの値として使用します。
filter
string
いいえ
フィルタ。KNNベクトルクエリ条件ではないクエリ条件の組み合わせを使用できます。
例
次のSQLステートメントの例は、exampletableテーブルのcol_vector列で、
[1.5, -1.5, 2.5, -2.5]と最も類似性の高い上位10個の値をクエリする方法を示しています。SELECT * FROM exampletable WHERE VECTOR_QUERY_FLOAT32(col_vector, "[1.5, -1.5, 2.5, -2.5]", 10) limit 10;
SCORE()
SCORE()関数を使用して、クエリ結果の関連性スコアをクエリできます。スコアが高いほど、類似性が高くなります。
SQL式
SCORE()例
次のSQLステートメントの例は、exampletableテーブルのcol_vector列で、
[1.5, -1.5, 2.5, -2.5]と最も類似性の高い上位10個の値をクエリし、クエリ結果の関連性スコアを表示する方法を示しています。SELECT *,SCORE() FROM exampletable WHERE VECTOR_QUERY_FLOAT32(col_vector, "[1.5, -1.5, 2.5, -2.5]", 10) limit 10;
KNNベクトルクエリと他のクエリ条件の組み合わせ
KNNベクトルクエリと他のクエリ条件をさまざまな組み合わせで使用できます。クエリ効果は、使用する組み合わせによって異なります。このセクションの例では、少量のデータがフィルタ条件を満たしています。
この例では、1億枚の画像がテーブルに格納されており、5万枚の画像がユーザーAに属しています。5万枚の画像のうち、50枚が2024年に格納されています。ユーザーAは、50枚の画像の中で、指定された画像と最も類似性の高い10枚の画像を検索したいと考えています。
次のSQLステートメントの例を実行すると、フィルタを使用して、2024年に格納されているユーザーAのすべての画像(合計50枚)が取得されます。次に、50枚の画像の中で、ユーザーAがクエリしたい画像と最も類似性の高い上位10枚の画像が特定され、ユーザーAに返されます。10枚の画像それぞれの関連性スコアが表示されます。
SELECT *,SCORE() FROM exampletable WHERE VECTOR_QUERY_FLOAT32(col_vector, "[1.5, -1.5, 2.5, -2.5]", 100, user="a" and year_num=2024) limit 10;次のSQLステートメントの例を実行すると、1億枚の画像の中で、ユーザーAがクエリしたい画像と最も類似性の高い上位500枚の画像が返されます。次に、500枚の画像の中で、2024年に格納されているユーザーAの画像で、指定された画像と最も類似性の高い10枚の画像が特定され、ユーザーAに返され、10枚の画像それぞれの関連性スコアが表示されます。上位500枚の画像には、2024年に格納されているユーザーAの50枚の画像がすべて含まれているとは限りません。このSQLステートメントの例を実行すると、ユーザーAは、50枚の画像の中で、指定された画像と最も類似性の高い10枚の画像を取得できない場合があります。極端な場合、ユーザーAは画像をまったく取得できない可能性があります。
SELECT *,SCORE() FROM exampletable WHERE user="a" and year_num=2024 and VECTOR_QUERY_FLOAT32(col_vector, "[1.5, -1.5, 2.5, -2.5]", 500) limit 10;
手順
この例では、vector_query_tableという名前のデータテーブルを使用します。データテーブルは、String型のpk主キー列、String型のcol_vector属性列、およびString型のcol_keyword属性列で構成されます。
SQLでKNNベクトルクエリを実行するには、データテーブルの検索インデックスを作成し、検索インデックスのマッピングテーブルを作成してから、SQLステートメントを実行します。手順:
検索インデックスを作成し、Vectorフィールドを設定します。詳細については、Tablestoreコンソールで検索インデックスを使用するおよびTablestore SDKを使用するを参照してください。
説明使用する検索インデックスにVectorフィールドが指定されていない場合は、検索インデックスのスキーマを変更してVectorフィールドを設定できます。詳細については、検索インデックスのスキーマを動的に変更するを参照してください。
次の図は、Tablestoreコンソールで検索インデックスを作成する方法を示しています。
この例では、
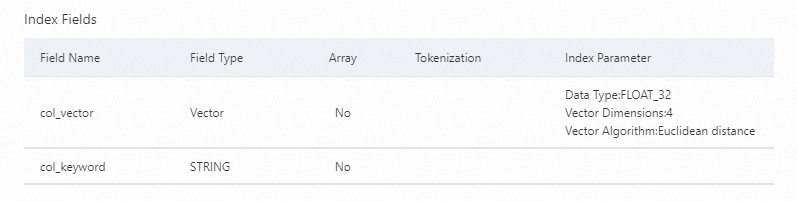
vector_query_table_indexという名前の検索インデックスが作成されます。検索インデックスは、Vector型のcol_vectorフィールドとString型のcol_keywordフィールドで構成されます。Vector型のcol_vectorフィールドは、データテーブルのString型のcol_vector列にマッピングされます。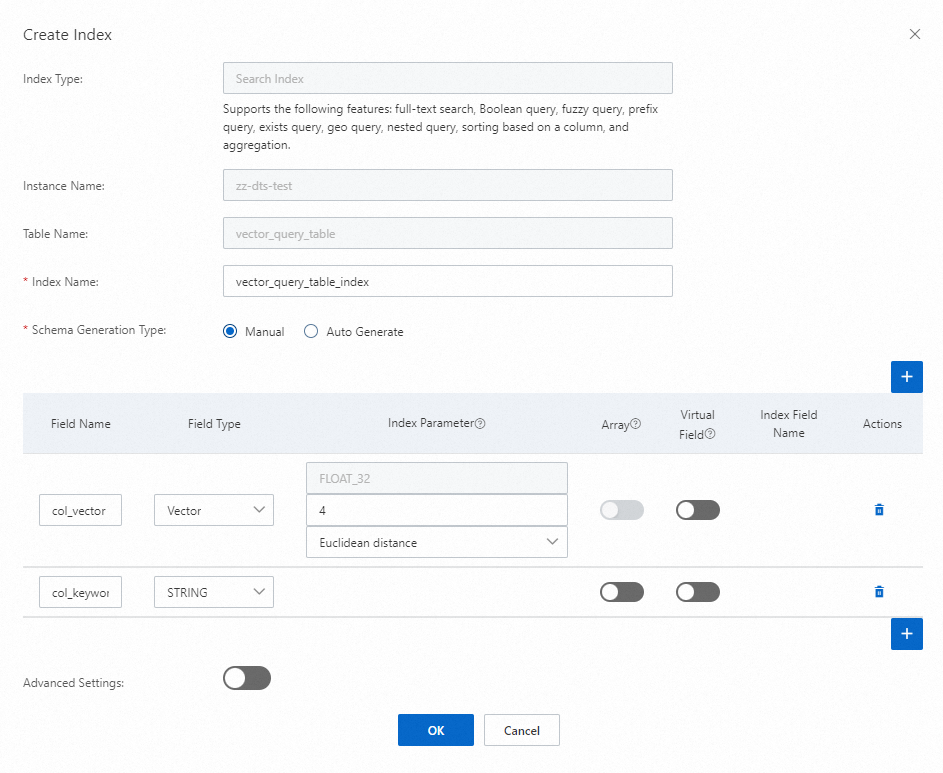
次の図は、検索インデックスのスキーマを示しています。
検索インデックスのマッピングテーブルを作成します。詳細については、TablestoreコンソールでSQLクエリ機能を使用するおよびTablestore SDKを使用してSQLクエリ機能を使用するを参照してください。
この例では、検索インデックス用に
vector_query_table__vector_query_table_indexという名前のマッピングテーブルが作成されます。マッピングテーブルのcol_vectorという名前のVectorフィールドにマッピングされているフィールドのデータ型は、SQLではMEDIUMTEXTです。詳細については、検索インデックスのマッピングテーブルの作成を参照してください。次のSQLステートメントの例を実行して、マッピングテーブルを作成できます。
CREATE TABLE `vector_query_table__vector_query_table_index`( `col_vector` MEDIUMTEXT, `col_keyword` MEDIUMTEXT ) ENGINE='searchindex', ENGINE_ATTRIBUTE='{"index_name":"vector_query_table_index","table_name":"vector_query_table"}';(オプション)検索インデックスのマッピングテーブルを作成した後、ビジネス要件に基づいて次の操作を実行できます。
テーブルに関する情報のクエリ
次のSQLステートメントを実行して、検索インデックスのマッピングテーブルに関する情報をクエリします。
DESCRIBE vector_query_table__vector_query_table_index;次の図は、クエリ結果を示しています。

テーブル内のデータのクエリ
次のSQLステートメントを実行して、検索インデックスのマッピングテーブル内のデータをクエリします。
SELECT * FROM vector_query_table__vector_query_table_index;次の図は、クエリ結果を示しています。たとえば、検索インデックスの
vector_query_table__vector_query_table_indexマッピングテーブルには、10行のデータが含まれています。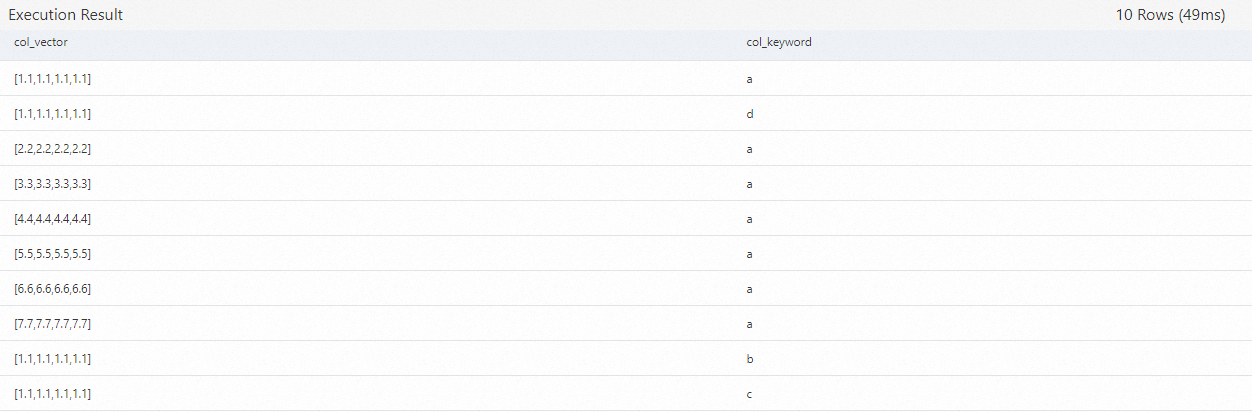
KNNベクトルクエリを実行してデータをクエリします。詳細については、データのクエリを参照してください。
次のSQLステートメントの例は、col_vector列で、
[1.5, 2.0, 2.5, 1.7]と最も類似性の高い上位5個の値をクエリし、クエリ結果の関連性スコアを表示する方法を示しています。SELECT *,SCORE() FROM vector_query_table__vector_query_table_index WHERE VECTOR_QUERY_FLOAT32(col_vector, "[1.5, 2.0, 2.5, 1.7]", 5) limit 5;次の図は、クエリ結果を示しています。

制限事項
VECTOR_QUERY_FLOAT32関数は、検索インデックス用に作成されたマッピングテーブルを使用してデータをクエリする場合にのみ使用できます。
VECTOR_QUERY_FLOAT32関数を使用する場合は、LIMIT句を使用する必要があります。HAVING句は使用できません。
VECTOR_QUERY_FLOAT32関数は、SELECTステートメントのWHERE句としてのみ使用でき、SELECTステートメントの列式、集計関数、グループ化、またはソートには使用できません。
SCORE()関数は、VECTOR_QUERY_FLOAT32関数と一緒に使用する必要があります。SCORE()関数を単独で使用することはできません。
SCORE()関数は、SELECTステートメントの列式としてのみ使用できます。SELECTステートメントのWHERE句、集計関数、またはソートには使用できません。