異常を検出するには、予測および異常検出関数を使用して時系列曲線を予測し、予測曲線と実際の曲線の間のエラーのKsigmaと分位数を特定します。
機能一覧
関数 | 説明 |
デフォルトパラメータを使用して時系列データをモデル化し、単純な時系列予測と異常検出を実行します。 | |
自己回帰モデル (AR) モデルを使用して時系列データをモデル化し、単純な時系列予測と異常検出を実行します。 | |
自己回帰移動平均 (ARMA) モデルを使用して時系列データをモデル化し、単純な時系列予測と異常検出を実行します。 | |
自己回帰統合移動平均 (ARIMA) モデルを使用して時系列データをモデル化し、単純な時系列予測と異常検出を実行します。 | |
周期的な時系列曲線の傾向を正確に予測する。 シナリオ: この関数は、測定データ、ネットワークトラフィック、財務データ、および特定のルールに従うさまざまなビジネスデータを予測するために使用できます。 | |
カスタム異常モードに基づいて、複数の時系列曲線で異常検出中に検出された異常をフィルタリングします。 この機能は、異常な曲線をすばやく見つけるのに役立ちます。 |
ts_predicate_simple
関数の形式:
select ts_predicate_simple(x, y, nPred, isSmooth) 関数形式のパラメーターを次の表に示します。
パラメーター | 説明 | 値 |
x | タイムシーケンス。 時間内のポイントは、横軸に沿って昇順にソートされます。 | 各時点はUnixタイムスタンプです。 単位は秒です。 |
y | 指定された各時点に対応する数値データのシーケンス。 | 非該当 |
nPred | 予測のポイント数。 | 値はlongデータ型で、1以上でなければなりません。 |
isSmooth | 生データをフィルタリングするかどうかを指定します。 | 値はBooleanデータ型です。 デフォルト値はtrueで、生データがフィルタリングされていることを示します。 |
例:
クエリステートメントは次のとおりです。
* | select ts_predicate_simple(stamp, value, 6) from (select ("__time__" - ("__time__" % 60)) as stamp, avg(v) as value from log GROUP BY stamp order by stamp)出力結果
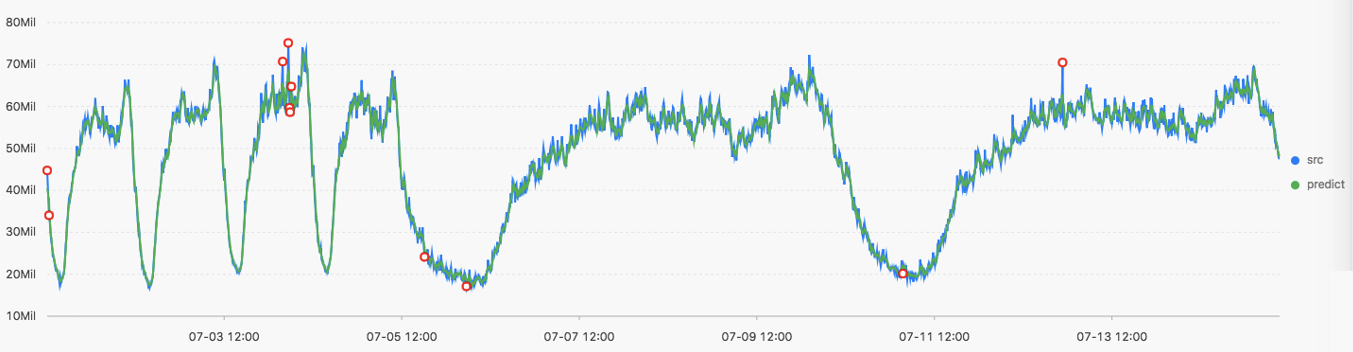
表示项目一覧を次の表に示します。
表示アイテム | 説明 | |
横軸 | unixtime | データのUnixタイムスタンプ。 単位は秒です。 |
垂直軸 | src | 生データ。 |
predict | フィルタリング演算後に生成されたデータが実行される。 | |
upper | 信頼区間の上限。 信頼レベルは0.85であり、変更することはできない。 | |
lower | 信頼区間の下限。 信頼レベルは0.85であり、変更することはできない。 | |
anomaly_prob | ポイントが異常である確率。 有効な値: [0, 1] | |
ts_predicate_ar
関数の形式:
select ts_predicate_ar(x, y, p, nPred, isSmooth) 関数形式のパラメーターを次の表に示します。
パラメーター | 説明 | 値 |
x | タイムシーケンス。 時間内のポイントは、横軸に沿って昇順にソートされます。 | 各時点はUnixタイムスタンプです。 単位は秒です。 |
y | 指定された各時点に対応する数値データのシーケンス。 | 非該当 |
p | ARモデルの順序。 | 値はlongデータ型です。 有効な値: 2、3、4、5、6、7、および8。 |
nPred | 予測のポイント数。 | 値はlongデータ型です。 有効値: [1, 5 × p] 。 |
isSmooth | 生データをフィルタリングするかどうかを指定します。 | 値はBooleanデータ型です。 デフォルト値はtrueで、生データがフィルタリングされていることを示します。 |
クエリ文の例を次に示します。
* | select ts_predicate_ar(stamp, value, 3, 4) from (select ("__time__" - ("__time__" % 60)) as stamp, avg(v) as value from log GROUP BY stamp order by stamp)出力結果は、ts_predicate_simple関数と同様です。 詳細については、ts_predicate_simple関数の出力結果をご参照ください。
ts_predicate_arma
関数の形式:
select ts_predicate_arma(x, y, p, q, nPred, isSmooth) 関数形式のパラメーターを次の表に示します。
パラメーター | 説明 | 値 |
x | タイムシーケンス。 時間内のポイントは、横軸に沿って昇順にソートされます。 | 各時点はUnixタイムスタンプです。 単位は秒です。 |
y | 指定された各時点に対応する数値データのシーケンス。 | 非該当 |
p | ARモデルの順序。 | 値はlongデータ型です。 有効な値: [2, 100] 。 |
q | ARMAモデルの順序。 | 値はlongデータ型です。 有効な値: 2、3、4、5、6、7、および8。 |
nPred | 予測のポイント数。 | 値はlongデータ型です。 有効値: [1, 5 × p] 。 |
isSmooth | 生データをフィルタリングするかどうかを指定します。 | 値はBooleanデータ型です。 デフォルト値はtrueで、生データがフィルタリングされていることを示します。 |
クエリ文の例を次に示します。
* | select ts_predicate_arma(stamp, value, 3, 2, 4) from (select ("__time__" - ("__time__" % 60)) as stamp, avg(v) as value from log GROUP BY stamp order by stamp) 出力結果は、ts_predicate_simple関数と同様です。 詳細については、ts_predicate_simple関数の出力結果をご参照ください。
ts_predicate_arima
関数の形式:
select ts_predicate_arima(x, y, p, d, q, nPred, isSmooth) 関数形式のパラメーターを次の表に示します。
パラメーター | 説明 | 値 |
x | タイムシーケンス。 時間内のポイントは、横軸に沿って昇順にソートされます。 | 各時点はUnixタイムスタンプです。 単位は秒です。 |
y | 指定された各時点に対応する数値データのシーケンス。 | 非該当 |
p | ARモデルの順序。 | 値はlongデータ型です。 有効な値: 2、3、4、5、6、7、および8。 |
d | ARIMAモデルの順序。 | 値はlongデータ型です。 有効な値: [1, 3] 。 |
q | ARMAモデルの順序。 | 値はlongデータ型です。 有効な値: 2、3、4、5、6、7、および8。 |
nPred | 予測のポイント数。 | 値はlongデータ型です。 有効値: [1, 5 × p] 。 |
isSmooth | 生データをフィルタリングするかどうかを指定します。 | 値はBooleanデータ型です。 デフォルト値はtrueで、生データがフィルタリングされていることを示します。 |
クエリ文の例を次に示します。
* | select ts_predicate_arima(stamp, value, 3, 1, 2, 4) from (select ("__time__" - ("__time__" % 60)) as stamp, avg(v) as value from log GROUP BY stamp order by stamp)出力結果は、ts_predicate_simple関数と同様です。 詳細については、ts_predicate_simple関数の出力結果をご参照ください。
ts_regression_predict
関数の形式:
select ts_regression_predict(x, y, nPred, algotype,processType)関数形式のパラメーターを次の表に示します。
パラメーター | 説明 | 値 |
x | タイムシーケンス。 時間内のポイントは、横軸に沿って昇順にソートされます。 | 各時点はUnixタイムスタンプです。 単位は秒です。 |
y | 指定された各時点に対応する数値データのシーケンス。 | 非該当 |
nPred | 予測のポイント数。 | 値はlongデータ型です。 有効な値: [1, 500] 。 |
アルゴタイプ | 予測のアルゴリズムタイプ。 | 有効な値:
|
processType | データを前処理するかどうかを指定します。 | 有効な値:
|
例:
クエリステートメントは次のとおりです。
* and h : nu2h05202.nu8 and m: NET | select ts_regression_predict(stamp, value, 200, 'origin') from (select ("__time__" - ("__time__" % 60)) as stamp, avg(v) as value from log group by stamp order by stamp)出力結果
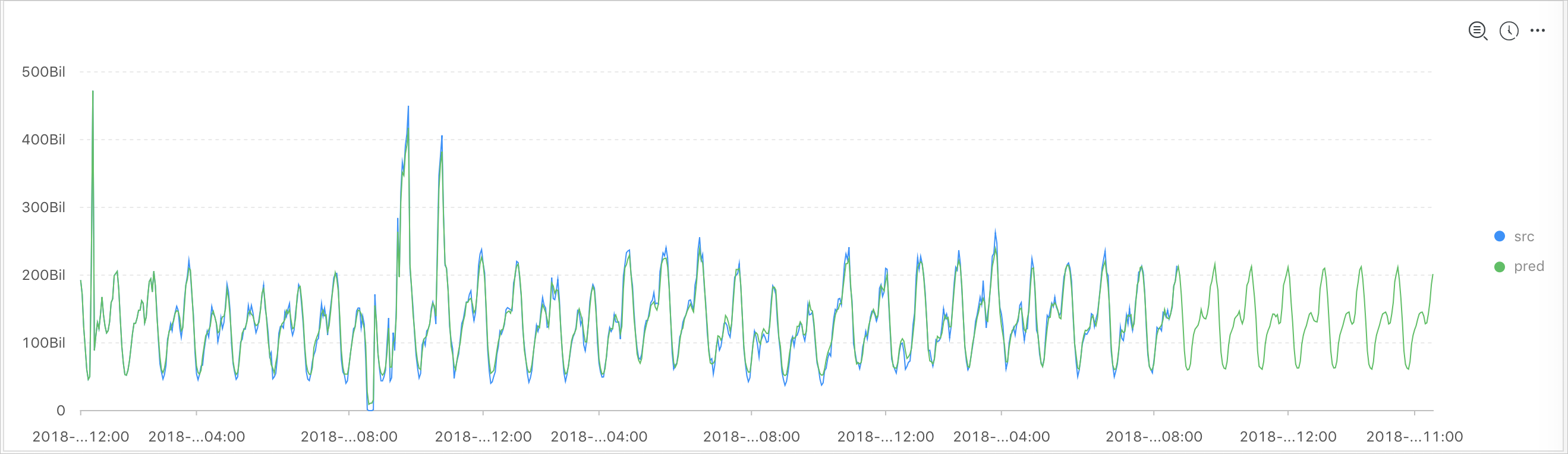
表示项目一覧を次の表に示します。
表示アイテム | 説明 | |
横軸 | unixtime | データのUnixタイムスタンプ。 単位は秒です。 |
垂直軸 | src | 生データ。 |
predict | フィルタリング演算後に生成されたデータが実行される。 | |
ts_anomaly_filter
関数の形式:
select ts_anomaly_filter(lineName, ts, ds, preds, probs, nWatch, anomalyType)関数形式のパラメーターを次の表に示します。
パラメーター | 説明 | 値 |
lineName | 各カーブの名前。 値はvarchar型です。 | 非該当 |
ts | 現在のカーブの時間を示すカーブの時間シーケンス。 パラメーター値は、昇順でソートされたdoubleデータ型の時点の配列です。 | 非該当 |
ds | カーブの実際の値シーケンス。 パラメーター値は、doubleデータ型のデータポイントの配列です。 このパラメーター値はtsパラメーター値と同じ長さです。 | 非該当 |
プレド | カーブの予測値シーケンス。 パラメーター値は、doubleデータ型のデータポイントの配列です。 このパラメーター値はtsパラメーター値と同じ長さです。 | 非該当 |
probs | カーブの異常検出結果のシーケンス。 パラメーター値は、doubleデータ型のデータポイントの配列です。 このパラメーター値はtsパラメーター値と同じ長さです。 | 非該当 |
nWatch | 曲線上の最近観察された実際の値の数。 値はlongデータ型です。 値は、カーブ上の時点の数よりも小さくなければなりません。 | 非該当 |
anomalyType | フィルタリングする異常のタイプ。 値はlongデータ型です。 | 有効な値:
|
例:
クエリステートメントは次のとおりです。
* | select res.name, res.ts, res.ds, res.preds, res.probs from ( select ts_anomaly_filter(name, ts, ds, preds, probs, cast(5 as bigint), cast(1 as bigint)) as res from ( select name, res[1] as ts, res[2] as ds, res[3] as preds, res[4] as uppers, res[5] as lowers, res[6] as probs from ( select name, array_transpose(ts_predicate_ar(stamp, value, 10)) as res from ( select name, stamp, value from log where name like '%asg-%') group by name)) );出力結果
| name | ts | ds | preds | probs | | ------------------------ | ---------------------------------------------------- | ----------- | --------- | ----------- | | asg-bp1hylzdi2wx7civ0ivk | [1.5513696E9, 1.5513732E9, 1.5513768E9, 1.5513804E9] | [1,2,3,NaN] | [1,2,3,4] | [0,0,1,NaN] |