GROUP BY 句は、多くの場合、集計関数と共に使用され、1 つ以上の列の値に基づいてクエリ結果の行を分類します。これにより、値の一意の組み合わせごとにサマリー行が作成され、データ分析が向上します。さらに、GROUP BY は、ROLLUP、CUBE、および GROUPING SETS と組み合わせて、グループ化機能を強化し、より多くの分析オプションを提供できます。
基本構文
GROUP BY
GROUP BY 句は、分析結果をグループ化します。
SELECT
key1,
...
aggregate_function
GROUP BY
key,...パラメータ:
key1: 値でグループ化する列。ログフィールド名または集計関数の結果列によるグループ化をサポートします。GROUP BY句は、単一または複数の列をサポートします。aggregate_function: 各グループに適用される 集計関数 (count、min、max、avg、sumなど)。
GROUP BY ROLLUP
GROUP BY ROLLUP 句は、各グループのサマリーとすべてのグループの合計を作成します。たとえば、GROUP BY ROLLUP (a, b) の結果セットには、(a, b)、(a, null)、および (null, null) が含まれます。
SELECT
key1,
...
aggregate_function
GROUP BY ROLLUP (key1,...)パラメータ:
key1: 値でグループ化する列。ログフィールド名または集計関数の結果列によるグループ化をサポートします。GROUP BY句は、単一または複数の列をサポートします。aggregate_function: 各グループに適用される 集計関数 (count、min、max、avg、sumなど)。
GROUP BY CUBE
GROUP BY CUBE 句は、考えられるすべての列の組み合わせでグループ化します。たとえば、GROUP BY CUBE (a, b) の結果セットには、(a, b)、(null, b)、(a, null)、および (null, null) が含まれます。
SELECT
key1,
...
aggregate_function
GROUP BY CUBE (key1,...)パラメータ:
key1: 値でグループ化する列。ログフィールド名または集計関数の結果列によるグループ化をサポートします。GROUP BY句は、単一または複数の列をサポートします。aggregate_function: 各グループに適用される 集計関数 (count、min、max、avg、sumなど)。
GROUP BY GROUPING SETS
GROUP BY GROUPING SETS 句は、列を順番にグループ化します。たとえば、GROUP BY GROUPING SETS (a, b) の結果セットには、(a, null) と (null, b) が含まれます。
SELECT
key1,
...
aggregate_function
GROUP BY GROUPING SETS (key1,...)パラメータ:
key1: 値でグループ化する列。ログフィールド名または集計関数の結果列によるグループ化をサポートします。GROUP BY句は、単一または複数の列をサポートします。aggregate_function: 各グループに適用される 集計関数 (count、min、max、avg、sumなど)。
例
SQL 文では、GROUP BY 句を使用する場合、SELECT 文では以下のみを選択できます。
GROUP BY句で指定された列。任意の列に対する集計計算の結果 (たとえば、
COUNT()、SUM()など)。
GROUP BY 句に含まれていない列を直接選択することは許可されていません。これは、グループ化後にそれらの値が一意ではなくなり、あいまいさが生じる可能性があるためです。たとえば、次の文は無効です。
* | SELECT status, request_time, COUNT(*) AS PV GROUP BY statusこれは、request_time が GROUP BY 句の一部ではなく、集計されていないためです。
正しい形式は次のとおりです。
* | SELECT status, arbitrary(request_time), COUNT(*) AS PV GROUP BY statusarbitrary(request_time) は、request_time を集計する方法であり、各グループからランダムな request_time 値が選択されることを示します。このアプローチは、SQL 構文規則に準拠し、クエリ要件を満たしています。
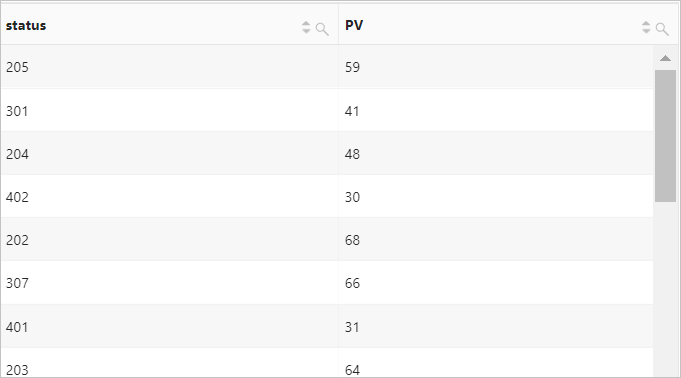
例 1: 状態コード別にページビュー (PV) をカウントする
クエリ文
* | SELECT status, count(*) AS PV GROUP BY statusクエリ結果
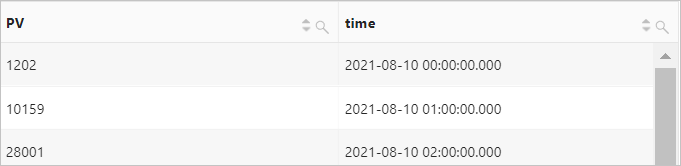
例 2: ウェブサイトアクセスの 1 時間ごとの PV をカウントする
クエリ文
__time__フィールドは、Simple Log Service の予約フィールドであり、時間列を表します。timeはdate_trunc('hour', __time__)のエイリアスです。詳細については、「date_trunc 関数」をご参照ください。* | SELECT count(*) AS PV, date_trunc('hour', __time__) AS time GROUP BY time ORDER BY time LIMIT 1000クエリ結果
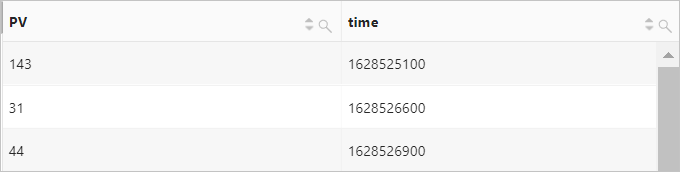
例 3: 5 分間隔で PV をカウントする
クエリ文
date_trunc関数は一定の間隔でカウントするため、カスタムの時間ベースの統計分析に剰余演算を使用できます。たとえば、%300は、データを 5 分間隔でグループ化するための剰余演算を表します。* | SELECT count(*) AS PV, __time__-__time__ % 300 AS time GROUP BY time LIMIT 1000クエリ結果
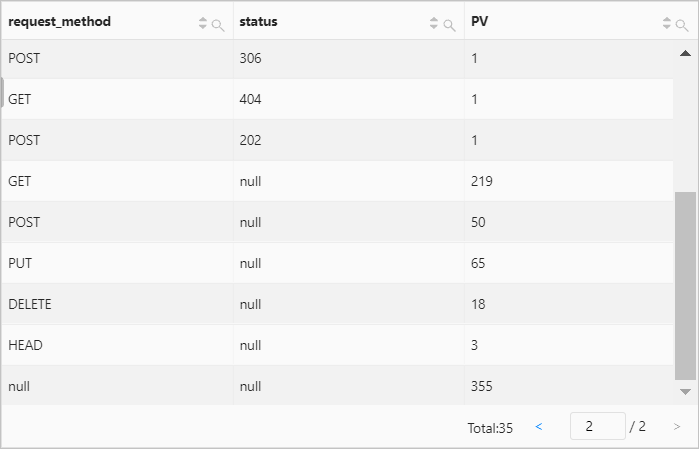
例 4: リクエストメソッドとステータス別にグループ化し、各メソッドのアクセスデータと各ステータスのカウントを計算する
クエリ文
* | SELECT request_method, status, count(*) AS PV GROUP BY GROUPING SETS (request_method, status)クエリ結果
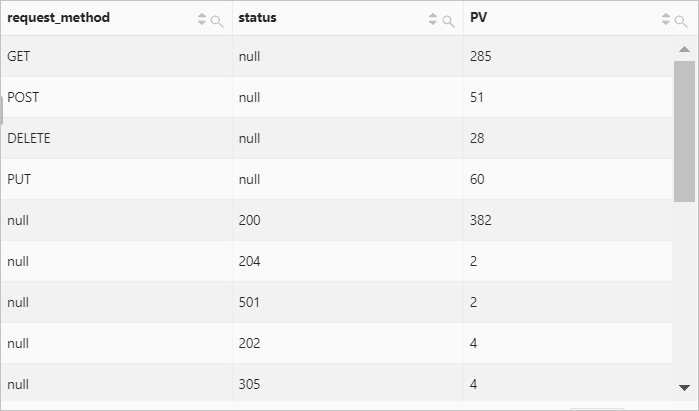
例 5: セット
(null, null)、(request_method, null)、(null, status)、および(request_method, status)を使用してリクエストメソッドとステータス別にグループ化し、各グループのアクセス数を計算するクエリ文
* | SELECT request_method, status, count(*) AS PV GROUP BY CUBE (request_method, status)クエリ結果
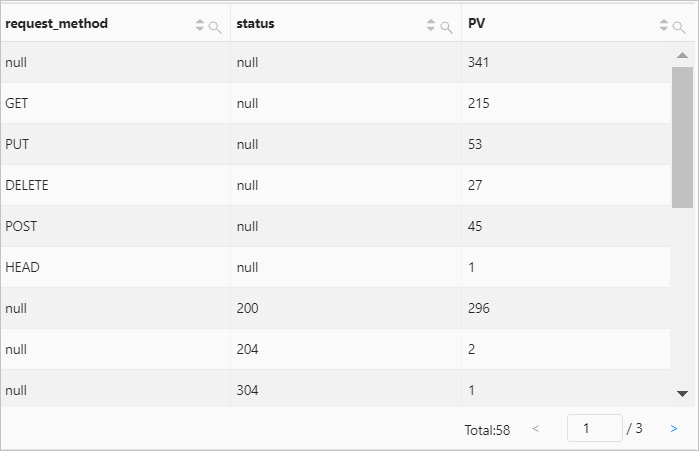
例 6: セット
(request_method, status)、(request_method, null)、および(null, null)を使用してリクエストメソッドとステータス別にグループ化し、各グループのアクセス数を計算するクエリ文
* | SELECT request_method, status, count(*) AS PV GROUP BY ROLLUP (request_method, status)クエリ結果