このトピックでは、リソース関数の構文とパラメーターについて説明します。 このトピックでは、関数の使用方法の例も示します。
関数
次のリソース関数を呼び出すときは、高度なプレビューモードを設定して、必要なデータを取得する必要があります。 詳細プレビューモードの設定方法の詳細については、「詳細プレビュー」をご参照ください。
関数 | 説明 |
現在のデータ変換ジョブから高度なパラメーターの値を取得します。 この関数は、他の関数と一緒に使用できます。 詳細については、「Simple Log Serviceを使用してApsaraDB RDS For MySQLインスタンスに接続し、データを強化する」をご参照ください。 | |
ApsaraDB RDS for MySQLインスタンスに作成されたデータベースの指定されたテーブルからデータを取得するか、SQLステートメントの実行結果を取得します。 データと結果は定期的に更新できます。 この関数は、他の関数と一緒に使用できます。 詳細については、「Simple Log Serviceを使用してApsaraDB RDS For MySQLインスタンスに接続し、データを強化する」をご参照ください。 | |
Logstore内のデータを変換するときに、別のLogstoreからデータをプルします。 継続的にデータをプルできます。 この関数は、他の関数と一緒に使用できます。 詳細については、「あるログストアからデータをプルして別のログストアのログデータを強化する」をご参照ください。 | |
指定されたobject Storage Service (OSS) バケット内のオブジェクトからデータを取得します。 データは定期的に更新できます。 この関数は、他の関数と一緒に使用できます。 詳細については、「OSSからCSVファイルをプルしてデータを強化する」をご参照ください。 |
res_local
res_local関数は、現在のデータ変換ジョブから高度なパラメーターの値を取得します。
構文
res_local(param, default=None, type="auto")パラメーター
パラメーター
型
必須 / 任意
説明
param
String
対象
現在のデータ変換ジョブの詳細パラメーター設定で指定されているキー。
default
String
任意
paramパラメーターに指定されたキーが存在しない場合に返される値。 デフォルト値: None。
type
String
任意
出力データのフォーマットです。 有効な値:
auto: 生データはJSON文字列に変換されます。 変換が失敗した場合、生データが返されます。 デフォルト値です。
JSON: 生データはJSON文字列に変換されます。 変換が失敗した場合は、default パラメーターの値が返されます。
raw: 生データが返されます。
レスポンス
パラメーター設定に基づいてJSON文字列または生データが返されます。
変換の成功
生データ
戻り値
戻り値のデータ型
1
1
Integer
1.2
1.2
浮く
true
正しい
Boolean
false
False
Boolean
"123"
123
String
null
なし
なし
["v1", "v2", "v3"]
["v1", "v2", "v3"]
List
["v1", 3, 4.0]
["v1", 3, 4.0]
List
{"v1": 100, "v2": "good"}
{"v1": 100, "v2": "good"}
List
{"v1": {"v11": 100, "v2": 200}, "v3": "good"}
{"v1": {"v11": 100, "v2": 200}, "v3": "good"}
List
変換の失敗
次の表に、変換失敗の例をいくつか示します。 次の生データはJSON文字列に変換されず、生データは文字列として返されます。
生データ
戻り値
説明
(1,2,3)
"(1,2,3)"
タプルはサポートされていません。 リストを使用する必要があります。
正しい
"True",
Booleanデータ型の値は、trueまたはfalseのみになります。 値は小文字である必要があります。
{1: 2, 3: 4}
"{1: 2, 3: 4}"
辞書キーは文字列のみです。
例
詳細パラメーター設定で指定したキーを取得し、取得したキーの値をlocalパラメーターに割り当てます。
高度なパラメーター設定では、キーはendpointで、値はhangzhouです。
生ログ
content: 1変換ルール
e_set("local", res_local('endpoint'))結果
content: 1 local: hangzhou
関連ドキュメント
この関数は、他の関数と一緒に使用できます。 詳細については、「Simple Log Serviceを使用してApsaraDB RDS For MySQLインスタンスに接続し、データを強化する」をご参照ください。
res_rds_mysql
res_rds_mysql関数は、ApsaraDB RDS for MySQLインスタンスに作成されたデータベース内の指定されたテーブルからデータを取得するか、SQLステートメントの実行結果を取得します。 Log Serviceでは、次の方法を使用してデータをプルできます。
res_rds_mysql関数を使用して、ApsaraDB RDS for MySQLインスタンスに作成されたデータベースからデータをプルする場合、インスタンスにホワイトリストを作成し、
ticket0.0.0.0をホワイトリストに追加する必要があります。 これにより、すべてのIPアドレスからデータベースにアクセスできます。 ただし、これはデータベースにリスクをもたらす可能性があります。 Log ServiceのIPアドレスをホワイトリストに追加する場合は、Log Serviceは、インスタンスのパブリックまたは内部エンドポイントを使用して、ApsaraDB RDS for MySQLインスタンスに作成されたデータベースにアクセスできます。 内部エンドポイントを使用する場合は、詳細パラメーターを設定する必要があります。 詳細については、「Simple Log Serviceを使用してApsaraDB RDS For MySQLインスタンスに接続し、データを強化する」をご参照ください。
すべてのデータを1回だけプルする
データ変換ジョブを初めて実行すると、Log Serviceは指定されたテーブルからすべてのデータをプルし、データをプルしなくなります。 データベースが更新されない場合は、この方法を使用することを推奨します。
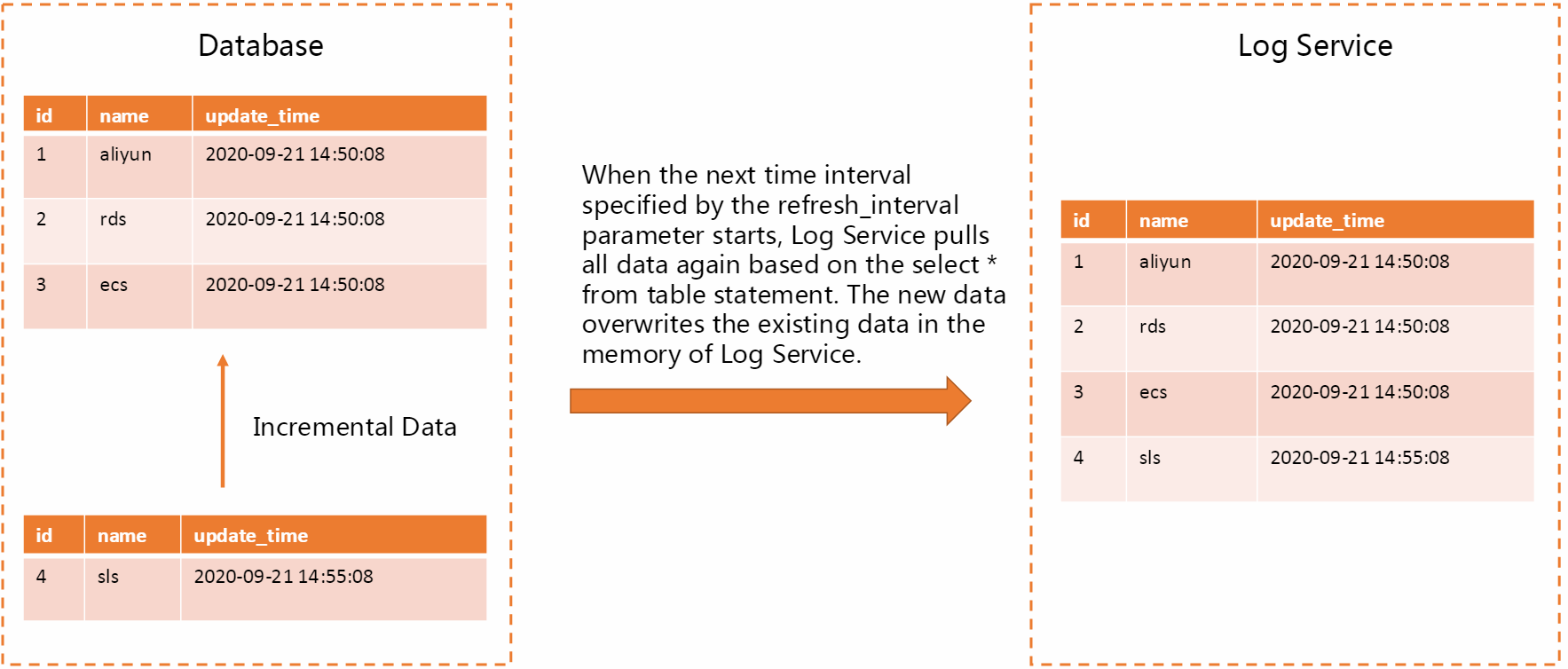
定期的にすべてのデータをプル
データ変換ジョブを実行すると、Log Serviceは指定されたテーブルからすべてのデータを定期的に取得します。 これにより、Log Serviceはデータベースとデータをタイムリーに同期できます。 しかし、この方法では時間がかかる。 データベースのデータ量が2 GB以下で、refresh_intervalパラメーターの値が300秒以上の場合、この方法を使用することを推奨します。
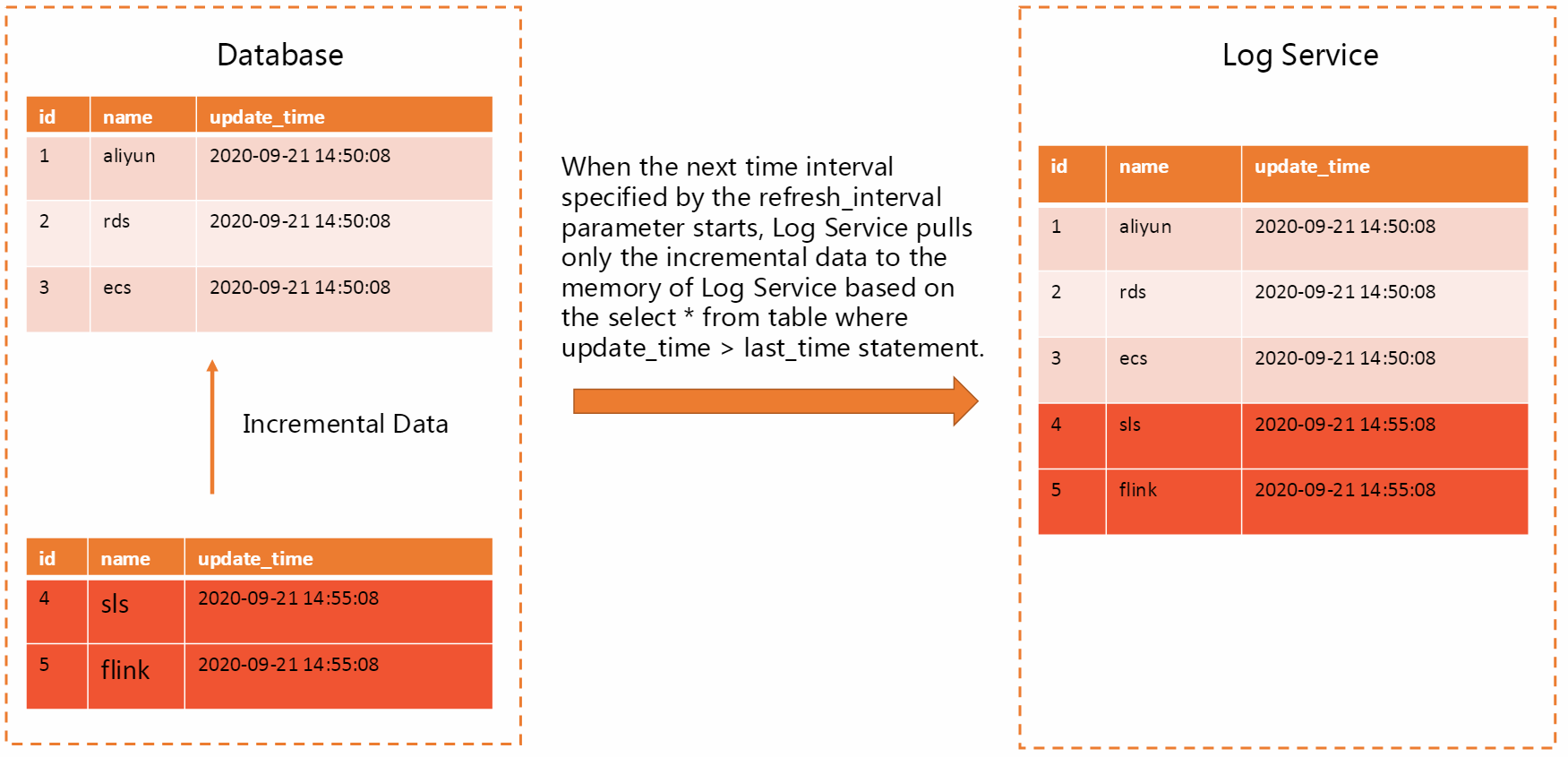
一定間隔で増分データをプルする
データ変換ジョブを実行すると、Log Serviceは指定されたデータベースのタイムスタンプフィールドに基づいて増分データのみを取得します。 この方法を使用すると、Log Serviceは新しく追加されたデータのみを取得します。 この方法は効率的です。 refresh_intervalパラメーターを1秒に設定すると、数秒以内にデータを同期できます。 データベースのデータ量が多い場合、データが頻繁に更新される場合、またはタイムリーにデータを取得する必要がある場合は、この方法を使用することをお勧めします。
構文
res_rds_mysql(address="The address of the database from which data is pulled", username="The username used to connect to the database", password="The password used to connect to the database", database="The name of the database", table=None, sql=None, fields=None, fetch_include_data=None, fetch_exclude_data=None, refresh_interval=0, base_retry_back_off=1, max_retry_back_off=60, primary_keys=None, use_ssl=false, update_time_key=None, deleted_flag_key=None)説明res_rds_mysql関数を使用して、AnalyticDB for MySQLまたはPolarDB for MySQLクラスターで作成されたデータベースからデータをプルすることもできます。 これらのシナリオでは、変換ルール内のデータベースのアドレス、ユーザー名、パスワード、および名前を実際の値に置き換えるだけで済みます。
パラメーター
パラメーター
型
必須 / 任意
説明
address
String
対象
接続するデータベースのエンドポイントまたはIPアドレス。 ポート番号が3306でない場合は、
IP address: port形式で値を指定してください。 詳細については、「エンドポイントとポート番号の表示と変更」をご参照ください。username
String
対象
データベースへの接続に使用されるユーザー名。
password
String
対象
データベースへの接続に使用されるパスワードです。
削除
String
対象
接続するデータベースの名前。
table
String
対象
データを取得するテーブルの名前。 sqlパラメーターが設定されている場合、このパラメーターは必要ありません。
sql
String
対象
SQL SELECTステートメントを使用して、データベースから関連するすべてのデータを取得し、処理メモリにロードします。 SQLは、フィールドと行をフィルタリングしてメモリ使用量を最適化し、処理メモリテーブルが占有するスペースを削減できます。 tableパラメーターが設定されている場合、このパラメーターは必要ありません。
fields
String list
非対象
文字列リストまたは文字列エイリアスリストです。 このパラメーターを設定しない場合、sqlまたはtableパラメーターに返されるすべての列が使用されます。 たとえば、名前を変更する場合は、名前の列["user_id", "province", "city", "name", "age"]リストにuser_nameを設定する必要があります。フィールドパラメーターを["user_id", "province", "city", ("name", "user_name"), ("nick_name"), "age"].
説明sql、table、およびfieldsパラメーターを一緒に設定すると、SQLパラメーターのsql文が実行されます。 tableおよびfieldsパラメーターは有効になりません。
fetch_include_data
String
任意
フィールドのホワイトリスト。 フィールドがfetch_include_dataパラメーターと一致するログは保持されます。 フィールドがこのパラメーターと一致しないログは破棄されます。
このパラメーターを設定しないか、このパラメーターを [なし] に設定すると、フィールドホワイトリスト機能は無効になります。
このパラメーターを特定のフィールドとフィールド値に設定すると、フィールドとフィールド値を含むログが保持されます。
fetch_exclude_data
String
任意
フィールドのブラックリスト。 フィールドがfetch_exclude_dataパラメーターと一致するログは破棄されます。 フィールドがこのパラメーターと一致しないログは保持されます。
このパラメーターを設定しないか、このパラメーターを [なし] に設定すると、フィールドブラックリスト機能は無効になります。
このパラメーターを特定のフィールドとフィールド値に設定すると、フィールドとフィールド値を含むログは破棄されます。
説明fetch_include_dataパラメーターとfetch_exclude_dataパラメーターの両方を設定した場合、データは最初にfetch_include_dataパラメーターの設定に基づいてプルされ、次にfetch_exclude_dataパラメーターの設定に基づいてプルされます。
refresh_interval
Numeric string or number
非対象
ApsaraDB RDS for MySQLからデータを取得する間隔。 単位は秒です。 デフォルト値:0 この値は、すべてのデータが1回だけプルされることを示します。
base_retry_back_off
Number
非対象
プル失敗後にシステムがデータを再度プルしようとする間隔。 デフォルト値:1 単位は秒です。
max_retry_back_off
Int
非対象
プル失敗後の2つの連続した再試行間の最大間隔。 デフォルト値: 60。 単位は秒です。 デフォルト値を使用することを推奨します。
primary_keys
文字列 /リスト
非対象
メモリ内ディメンションテーブルのkey-valueストアの主キー。 このパラメーターを設定すると、テーブル内のデータはキー: 値形式の辞書としてメモリに保存されます。 ディクショナリ内のキーは、primary_keysパラメーターの値です。 ディクショナリ内の値は、テーブル内のデータの行全体です。
説明primery_keysパラメーターを設定する必要があります。 そうしないと、パフォーマンスが大きく影響し、タスクの遅延が発生する可能性があります。
primary_keysパラメーターの値は、テーブルから取得されるフィールドに存在する必要があります。
primery_keysパラメーターの値は大文字と小文字が区別されます。
use_ssl
Boolean
非対象
SSLプロトコルを使用してApsaraDB RDS for MySQLインスタンスに接続するかどうかを指定します。 デフォルト値:false
説明ApsaraDB RDS for MySQLインスタンスでSSL暗号化が有効になっている場合、Log ServiceはSSL経由でインスタンスに接続します。 ただし、サーバー証明書は検証されません。 サーバー証明書を使用して接続を確立することはできません。
update_time_key
String
任意
増分データをプルするために使用される時間フィールド。 このパラメーターを設定しないと、すべてのデータがプルされます。 たとえば、update_time_key="update_time" のupdate_timeは、データベース内のデータ更新の時間フィールドを示します。 timeフィールドは、datetime、timestamp、integer、float、decimalのデータ型をサポートしています。 時間フィールドの値が時系列で増加していることを確認します。
説明Log Serviceは、時間フィールドに基づいて増分データを取得します。 テーブルのこのフィールドにインデックスが設定されていることを確認します。 インデックスが設定されていない場合は、テーブル全体のスキャンが実行されます。 さらに、増分データのプルに失敗したことを示すエラーが報告されます。
deleted_flag_key
String
任意
変換する必要がなく、増分データがプルされたときに破棄されるデータ。 たとえば、update_time_key="key" のkeyの値が次の条件を満たす場合、値は削除されたデータとして解析されます。
ブール値: true
Datetimeとtimestamp: 空ではない
Charとvarchar: 1、true、t、yes、y
整数: 非ゼロ
説明deleted_flag_keyパラメーターとupdate_time_keyパラメーターを一緒に設定する必要があります。
update_time_keyパラメーターを設定し、deleted_flag_keyパラメーターを設定しない場合、増分データがプルされてもデータは破棄されません。
コネクター
String
任意
データベースにリモート接続するために使用されるコネクタ。 有効な値: mysqlとpgsql。 デフォルト値: mysql。
レスポンス
複数の列を含むテーブルが返されます。 列は、fields パラメーターで定義されます。
エラー処理
データのプル時にエラーが発生すると、エラーが報告されますが、データ変換ジョブは引き続き実行されます。 再試行は、base_retry_back_offパラメーターの値に基づいて実行されます。 たとえば、最初のリトライ間隔は1秒で、最初のリトライは失敗します。 第2の再試行間隔は、第1の再試行間隔の2倍である。 このプロセスは、間隔がmax_retry_back_offパラメーターの値に達するまで続きます。 エラーが続く場合、max_retry_back_offパラメーターの値に基づいて再試行が実行されます。 リトライが成功した場合、リトライ間隔は初期値である1秒にリセットされます。
例
すべてのデータをプル
例1: test_dbデータベースのtest_tableテーブルから300秒間隔でデータを取得します。
res_rds_mysql( address="rm-uf6wjk5****mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, )例2: status値がdeleteであるデータレコードを除いて、test_tableテーブルからデータをプルします。
res_rds_mysql( address="rm-uf6wjk5****mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, fetch_exclude_data="'status':'delete'", )例3: status値がexitであるデータレコードをtest_tableテーブルからプルします。
res_rds_mysql( address="rm-uf6wjk5***mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, fetch_include_data="'status':'exit'", )例4: status値がexitのデータレコードをtest_tableテーブルからプルします。ただし、name値がaliyunのデータレコードは除きます。
res_rds_mysql( address="rm-uf6wjk5***mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, fetch_include_data="'status':'exit'", fetch_exclude_data="'name':'aliyun'", )例5: pgsqlコネクタを使用してHologresデータベースに接続し、test_tableテーブルからデータをプルします。
res_rds_mysql( address="hgpostcn-cn-****-cn-hangzhou.hologres.aliyuncs.com:80", username="test_username", password="****", database="aliyun", table="test_table", connector="pgsql", )例6: primary_keysパラメーターを使用してデータをプルします。
primery_keysパラメーターを設定すると、その値がキーとして抽出されます。 テーブルから取り出されたデータは、{"10001":{"userid":"10001" 、"city_name":"beijing" 、"city_number":"12345"}}} の形式でメモリに保存されます。 この場合、データは高速に引き抜かれる。 大量のデータを取得する場合は、この方法を使用することをお勧めします。 primary_keysパラメーターを設定しない場合、関数は行ごとにテーブルをトラバースします。 次に、関数はデータをプルし、[{"userid":"10001","city_name":"beijing","city_number":"12345"}] 形式でデータをメモリに保存します。 この場合、データは低速でプルされますが、メモリのごく一部しか占有されません。 少量のデータを取得する場合は、この方法を使用することをお勧めします。
テーブル
userid
city_name
city_number
10001
beijing
12345
生ログ
# Data Record 1 userid:10001 gdp:1000 # Data Record 2 userid:10002 gdp:800変換ルール
e_table_map( res_rds_mysql( address="rm-uf6wjk5***mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", primary_keys="userid", ), "userid", ["city_name", "city_number"], )結果
# Data Record 1 userid:10001 gdp:1000 city_name: beijing city_number:12345 # Data Record 2 userid:10002 gdp:800
増分データのプルPull incremental data
例1: 増分データをプルします。
説明次の条件を満たす場合にのみ、テーブルから増分データを取得できます。
テーブルには、一意の主キーと、iteme_idフィールドやupdate_timeフィールドなどの時間フィールドがあります。
primary_keys、refresh_interval、およびupdate_time_keyパラメーターが設定されます。
テーブル
iteme_id
item_name
価格
1001
オレンジ
10
1002
Apple
12
1003
マンゴー
16
生ログ
# Data Record 1 item_id: 1001 total: 100 # Data Record 2 item_id: 1002 total: 200 # Data Record 3 item_id: 1003 total: 300変換ルール
e_table_map( res_rds_mysql( address="rm-uf6wjk5***mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", primary_key="item_id", refresh_interval=1, update_time_key="update_time", ), "item_id", ["item_name", "price"], )結果
# Data Record 1 item_id: 1001 total: 100 item_name: Orange price:10 # Data Record 2 item_id: 1002 total: 200 item_name: Apple price:12 # Data Record 3 item_id: 1003 total: 300 item_name: Mango price:16
例2: 増分データがプルされたときに指定されたデータを破棄するようにdeleted_flag_keyパラメーターを設定します。
テーブル
iteme_id
item_name
価格
update_time
Is_deleted
1001
オレンジ
10
1603856138
False
1002
Apple
12
1603856140
False
1003
マンゴー
16
1603856150
False
生ログ
# Data Record 1 item_id: 1001 total: 100 # Data Record 2 item_id: 1002 total: 200 # Data Record 3 item_id: 1003 total: 300変換ルール
e_table_map( res_rds_mysql( address="rm-uf6wjk5***mo.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", primary_key="item_id", refresh_interval=1, update_time_key="update_time", deleted_flag_key="is_deleted", ), "item_id", ["item_name", "price"], )結果
res_rds_mysq関数は、テーブルからLog Serviceが実行されているサーバーのメモリに3つのデータレコードをプルします。 これらのデータレコードは、ソースLogstore内の既存のデータレコードと比較され、レコードが一致するかどうかが確認されます。 item_idが1001のデータレコードを破棄する場合は、テーブルでitem_idが1001のデータレコードを見つけ、is_deletedフィールドの値をtrueに変更します。 このように、データレコード1001は、インメモリ次元テーブルが次回更新されるときに破棄される。
# Data Record 2 item_id: 1002 total: 200 item_name: Apple price:12 # Data Record 3 item_id: 1003 total: 300 item_name: Mango price:1
関連ドキュメント
この関数は、他の関数と一緒に使用できます。 詳細については、「Simple Log Serviceを使用してApsaraDB RDS For MySQLインスタンスに接続し、データを強化する」をご参照ください。
res_log_logstore_pull
Logstore内のデータを変換するときに、res_log_logstore_pull関数は別のLogstoreからデータをプルします。
構文
res_log_logstore_pull(endpoint, ak_id, ak_secret, project, logstore, fields, from_time="begin", to_time=None, fetch_include_data=None, fetch_exclude_data=None, primary_keys=None, fetch_interval=2, delete_data=None, base_retry_back_off=1, max_retry_back_off=60, ttl=None, role_arn=None)パラメーター
パラメーター
型
必須 / 任意
説明
endpoint
String
対象
エンドポイント。 詳細については、「エンドポイント」をご参照ください。 デフォルトでは、HTTPSエンドポイントが使用されます。 HTTPエンドポイントを使用することもできます。 特別な場合は、ポート80 443以外のポートを使用する必要があります。
ak_id
String
対象
Alibaba CloudアカウントのAccessKey ID。 データのセキュリティを確保するために、[詳細パラメーター設定] でこのパラメーターを設定することを推奨します。 高度なパラメーターを設定する方法の詳細については、「データ変換ジョブの作成」をご参照ください。
ak_secret
String
対象
Alibaba CloudアカウントのAccessKeyシークレット。 データのセキュリティを確保するために、[詳細パラメーター設定] でこのパラメーターを設定することを推奨します。 高度なパラメーターを設定する方法の詳細については、「データ変換ジョブの作成」をご参照ください。
project
String
対象
データをプルするプロジェクトの名前です。
logstore
String
対象
データをプルするLogstoreの名前。
fields
String list
対象
文字列リストまたは文字列エイリアスリストです。 ログに指定されたフィールドが含まれていない場合、このフィールドの値は空の文字列です。 たとえば、名前を変更する場合は、名前の列["user_id", "province", "city", "name", "age"]リストにuser_nameこのパラメーターを["user_id", "province", "city", ("name", "user_name"), ("nick_name"), "age"].
from_time
String
任意
Logstoreからの最初のデータのプルが開始されるサーバー時刻。 デフォルト値: begin。 この値は、Log Serviceが最初のログからデータのプルを開始することを示します。 以下の時間フォーマットをサポートしています。
UNIXタイムスタンプ。
時間文字列。
beginやendなどのカスタム文字列。
式: dt_関数によって返される時間。 たとえば、関数dt_totimestamp(dt_truncate(dt_today(tz="Asia/Shanghai"), day=op_neg(-1))) は、現在時刻の1日前のデータプルの開始時刻を返します。 現在の時刻が2019-5-5 10:10:10 (UTC + 8) の場合、返される時刻は2019-5-4 10:10:10 (UTC + 8) です。
to_time
String
任意
Logstoreからの最初のデータのプルが終了したサーバー時刻。 デフォルト値: None。 この値は、Log Serviceが最後のログでデータのプルを停止することを示します。 以下の時間フォーマットをサポートしています。
UNIXタイムスタンプ。
時間文字列。
beginやendなどのカスタム文字列。
式: dt_関数によって返される時間。
このパラメーターを設定しないか、このパラメーターをNoneに設定すると、最新のログからデータが継続的に取得されます。
説明このパラメーターを現在の時刻より後の時点に設定すると、Logstore内の既存のデータのみがプルされます。 新しいデータはプルされません。
fetch_include_data
String
任意
フィールドのホワイトリスト。 フィールドがfetch_include_dataパラメーターと一致するログは保持されます。 フィールドがこのパラメーターと一致しないログは破棄されます。
このパラメーターを設定しないか、このパラメーターを [なし] に設定すると、フィールドホワイトリスト機能は無効になります。
このパラメーターを特定のフィールドとフィールド値に設定すると、フィールドとフィールド値を含むログが保持されます。
fetch_exclude_data
String
任意
フィールドのブラックリスト。 フィールドがfetch_exclude_dataパラメーターと一致するログは破棄されます。 フィールドがこのパラメーターと一致しないログは保持されます。
このパラメーターを設定しないか、このパラメーターを [なし] に設定すると、フィールドブラックリスト機能は無効になります。
このパラメーターを特定のフィールドとフィールド値に設定すると、フィールドとフィールド値を含むログは破棄されます。
説明ブラックリストとホワイトリストの両方のパラメーターを設定した場合、フィールドがブラックリストパラメーターと一致するログは最初に破棄され、フィールドがホワイトリストパラメーターと一致する残りのログは保持されます。
primary_keys
String list
非対象
テーブルを維持するために使用される主キーフィールドのリスト。 fieldsパラメーターを使用して主キーフィールドの名前を変更する場合は、新しい名前を使用してこのパラメーターの主キーフィールドを指定する必要があります。
説明primary_keysパラメーターの値には、fieldsパラメーターの値で指定されている単一値の文字列のみを含めることができます。
このパラメーターは、データのプル元であるLogstoreにシャードが1つしか存在しない場合に有効です。
primery_keysパラメーターを設定する必要があります。 そうしないと、パフォーマンスが大きく影響し、タスクの遅延が発生する可能性があります。
primery_keysパラメーターの値は大文字と小文字が区別されます。
fetch_interval
Int
非対象
データが連続的にプルされる場合の2つの連続するデータプル要求の間隔。 デフォルト値:2 単位は秒です。 値は 1 秒以上でなければなりません。
delete_data
String
任意
テーブルからデータを削除する操作。 指定された条件を満たし、
primary_keysの値を含むデータレコードは削除されます。 詳細については、「クエリ文字列構文」をご参照ください。base_retry_back_off
Number
非対象
プル失敗後にシステムがデータを再度プルしようとする間隔。 デフォルト値:1 単位は秒です。
max_retry_back_off
Int
非対象
プル失敗後の2つの連続した再試行間の最大間隔。 デフォルト値: 60。 単位は秒です。 デフォルト値を使用することを推奨します。
ttl
Int
非対象
連続的にデータを取得する範囲を決定するために使用される秒数。 データプルは、ログデータが生成されたときに開始され、ログデータが生成された時間のttl秒後に終了します。 単位は秒です。 デフォルト値 : なし。 この値は、すべてのログデータがプルされることを示します。
role_arn
String
任意
使用されるRAMロールのAlibaba Cloudリソース名 (ARN) 。 RAMロールには、データのプル元のLogstoreに対する読み取り権限が必要です。 RAMコンソールで、ロールの詳細ページの基本情報セクションでRAMロールのARNを表示できます。 例:
acs:ram::1379 ****** 44:role/role-aRAMロールのARNを取得する方法の詳細については、「RAMロールに関する情報の表示」をご参照ください。レスポンス
複数の列を含むテーブルが返されます。
エラー処理
データのプル時にエラーが発生すると、エラーが報告されますが、データ変換ジョブは引き続き実行されます。 再試行は、base_retry_back_offパラメーターの値に基づいて実行されます。 たとえば、最初のリトライ間隔は1秒で、最初のリトライは失敗します。 第2の再試行間隔は、第1の再試行間隔の2倍である。 このプロセスは、間隔がmax_retry_back_offパラメーターの値に達するまで続きます。 エラーが続く場合、max_retry_back_offパラメーターの値に基づいて再試行が実行されます。 リトライが成功した場合、リトライ間隔は初期値である1秒にリセットされます。
例
この例では、フィールドkey1とkey2のデータは、test_projectプロジェクトのtest_logstore Logstoreから取得されます。 ログデータがLogstoreに書き込まれると、データプルが開始されます。 データ書き込み動作が完了すると、データプルは終了する。 データは1回だけプルされます。
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time="end", )この例では、フィールドkey1とkey2のデータは、test_projectプロジェクトのtest_logstore Logstoreから取得されます。 ログデータがLogstoreに書き込まれると、データプルが開始されます。 データ書き込み動作が完了すると、データプルは終了する。 データは30秒間隔で連続的に引き出される。
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time=None, fetch_interval=30, )この例では、Logstoreからデータを取得するときに、key1:value1を含むデータレコードをスキップするようにブラックリストが設定されています。
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time=None, fetch_interval=30, fetch_exclude_data="key1:value1", )この例では、ホワイトリストは、Logstoreからkey1:value1を含むデータレコードを取得するように設定されています。
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time=None, fetch_interval=30, fetch_include_data="key1:value1", )この例では、フィールドkey1とkey2のデータは、test_projectプロジェクトのtest_logstore Logstoreから取得されます。 データプルは、ログデータが生成されたときに開始され、ログデータが生成されてから40,000,000秒後に終了します。
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LTAI*****Cajvr", "qO0Tp*****jJ9", "test_project", "test_logstore", fields=["key1","key2"], ttl="40000000" )この例では、フィールドkey1とkey2のデータは、project-test1プロジェクトのtest-logstore Logstoreから取得されます。 Log serviceのサービスにリンクされたロールが権限付与に使用されます。 ログデータがLogstoreに書き込まれると、データプルが開始されます。 データ書き込み動作が完了すると、データプルは終了する。 データは1回だけプルされます。
res_log_logstore_pull( "pub-cn-hangzhou-staging-intranet.log.aliyuncs.com", "", "", "project-test1", "test-logstore", ["key1", "key2"], from_time="2022-7-27 10:10:10 8:00", to_time="2022-7-27 14:30:10 8:00", role_arn="acs:ram::***:role/aliyunserviceroleforslsaudit", )この例では、フィールドkey1とkey2のデータは、project-test1プロジェクトのtest-logstore Logstoreから取得されます。 デフォルトのロールが権限付与に使用されます。 ログデータがLogstoreに書き込まれると、データプルが開始されます。 データ書き込み動作が完了すると、データプルは終了する。 データは1回だけプルされます。
res_log_logstore_pull( "cn-chengdu.log.aliyuncs.com", "", "", "project-test1", "test-logstore", ["key1", "key2"], from_time="2022-7-21 10:10:10 8:00", to_time="2022-7-21 10:30:10 8:00", role_arn="acs:ram::***:role/aliyunlogetlrole", )
関連ドキュメント
この関数は、他の関数と一緒に使用できます。 詳細については、「あるログストアからデータをプルして別のログストアのログデータを強化する」をご参照ください。
res_oss_file
res_oss_file関数は、指定されたOSSバケット内のオブジェクトからデータを取得します。 データは定期的に更新できます。
OSSバケットと同じリージョンにあるLog Serviceプロジェクトを使用することを推奨します。 これにより、バケット内のオブジェクトデータをAlibaba Cloudの内部ネットワーク経由でプルできます。 内部ネットワークは安定しており高速です。
構文
res_oss_file(endpoint, ak_id, ak_key, bucket, file, format='text', change_detect_interval=0, base_retry_back_off=1, max_retry_back_off=60, encoding='utf8', error='ignore')パラメーター
パラメーター
型
必須 / 任意
説明
endpoint
String
対象
OSSバケットのエンドポイント。 詳細は、「リージョンとエンドポイント」をご参照ください。 デフォルトでは、HTTPSエンドポイントが使用されます。 HTTPエンドポイントを使用することもできます。 特別な場合は、ポート80 443以外のポートを使用する必要があります。
ak_id
String
対象
Alibaba CloudアカウントのAccessKey ID。 データのセキュリティを確保するために、[詳細パラメーター設定] でこのパラメーターを設定することを推奨します。 高度なパラメーターを設定する方法の詳細については、「データ変換ジョブの作成」をご参照ください。
ak_key
String
対象
Alibaba CloudアカウントのAccessKeyシークレット。 データのセキュリティを確保するために、[詳細パラメーター設定] でこのパラメーターを設定することを推奨します。 高度なパラメーターを設定する方法の詳細については、「データ変換ジョブの作成」をご参照ください。
バケット
String
対象
データをプルするOSSバケットの名前。
file
String
対象
データをプルするオブジェクトへのパス。 例: test/data.txt パスの先頭にスラッシュ (/) を入力しないでください。
フォーマット
String
対象
出力ファイルの形式です。 有効な値:
テキスト: テキスト形式
バイナリ: バイトストリーム形式
change_detect_interval
String
任意
Log ServiceがOSSからオブジェクトデータを取得する間隔。 単位は秒です。 システムは、データがプルされたときにオブジェクトが更新されるかどうかをチェックします。 オブジェクトが更新されると、増分データがプルされます。 デフォルト値:0 この値は、増分データがプルされないことを示します。 関数が呼び出されると、すべてのデータが1回だけプルされます。
base_retry_back_off
Number
非対象
プル失敗後にシステムがデータを再度プルしようとする間隔。 デフォルト値:1 単位は秒です。
max_retry_back_off
Int
非対象
プル失敗後の2つの連続した再試行間の最大間隔。 デフォルト値: 60。 単位は秒です。 デフォルト値を使用することを推奨します。
encoding
String
任意
エンコード形式。 formatパラメーターをTextに設定すると、このパラメーターは自動的にutf8に設定されます。
error
String
任意
エラーを処理するために使用されるメソッド。 このパラメーターは、UnicodeErrorメッセージが報告された場合にのみ有効です。 有効な値:
ignore: 無効な形式のデータをスキップし、データのエンコードを続行します。
xmlcharrefreplace: 適切なXML文字参照を使用して、エンコードできない文字を置き換えます。
詳細については、「エラーハンドラ」をご参照ください。
解凍
String
任意
オブジェクトを解凍するかどうかを指定します。 有効な値:
なし: オブジェクトは解凍されません。 デフォルト値です。
gzip: オブジェクトはgzipを使用して解凍されます。
レスポンス
オブジェクトデータは、バイトストリームまたはテキスト形式で返されます。
エラー処理
データのプル時にエラーが発生すると、エラーが報告されますが、データ変換ジョブは引き続き実行されます。 再試行は、base_retry_back_offパラメーターの値に基づいて実行されます。 たとえば、最初のリトライ間隔は1秒で、最初のリトライは失敗します。 第2の再試行間隔は、第1の再試行間隔の2倍である。 このプロセスは、間隔がmax_retry_back_offパラメーターの値に達するまで続きます。 エラーが続く場合、max_retry_back_offパラメーターの値に基づいて再試行が実行されます。 リトライが成功した場合、リトライ間隔は初期値である1秒にリセットされます。
例
例1: OSSからJSONデータをプルします。
JSON データ
{ "users": [ { "name": "user1", "login_historys": [ { "date": "2019-10-10 0:0:0", "login_ip": "203.0.113.10" }, { "date": "2019-10-10 1:0:0", "login_ip": "203.0.113.10" } ] }, { "name": "user2", "login_historys": [ { "date": "2019-10-11 0:0:0", "login_ip": "203.0.113.20" }, { "date": "2019-10-11 1:0:0", "login_ip": "203.0.113.30" }, { "date": "2019-10-11 1:1:0", "login_ip": "203.0.113.50" } ] } ] }生ログ
content: 123変換ルール
e_set( "json_parse", json_parse( res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", ak_id="LT****Gw", ak_key="ab****uu", bucket="log-etl-staging", file="testjson.json", ) ), )結果
content: 123 prjson_parse: '{ "users": [ { "name": "user1", "login_historys": [ { "date": "2019-10-10 0:0:0", "login_ip": "203.0.113.10" }, { "date": "2019-10-10 1:0:0", "login_ip": "203.0.113.10" } ] }, { "name": "user2", "login_historys": [ { "date": "2019-10-11 0:0:0", "login_ip": "203.0.113.20" }, { "date": "2019-10-11 1:0:0", "login_ip": "203.0.113.30" }, { "date": "2019-10-11 1:1:0", "login_ip": "203.0.113.50" } ] } ] }'
例2: OSSからテキストコンテンツをプルします。
テキストコンテンツ
Test bytes生ログ
content: 123変換ルール
e_set( "test_txt", res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", ak_id="LT****Gw", ak_key="ab****uu", bucket="log-etl-staging", file="test.txt", ), )結果
content: 123 test_txt: Test bytes
例3: 圧縮されたOSSオブジェクトからデータを引き出し、オブジェクトを解凍します。
圧縮オブジェクトの内容
Test bytes\nupdate\n123生ログ
content:123変換ルール
e_set( "text", res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", ak_id="LT****Gw", ak_key="ab****uu", bucket="log-etl-staging", file="test.txt.gz", format="binary", change_detect_interval=30, decompress="gzip", ), )結果
content:123 text: Test bytes\nupdate\n123
例4: ACLがpublic-read-writeであるOSSバケット内のオブジェクトにアクセスします。 AccessKeyペアは使用されません。
圧縮オブジェクトの内容
Test bytes生ログ
content:123変換ルール
e_set( "test_txt", res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", bucket="log-etl-staging", file="test.txt", ), )結果
content: 123 test_txt: Test bytes
関連ドキュメント
この関数は、他の関数と一緒に使用できます。 詳細については、「OSSからCSVファイルをプルしてデータを強化する」をご参照ください。