このトピックでは、 でブルームフィルターインデックスを使用する際の注意事項と関連操作について説明します。 ApsaraDB for SelectDB。
機能の説明
1970 年に Burton Howard Bloom によって考案されたブルームフィルターは、複数のハッシュ関数のマッピングに基づく確率的データ構造です。これは、要素がセットに属しているかどうかを確認するために使用されます。
シナリオ: ブルームフィルターは、
IN演算子と=演算子向けに設計されています。これは、大量の無関係なデータを除外するのに役立ちます。特徴:
省スペースのデータ構造: 非常に長いバイナリビット配列と一連のハッシュ関数で構成されます。
確率的結果: ブルームフィルターは、要素がセットに属しているかどうかを確認するときに、次のタイプの結果を返します。
true: 要素はセットに属している可能性があります。誤判定の可能性があります。
false: 要素はセットに属していません。
実装:
ブルームフィルターは、非常に長いバイナリビット配列と一連のハッシュ関数で構成されます。 最初は、バイナリビット配列のすべてのビットが 0 に設定されています。クエリ対象の要素が指定されている場合、その要素はハッシュ関数を使用して計算され、一連のビットにマッピングされます。すべてのビットのオフセットは、ビット配列で 1 に設定されます。
次の図は、m が 18、k が 3 に設定されているブルームフィルターの例を示しています。m はビット配列のサイズを示し、k はハッシュ関数の数を示します。セット内の x、y、z の要素は、3 つの異なるハッシュ関数を使用してビット配列にハッシュされます。要素 w がクエリされると、要素 w はハッシュ関数によって計算されます。1 つのビットが 0 であるため、結果が返され、要素 w がセットに属していないことが示されます。
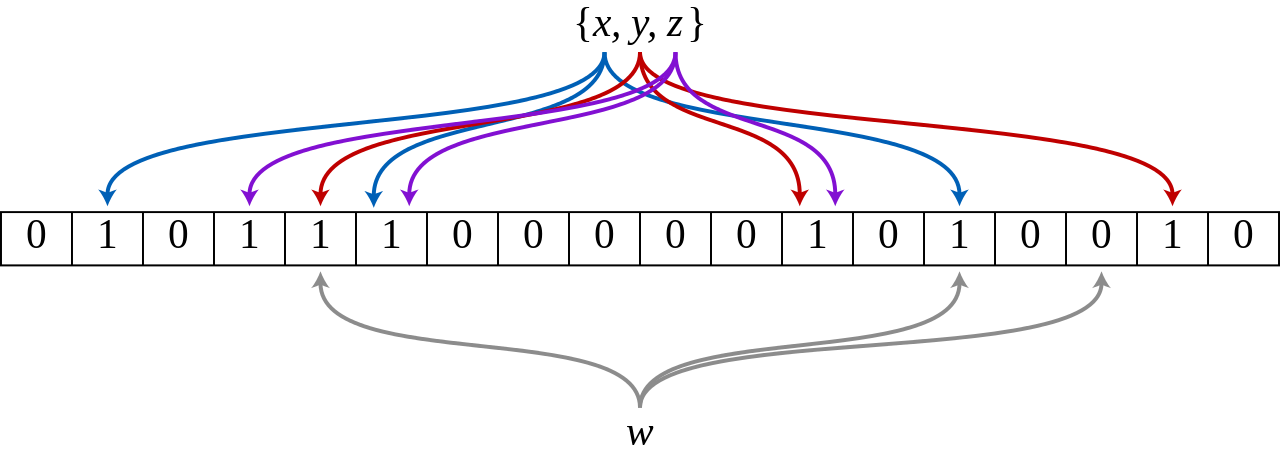
ハッシュ関数によって計算されたオフセットに基づいて、要素がセットに属しているかどうかを確認できます。すべてのオフセットが 1 の場合、要素はセットに属しています。オフセットのいずれかが 1 でない場合、要素はセットに属していません。
使用上の注意
TINYINT、FLOAT、または DOUBLE データ型の列にブルームフィルターインデックスを作成することはできません。
ブルームフィルターインデックスは、 演算子と 演算子によって指定されたフィルター条件を含むクエリのみを高速化します。
でおよび=オペレーター。クエリがブルームフィルターインデックスと一致するかどうかを確認するには、クエリのプロファイル情報を表示します。
インデックスの作成
ブルームフィルターインデックスは、ブロックに基づいて作成されます。各ブロックでは、列の値がセットとして使用され、ブルームフィルターインデックスが生成されます。
ApsaraDB for SelectDBでは、テーブルの作成時またはテーブルに対する ALTER 操作の実行時に、ブルームフィルターインデックスを指定できます。
テーブルの作成時にインデックスを作成する
テーブル作成時に Bloom フィルターインデックスを作成する場合、テーブル作成ステートメントの PROPERTIES に "bloom_filter_columns"="k1,k2,k3" 設定を追加できます。この例では、k1,k2,k3 は、Bloom フィルターインデックスを作成するキー列の名前を示しています。
次のサンプルコードは、 テーブルに と のブルームフィルターインデックスを作成する方法の例を示しています。 saler_idcategory_id の sale_detail_bloom テーブル。
CREATE TABLE IF NOT EXISTS sale_detail_bloom(
sale_date date NOT NULL COMMENT "販売日",
customer_id int NOT NULL COMMENT "顧客 ID",
saler_id int NOT NULL COMMENT "販売者 ID",
sku_id int NOT NULL COMMENT "商品 ID",
category_id int NOT NULL COMMENT "商品が属するカテゴリ ID",
sale_count int NOT NULL COMMENT "販売数量",
sale_price DECIMAL(12,2) NOT NULL COMMENT "商品単価",
sale_amt DECIMAL(20,2) COMMENT "総売上高"
)
Duplicate KEY(sale_date, customer_id, saler_id, sku_id, category_id)
distributed BY hash(customer_id) buckets 3
PROPERTIES("bloom_filter_columns"="saler_id, category_id");既存のテーブルにインデックスを作成する
既存のテーブルの bloom_filter_columns パラメーターを変更するには、次のステートメントを実行して、既存のテーブルにインデックスを作成します。
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "k1,k3");インデックスを表示する
テーブルに作成されたブルームフィルターインデックスを表示するには、次のステートメントを実行します。
SHOW CREATE TABLE <table_name>;sale_detail_bloom テーブルに作成されたブルームフィルターインデックスをクエリする方法の例を次に示します。
SHOW CREATE TABLE sale_detail_bloom;次の結果が返されます。
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| sale_detail_bloom | CREATE TABLE `sale_detail_bloom` (
`sale_date` datev2 NOT NULL COMMENT '販売日',
`customer_id` int(11) NOT NULL COMMENT '顧客 ID',
`saler_id` int(11) NOT NULL COMMENT '販売者 ID',
`sku_id` int(11) NOT NULL COMMENT '商品 ID',
`category_id` int(11) NOT NULL COMMENT '商品が属するカテゴリ ID',
`sale_count` int(11) NOT NULL COMMENT '販売数量',
`sale_price` decimalv3(12, 2) NOT NULL COMMENT '商品単価',
`sale_amt` decimalv3(20, 2) NULL COMMENT '総売上高'
) ENGINE=OLAP
DUPLICATE KEY(`sale_date`, `customer_id`, `saler_id`, `sku_id`, `category_id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`customer_id`) BUCKETS 3
PROPERTIES (
"bloom_filter_columns" = "category_id, saler_id",
"light_schema_change" = "true"
); |
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)インデックスの削除
ブルームフィルターインデックスを削除するには、次のステートメントを実行します。削除中に、インデックス列の bloom_filter_columns パラメーターが削除されます。
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "");インデックス変更の進捗状況のクエリ
インデックスの作成、変更、および削除は非同期です。インデックス変更の進捗状況を表示するには、次のステートメントを実行します。
SHOW ALTER TABLE COLUMN;ベストプラクティス
次の条件が満たされている場合、列にブルームフィルターインデックスを作成できます。
データはプレフィックスに基づいてフィルタリングされません。
クエリ対象のデータは、列に基づいて頻繁にフィルタリングされ、ほとんどのフィルター条件には
inと=が含まれます。ビットマップインデックスとは異なり、ブルームフィルターインデックスは、ユーザー ID を格納する列など、カーディナリティの高い列に適しています。これは、ユーザーの性別を格納する列など、カーディナリティの低い列にブルームフィルターインデックスを作成すると、各ブロックにほぼすべての値が含まれるためです。この場合、ブルームフィルターインデックスはクエリのパフォーマンスを向上させません。
例
長さが 100 バイトの短い行をクエリする場合、サイズは 64 KB の HFile データブロックには、(64 × 1,024)/100 = 655.53 行、つまり約 700 行が含まれます。ブルームフィルターインデックスをデータブロックの最初の行キーにのみ作成できる場合、ブルームフィルターインデックスは詳細なインデックス情報を提供できません。これは、クエリ対象の行データがデータブロックの行範囲に属している可能性がある、行データがデータブロックに属していない可能性がある、行データがテーブルに存在しない可能性がある、または行データが別の HFile データブロックに属しているか、Memstore に格納されている可能性があるためです。前述の場合、ディスクからデータブロックを読み取るときに追加の I/O オーバーヘッドが必要になり、データブロックのキャッシュが乱用されます。大きなデータセットを高並列で読み取ると、クラスタのパフォーマンスが深刻な影響を受けます。
したがって、HBase はブルームフィルターを提供します。これにより、各データブロックに格納されているデータに対して逆テストを実行できます。行へのアクセスをリクエストすると、ブルームフィルターはまず、行がデータブロックに属しているかどうかを確認します。ブルームフィルターは、行がデータブロックに属していない、または行がデータブロックに属しているかどうかがわからないという結果を返します。これは逆テストと呼ばれます。ブルームフィルターは行内のセルにも適用され、列識別子にアクセスするときに同じ逆テストを使用できます。
ただし、ブルームフィルターにはコストがかかります。ブルームフィルターインデックスは追加のストレージスペースを占有します。ブルームフィルターの数は、インデックスオブジェクトが増加するにつれて増加します。したがって、行レベルのブルームフィルターは、列識別子レベルのブルームフィルターよりもストレージスペースを占有しません。ストレージスペースが十分であれば、ブルームフィルターはシステムの潜在的なパフォーマンスを活用するのに役立ちます。
ApsaraDB for SelectDB では、テーブルの作成時、またはテーブルに対する ALTER 操作の実行時に、ブルームフィルターインデックスを指定できます。
ブルームフィルターインデックスは、ブロックに基づいて作成することもできます。各ブロックでは、指定された列の値がセットとして使用され、ブルームフィルターインデックスカタログが生成されます。これは、クエリ中に条件を満たさないデータをすばやくフィルタリングするために使用されます。