SchedulerX を使用してジョブをスケジュールできます。たとえば、スケジュールされた時間にジョブをトリガーしたり、ジョブを調整するワークフローを作成したり、ジョブの出力を更新したりできます。SchedulerX は、Java、Python、Shell、および Go のシャーディングモデルも提供しており、ビッグデータコンピューティングに関連するビジネスをサポートします。
背景情報
シャーディングモデルには、静的シャーディングモデルと動的シャーディングモデルがあります。
静的シャーディング: このモデルは、固定数のシャードを処理するのに適しています。たとえば、分散コンピューティングシナリオで複数のワーカー上のテーブルシャーディングジョブで 1,024 個のテーブルを処理する場合に、このモデルを使用できます。
動的シャーディング: このモデルは、分散コンピューティングシナリオで量が不明なデータを処理するのに適しています。たとえば、継続的に更新される大きなテーブルがあり、そのテーブルをバッチで処理する場合に、このモデルを使用できます。SchedulerX によって提供される MapReduce モデルは、主流のフレームワークであり、オープンソースではありません。
機能
シャーディングモデルには、次の機能があります。
静的シャーディングモデルは elastic-job と互換性があります。
シャーディングモデルは、Java、Python、Shell、および Go をサポートしています。
高可用性: シャーディングモデルは MapReduce モデルに基づいて開発されており、高可用性も確保できます。ワーカーでエラーが発生した場合、マスターワーカーはシャードを別のワーカーに自動的にフェイルオーバーします。
トラフィック調整: シャーディングモデルは MapReduce モデルに基づいて開発されており、トラフィック調整もサポートしています。この機能を使用すると、単一ワーカーでのタスクの同時実行性を制御できます。たとえば、1,000 個のシャードと 10 個のワーカーがあるとします。各ワーカーが最大 5 つのシャードを並列で実行するように構成できます。残りのシャードはキューで待機する必要があります。
自動再シャーディング: シャーディングモデルは MapReduce モデルに基づいて開発されており、自動再シャーディングもサポートしています。この機能は、失敗したタスクを自動的に再実行するために使用されます。
ジョブの作成時に、ジョブの高度な設定で高可用性とトラフィック調整機能を構成できます。詳細については、「ジョブ管理」トピックのジョブの作成セクションとジョブ管理の高度なパラメーターをご参照ください。
バージョン 1.1.0 以降のエージェントのみが、多言語シャーディングモデルをサポートしています。
Java シャーディングジョブの作成
SchedulerX コンソール にログオンします。
上部のナビゲーションバーで、リージョンを選択します。
左側のナビゲーションペインで、[タスク管理] をクリックします。
[ジョブ] ページで、ジョブを作成する名前空間を [名前空間が属する名前空間] ドロップダウンリストから選択し、[タスクの作成] をクリックします。
基本構成[タスクの作成] ウィザードの 実行モードシャード実行シャーディング パラメーター次の手順 ステップで、 パラメーターを に設定し、 を指定します。次に、 をクリックします。
複数のシャーディングパラメーターはコンマ (,) で区切るか、各行に 1 つのシャーディングパラメーターのみを指定します。例:
Shard index 1=Shard parameter 1,Shard index 2=Shard parameter 2,...。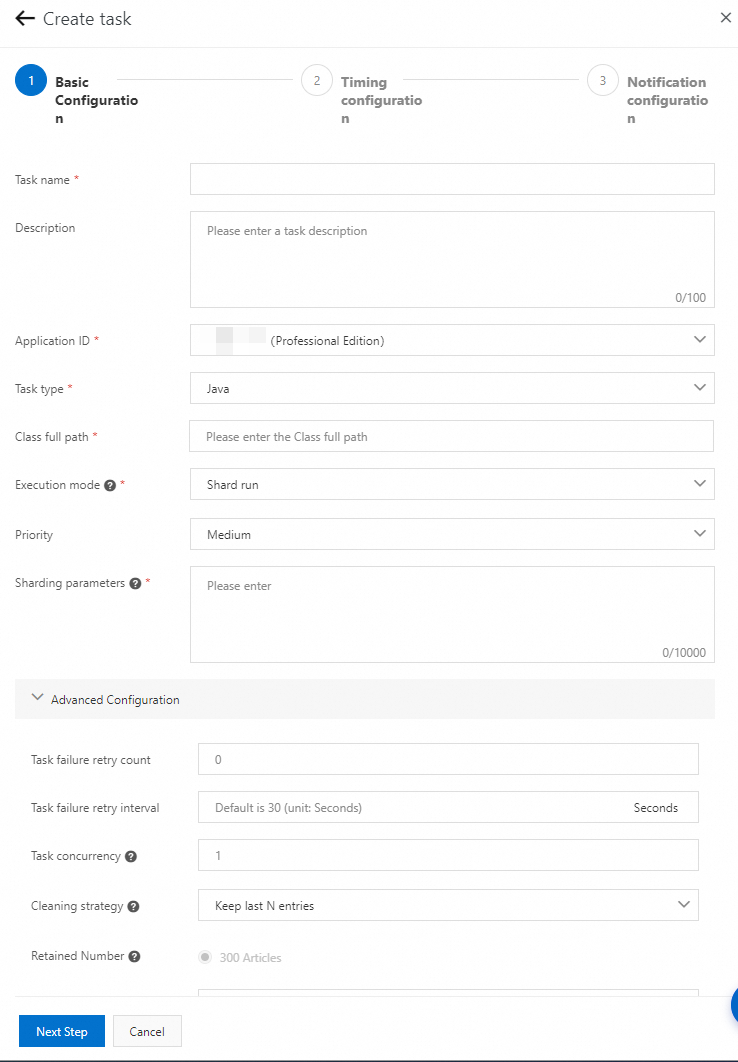
アプリケーションコードで
JavaProcessorを継承し、JobContext.getShardingId()を使用してシャードインデックスを取得し、JobContext.getShardingParameter()を使用して対応するシャーディングパラメーターを取得します。サンプルコード:
@Component public class HelloWorldProcessor extends JavaProcessor { @Override public ProcessResult process(JobContext context) throws Exception { // シャードインデックスとシャーディングパラメーターを出力します。 System.out.println("Shard index=" + context.getShardingId() + ", Shard parameter=" + context.getShardingParameter()); return new ProcessResult(true); } }[インスタンス] ページで、表示するジョブを見つけて、詳細[操作] 列の をクリックします。
Python シャーディングジョブの作成
Python アプリケーションを構成して分散バッチ処理を実行する場合、SchedulerX エージェントをインストールするだけで済みます。SchedulerX を使用してスクリプトを管理できます。
SchedulerX エージェントをダウンロードし、エージェントを使用してスクリプトジョブをデプロイします。
SchedulerX で Python シャーディングジョブを作成します。詳細については、「ジョブ管理」トピックの ジョブの作成 セクションをご参照ください。
sys.argv[1]はシャードインデックスを示し、sys.argv[2]はシャーディングパラメーターを示します。複数のシャーディングパラメーターはコンマ (,) で区切るか、各行に 1 つのシャーディングパラメーターのみを指定します。例:
Shard index 1=Shard parameter 1,Shard index 2=Shard parameter 2,...。[インスタンス] ページで、表示するジョブを見つけて、詳細[操作] 列の をクリックします。
Shell シャーディングジョブまたは Go シャーディングジョブの作成
Python シャーディングジョブを作成するのと同じような方法で、Shell シャーディングジョブまたは Go シャーディングジョブを作成できます。詳細については、このトピックの Python シャーディングジョブの作成 セクションをご参照ください。