高性能なキーバリューデータベースとして、Tair (Redis OSS-compatible) は、ビジネスにとって大量の重要なデータを保存するためによく利用されます。データセキュリティを確保するため、Tair (Redis OSS-compatible) はさまざまなディザスタリカバリソリューションを提供しています。
ディザスタリカバリアーキテクチャの進化
災害復旧メカニズムは、ハードウェアの故障やデータセンターの停電などの不測の事態によりインスタンスに障害が発生した場合でも、データ整合性とサービス可用性を確保します。
図 1. ディザスタリカバリアーキテクチャの進化
ディザスタリカバリソリューション | 保護レベル | 説明 |
★★★☆☆ | マスターノードとレプリカノードは、同一ゾーン内の異なるマシンにデプロイされます。ノードに障害が発生した場合、高可用性 (HA) システムが自動的にフェイルオーバーを実行し、単一障害点 (SPOF) によるサービス中断を防ぎます。 | |
★★★★☆ | マスターノードとレプリカノードは、同一リージョン内の 2 つの異なるゾーンにデプロイされます。停電やネットワーク障害などの要因でゾーンが利用できなくなった場合、HA システムがフェイルオーバーを実行し、インスタンスの可用性を確保します。 | |
★★★★★ | Redis グローバル分散キャッシュインスタンスは、専用チャネルを介してリアルタイムでデータを同期する複数のサブインスタンスで構成されます。チャネルマネージャーはサブインスタンスのヘルス状態を監視し、フェイルオーバーなどの例外を処理します。このソリューションは、ジオディザスタリカバリ、アクティブ地理的冗長性、ユーザーを最寄りのアプリケーションアクセスポイントにルーティングする、負荷分散などのシナリオに最適です。 |
シングルゾーン HA ソリューション
すべてのインスタンスアーキテクチャ は、シングルゾーン HA アーキテクチャをサポートしています。HA システムはマスターノードとレプリカノードのヘルス状態を監視し、自動的にフェイルオーバーを実行して SPOF によるサービス中断を防ぎます。
デプロイメントアーキテクチャ | 説明 |
図 2. 標準デュアルレプリカインスタンスの HA アーキテクチャ 標準アーキテクチャのインスタンスは、2 ノードのマスター/レプリカ構成を使用します。HA システムがマスターノードの障害を検出すると、自動的にフェイルオーバーを開始し、レプリカノードを新しいマスターノードに昇格させます。元のマスターノードが回復すると、新しいレプリカノードとして再接続されます。 | |
図 3. マルチレプリカクラスターインスタンスの HA アーキテクチャ マルチレプリカのクラスターアーキテクチャでは、データはデータシャードに保存されます。各データシャードは、高可用性を確保するために異なるマシンにデプロイされたノードを持つマルチレプリカ構成になっています。マスターノードに障害が発生した場合、システムは自動的にフェイルオーバーを実行してサービス可用性を維持します。 | |
図 4. 読み書き分離インスタンスの HA アーキテクチャ
|
マルチゾーンディザスタリカバリ
Tair (Redis OSS-compatible) は、複数のゾーンにまたがるゾーンディザスタリカバリアーキテクチャを提供します。ご利用のサービスが単一リージョンにデプロイされており、高レベルのディザスタリカバリが必要な場合は、インスタンス作成時にマルチゾーンオプションを選択できます。手順については、「インスタンスの作成」をご参照ください。
図 5. ゾーンディザスタリカバリインスタンスの作成
インスタンスが作成されると、プライマリインスタンスと同じ仕様のレプリカインスタンスがセカンダリゾーンに作成されます。データは、専用のレプリケーションチャネルを介してプライマリゾーンとセカンダリゾーン間で同期されます。
プライマリゾーンで停電やネットワーク障害が発生した場合、システムはレプリカインスタンスをマスターインスタンスに昇格させ、Config Server API を呼び出してプロキシのルーティング情報を更新します。さらに、Tair (Redis OSS-compatible) は Redis 同期メカニズムを最適化しています。MySQL の GTID 機能と同様に、Tair はグローバル Opid を使用して同期ポイントを管理します。ロックフリーのバックグラウンドスレッドが Opid のルックアップを実行し、AOF binlog はレート制限付きで非同期に送信されるため、Redis サービスのパフォーマンスが保証されます。
図 6. ゾーンディザスタリカバリインスタンスのデータ同期プロセス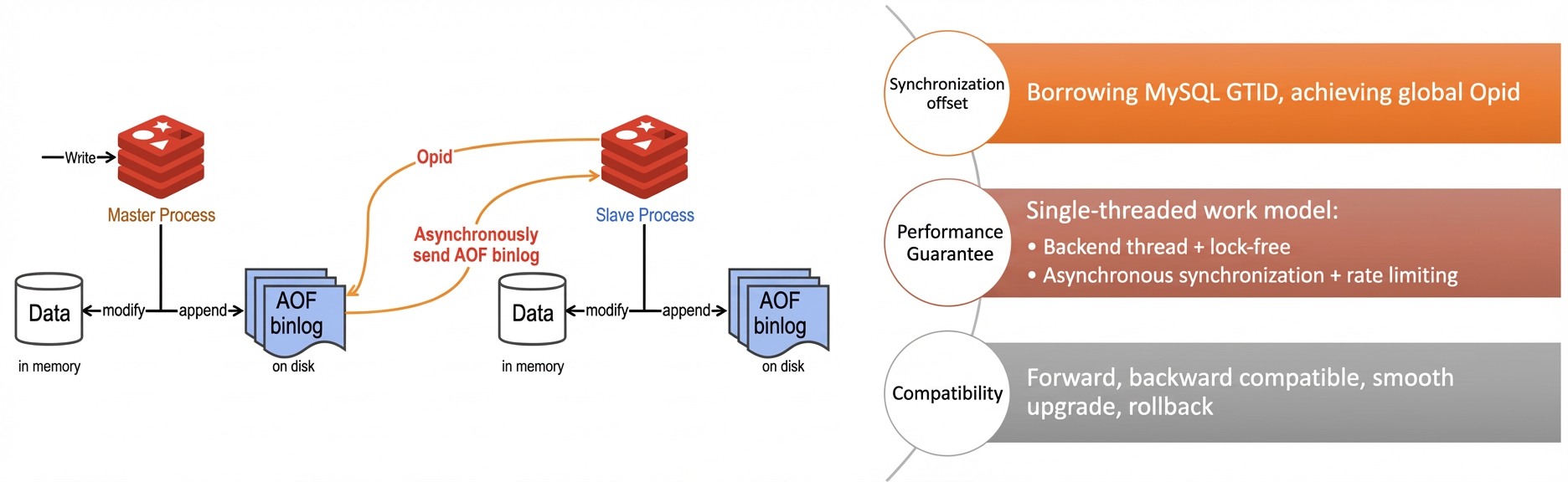
クロスリージョンディザスタリカバリ
ビジネスがグローバルに拡大するにつれて、クロスリージョンアクセスアーキテクチャは、高いレイテンシやユーザーエクスペリエンスの低下を招く可能性があります。Tair グローバル分散キャッシュ機能は、このクロスリージョンレイテンシを削減します。この機能には、次のような利点があります。
同期用のサブインスタンスを直接作成または指定できます。これにより、複雑なアプリケーションレベルの冗長性設計が不要になり、開発が大幅に簡素化され、コアビジネスロジックに集中できます。
ジオディザスタリカバリとアクティブ地理的冗長性を迅速に実装できます。
この機能は、マルチメディア、ゲーム、E コマースなどの業界におけるクロスリージョンデータ同期やグローバルデプロイメントに適しています。詳細については、「Redis グローバル分散キャッシュ」をご参照ください。
図 7. Tair グローバル分散キャッシュのアーキテクチャ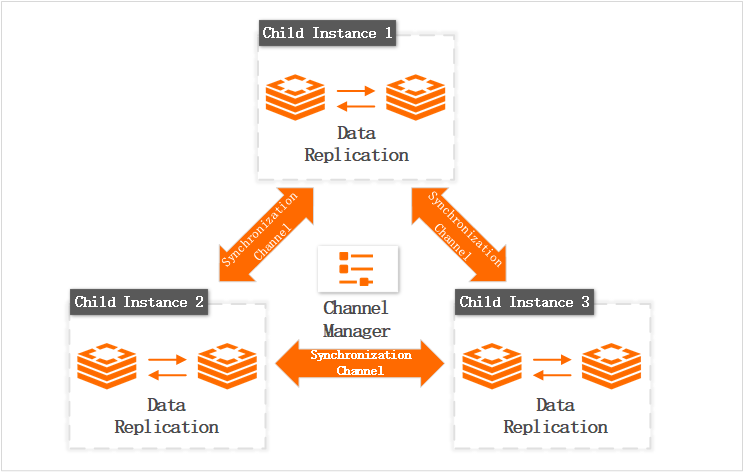
障害への対応
ハードウェアの故障、データセンターの停電、自然災害などの障害は、マスターノード障害またはゾーンレベルの障害に分類できます。まれではありますが、障害が発生すると、一時的にデータ書き込みが妨げられたり、一時的な接続の問題が発生したり、ダウンタイムやデータ損失につながる可能性があります。インスタンスの信頼性は、そのアーキテクチャと密接に関連しています。クラスターアーキテクチャは一般的に高い信頼性を提供します。障害の影響を最小限に抑えるため、マルチレプリカおよびマルチゾーンデプロイメントのインスタンスは自動的にフェイルオーバーを実行します。これにより、ダウンタイムが大幅に削減されます。以下のセクションでは、さまざまなディザスタリカバリソリューションを持つインスタンスが障害にどのように対応するかを説明します。
ノード障害への対応
マスターノードに障害が発生した場合:
インスタンスがシングルゾーンに複数のレプリカ (例えば、マスターノードとレプリカノード) を持つ場合:システムは、レプリケーションレイテンシが最も低いレプリカノードを新しいマスターノードに昇格させ、ルーティング情報を更新します。
インスタンスが複数のゾーンにまたがってデプロイされている場合:システムは別のゾーンのレプリカノードを新しいマスターノードに昇格させ、ルーティング情報を更新します。ただし、これにより、ご利用のインスタンスと他のサービスとの間でクロスゾーンアクセスが発生する可能性があります。
説明マルチゾーンのクラスターアーキテクチャでは、プライマリゾーンとセカンダリゾーンの両方にレプリカノードが存在する場合、フェイルオーバーは優先的にプライマリゾーンのレプリカノードを昇格させます。これにより、アプリケーションのクロスゾーンアクセスが回避されます。
ゾーンレベルの障害への対応
停電や火災など、データセンター全体が利用できなくなるゾーンレベルの障害が発生した場合:
インスタンスがシングルゾーンにデプロイされている場合:インスタンスは利用できなくなります。ゾーンが回復するのを待つ必要があります。この間、過去のバックアップデータを使用して別のゾーンに新しいインスタンスを作成できます。
インスタンスが複数のゾーンにまたがってデプロイされている場合:システムは自動フェイルオーバーをトリガーします。
信頼性を最大限に高めるには、複数のゾーンにまたがってデプロイし、各ゾーンに複数のレプリカを作成することで、ダウンタイムを大幅に最小化できます。ただし、障害の発生確率、データの重要性、および関連コストのバランスを取る必要があります。
前述の原則は、Redis グローバル分散キャッシュのサブインスタンスにも適用されます。単一のサブインスタンスの障害は、他のサブインスタンスの可用性に影響しません。単一のサブインスタンスに障害が発生した場合のデータ書き込み失敗を防ぐために、サブインスタンスを複数のゾーンにまたがってデプロイすることを推奨します。