Performance Insight は、ApsaraDB RDS for PostgreSQL の負荷モニタリングおよび診断ツールです。平均アクティブセッション (AAS) を通じてデータベース負荷を可視化し、その負荷を駆動する SQL ステートメントと待機イベントを明らかにし、複数のディメンションにわたってドリルダウンすることでパフォーマンスの問題を迅速に解決できます。
前提条件
開始する前に、以下を確認してください。
PostgreSQL 13 以降を実行している RDS インスタンス
High-availability Edition または Cluster Edition のインスタンス
マイナーエンジンバージョン 20240530 以降
Performance Insight の有効化
「ApsaraDB RDS コンソール」にログインします。[インスタンス] ページで、インスタンスが存在するリージョンを選択し、インスタンス ID をクリックします。
左側のナビゲーションウィンドウで、[モニタリングとアラート] を選択し、[Performance Insight] タブをクリックします。
[Performance Insight の有効化] をクリックします。ダイアログボックスで、[OK] をクリックします。
この機能を無効にするには、[Performance Insight] タブで [Disable Performance Insight] をクリックします。
Performance Insight ページにデータが表示されるまでしばらくお待ちください。
Performance Insight はパブリックプレビュー中で、無料です。データは 7 日間保持されます。公式リリースでは、必要に応じて保持期間を延長できるようになります。料金が発生する場合は、事前に通知されます。
Performance Insight を使用したパフォーマンス分析
機能を有効にした後、時間範囲を選択し、[表示] をクリックしてパフォーマンスを分析します。パフォーマンスの問題を診断するには、次のワークフローに従います。
AAS チャートで負荷スパイクを確認します。 平均アクティブセッション (AAS) チャートは、インスタンスの総負荷をリアルタイムで表示します。ピークはパフォーマンスボトルネックに対応します。
主要な待機イベントを特定します。 AAS チャートは、待機イベントタイプ別に負荷の内訳を表示します。AAS への貢献が最も高いディメンションは、ボトルネックカテゴリ (例: ロック待ち、I/O 待ち) を示します。
上位の SQL ステートメントを検索します。 多次元ロードテーブルの SQL タブに切り替えます。上位のエントリには、最も多くのリソースを消費するクエリ、または最も長く待機するクエリが表示されます。
ソースを特定します。 [Hosts] および [Databases] タブを使用して、負荷を生成しているクライアント IP アドレスとデータベースを特定します。
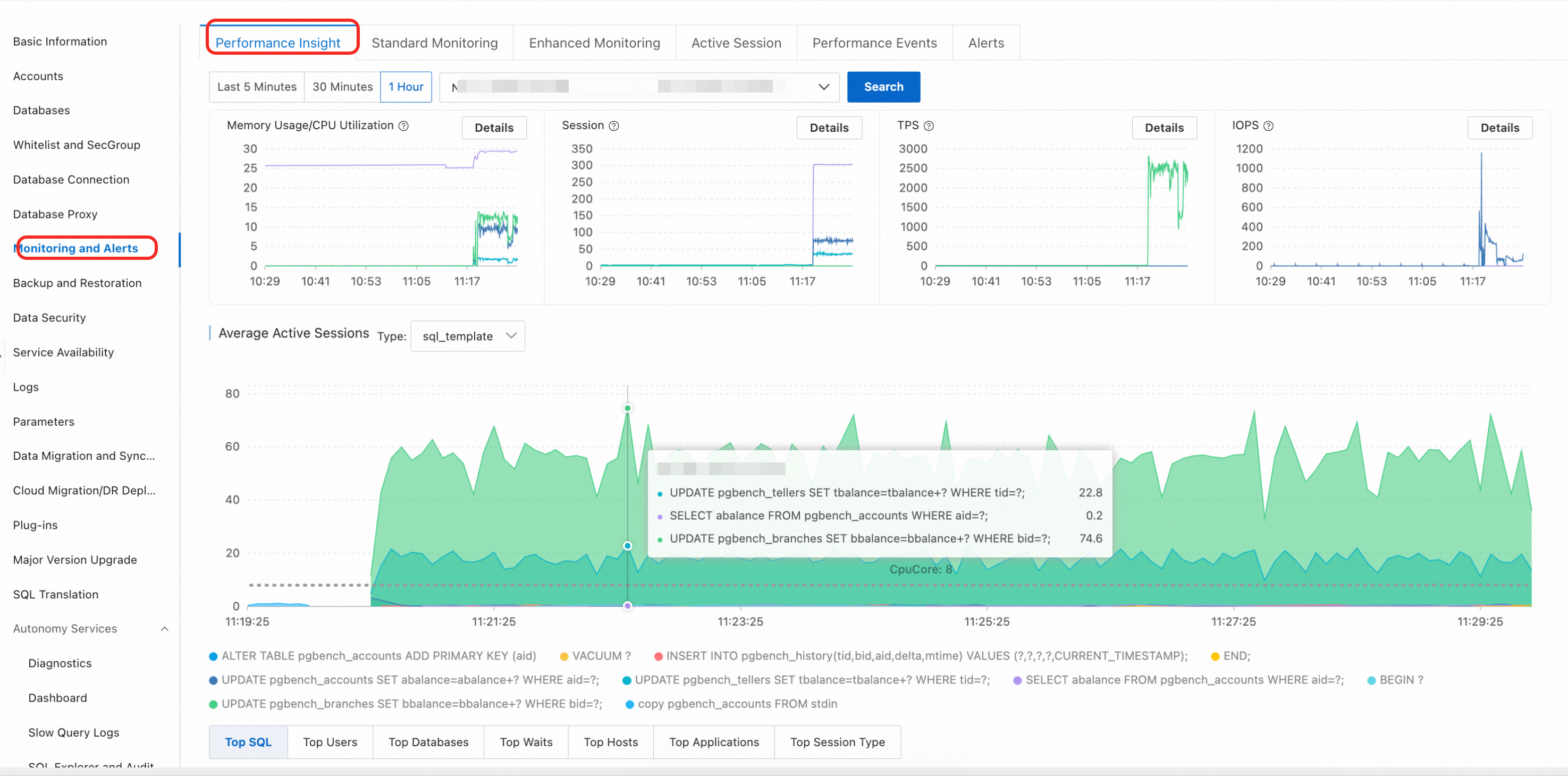
主要なパフォーマンスメトリックチャート
ページの上部には、選択した期間にわたる次のメトリックを追跡するトレンドチャートが表示されます。
| メトリック | 説明 |
|---|---|
| CPU/メモリ使用率 | CPU およびメモリリソースの使用率 |
| セッション接続 | インスタンスへのアクティブ接続数 |
| Transactions Per Second (TPS) | コミットされたトランザクションのレート |
| Input/output operations per second (IOPS) | ディスク I/O スループット |
多次元負荷の内訳
AAS チャートの下で、ディメンションタブを切り替えて、高負荷のソースを特定します。
| タブ | 表示内容 |
|---|---|
| SQL | 最もリソースを消費する SQL ステートメント |
| User | 最も高い負荷を生成しているデータベースユーザー |
| Databases | 最もアクティブセッションが多いデータベース |
| Waits | 負荷に最も貢献している待機イベントタイプ |
| Hosts | クライアントホスト名または IP アドレス |
| Applications | データベースに接続されているアプリケーション名 |
| Session Type | 現在のセッションタイプ |
スロー SQL スパイクからのロック競合のトラブルシューティング
症状
モニタリングデータは、スロー SQL ステートメントの急激なスパイクと、アプリケーション応答時間の大幅な増加を示しています。
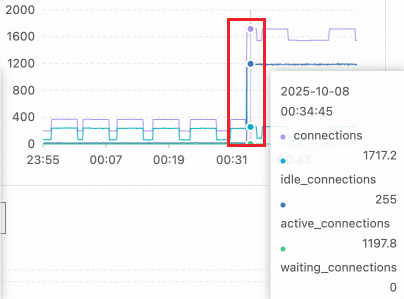
ステップ 1: パフォーマンスメトリックのトレンドを確認する
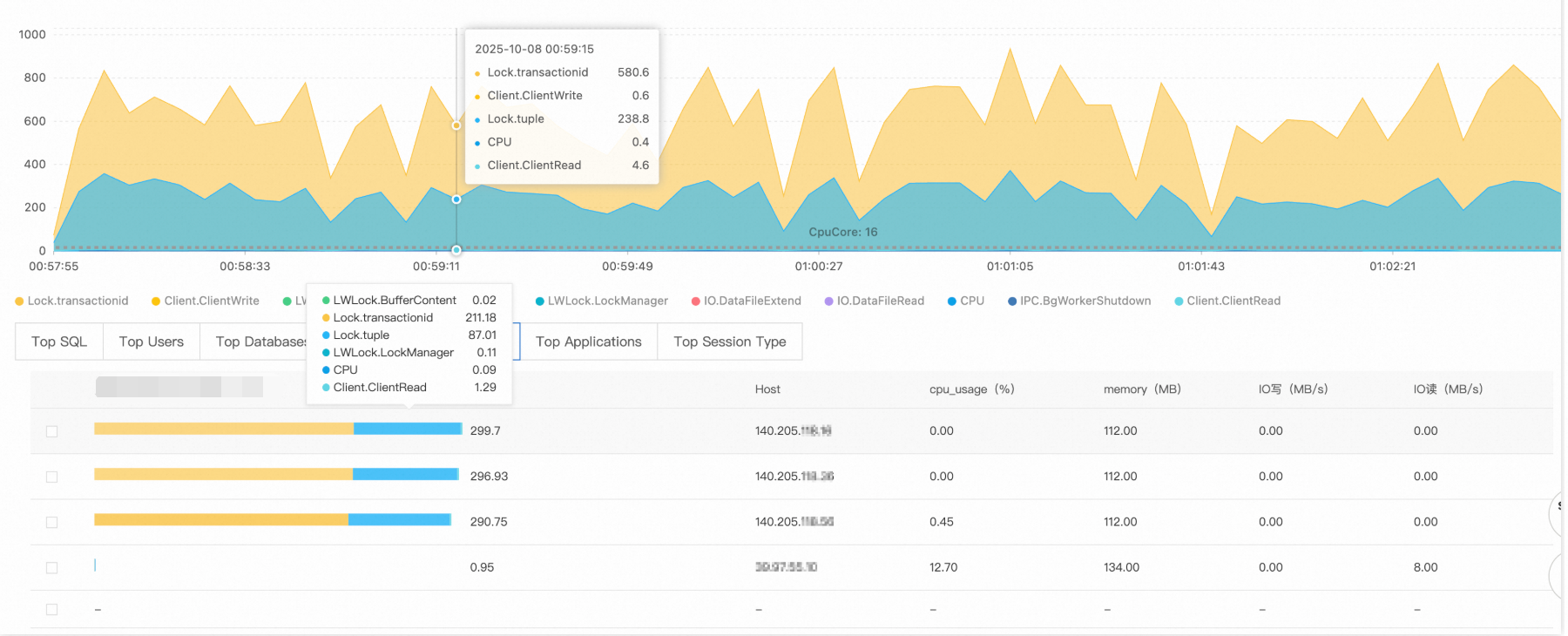
主要なパフォーマンスメトリックチャートで、アクティブセッションの急激な上昇を探します。この例では、セッション数は通常の数十レベルから 00:34 に 1,100 を超えるまで急増しました。これは、16 コアの PostgreSQL インスタンスの並行処理能力をはるかに超えています。
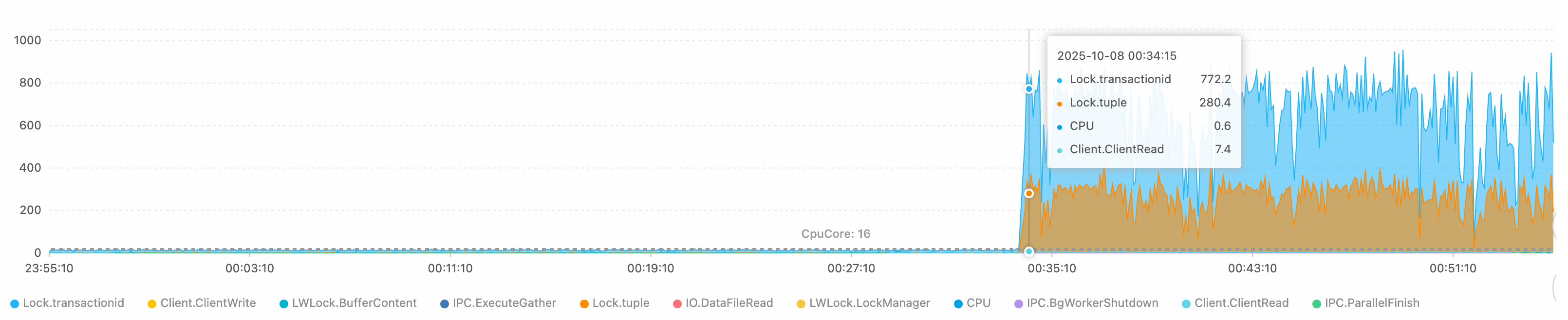
ステップ 2: 待機イベントを特定する
AAS チャートは待機イベントの分布を示します。この場合、2 つのイベントが支配的です。
Lock/transactionid: トランザクション ID ロック待ち。通常、長時間トランザクションまたはデッドロックによって引き起こされます。Lock/tuple: 行レベルのロック待ち。深刻な同時書き込み競合を示します。
アクティブセッションの数は、16 コア CPU の理論上の処理制限を超えており、深刻なロック競合を確認しています。
ステップ 3: 原因となっている SQL ステートメントを見つける
[SQL] タブに切り替えます。上位 2 つのクエリは、220 と 119 のセッションがロックリソースを待機していることを示しています。これらの文がロック待ちチェーンのルートです。
ステップ 4: ソースを特定する
ロードの発生元を特定するには、[ホスト] および [データベース] タブを確認してください:
ソースクライアント:
140.205.XXX.XXXターゲットデータベース:
perf_test
根本原因
障害タイプ: ロック競合の連鎖
140.205.XXX.XXX のクライアントは、perf_test データベースで高並行性データ操作言語 (DML) 操作を開始しました。これは、ホットスポットデータの更新または大規模トランザクション処理を伴う可能性が高いです。接続制限やロック待機タイムアウト制御がないため、各接続がロック待機キューに入ると新しい接続が殺到し、暴走するロック競合サイクルが発生しました。
ソリューション
緊急対策:
問題のあるクライアントからの接続を制限します。
ALTER ROLE target_user CONNECTION LIMIT 10; -- target_user: データベースユーザー名長時間待機セッションを終了します。
-- Review the sessions before terminating them SELECT pid, -- プロセス ID (セッション識別子) usename, -- データベースユーザー名 state, -- セッション状態 (アクティブまたはアイドル) wait_event, -- 特定の待機イベントタイプ now() - query_start AS query_duration, -- 現在のクエリの持続時間 left(query, 50) AS query_preview -- SQL ステートメントのプレビュー (最初の 50 文字) FROM pg_stat_activity WHERE datname = 'perf_test' -- ターゲットデータベース AND client_addr = '140.205.XXX.XXX' -- ソースクライアント IP アドレス AND state = 'active' AND wait_event_type = 'Lock' AND pid <> pg_backend_pid() -- 現在のセッションを除外する AND now() - query_start > interval '5 minutes'; -- After confirming the list, terminate the sessions SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'perf_test' AND client_addr = '140.205.XXX.XXX' AND state = 'active' AND wait_event_type = 'Lock' AND pid <> pg_backend_pid() AND now() - query_start > interval '5 minutes'; -- Verify that the target sessions are terminated SELECT pid, usename, state, query FROM pg_stat_activity WHERE datname = 'perf_test' AND client_addr = '140.205.XXX.XXX';
長期的な最適化:
接続プールをデプロイします。 PgBouncer などの接続プーラーを使用して、同時接続の最大数を制限します。
タイムアウトパラメーターを設定します。
-- ロック待機タイムアウトを設定します ALTER DATABASE perf_test SET lock_timeout = '30s'; -- ステートメント実行タイムアウトを設定します ALTER DATABASE perf_test SET statement_timeout = '60s';アプリケーションロジックを最適化します。
長時間トランザクションを回避するために、トランザクションの粒度を減らします。
ホットスポットデータには、楽観的ロックまたは分散ロックメカニズムを使用します。
読み取り専用クエリを読み取り専用インスタンスにルーティングするために、読み書き分離を実装します。
モニタリングしきい値を設定します。 アクティブ接続数とロック待機時間のアラートを設定して、問題がエスカレートする前に検出します。