Platform for AI (PAI) の一部である Elastic Algorithm Service (EAS) は、シナリオベースのデプロイを提供します。数個のパラメーターを設定するだけで、大規模言語モデル (LLM) と Retrieval-Augmented Generation (RAG) 技術を統合した対話システムをワンクリックでデプロイでき、デプロイ時間を大幅に短縮できます。推論時には、このサービスがナレッジベースから関連情報を取得し、LLM の応答と組み合わせることで、正確かつ情報量豊富な回答を生成し、Q&A システムの品質とパフォーマンスを向上させます。このサービスは、質問応答や要約生成など、外部知識を必要とする自然言語処理タスクに最適です。本トピックでは、ApsaraDB RDS for PostgreSQL を使用してベクトルデータベースを構築し、RAG 対話サービスをデプロイして、モデルの推論結果を検証する方法について説明します。
背景情報
大規模言語モデル (LLM) には、応答の精度や新鮮さに制限があるため、カスタマーサポートや Q&A など正確な情報が求められるシナリオには不向きです。これを解決するために、業界では広く Retrieval-Augmented Generation (RAG) 技術が採用され、LLM のパフォーマンスを強化しています。この技術により、外部知識に依存する Q&A や要約生成などの自然言語処理 (NLP) タスクの品質を大幅に向上できます。
RAG は、Qwen などの LLM と情報取得コンポーネントを組み合わせることで、生成された回答の精度と情報量を高めます。ユーザークエリを処理する際、RAG システムの取得コンポーネントがナレッジベース内を検索し、関連ドキュメントまたは情報スニペットを取得します。この取得されたコンテンツと元のクエリを LLM に送信し、モデルは帰納的な生成能力を活用して、再トレーニングすることなく事実に基づいた最新の応答を生成します。
EAS を使用してデプロイされる対話システムサービスは、LLM と RAG 技術を統合することで、単体の LLM が抱える精度および新鮮さの制限を克服します。さまざまな Q&A シナリオに対して正確かつ情報量豊富な応答を提供し、NLP タスクの全体的な効果とユーザーエクスペリエンスを向上させます。
前提条件
Virtual Private Cloud (VPC)、vSwitch、およびセキュリティグループを作成済みである必要があります。詳細については、「VPC の作成と管理」および「セキュリティグループの作成」をご参照ください。
カスタムファインチューニング済みモデルを使用してサービスをデプロイする場合は、モデルファイルを保存するための Object Storage Service (OSS) バケットまたは Apsara File Storage NAS (NAS) ファイルシステムを準備してください。詳細については、「コンソールの概要」または「ファイルシステムの作成」をご参照ください。
注意事項
このプロシージャは LLM サービスの最大トークン制限の影響を受け、RAG ベースの対話システムにおける基本的な取得機能を確認するのに役立ちます。
LLM サービスのサーバーリソースおよびデフォルトのトークン制限により、最大会話長が決定されます。
マルチターン対話を必要としない場合は、RAG サービスの
with chat history機能を無効にすることを推奨します。これにより、トークン制限に達するのを回避できます。詳細については、「RAG サービスで「チャット履歴あり」機能を無効にする方法」をご参照ください。
ステップ 1:ApsaraDB RDS for PostgreSQL ベクトルデータベースの準備
ApsaraDB RDS for PostgreSQL を使用して RAG 向けのベクトルデータベースを構築できます。データベース接続に必要な構成パラメーターを準備してください。
ApsaraDB RDS for PostgreSQL インスタンスを迅速に作成します。
ApsaraDB RDS for PostgreSQL インスタンスと RAG サービスを同一リージョンにデプロイすることを推奨します。これにより、VPC 内部ネットワーク経由での通信が可能になります。
RDS インスタンス用のアカウントおよびデータベースを作成します。詳細については、「アカウントおよびデータベースの作成」をご参照ください。
注:
アカウント作成時に、アカウントタイプ: を 特権アカウント に設定します。
データベース作成時に、所属アカウント として作成済みの特権アカウントを選択します。
データベース接続を構成します。
インスタンス ページに移動します。上部ナビゲーションバーで RDS インスタンスが配置されているリージョンを選択し、該当の RDS インスタンスを見つけてインスタンス ID をクリックします。
[データベース接続] ページで、データベースエンドポイントおよびポート番号を確認します。
適用中のパラメーター値 の shared_preload_libraries に pg_jieba を追加します。たとえば、適用中のパラメーター値 を
'pg_stat_statements,auto_explain,pg_cron'に変更します。詳細については、「インスタンスパラメーターの設定」をご参照ください。説明ApsaraDB RDS for PostgreSQL は、キーワードベースの取得および再現率向上のために中国語テキストのセグメンテーションに pg_jieba 拡張を使用します。
ステップ 2:RAG サービスのデプロイ
モデルオンラインサービスページに移動します。
PAI コンソール にログインします。
左側のナビゲーションウィンドウで、Workspaces をクリックします。[ワークスペース] ページで、管理対象のワークスペース名をクリックします。
ワークスペースがない場合は、「ワークスペースの作成と管理」をご参照ください。
ワークスペースの左側ナビゲーションウィンドウで、Model Deployment > Elastic Algorithm Service (EAS) の順に選択して、Elastic Algorithm Service (EAS) ページを開きます。
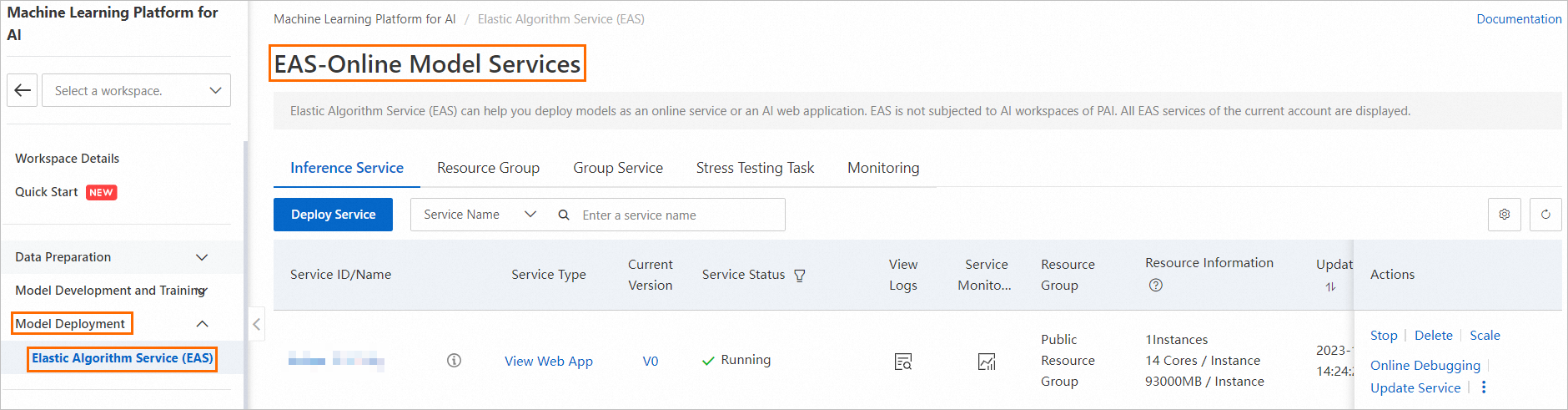
Elastic Algorithm Service (EAS) ページで、Deploy Service をクリックします。[Scenario-based Model Deployment] セクションで、RAG-based Smart Dialogue Deployment をクリックします。
RAG-based LLM Chatbot Deployment ページで、以下の主要パラメーターを構成します。
基本情報
パラメーター
説明
Service Name
任意のサービス名を指定します。
Model Source
有効な値:Open Source Model および Custom Fine-tuned Model。
Model Type
シナリオに応じてモデルタイプを選択します。
カスタムファインチューニング済みモデルを使用する場合、モデルのパラメーターサイズおよび精度を構成する必要があります。
モデル構成
カスタムファインチューニング済みモデルを使用する場合、ファインチューニング済みモデルのファイルパスを構成する必要があります。以下の 2 つの方法がサポートされています。
説明モデルファイル形式が HuggingFace Transformers と互換性があることを確認してください。
Object Storage Service (OSS) 経由:ファインチューニング済みモデルファイルが保存されている OSS パスを選択します。
Apsara File Storage NAS 経由:ファインチューニング済みモデルファイルが保存されている NAS ファイルシステムおよび NAS ソースパスを選択します。
リソース構成
パラメーター
説明
Resource Configuration
オープンソースモデル を使用する場合、選択したモデルカテゴリに基づき、システムが適切なインスタンスタイプを自動的に推奨・選択します。
カスタムファインチューニング済みモデル を使用する場合、モデルに適合するインスタンスタイプを選択します。詳細については、「他のオープンソース大規模モデルへの切り替え方法」をご参照ください。
Inference Acceleration
A10 または GU30 シリーズインスタンス上でデプロイされた Qwen、Llama2、ChatGLM、または Baichuan2 シリーズモデルでは、推論アクセラレーションがサポートされています。以下の 2 種類のアクセラレーションが利用可能です。
BladeLLM Inference Acceleration:BladeLLM は非常にコスト効率の高い LLM 推論アクセラレーションを提供し、ワンクリックで高い同時実行性と低遅延を実現します。
Open-source vLLM Inference Acceleration
ベクトルデータベース設定
パラメーター
説明
バージョンタイプ
ApsaraDB RDS for PostgreSQL を選択します。
Host Address
ApsaraDB RDS for PostgreSQL インスタンスの内部エンドポイントまたはパブリックエンドポイントを設定します。
内部エンドポイントを使用:RAG アプリケーションとデータベースが同一リージョンにある場合、内部エンドポイントを使用してインスタンスに接続できます。
パブリックエンドポイントを使用:RAG アプリケーションとデータベースが異なるリージョンにある場合、ApsaraDB RDS for PostgreSQL インスタンスにパブリックエンドポイントを申請する必要があります。詳細については、「パブリックエンドポイントの申請または解放」をご参照ください。
ポート
デフォルト値は 5432 です。必要に応じて別の値を入力します。
データベース
ApsaraDB RDS for PostgreSQL データベースの名前です。
テーブル名
新しいテーブル名または既存のテーブル名を入力します。既存のテーブルの構造は PAI-RAG の要件を満たしている必要があります。たとえば、以前に EAS を使用して RAG サービスをデプロイした際に自動作成されたテーブル名を入力できます。
アカウント
ApsaraDB RDS for PostgreSQL インスタンスの特権アカウントです。
パスワード
ApsaraDB RDS for PostgreSQL インスタンスの特権アカウントのパスワードです。
VPC 構成
パラメーター
説明
VPC
ホストアドレスに内部エンドポイントを使用する場合、RAG サービスを ApsaraDB RDS for PostgreSQL インスタンスと同じ VPC で構成する必要があります。
ホストアドレスにパブリックエンドポイントを使用する場合、RAG サービス用に VPC および vSwitch を構成し、さらに VPC に NAT ゲートウェイおよび Elastic IP アドレス (EIP) を構成して、RAG アプリケーションにインターネットアクセスを提供する必要があります。詳細については、「パブリック NAT ゲートウェイの SNAT 機能を使用したインターネットアクセス」をご参照ください。また、バインドされた EIP を ApsaraDB RDS for PostgreSQL インスタンスのパブリック IP アドレスホワイトリストに追加する必要があります。詳細については、「IP アドレスホワイトリストの設定」をご参照ください。
VSwitch
Security Group Name
セキュリティグループを構成します。
重要created_by_rds という名前のセキュリティグループは使用しないでください。このセキュリティグループは内部システム専用に予約されています。
Deploy をクリックします。
Service Status が 実行中 に変わると、サービスのデプロイが完了します。
ステップ 3:Web UI による推論の検証
このセクションの手順に従って、まず Web UI 上でサービスをデバッグできます。Web UI で目的の Q&A パフォーマンスが得られたら、PAI が提供する API を使用して、サービスを自社の業務システムに統合できます。詳細については、「ステップ 4:API を使用したモデル推論の検証」をご参照ください。
1. RAG サービスの構成
RAG サービスのデプロイ後、[View Web App] 列の Service Type をクリックして Web UI を開きます。
機械学習モデルを構成します。
埋め込みモデル名:4 つの組み込みモデルが利用可能です。システムが最も適切なモデルを自動的に選択・構成します。
埋め込み次元:埋め込みモデル名 を選択すると、システムがこのパラメーターを自動的に構成します。操作は不要です。
ベクトルデータベース接続をテストします。
システムはサービスデプロイ時に構成したベクトルデータベース設定を自動的に検出して適用し、これらの設定は変更できません。Connect PostgreSQL をクリックして、ApsaraDB RDS for PostgreSQL への接続性を確認します。
2. 業務データファイルのアップロード
[アップロード] タブで、業務データファイルをアップロードします。サポートされる形式は .txt、.pdf、Excel (.xlsx または .xls)、.csv、Word (.docx または .doc)、Markdown、および .html です。
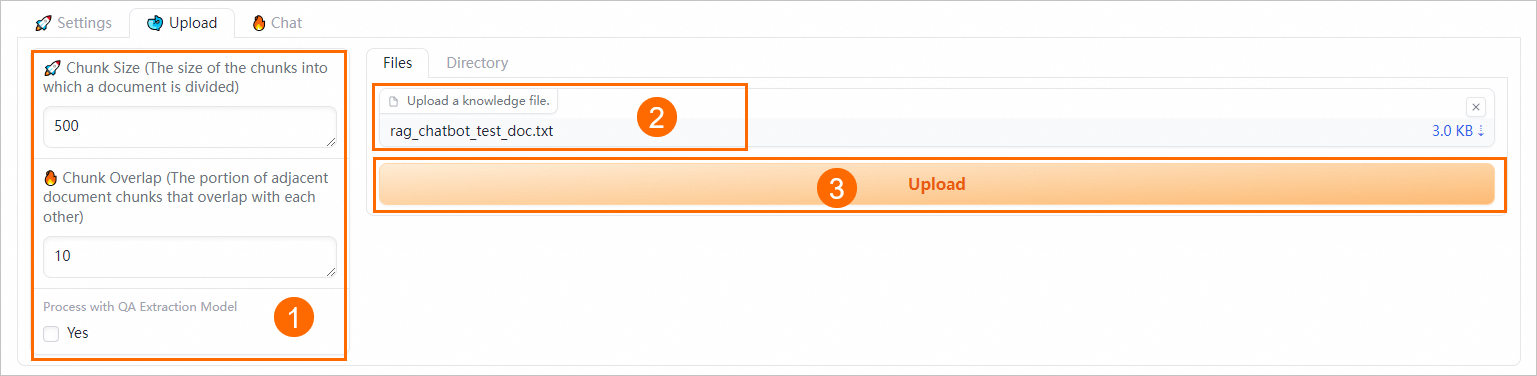
セマンティックチャンキングパラメーターを設定します。
以下のパラメーターを使用して、ドキュメントチャンキングの粒度を制御し、QA 情報抽出を実行します。
パラメーター
説明
チャンクサイズ
各チャンクのサイズ(バイト単位)。デフォルト値は 500 です。
チャンクオーバーラップ
隣接するチャンク間の重複量。デフォルト値は 10 です。
QA 抽出モデルで処理
はい チェックボックスをオンにして QA 情報抽出を有効にします。システムがアップロードされた業務データファイルから自動的に Q&A ペアを抽出し、取得および応答品質を向上させます。
[ファイル] または [ディレクトリ] タブで、業務データファイル(複数ファイル可)または対応するディレクトリをアップロードします。たとえば、rag_chatbot_test_doc.txt をアップロードします。
ファイルを選択すると、システムが選択されたファイルに対してデータクレンジング(テキスト抽出、ハイパーリンク置き換えなど)およびセマンティックチャンキングを実行した後、アップロードします。

3. モデル推論パラメーターの構成
[チャット] タブで、Q&A 戦略を構成します。
検索型Q&A
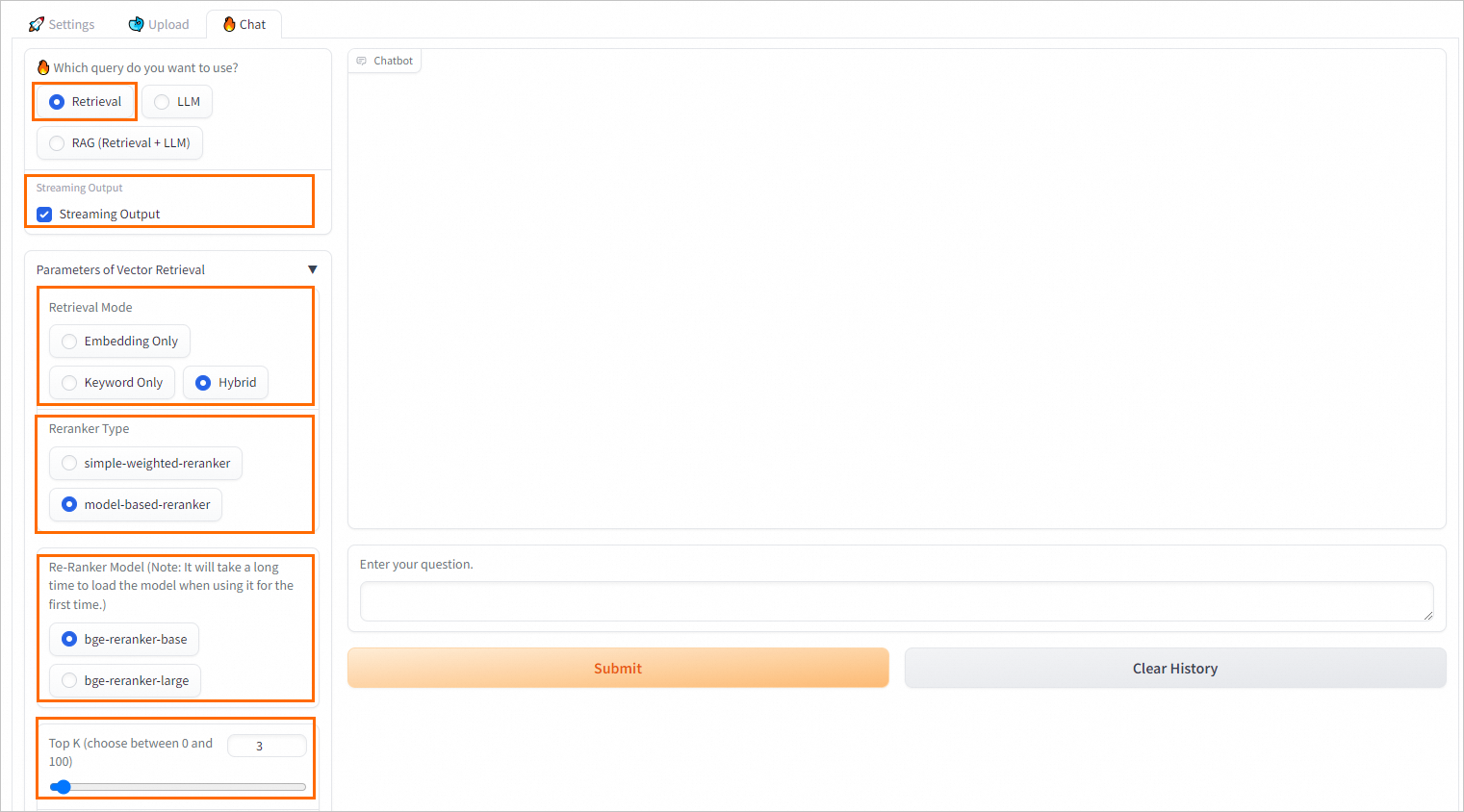
パラメーター | 説明 |
ストリーミング出力 | ストリーミング出力 を選択すると、システムがストリーミングモードで結果を返します。 |
取得モデル | 以下の 3 つの取得方法がサポートされています。
説明 多くの複雑なシナリオでは、ベクトルデータベース取得が良好なパフォーマンスを発揮します。ただし、コーパスが疎な特定ドメインや完全一致が求められるシナリオでは、ベクトル取得手法が従来のスパース取得手法ほど効果的でない場合があります。スパース取得手法は、ユーザークエリとナレッジドキュメント間のキーワード重複を計算して取得を行うため、シンプルかつ効率的です。 ApsaraDB RDS for PostgreSQL は、キーワードベースの再現率向上のために中国語テキストのセグメンテーションに pg_jieba 拡張を使用します。pg_jieba 拡張の使用方法の詳細については、「中国語形態素解析 (pg_jieba)」をご参照ください。 |
リランカータイプ | ほとんどのベクトルデータベースは計算効率のために若干の精度を犠牲にしており、取得結果に多少のランダム性が生じます。そのため、最初に返された上位 K 件の結果が必ずしも最も関連性が高いとは限りません。simple-weighted-reranker または model-based-reranker モデルを選択して、ベクトルデータベースによって最初に取得された上位 K 件の結果に対して高精度な再ランキング操作を実行できます。これにより、より関連性が高く正確なナレッジドキュメントを取得できます。 説明 モデルを初めて使用する際は、ロードに時間がかかる場合があります。要件に応じてモデルを選択してください。 |
Top K | ベクトルデータベースから返す類似結果の件数。システムは最も類似度の高い上位 K 件の結果を取得します。 |
類似度スコアしきい値 | 類似度のしきい値。値が大きいほど類似度が高くなります。 |
RAG (取得 + LLM) Q&A

PAI は複数のプロンプト戦略を提供しています。適切な事前定義済みプロンプトテンプレートを選択するか、カスタムプロンプトテンプレートを入力して、推論結果を改善できます。
RAG (取得 + LLM) Q&A 方式でも、ストリーミング出力、取得モード、リランカータイプなどのパラメーターを構成できます。詳細については、「取得 Q&A」をご参照ください。
4. モデル推論の検証
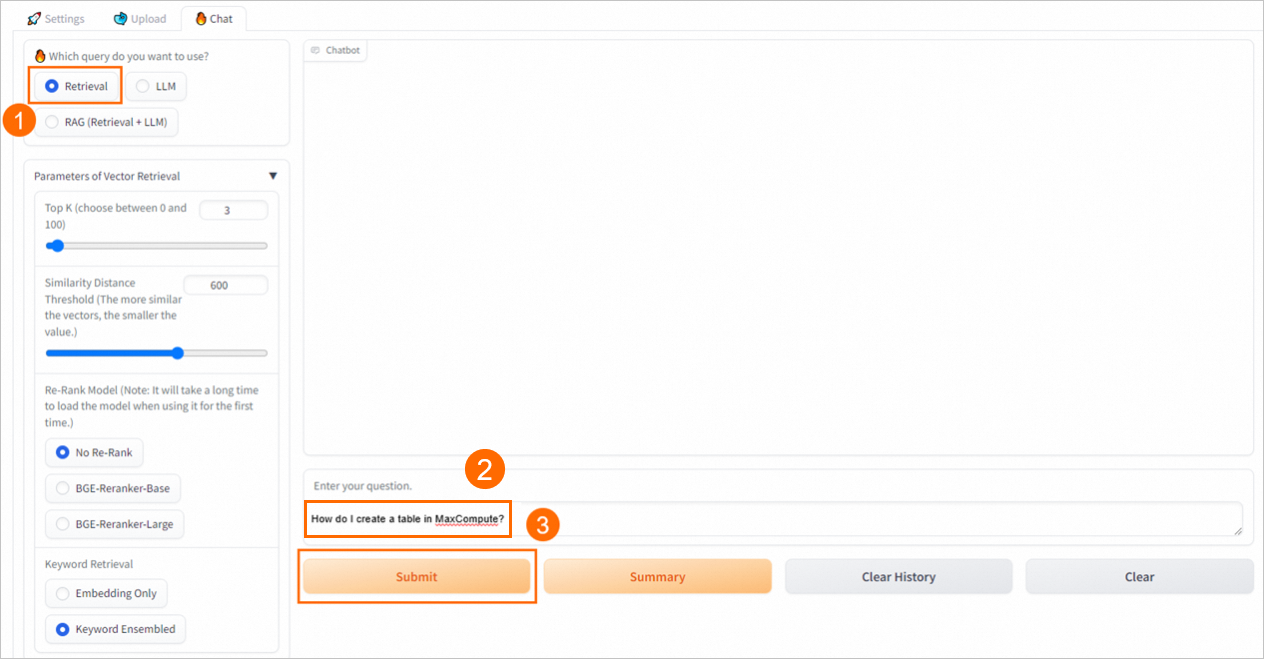
検索
ベクトルデータベースから直接、類似度の高い上位 K 件の結果を取得して返します。
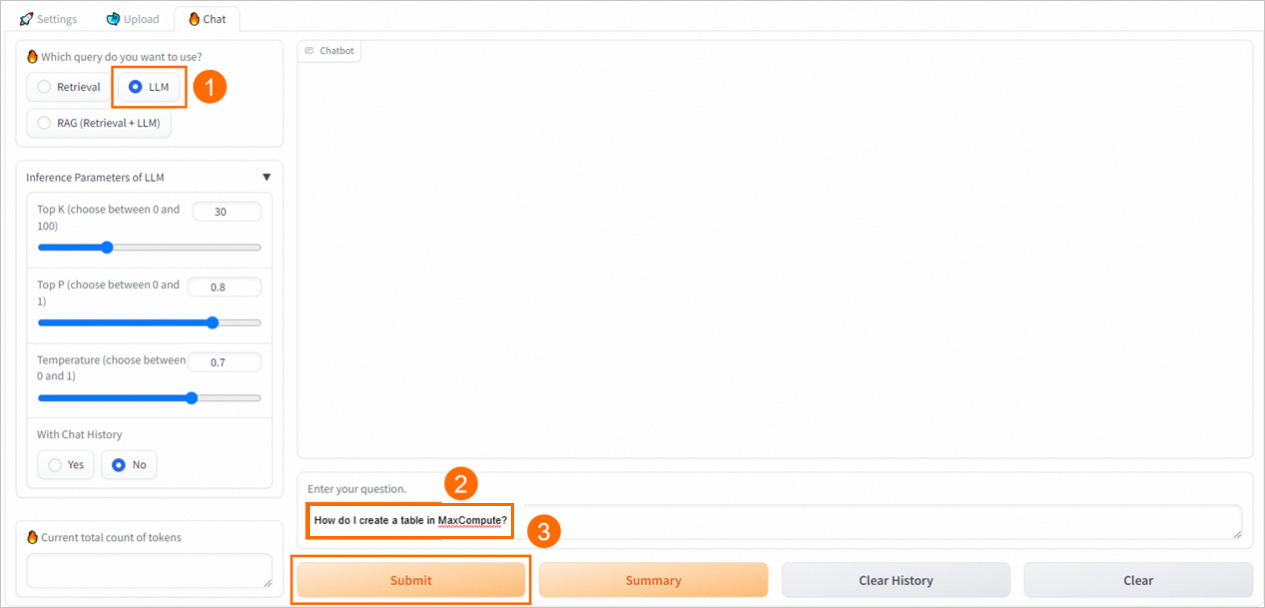
LLM
EAS-LLM サービスと直接対話し、LLM の応答を返します。
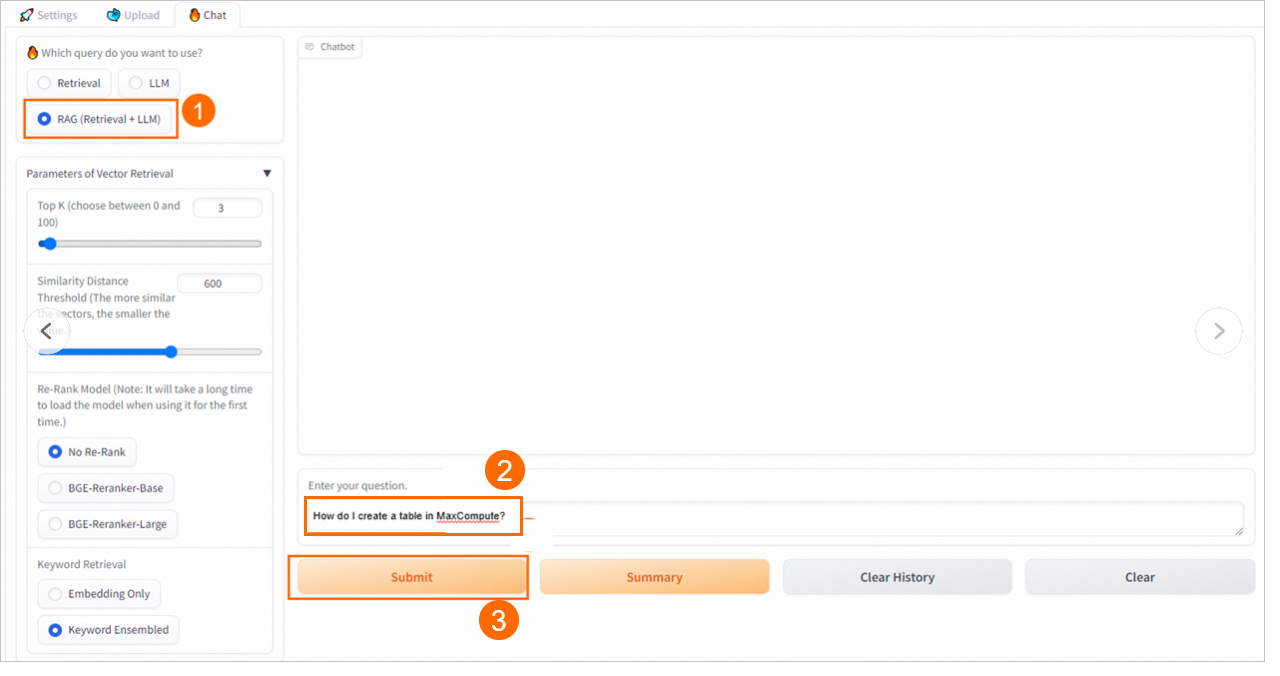
RAG (取得 + LLM)
取得結果およびユーザーの質問を選択したプロンプトテンプレートに挿入し、結合された入力を EAS-LLM サービスに送信して、Q&A 結果を取得します。
ステップ 4:API による推論の検証
RDS for PostgreSQL でのナレッジベースの確認
ベクトルデータベースとして機能する ApsaraDB RDS for PostgreSQL データベースに接続後、インポートされたナレッジベースの内容を確認できます。データベースへの接続方法については、「PostgreSQL インスタンスへの接続」をご参照ください。
次のステップ
EAS を使用して、以下のシナリオベースのデプロイも実行できます。
Web UI および API 呼び出しをサポートする LLM アプリケーションをデプロイします。アプリケーションのデプロイ後、LangChain フレームワークを使用して企業のナレッジベースを統合し、インテリジェントな Q&A および自動化を実現できます。詳細については、「EAS を使用した LLM アプリケーションの迅速なデプロイ」をご参照ください。
ComfyUI および Stable Video Diffusion モデルに基づく AI 動画生成サービスをデプロイして、ソーシャルメディアプラットフォーム向けのショートビデオコンテンツやアニメーションを生成できます。詳細については、「AI 動画生成 - ComfyUI デプロイ」をご参照ください。
よくある質問
RAG サービスでチャット履歴を無効にする方法
RAG サービスの Web UI で、Chat history チェックボックスをオフにします。