このトピックでは、PostgreSQL ANN search extension (PASE) を使用して、ApsaraDB RDS for PostgreSQLでベクトルを検索する方法について説明します。 PASEは、IVFFlatまたはHierarchical Navigable Small World (HNSW) アルゴリズムに基づいて機能します。
PASE拡張はもはや維持されない。 pgvector拡張を使用することを推奨します。 詳細については、「pgvector拡張を使用して高次元ベクトル類似性検索を実行する」をご参照ください。
前提条件
RDSインスタンスはPostgreSQL 11以降を実行します (PostgreSQL 17を除く) 。
背景情報
表現学習は、ディープラーニング分野における典型的な人工知能 (AI) 技術です。 この技術は近年急速に発展しており、広告、顔スキャン支払い、画像認識、音声認識などのさまざまなビジネスシナリオで使用されています。 このテクノロジーにより、データを高次元ベクトルに埋め込むことができ、ベクトル検索アプローチを使用してデータをクエリできます。
PASEは、PostgreSQL用に開発された高性能ベクトル検索インデックス拡張機能です。 PASEは、2つの十分に開発された、安定した、効率的な近似最近傍 (ANN) 検索アルゴリズム、IVFFlatおよびHNSWを使用して、PostgreSQLデータベースからベクトルを高速でクエリします。 PASEは、特徴ベクトルの抽出または出力をサポートしない。 クエリするエンティティのフィーチャベクトルを取得する必要があります。 PASEは、検索された特徴ベクトルに基づいて識別される多数のベクトル間の類似性検索を実行するだけである。
対象
このトピックでは、機械学習に関連する用語の詳細については説明しません。 このトピックを読む前に、機械学習と検索技術の基本を理解する必要があります。
使用上の注意
テーブルのインデックスが肥大化している場合は、
select pg_relation_size('Index name');ステートメントを実行して、インデックス付きデータのサイズを取得できます。 次に、インデックスのサイズとテーブル内のデータのサイズを比較します。 インデックス付きデータのサイズがテーブル内のデータのサイズよりも大きく、データクエリの速度が低下する場合は、テーブル上のインデックスを再構築する必要があります。テーブル上のインデックスは、頻繁なデータ更新後に不正確になる可能性があります。 精度レベルの100% が必要な場合は、定期的にインデックスを再構築する必要があります。
内部重心を使用してテーブルにIVFFlatインデックスを作成する場合は、clustering_typeパラメーターを1に設定し、テーブルにデータを挿入する必要があります。
このトピックで説明するSQL文を実行するには、特権アカウントを使用する必要があります。
PASEによって使用されるアルゴリズム
IVFFlat
IVFFlatはIVFADCアルゴリズムの簡易版です。 IVFFlatは、高精度を必要とするビジネスシナリオに適していますが、クエリに最大100ミリ秒かかる可能性があります。 IVFFlatには、他のアルゴリズムと比較して次の利点があります。
クエリするベクトルが候補データセットの1つである場合、IVFFlatは100% リコールを提供します。
IVFFlatはシンプルな構造を使用してインデックスを高速で作成し、作成されたインデックスの占有容量が少なくなります。
クラスタリングの重心を指定し、パラメーターを再設定することで精度を制御できます。
IVFFlatの精度は、解釈可能なパラメータを再設定することで制御できます。
次の図は、IVFFlatの仕組みを示しています。
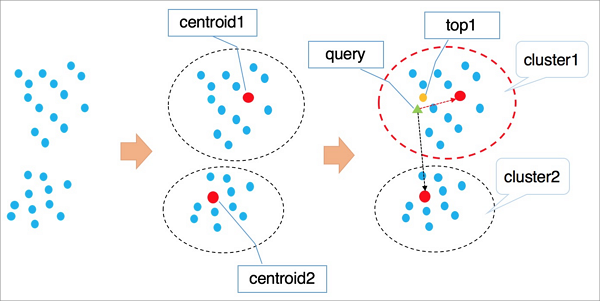
次の手順では、IVFFlatの動作について説明します。
IVFFlatは、k平均などのクラスタリングアルゴリズムを使用して、暗黙的なクラスタリング特性に基づいて、高次元データ空間内のベクトルをクラスタに分割します。 各クラスタは重心を有する。
IVFFlatは、すべてのクラスターの重心をトラバースして、クエリするベクトルに最も近いn個の重心を識別します。
IVFFlatは、識別されたn個の重心が属するクラスタ内のすべてのベクトルをトラバースおよびソートする。 次いで、IVFFlatは、最も近いk個のベクトルを得る。
説明IVFFlatが最も近いn個の重心を識別しようとすると、クエリするベクトルから遠く離れた場所にあるクラスターをスキップします。 これにより、クエリが促進されます。 しかしながら、IVFFlatは、識別されたn個の重心が属するクラスタにすべての類似するk個のベクトルが含まれることを保証できない。 結果として、精度が低下する可能性がある。 変数nを使用して精度を制御できます。 nの値が大きいほど、精度は高くなりますが、コンピューティングワークロードは多くなります。
最初のフェーズでは、IVFFlatはIVFADCと同じように機能します。 IVFFlatとIVFADCの主な違いは、2番目のフェーズにあります。 第2フェーズでは、IVFADCは積量子化を使用して、トラバースコンピューティングワークロードの必要性を排除します。 これは、クエリを促進するが、精度を低下させる。 IVFFlatは、精度を確保するためにブルートフォース検索を実装し、コンピューティングワークロードを制御できます。
HNSW
HNSWは、数千万以上のベクトルデータセット間のクエリに適したグラフベースのANNアルゴリズムです。 これらのクエリへの応答は、10ミリ秒以内に返す必要があります。
HNSWは、近接グラフ近傍の間で類似ベクトルを検索する。 データ量が多い場合、HNSWは他のアルゴリズムと比較してパフォーマンスを大幅に向上させます。 しかしながら、HNSWは、記憶空間を占有する近接グラフ近傍の記憶を必要とする。 さらに、HNSWの精度が特定のレベルに達した後は、パラメーターを再設定してHNSWの精度を上げることはできません。
HNSWの動作を次の図に示します。
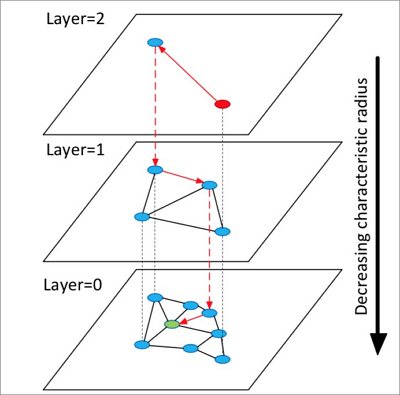
以下の手順では、HNSWの仕組みについて説明します。
HNSWは、グラフとも呼ばれる複数の層からなる階層構造を構築する。 各レイヤーはパノラマであり、その下位レイヤーのリストをスキップします。
HNSWは、最上層からランダムに要素を選択して検索を開始する。
HNSWは、選択された要素の近傍を識別し、識別された近傍の選択された要素までの距離に基づいて、識別された近傍を固定長の動的リストに追加する。 HNSWは、リストに含まれる各ネイバーのネイバーを識別し続け、識別されたネイバーをリストに追加する。 HNSWがリストにネイバーを追加するたびに、HNSWはリスト内のネイバーを再ソートし、最初のk個のネイバーのみを保持する。 リストが変化した場合、HNSWは、リストが最終状態に達するまで検索を続ける。 次に、HNSWは、リスト内の最初の要素を、下位レイヤでの検索の開始として使用する。
HNSWは、最下層における探索を完了するまで第3のステップを繰り返す。
説明HNSWは、単層構造を構築するように設計されたNavigable Small World (NSW) アルゴリズムを使用して、多層構造を構築する。 近接グラフ近傍を選択するための手法の採用により、HNSWは、クラスタリングアルゴリズムよりも高いクエリ高速化を実現することができる。
IVFFlatとHNSWはそれぞれ、特定のビジネスシナリオに適しています。 例えば、IVFFlatは高精度での画像比較に適しており、HNSWは推奨リコールでの検索に適している。
PASEの使用
手順
次のステートメントを実行してPASEを作成します。
CREATE EXTENSION pase;次のいずれかの構築方法を使用して、ベクトル類似度を計算します。
PASEタイプベースの構造
例:
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[]) AS distance; SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0) AS distance; SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 1) AS distance;説明<?> はPASE型の演算子で、特定の要素の左右のベクトル間の類似度を計算するために使用されます。 左側のベクトルはfloat4[] データ型を使用し、右側のベクトルはPASEデータ型を使用する必要があります。
PASEデータ型はPASEで定義されています。 上記のステートメントに基づいて、PASE型のデータを構築できます。 例として、前の3番目のステートメントの
float4[], 0, 1の部分を取り上げます。 最初のパラメーターは、float4[] データ型で右側のベクトルを指定します。 2番目のパラメータは特別な目的には役立たず、0に設定できます。 第3のパラメータは、類似度計算方法を指定し、値0はユークリッド距離法を表し、値1は内積法を表す。 ドット積は内積とも呼ばれます。左側のベクトルは、右側のベクトルと同じ数の次元を持つ必要があります。 そうでなければ、システムは類似性計算エラーを報告する。
文字列ベースの構築
例:
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1'::pase AS distance; SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0'::pase AS distance; SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0:1'::pase AS distance;説明文字列ベースの構築方法は、PASEタイプベースの構築方法とは次の点で異なります。文字列ベースの構築方法は、colon (:) を使用してパラメーターを分離します。 例として、前の3番目のステートメントの
3,1 1:0:1の部分を取り上げます。最初のパラメーターは、右側のベクトルを指定します。 2番目のパラメータは特別な目的には役立たず、0に設定できます。 第3のパラメータは、類似度計算方法を指定し、値0はユークリッド距離法を表し、値1は内積法を表す。 ドット積は内積とも呼ばれます。
IVFFlatまたはHNSWを使用してインデックスを作成します。
説明ユークリッド距離法を使用してベクトルの類似度を計算する場合、元のベクトルを処理する必要はありません。 ドット積またはコサイン法を使用してベクトル類似度を計算する場合、元のベクトルを正規化する必要があります。 たとえば、元のベクトルが
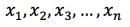 の場合、次の式に従わなければなりません。
の場合、次の式に従わなければなりません。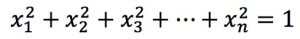 。 この例では、内積はコサイン値と同じです。
。 この例では、内積はコサイン値と同じです。 IVFFlat
CREATE INDEX ivfflat_idx ON table_name USING pase_ivfflat(column_name) WITH (clustering_type = 1, distance_type = 0, dimension = 256, base64_encoded = 0, clustering_params = "10,100");次の表に、IVFFlatインデックスのパラメーターを示します。
パラメーター
説明
clustering_type
IVFFlatがベクトルに対して実行するクラスタリング操作のタイプ。 This parameter is required. 有効な値:
0: 外部クラスタリング。 外部セントロイドファイルがロードされます。 このファイルは、clustering_paramsパラメーターで指定します。
1: 内部クラスタリング。 k平均クラスタリングアルゴリズムが使用される。 このアルゴリズムは、clustering_paramsパラメーターで指定します。
PASEを初めて使用する場合は、内部クラスタリングを選択することを推奨します。
distance_type
ベクトルの類似度を計算するために使用されるメソッド。 デフォルト値:0 有効な値:
0: ユークリッド距離。
1: ドット商品。 この方法は、ベクトルの正規化を必要とする。 ドット積の順序は、ユークリッド距離の順序とは逆です。
ApsaraDB RDS for PostgreSQLは、ユークリッド距離法のみをサポートしています。 ドット積は、ベクトルが正規化された後にのみ、付録に記載されている方法を使用して計算できます。
ディメンション
ディメンションの数。 This parameter is required. このパラメータの最大値は512です。
base64_エンコード
Base64エンコーディングを使用するかどうかを指定します。 デフォルト値:0 有効な値:
0: float4[] データ型を使用してベクトル型を表します。
1: Base64-encoded float[] データ型を使用してベクトル型を表します。
clustering_params
外部クラスタリングの場合、このパラメータは、使用する外部セントロイドファイルのディレクトリを指定します。 内部クラスタリングの場合、このパラメーターは使用するクラスタリングアルゴリズムを指定します。 このパラメーターの値は、次の形式
clustering_sample_ratio,kです。 This parameter is required.clustering_sample_ratio: 1000を分母とするサンプリング比。 このフィールドの値は、
(0,1000)の範囲内の整数である。 たとえば、このフィールドを1に設定した場合、システムはk-meansクラスタリングを実行する前に、1:1000のサンプリング比に基づいて動的リストからデータをサンプリングします。 値が大きいほど、クエリの精度は高くなりますが、インデックスの作成は遅くなります。 サンプリングされたデータレコードの総数は100,000を超えないようにすることを推奨します。k: 重心の数。 値が大きいほど、クエリの精度は高くなりますが、インデックスの作成は遅くなります。 このフィールドを [100、1000] の範囲内の値に設定することを推奨します。
HNSW
CREATE INDEX hnsw_idx ON table_name USING pase_hnsw(column_name) WITH (dim = 256, base_nb_num = 16, ef_build = 40, ef_search = 200, base64_encoded = 0);次の表に、HNSWインデックスのパラメーターを示します。
パラメーター
説明
薄暗い
ディメンションの数。 This parameter is required. 有効な値:
[8,512]。base_nb_num
要素に対して識別するネイバーの数。 This parameter is required. 値が大きいほど、クエリの精度は高くなりますが、インデックスの作成が遅くなり、ストレージが占有されます。 このパラメーターを
[16,128]の範囲の値に設定することを推奨します。ef_build
インデックスの作成時に使用するヒープの長さ。 This parameter is required. ヒープ長が長いほど、クエリの精度は高くなりますが、インデックスの作成は遅くなります。 このパラメーターを
[40, 400]の範囲内の値に設定することを推奨します。ef_search
クエリ中に使用するヒープの長さ。 This parameter is required. ヒープ長が長いほど、クエリの精度は高くなりますが、クエリのパフォーマンスは低下します。 有効な値:
[10,400]。base64_エンコード
Base64エンコーディングを使用するかどうかを指定します。 デフォルト値:0 有効な値:
0: float4[] データ型を使用してベクトル型を表します。
1: Base64-encoded float[] データ型を使用してベクトル型を表します。
次のいずれかのインデックスを使用してベクトルを照会します。
IVFFlatインデックス
SELECT id, vector <#> '1,1,1'::pase as distance FROM table_name ORDER BY vector <#> '1,1,1:10:0'::pase ASC LIMIT 10;説明<#> はIVFFlatインデックスで使用される演算子です。
IVFFlatインデックスを有効にするには、ORDER BYステートメントを実行する必要があります。 IVFFlatインデックスは、ベクトルを昇順にソートすることを可能にする。
PASEデータ型では、ベクトルを指定するために3つのパラメーターが必要です。 これらのパラメータはコロン (:) で区切られています。 例えば、
1,1、1:10:0は3つのパラメータを含む。 最初のパラメーターは、クエリするベクトルを指定します。 第2のパラメータは、(0,1000)の値範囲を有するIVFFlatのクエリ効率を指定し、値が大きいほど、クエリ精度は高いが、クエリ性能は低いことを示す。 ビジネス要件に基づいてこのパラメーターを設定することを推奨します。 第3のパラメータは、ベクトル類似度計算方法を指定し、値0はユークリッド距離法を表し、値1はドット積法を表す。 ドット積は内積とも呼ばれます。 ドット積法は、ベクトルの正規化を必要とする。 ドット積の順序は、ユークリッド距離の順序とは逆です。
HNSW
SELECT id, vector <?> '1,1,1'::pase as distance FROM table_name ORDER BY vector <?> '1,1,1:100:0'::pase ASC LIMIT 10;説明<?> は、HNSWインデックスによって使用される演算子です。
HNSWインデックスを有効にするには、ORDER BYステートメントを実行する必要があります。 HNSWインデックスは、ベクトルが昇順にソートされることを可能にする。
PASEデータ型では、ベクトルを指定するために3つのパラメーターが必要です。 これらのパラメータはコロン (:) で区切られています。 例えば、
1,1、1:100:0は3つのパラメータを含む。 最初のパラメーターは、クエリするベクトルを指定します。 第2のパラメータは、(0, ∞)の値範囲を有するHNSWのクエリ効率を指定し、値が大きいほど、クエリ精度は高いが、クエリ性能は低いことを示す。 2番目のパラメーターを40に設定し、ビジネスに最適な値が見つかるまで、値を少しずつ増やしてテストすることをお勧めします。 第3のパラメータは、ベクトル類似度計算方法を指定し、値0はユークリッド距離法を表し、値1はドット積法を表す。 ドット積は内積とも呼ばれます。 ドット積法は、ベクトルの正規化を必要とする。 ドット積の順序は、ユークリッド距離の順序とは逆です。
例
IVFFlatインデックスを使用してベクトルを照会します。
次のステートメントを実行してPASEを作成します。
CREATE EXTENSION pase;テストテーブルを作成し、テーブルにテストデータを挿入します。
次の文を実行してテストテーブルを作成します。
CREATE TABLE vectors_table ( id SERIAL PRIMARY KEY, vector float4[] NOT NULL );テーブルにテストデータを挿入します。
INSERT INTO vectors_table (vector) VALUES ('{1.0, 0.0, 0.0}'), ('{0.0, 1.0, 0.0}'), ('{0.0, 0.0, 1.0}'), ('{0.0, 0.5, 0.0}'), ('{0.0, 0.5, 0.0}'), ('{0.0, 0.6, 0.0}'), ('{0.0, 0.7, 0.0}'), ('{0.0, 0.8, 0.0}'), ('{0.0, 0.0, 0.0}');インデックスを作成するには、IVFFlatアルゴリズムを使用します。
CREATE INDEX ivfflat_idx ON vectors_table USING pase_ivfflat(vector) WITH (clustering_type = 1, distance_type = 0, dimension = 3, base64_encoded = 0, clustering_params = "10,100");IVFFlatインデックスを使用してベクトルを照会します。
SELECT id, vector <#> '1,1,1'::pase as distance FROM vectors_table ORDER BY vector <#> '1,1,1:10:0'::pase ASC LIMIT 10;
付録
ベクトルのドット積を計算します。
この例では、HNSWインデックスを使用して関数を作成します。
CREATE OR REPLACE FUNCTION inner_product_search(query_vector text, ef integer, k integer, table_name text) RETURNS TABLE (id integer, uid text, distance float4) AS $$ BEGIN RETURN QUERY EXECUTE format(' select a.id, a.vector <?> pase(ARRAY[%s], %s, 1) AS distance from (SELECT id, vector FROM %s ORDER BY vector <?> pase(ARRAY[%s], %s, 0) ASC LIMIT %s) a ORDER BY distance DESC;', query_vector, ef, table_name, query_vector, ef, k); END $$ LANGUAGE plpgsql;説明正規化されたベクトルの内積は、その余弦値と同じである。 したがって、この例に従って、ベクトルの余弦値を計算することもできます。
外部セントロイドファイルからIVFFlatインデックスを作成します。
これは高度な機能です。 外部セントロイドファイルをサーバーの指定されたディレクトリにアップロードし、このファイルを使用してIVFFlatインデックスを作成する必要があります。 詳細については、「IVFFlatインデックスのパラメーター」をご参照ください。 このファイルの形式は次のとおりです。
Number of dimensions|Number of centroids|Centroid vector dataset例:
3|2|1,1,1,2,2,2
関連ドキュメント
ハーヴ・ジェーグ、マタイス・ドゥーズ、コーデリア・シュミット。 最近傍検索のためのプロダクト量子化。
効率的で堅牢な近似最近傍検索を使用した階層的ナビゲート可能スモールワールドグラフ
Yu.A.Malkov、D。A。Yashunin。 階層的ナビゲート可能スモールワールドグラフを使用した効率的で堅牢な近似最近傍検索。