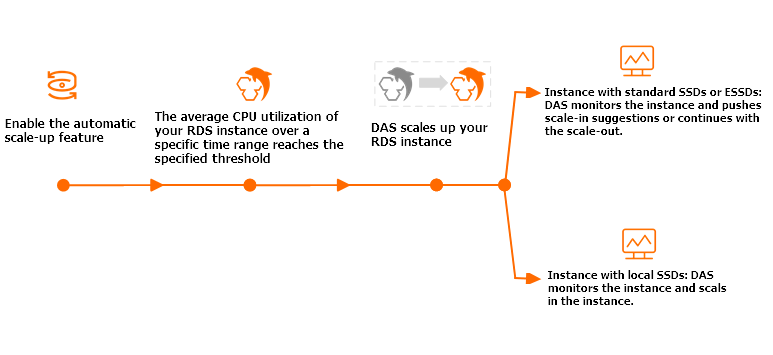
データベースのトラフィックが予期せず急増した場合、手動でインスタンスをスケールアップするには時間がかかります。また、スケールダウンを忘れると、不要になったリソースに対して料金を支払うことになります。Database Autonomy Service (DAS) による性能自動スケーリングは、両方向のスケーリングを自動的に処理します。CPU 使用率が設定したしきい値を超えるとインスタンスはスケールアップし、負荷が減少するとスケールダウンします。
仕組み
スケーリングの動作は、クラウドディスクインスタンスとプレミアムローカルディスクインスタンスで異なります。
クラウドディスクインスタンス (ESSD および高性能ディスク)
[観測ウィンドウ] の間、システムは CPU 使用率を定期的にチェックします。平均 CPU 使用率が [CPU トリガーしきい値] 以上になるたびに、インスタンスは 1 段階スケールアップします。CPU、メモリ、IOPS、最大接続数がすべて同時に増加します。これは、インスタンスが設定した [最大仕様] に達するまで繰り返されます。
スケールダウンは、次の両方の条件が満たされたときにトリガーされます。
インスタンスは[クールダウン期間]中ではありません。
[スケールダウン観測ウィンドウ] (観測ウィンドウ + 10 分) の間、CPU 使用率が 99% 以上の時間、30% 未満であること。
システムは、スケールアップ前の仕様に段階的にスケールダウンします。
設定変更中に最大 30 秒間の一時的な切断が発生する可能性があります。オフピーク時に変更をスケジュールし、アプリケーションに再接続メカニズムがあることを確認してください。
プレミアムローカルディスクインスタンス (汎用)
[スケールアップ観測ウィンドウ] の間、CPU 使用率がしきい値以上になると、CPU コア数が 2 倍になります。追加された CPU コアごとに IOPS が 1,000 増加します。メモリと最大接続数は増加せず、最初の 2 倍化の後にさらなるスケールアップは発生しません。
ホストリソースが不足している場合 (確率 1% 未満)、スケールアップは実行されません。
[スケールダウン観測ウィンドウ] の間に CPU 使用率が 99% 以上の時間 30% 未満を維持すると、スケールダウンがトリガーされます。CPU と IOPS の両方がスケールアップ前のレベルに戻ります。
プレミアムローカルディスクのスケールアップおよびスケールダウン操作は、インスタンスのスイッチオーバーなしで 30 秒以内に完了し、ユーザーへの知覚可能な影響はありません。
前提条件
開始する前に、以下を確認してください。
次のすべてを満たす ApsaraDB RDS for MySQL インスタンス:
課金方法:サブスクリプションまたは従量課金 (サーバーレスインスタンスは自動的にスケーリングするため、設定は不要です)
ストレージクラス:クラウドディスク (汎用または専用) またはプレミアムローカルディスク (汎用)
製品シリーズ:High-availability Edition
インスタンスタイプ:Standard Edition
リージョン:DAS 異常検知機能をサポートしていること
スケールアップにかかる費用をカバーできる十分なアカウント残高
クラウドディスクを使用する廃止されたインスタンスタイプのインスタンスでは、性能自動スケーリングはサポートされていません。この機能を使用するには、まず廃止されたインスタンスタイプを現在のインスタンスタイプに変更してください。
制限事項と副作用
読み取り専用インスタンス
プライマリインスタンスの自動スケールアップ設定は、その読み取り専用インスタンスには適用されません。各読み取り専用インスタンスに対して、個別に自動スケールアップを設定してください。
プライマリ/セカンダリ スイッチオーバー後
スケールアップ操作はプライマリインスタンスでのみ実行されます。スケールアップ後にスイッチオーバーが発生した場合:
新しいプライマリインスタンス (元のセカンダリ) は、トリガー条件を満たすと自動的にスケールアップまたはスケールダウンされます。
新しいセカンダリインスタンス (元のプライマリ) は、スケールダウン条件を満たすと、元の仕様に自動的にスケールダウンされます。
機能を有効にした場合の副作用
インスタンスのマイナーバージョンが最新でない場合、最新バージョンにアップグレードされます。
性能自動スケーリングを有効にすると、AliyunServiceRoleForDAS サービスリンクロールが DAS に付与され、DAS が ApsaraDB リソースにアクセスできるようになります。
課金
クラウドディスクインスタンス (汎用および専用)
スケールアップ後、料金は新しいインスタンスタイプに基づいて計算されます。料金はリージョンと新しい仕様によって異なります。詳細については、購入ページをご参照ください。
プレミアムローカルディスクインスタンス (汎用)
従量課金制で、時間単位で請求されます。
計算式: CPU コアあたりの料金 × 追加された CPU コア数 × スケールアップ期間 (時間)
例: 中国(杭州)のインスタンスには 4 つの CPU コアがあります。スケールアップ後、8 つのコアになります。スケールアップの期間は 30 分です。単位価格は、1 コア時間あたり USD 0.083 です。USD 0.083 / コア時間0.083 (単位価格) × 4 (追加されたコア数) × 0.5 (時間) = USD 0.166
料金 = 0.083 × 4 × 0.5 = USD 0.166
リージョン別の単価 (USD/コア時間)
| リージョン | 単価 |
|---|---|
| 中国 (張家口)、中国 (ウランチャブ) | 0.063 |
| 中国 (香港)、韓国 (ソウル) | 0.134 |
| 日本 (東京) | 0.100 |
| マレーシア (クアラルンプール) | 0.102 |
| シンガポール、インドネシア (ジャカルタ) | 0.155 |
| ドイツ (フランクフルト)、イギリス (ロンドン) | 0.078 |
| 米国 (バージニア)、米国 (シリコンバレー) | 0.129 |
| UAE (ドバイ) | 0.091 |
| その他のリージョン | 0.083 |
性能自動スケーリングの有効化
クラウドディスクインスタンス
RDS インスタンスページに移動します。左上の隅でインスタンスが配置されているリージョンを選択し、インスタンス ID をクリックします。
[設定情報] セクションで、[性能自動スケーリング] の横にある [設定] をクリックします。
ダイアログボックスで、次のパラメーターを設定し、[OK] をクリックします。
| パラメーター | 説明 |
|---|---|
| 性能自動スケーリング | スイッチをオンにして機能を有効にします。 |
| 観測ウィンドウ | システムが CPU 使用率をチェックする期間です。[スケールダウン観測ウィンドウ] は、この値に 10 分を加えたものと等しくなります。たとえば、これを 30 分に設定した場合、スケールダウン観測期間は 40 分になります。 |
| CPU トリガーしきい値 | 自動スケールアップをトリガーする平均 CPU 使用率です。CPU 使用率がこの値以上になると、スケールアップがトリガーされます。 |
| 最大仕様 | 自動スケールアップの上限です。現在のインスタンス仕様より大きい必要があります。現在の仕様は設定に表示されます。 |
| クールダウン期間 | 2 回連続するスケールアップまたはスケールダウン操作の間の最小間隔です。DAS はクールダウン期間中もモニタリングを続けますが、スケーリングはトリガーしません。クールダウン期間と観測ウィンドウが同時に終了し、CPU 使用率がしきい値に達した場合、DAS は両方の期間が終了したときにスケーリングをトリガーします。 |
| 自動的に取り消す | 有効にすると、インスタンスがクールダウン期間を終了し、スケールダウン観測ウィンドウ中に CPU 使用率が 99% 以上の時間 30% 未満を維持すると、システムはスケールアップ前の仕様に段階的にインスタンスをスケールダウンします。 |
自動スケールダウン機能は、新しいアーキテクチャ (kindcode=18) バージョンでのみ安定して実行されることが保証されています。DescribeDBInstanceAttribute を実行して、インスタンスのアーキテクチャバージョンを確認してください。
プレミアムローカルディスクインスタンス
RDS インスタンスページに移動します。左上の隅でインスタンスが配置されているリージョンを選択し、インスタンス ID をクリックします。
ダイアログボックスで、次のパラメーターを設定し、[OK] をクリックします。
| パラメーター | 説明 |
|---|---|
| 性能自動スケーリング | スイッチをオンにして機能を有効にします。 |
| スケールアップ観測ウィンドウ | システムが CPU 使用率をチェックしてスケールアップをトリガーするかどうかを判断する期間です。 |
| CPU トリガーしきい値 | 自動スケールアップをトリガーする平均 CPU 使用率です。CPU 使用率がこの値以上になると、スケールアップがトリガーされます。 |
| スケールダウン観測ウィンドウ | システムが CPU 使用率をチェックしてスケールダウンをトリガーするかどうかを判断する期間です。この期間の 99% 以上で CPU 使用率が 30% 未満を維持した場合、スケールダウンがトリガーされます。 |
よくある質問
インスタンスがそのシリーズの上限に達した場合はどうすればよいですか?
より高い仕様のシリーズからインスタンスを購入します。次に、DTS を使用して新しいインスタンスにデータを移行します。
スケールアップ中、インスタンスは継続的にモニタリングされますか?
はい。たとえば、[観測ウィンドウ] が 5 分で、スケールアップに 10 分かかる場合、合計経過時間は 15 分です。スケールアップ中、システムはインスタンスをモニタリングしますが、現在のスケールアップが完了するまで別のスケールアップはトリガーしません。スケールアップが完了した後、[観測ウィンドウ] 内の CPU 使用率が依然としてしきい値を満たしている場合、別のスケールアップがトリガーされます。これは、インスタンスが [最大仕様] に達するまで繰り返されます。
次のステップ
自動スケーリングがニーズを満たさない場合は、インスタンスを手動でスケーリングします。詳細については、「インスタンス仕様の変更」をご参照ください。
トラフィックのピークが予測可能な時間に発生する場合は、スケジュールされた自動スケーリングを使用して、事前に設定した時間にスケールアウトし、ピークが終了すると自動的に元のインスタンスタイプに復元します。