このトピックでは、データセットの作成時に発生する一般的な問題をまとめています。
データセットエラーの問題
データセット作成の問題
データセットフィールドの処理に関する問題
データセット権限の問題
データセット表示の問題
データセットの関連付けに関する問題
データセットのパフォーマンスの問題
カスタム SQL エラー
カスタム SQL の実行または保存中にエラーが発生した場合は、次の一般的な問題を確認してください。
1. カスタム SQL 構文が正しくない
Quick BI は、データベースによって実行される前に、カスタム SQL を部分的に処理します。この前処理には、プレースホルダーの解析、limit 文による行制限の適用、SQL コメントの挿入が含まれます。その結果、カスタム SQL 構文が正しくない場合、基になるデータベースからエラーが発生する可能性があります。
カスタム SQL エラーのトラブルシューティングを行うには、SQL 文をデータベースで直接実行して、構文の問題がないか確認してください。以前に実行された SQL 文は、「履歴」で確認できます。
2. SELECT 文の前に他の文が記述されている
大量のデータによるパフォーマンスの問題を防ぐため、Quick BI は実行時および保存時にカスタム SQL に 'limit 200' 句を追加します。したがって、カスタム SQL は SELECT 文で始める必要があります。HINT 文は SELECT 文の直前に記述することはできません。記述するとエラーが発生します。
HINT 文を使用するには、[HINT 文の設定] オプションを使用して設定してください。
HINT 文をサポートするデータソースの一覧については、データソース関数項目リスト をご参照ください。
3. デフォルト値なしでプレースホルダーが使用されている
Quick BI のカスタム SQL では、プレースホルダーを介してパラメーターを渡すことができます。レポートを表示する際に、プレースホルダーを使用すると、クエリ コントロールを介して基になる SQL に値を渡すことで、動的データ分析が可能になります。使用シナリオと方法については、ドキュメント「プレースホルダー」をご参照ください。
不完全な SQL と実行エラーを回避するには、SELECT 文で使用されるプレースホルダーにデフォルト値を設定する必要があります。
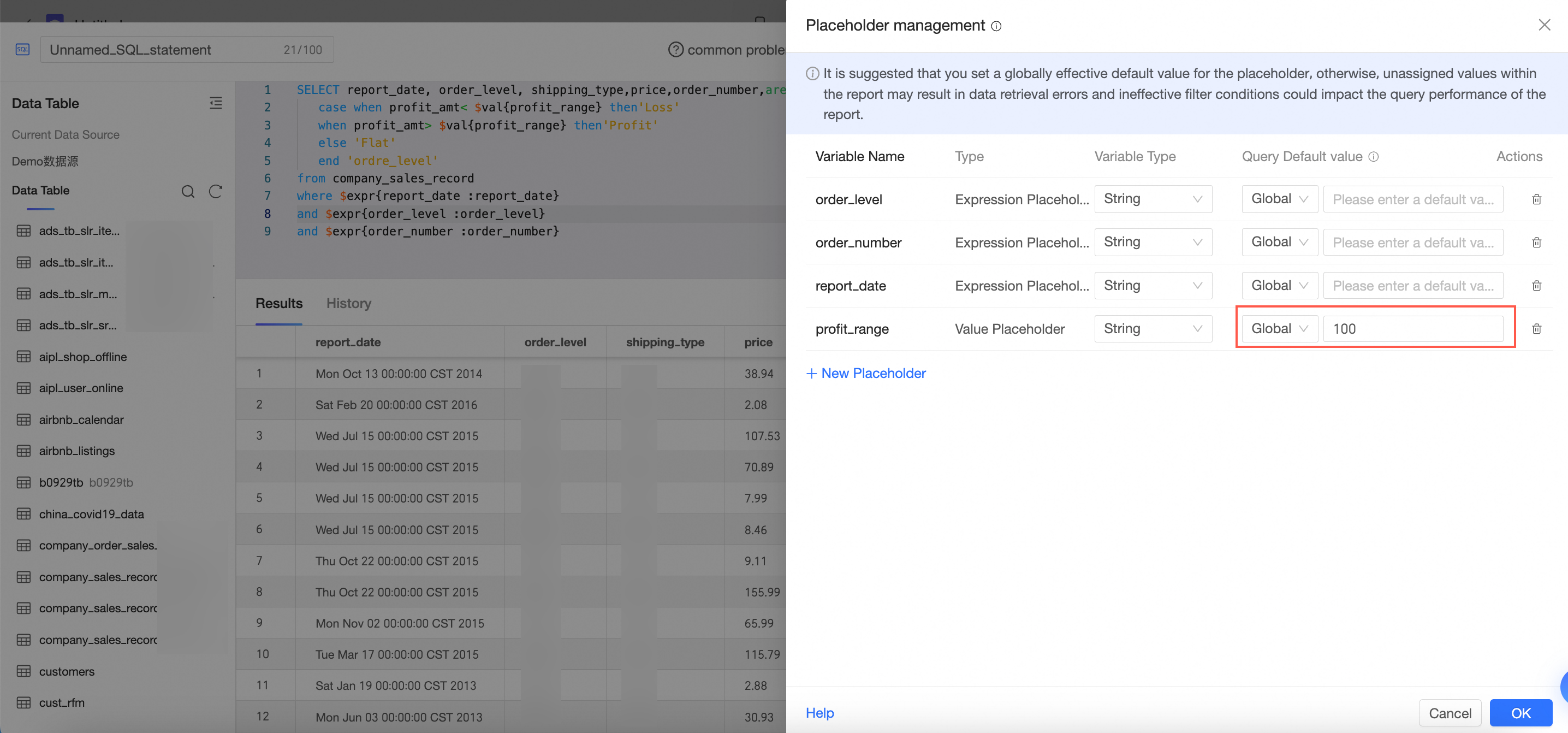
たとえば、以下の例では、プレースホルダー $val{profit_range} にデフォルト値がない場合、「注文レベル」を計算できず、カスタム SQL エラーが発生します。プレースホルダーにデフォルト値 100 を割り当てると、SQL は正しく実行され、データが表示されます。
割り当てられていないプレースホルダーによるレポートエラーを防ぐには、SELECT 文の後で、プレースホルダーに「データセットのみ」に有効なデフォルト値ではなく、「グローバルに有効」なデフォルト値を設定することをお勧めします。
SELECT report_date, order_level, shipping_type,price,order_number,area,
case when profit_amt< $val{profit_range} then'Loss' /* 損失 */
when profit_amt> $val{profit_range} then'Profit' /* 利益 */
else 'Flat' /* 横ばい */
end 'order_level' /* 注文レベル */
from company_sales_record /* 会社売上レコード */
where $expr{report_date :report_date} /* レポート日付 */
and $expr{order_level :order_level} /* 注文レベル */
and $expr{order_number :order_number} /* 注文番号 */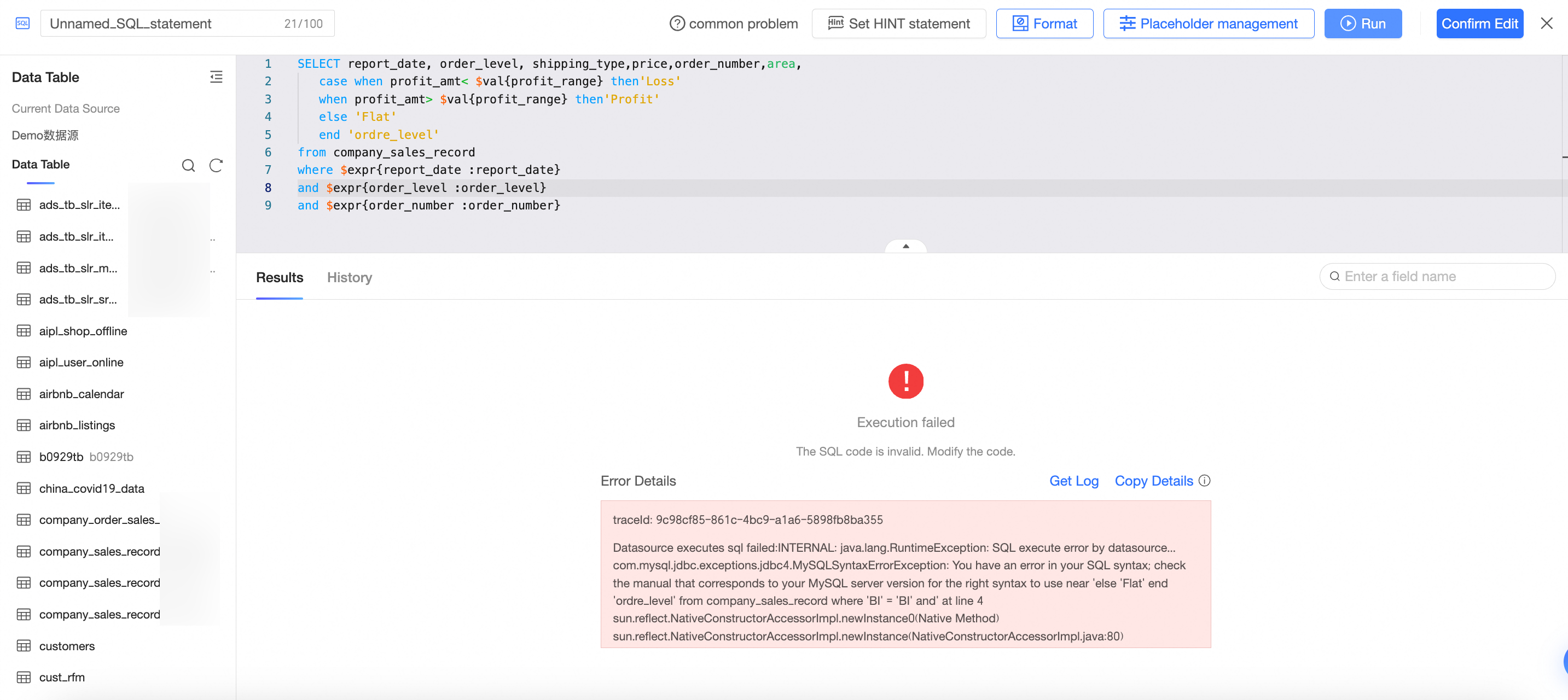
4. その他
基になるデータベースから返される特殊なフィールド名、またはプレースホルダーの解析の問題によって発生する可能性のあるエラーを回避するために、カスタム SQL でコメントとエイリアスの使用を標準化することをお勧めします。
また、カスタム SQL の末尾にセミコロン「;」を追加する必要はありません。
計算フィールドのエラーの一般的な原因
計算フィールドは物理フィールドを参照します。フィールドタイプを変換するには、適切な変換関数を使用する必要があります。フィールドタイプを手動で変更しても、基になる物理フィールドタイプは変更されません。そのため、タイプの不一致によりエラーが発生する可能性があります。
ディメンション計算フィールドでは、SUM や AVG などの集計関数を使用できません。集計計算を実行するには、メジャーとして保存する必要があります。
テキストタイプのフィールドは、集計に COUNT と COUNTD のみを使用できます。SUM や MAX などの集計関数とは互換性がありません。集計計算を実行する前に、これらのフィールドを数値タイプに変換してください。
ローカルファイルを使用してデータセットを作成する場合、どのような問題に注意する必要がありますか?
アップロードされたローカルファイルを使用してデータセットを作成する場合は、アップロードされたデータソースのデータベース構文に従う必要があります。ファイルが探索スペースにアップロードされている場合は、データセットの作成時および使用時に ClickHouse データベース構文に従う必要があります。
探索スペースにファイルをアップロードする場合、カスタム SQL を使用したデータセットの作成はサポートされていません。探索スペースにファイルをアップロードする場合、データセット作成のためのクロスソース関連付けもサポートされていません。クロスソース関連付けを使用してデータセットを作成する必要がある場合は、クロスソース関連付けをサポートするグループ ワークスペース データソースにファイルをアップロードできます。ファイルがデータベース データソースにアップロードされ、カスタム SQL を使用してデータセットを作成する場合は、ファイルのアップロード後にデータベースで自動的に生成される物理テーブル名を使用する必要があります。アップロードされたファイル名ではありません。アップロードされたファイルに対応する物理テーブル名を表示するには、データソースのアップロードファイル一覧でファイルの設定ボタンをクリックし、ファイルアップロード変更ページに入り、物理テーブル名情報を表示します。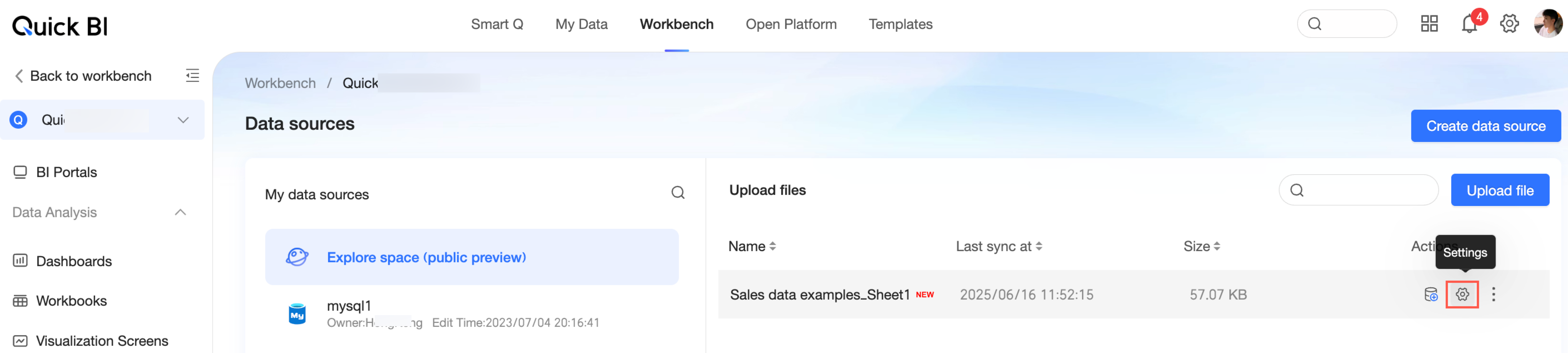
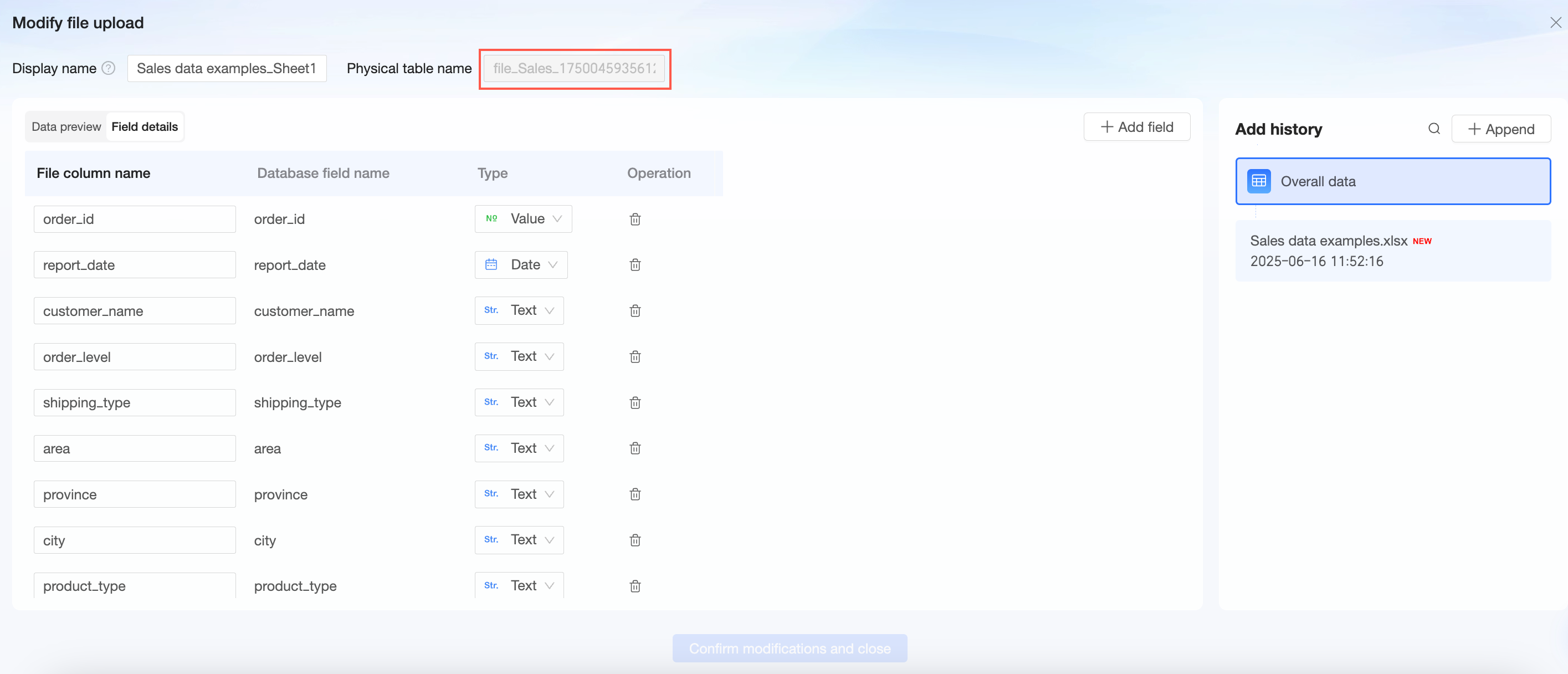
UNIX タイムスタンプタイプのフィールドを標準の日時タイプのフィールドに変換する方法
時間フィールドが UNIX タイムスタンプとして保存されていて、[データ型] が [テキスト] または [数値] に設定されている場合は、from_unixtime 関数を使用して変換する必要があります。
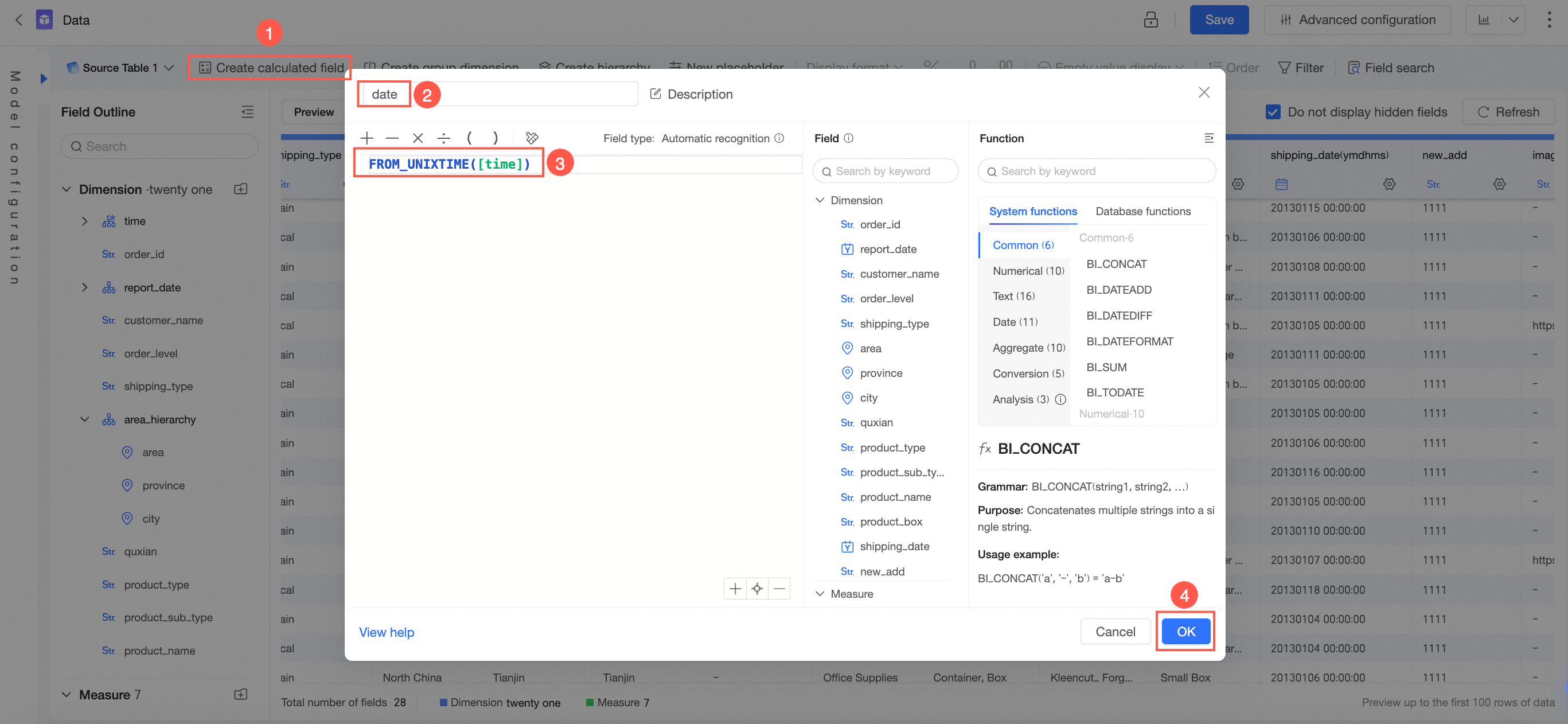
画像に示されている手順に従って、データセット編集ページで計算フィールドを作成します。
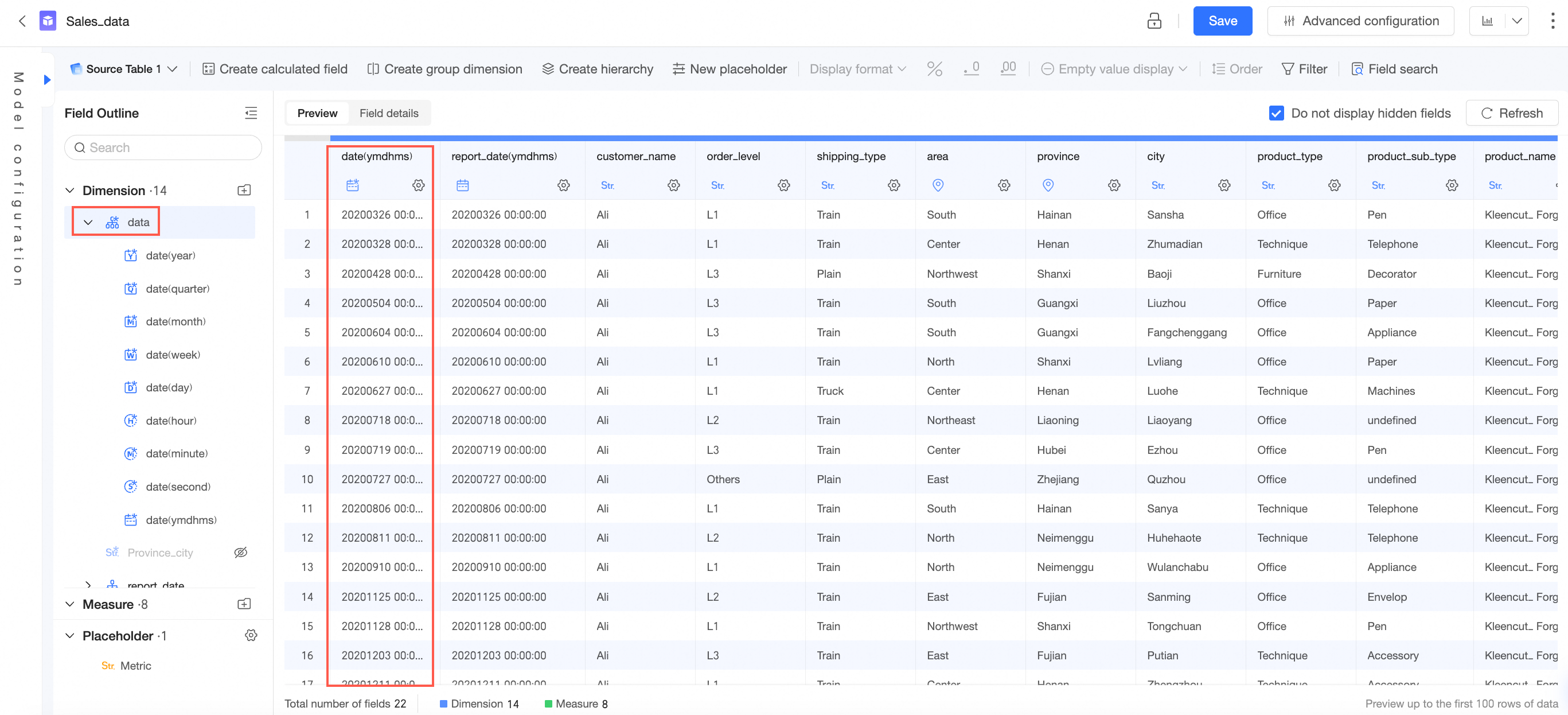
データセットを保存した後、以下に示すようにリフレッシュします。
ダッシュボードに表示される Null 値または空の値を設定する方法
1. データセット内で空の値の表示スタイルを設定します。
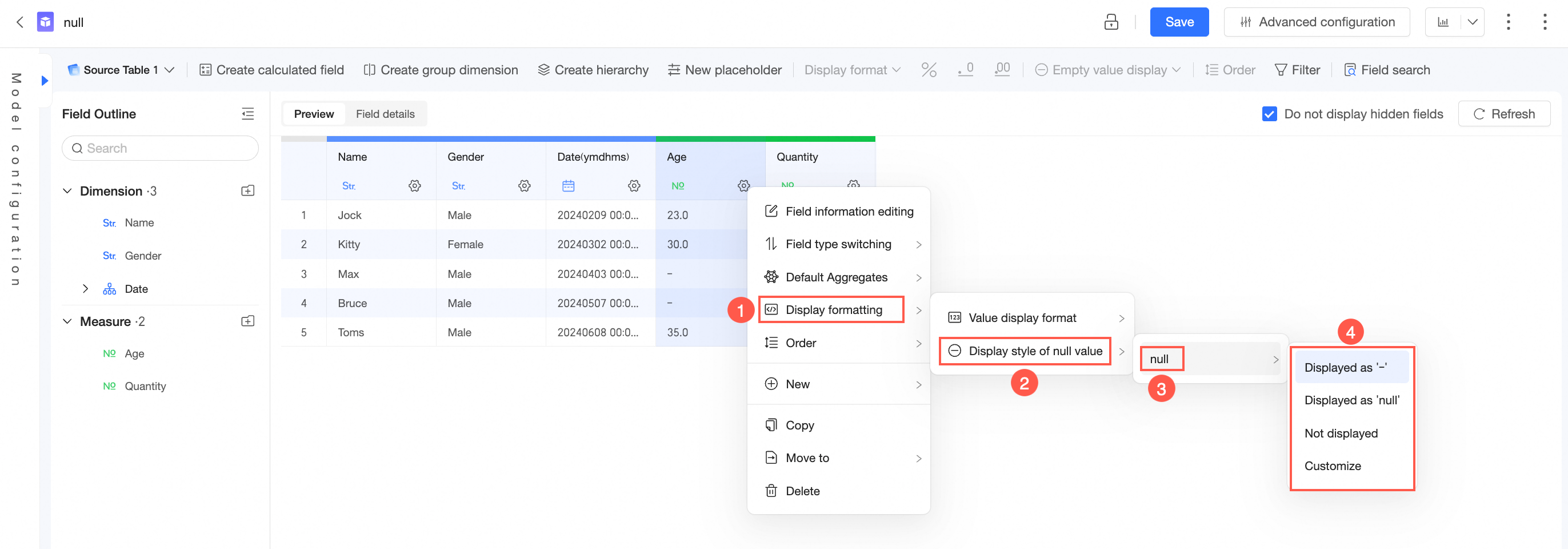
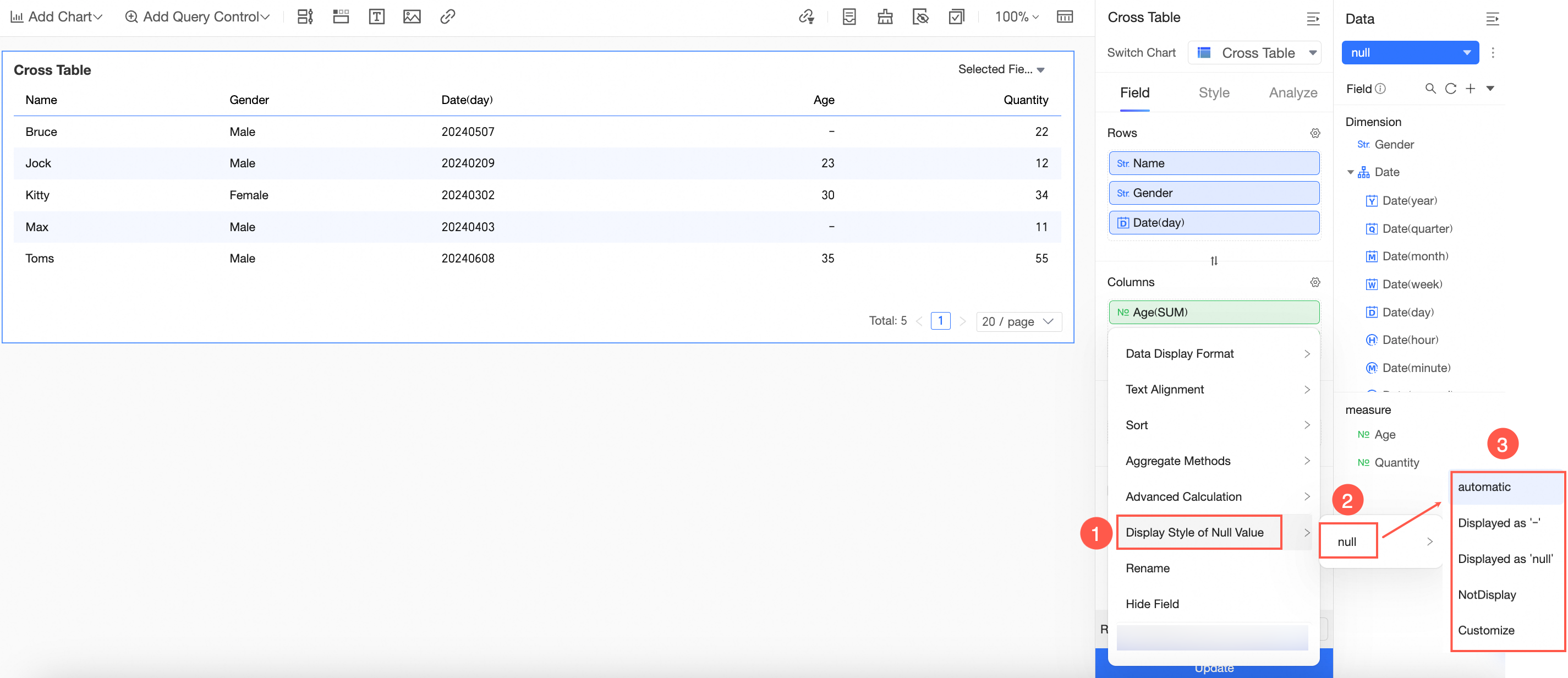
2. ダッシュボード自体で空の値の表示スタイルを設定します。
パラメーター SQL を使用して比率の柔軟な計算を実現する方法
Quick BI は現在、比率の直接計算をネイティブでサポートしていません。ただし、パラメーター化された SQL を使用して、この目的のためのデータセットを構築できます。
日付、都道府県、市区町村、売上高という構造のテーブルを考えてみましょう。各都道府県内の市区町村別の売上高比率を計算するには、次の手順を実行する必要があります。1. 市区町村ディメンションで集計する。2. 任意の日付範囲を選択できるようにし、都道府県と市区町村の複数選択を有効にする。
以下は、パラメーター化された SQL を使用してデータセットモデルを構築する方法の例です。
select a.city,sum(fenzi)/sum(fenmu) as ratio
from
(select province,city,sum(order_amt) fenzi
from zhanbi_test
where $expr{date:date_para}
and $expr{province:province_para}
and $expr{city:city_para}
group by province,city
)a
left join
(select province,sum(order_amt) fenmu
from zhanbi_test
where $expr{date:date_para}
and $expr{province:province_para}
and $expr{city:city_para}
group by province
)b on a.province=b.province提供されている SQL の例では、市区町村フィールドでデータが集計されていますが、同様の集計を他のフィールドにも適用できます。このパラメーター化された形式で SQL を使用する場合、データセットのパラメーター設定内で日付フィールドを日付タイプに変換して、データセットを正常に作成し、ダッシュボードで視覚化できるようにしてください。
パラメーター SQL を使用して累積計算を実現する方法
設定オプションでは現在、今年、前年、月次、四半期、カスタム期間など、さまざまな累積計算がサポートされています。データセットが会計年度で設定されていて、日付フィールドが会計年度に対応している場合、日次粒度では会計年度と会計四半期にわたる累積計算が可能です。詳細については、「日付累積」をご参照ください。
構成するには、以下に示すように、ディメンション内で日付タイプの 日 フィールドを選択します。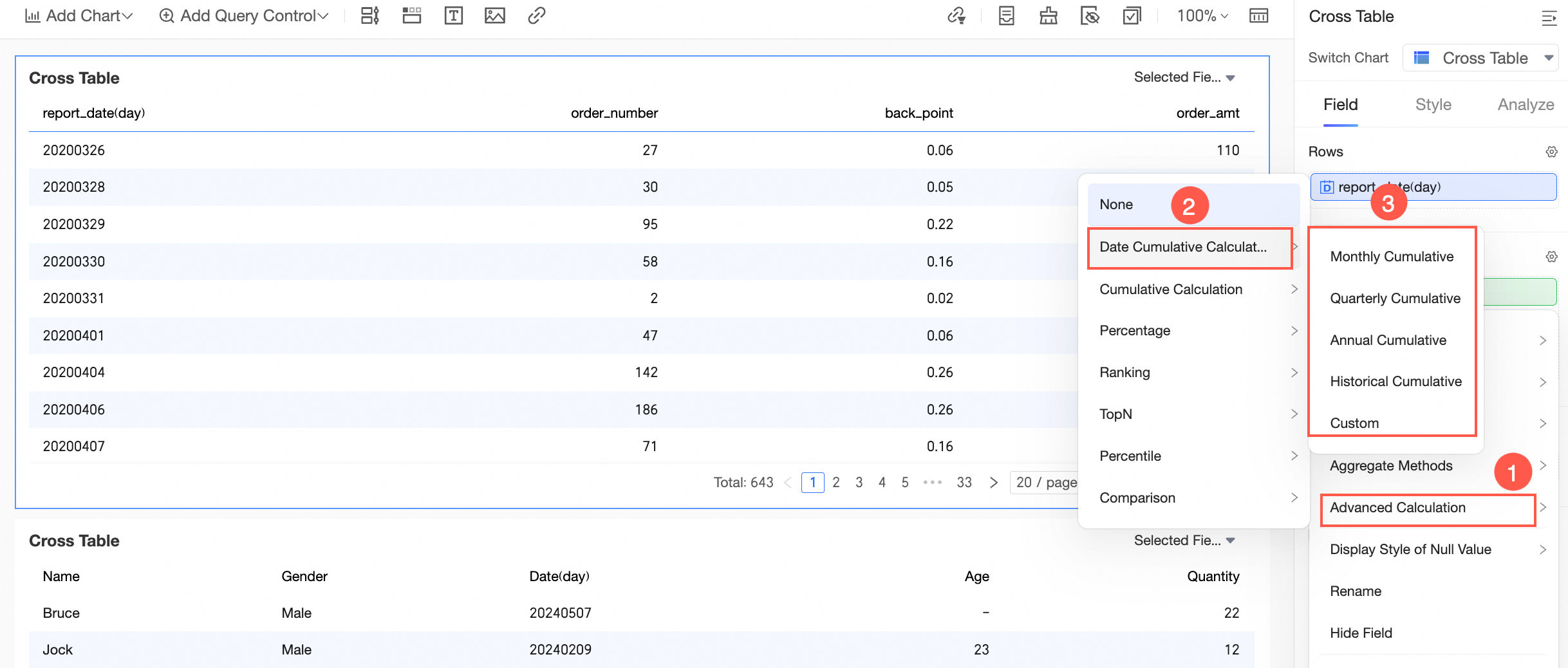
任意の期間を選択し、各期間の指定された開始日からの累積値を計算するには、パラメーター化された SQL が必要です。以下は、月次累積計算の参照文です。
select a.mon_date,avg(a.order_num) order_num,sum(b.order_num) add_num
from (
select date_format(report_date,'%Y/%m') mon_date,count(distinct order_id) order_num,max(date_format(report_date,'%Y/%m')) max_mon_date
from company_sales_record_copy
where $expr{report_date:month_date}
group by date_format(report_date,'%Y/%m')
)a
left join(
select date_format(report_date,'%Y/%m') mon_date,count(distinct order_id) order_num
from company_sales_record_copy
where $expr{report_date:month_date}
group by date_format(report_date,'%Y/%m')
)b on a.max_mon_date>=b.mon_date
group by a.mon_date この設定では、ダッシュボードのクエリ条件がパラメーターフィールドにリンクされている限り、異なる月の範囲をフィルタリングすることで、選択した月から始まる各月の累積値を取得できます。
パラメーター SQL を使用して単一の日付を入力することで過去 n 日間のデータをクエリする方法
Quick BI では、デフォルトの動作では、単一の日付を入力して、その特定の日付のデータを表示します。一定期間のデータを表示するには、期間の開始日と終了日を入力する必要があります。ただし、2 つのチャートでデータを異なる方法でフィルタリングする必要がある場合 (たとえば、一方のチャートには特定の日のデータが表示され、もう一方のチャートにはその日から始まる過去 3 日間のデータが表示される場合) は、パラメーター SQL を使用してこれを実現できます。以下は、参照用の SQL の例です。
select report_date,area,product_type,count(distinct order_id) order_num
from company_sales_record
where area in ('西南','西北','华北')
and ( $expr{dateadd(report_date,1,'dd'):date1}
or $expr{dateadd(report_date,2,'dd'):date1}
or $expr{dateadd(report_date,3,'dd'):date1})
group by area,product_type,report_date行レベル権限はサポートされていますか?
はい、サポートされています。詳細については、「行レベル権限」をご参照ください。
データセットはデフォルトで何行のデータを表示しますか?
デフォルトでは、データセットは 100 行のデータを表示します。
データセットはページングをサポートしていますか?
サポートされていません。
新しいフィールドが右側に表示されないのはなぜですか?
集計計算フィールドは、データプレビュー中には表示されません。
地図チャートに地理データを適用する方法
データセット編集ページでは、ディメンションタイプ切り替え機能を使用して、地理データを対応する地理情報に変換できます。
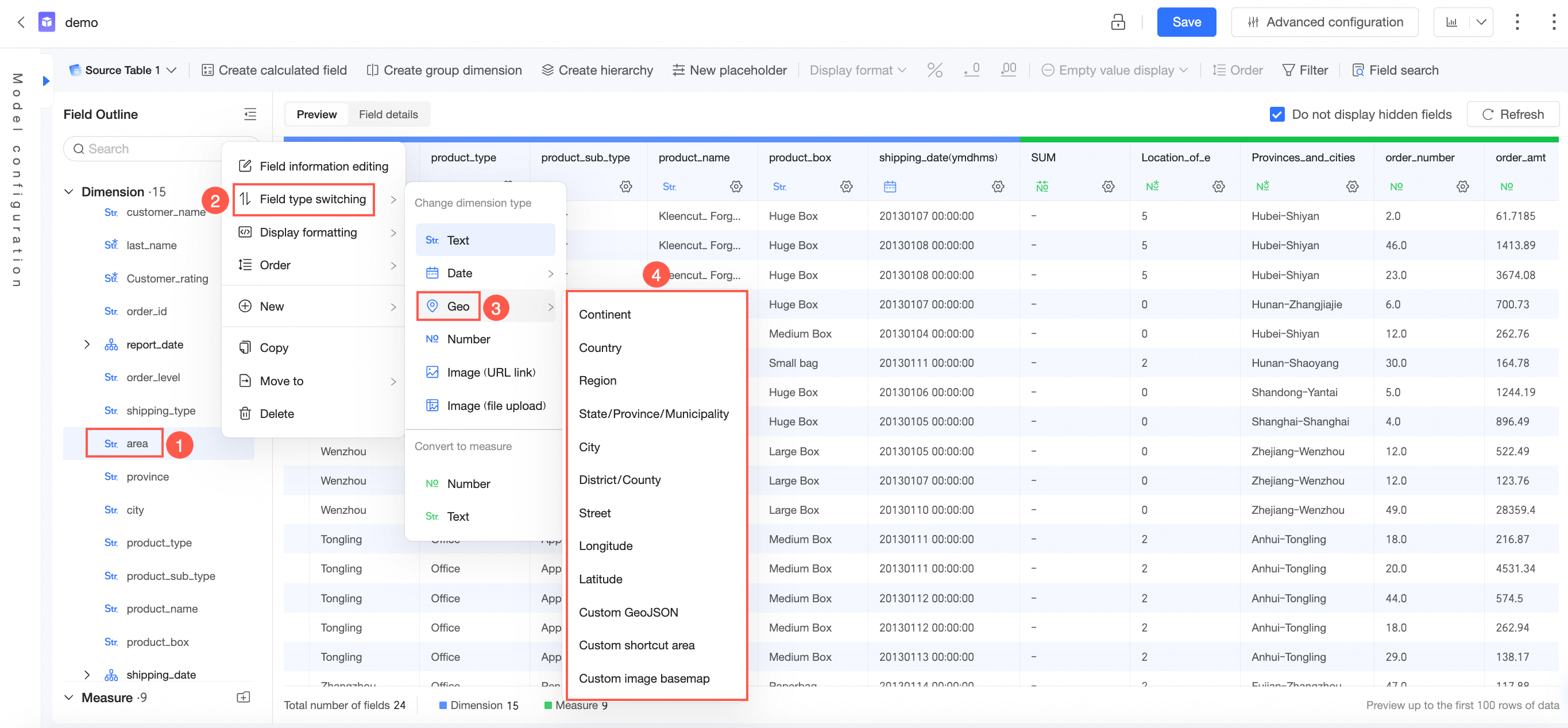
詳細については、「データセットの作成と管理」をご参照ください。
説明をフィールド名として使用する方法
ワークスペース設定では、データセットを作成するときに、テーブル名または説明をフィールド名として使用することを選択できます。
また、データセットの作成中に、[一括設定] タブで複数のフィールドを選択し、[説明をフィールド名として使用する] を選択することもできます。
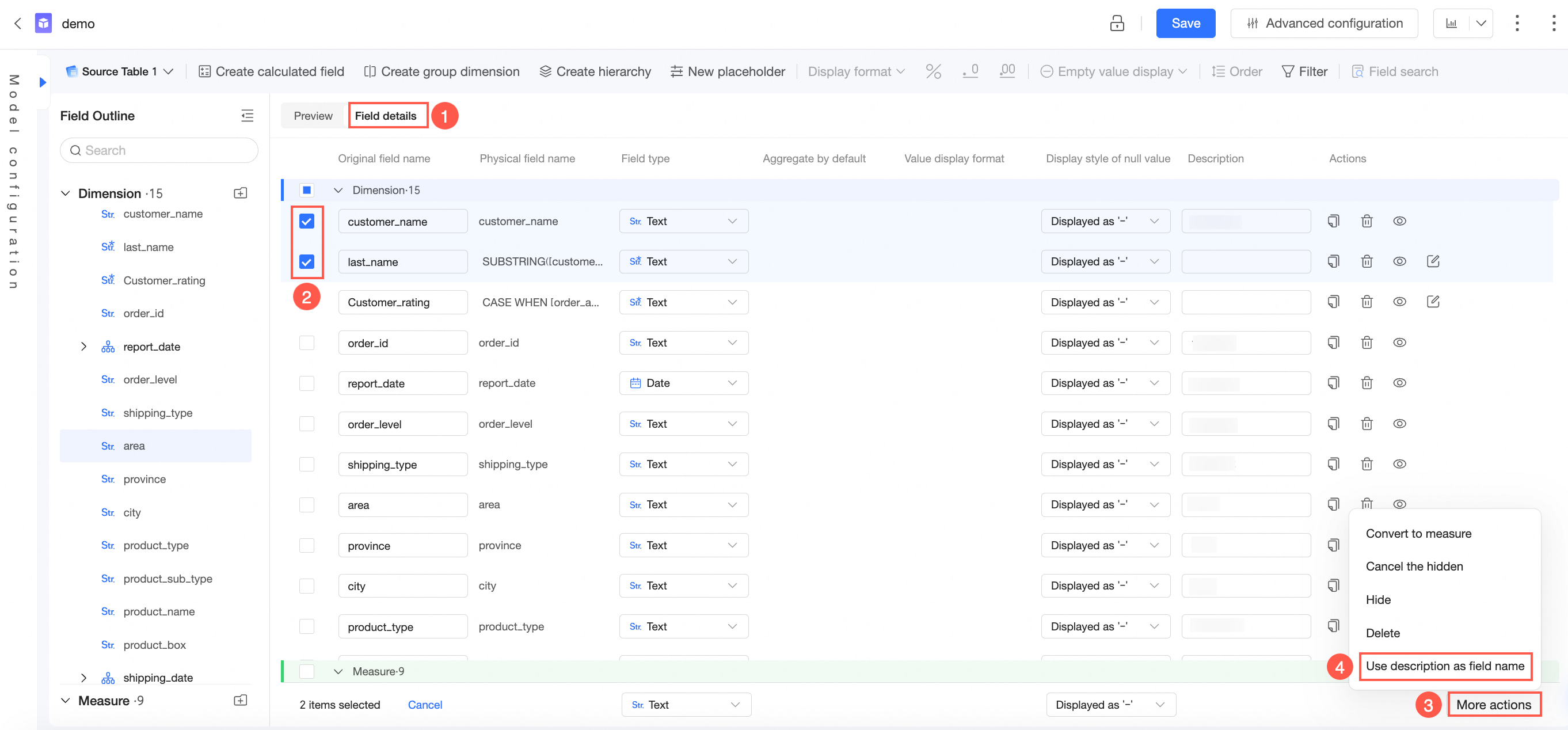
注: フィールドの説明が空の場合、フィールド名として使用することはできません。
データセットがカスタム SQL を使用して作成されている場合、データセットのフィールド名として表示するには、カスタム SQL 文でフィールドにエイリアスを設定する必要があります。
物理テーブルのフィールドが変更されたときにデータセットをすばやく更新する方法
物理フィールドが見つからない場合でも、分析に使用されたり、ダッシュボードに表示されたりする可能性があります。Quick BI はフィールドを自動的に削除しません。キャンバスでテーブルを選択し、右側のパネルでフィールドの変更を確認し、無効なフィールドを 1 回クリックするだけで削除できます。
2 つのデータベースからデータセットを作成する方法
2 つの異なるデータベースからデータテーブルをキャンバスにドラッグし、それらの関連付け関係を設定できます。Quick エンジンによって処理されると、期待どおりに機能します。Quick エンジン抽出アクセラレーションと互換性のあるデータソースの一覧については、「データソース関数項目リスト」をご参照ください。
データセットを別のワークスペースにコピーする方法
クロススペースデータセットコピー機能を使用して、データセットを別のワークスペースにコピーできます。詳細については、「クロススペースコピーデータセット」をご参照ください。
複数テーブルの関連付け分析を実現するために関連付けモデルを設定する方法
詳細については、「モデルの構築」をご参照ください。
関連付けモデルの構成は、SQL での Join 文の使用に似ています。データセット編集ページで関連付けモデルを設定できます。詳細については、「モデルの構築」をご参照ください。
データセットのクエリ結果キャッシュを有効にすることの利点
データセットのキャッシュを有効にすることで、レポートアクセスを高速化し、データベースクエリを最小限に抑えることができます。たとえば、データセットのキャッシュが有効になっていて、ユーザーがそのデータセットから派生したレポートでクエリを実行すると、結果のデータはキャッシュに保存されます。その後、他のユーザーがキャッシュの指定された期間内に同じレポートにアクセスした場合、Quick BI はデータベースを再クエリすることなく、すぐにデータを表示できます。
SQL データセットのクエリ時間が長すぎる場合の最適化方法
1. インデックスを効果的に使用するために SQL ロジックを改良するか、データベース内にビューを設定して複雑な結合を回避し、クエリ実行を高速化します。
2. 広範なデータセットを処理する場合に全表スキャンを防ぐために、SQL プレースホルダーにグローバルデフォルト値を設定します。