このトピックでは、Managed Service for Prometheusを使用してApsaraMQ for KafkaインスタンスとセルフマネージドKafkaクラスターを監視する方法について説明します。
セルフマネージドPrometheusサービスを使用してApsaraMQ for KafkaインスタンスとセルフマネージドKafkaクラスターを監視する場合の課題
セルフマネージドPrometheusサービスを使用してApsaraMQ for KafkaインスタンスとセルフマネージドKafkaクラスターを監視する場合、以下の課題に対処する必要がある場合があります。
セキュリティを確保し、組織管理を容易にするために、ビジネスを個別の仮想プライベートクラウド(VPC)にデプロイする可能性があります。セルフマネージドPrometheusサービスを使用してビジネスを監視する場合、各VPCにPrometheusサービスをデプロイする必要があります。これにより、デプロイコストとO&Mコストが増加します。
独立したセルフマネージド監視システムごとにPrometheus、Grafana、およびAlertmanagerを設定する必要があります。これは複雑であり、完了までに長い時間がかかります。
場合によっては、オープンソースのApache KafkaのJMXエージェントが大量のCPUリソースを消費します。これは、セルフマネージドKafkaクラスターにいくつかの影響を与えます。
セルフマネージドPrometheusサービスを使用してApsaraMQ for Kafkaインスタンスを監視することはできません。その結果、メッセージングクラスターを一元的に監視することはできません。
セルフマネージドKafkaクラスターがElastic Compute Service(ECS)インスタンスにデプロイされている場合、セルフマネージドPrometheusサービスは、サービスディスカバリーメカニズムがないため、ECSタグに基づいてターゲットを柔軟に定義およびキャプチャできません。同様のメカニズムを実装するには、Golangでコードを記述してAlibaba Cloud ECSのPOP APIを呼び出し、オープンソースのPrometheusサービスを統合する必要があります。次に、コードをコンパイルしてパッケージ化し、オープンソースのPrometheusサービスをデプロイする必要があります。このプロセスは複雑であり、バージョンのアップグレードに大きな問題を引き起こします。
一般的に使用されるオープンソースのGrafanaダッシュボードでは、Apache Kafkaの原則とベストプラクティスに基づいて監視メトリックをカスタマイズすることはできません。
Apache Kafkaを監視するためのアラートテンプレートはありません。アラートルールを自分で設定する必要があります。このプロセスには人手が必要であり、高い技術的要件があります。
セルフマネージドPrometheusサービスとManaged Service for Prometheusの比較
次の表は、ApsaraMQ for KafkaインスタンスとセルフマネージドKafkaクラスターの監視におけるセルフマネージドPrometheusサービスとManaged Service for Prometheusを比較したものです。
項目 | セルフマネージドPrometheusサービス | Managed Service for Prometheus |
デプロイコストとO&Mコスト | 複数のVPCにPrometheus、Grafana、およびAlertmanagerをデプロイするためにECSインスタンスを購入する必要があります。これにより、高いO&Mコストが発生します。 | Managed Service for Prometheusは、すぐに使用できるフルマネージドサービスであり、Prometheus、Grafana、およびAlertmanagerを統合しています。 |
可用性、パフォーマンス、およびストレージ容量 | 全体的なパフォーマンスと高可用性のパフォーマンスは低く、ストレージ容量は小さくなります。 | 全体的なパフォーマンスと高可用性のパフォーマンスは高く、ストレージ容量は大きくなります。 |
エクスポーターのパフォーマンス | 場合によっては、オープンソースのApache KafkaのJMXエージェントが大量のCPUリソースを消費します。これは、セルフマネージドKafkaクラスターにいくつかの影響を与えます。 | Managed Service for Prometheusは、オープンソースのApache KafkaのJMXエージェントのパフォーマンスを継続的に最適化し、安定性を向上させます。 |
サービスディスカバリー | ECSインスタンスのサービスディスカバリーは、オープンソースの静的構成またはサードパーティのサービスレジストリを使用して実行されます。サービスディスカバリープロセスは複雑であり、O&Mコストが高くなります。 | Managed Service for Prometheusは、オープンソースのサービスディスカバリー機能と互換性があり、aliyun_sd_configsを提供します。KubernetesサービスディスカバリーのLabelSelectorと同様に、ECSタグを使用してターゲットECSインスタンスを識別できます。これにより、サービスディスカバリーの設定とO&Mが簡素化されます。 |
Grafanaダッシュボード | Grafanaダッシュボードには、収集されたメトリックのみが表示されます。Apache Kafkaの原則とベストプラクティスに基づいて監視メトリックをカスタマイズすることはできません。 | Managed Service for Prometheusは、Apache Kafkaを監視するための専門的なダッシュボードテンプレートを提供します。ダッシュボードを使用して、Apache Kafkaプロセス全体の実行状態を迅速かつ正確に把握し、問題をトラブルシューティングできます。 |
アラートルール | Apache Kafkaを監視するためのアラートテンプレートはありません。アラートルールを設定する必要があります。 | Managed Service for Prometheusは、Apache Kafkaの監視のベストプラクティスに基づいて、専門的で柔軟なアラートメトリックテンプレートを提供します。GUIでアラートルールを設定できます。 |
統合サービス | セルフマネージドPrometheusサービスは複数のVPCにデプロイされており、サービスを使用してApsaraMQ for Kafkaインスタンスを監視することはできません。その結果、メッセージングクラスターを一元的に監視することはできません。 | Managed Service for Prometheusは、ApsaraMQ for Kafkaに統合されたフルマネージドサービスです。ApsaraMQ for Kafkaは、ネイティブの全体的な監視システムを提供します。 |
Managed Service for Prometheusを使用してApsaraMQ for Kafkaを監視する
Managed Service for PrometheusはApsaraMQ for Kafkaに統合されています。主なメトリックは次のとおりです。
インスタンス、グループ、およびトピックのトラフィック
グループおよびトピックのメッセージの蓄積
インスタンスのディスク使用量
グループのリバランスメトリック
ApsaraMQ for Kafkaダッシュボードを表示する
ApsaraMQ for Kafkaは、インスタンス、グループ、およびトピックの3つの監視ダッシュボードを提供します。ダッシュボードのデータを表示して、メッセージの生成と消費を理解し、問題を迅速に特定できます。
インスタンスダッシュボード
ApsaraMQ for Kafkaコンソールにログオンします。左側のナビゲーションペインで、インスタンスリストをクリックします。
表示するApsaraMQ for Kafkaインスタンスの名前をクリックします。左側のナビゲーションペインで、Prometheusモニタリングをクリックして、インスタンスの監視データを表示します。
コンシューマーグループダッシュボード
ApsaraMQ for Kafkaコンソールにログオンします。左側のナビゲーションペインで、インスタンスリストをクリックします。
表示するApsaraMQ for Kafkaインスタンスの名前をクリックします。左側のナビゲーションペインで、グループをクリックします。表示されるページで、表示するグループのIDをクリックし、Prometheusモニタリングタブをクリックして、グループの監視データを表示します。
トピックダッシュボード
ApsaraMQ for Kafkaコンソールにログオンします。左側のナビゲーションペインで、インスタンスリストをクリックします。
表示するApsaraMQ for Kafkaインスタンスの名前をクリックします。左側のナビゲーションペインで、トピックをクリックします。表示されるページで、表示するトピックの名前をクリックし、Prometheusモニタリングタブをクリックして、トピックの監視データを表示します。
Managed Service for Prometheusを使用してApsaraMQ for Kafkaのアラートルールを設定する
Managed Service for Prometheusコンソールにログオンします。
左側のナビゲーションペインで、インスタンスをクリックします。
管理するPrometheusインスタンスインスタンスの名前をクリックして、統合センターページに移動します。
インストール済みセクションのApsaraMQ for Kafkaカードをクリックします。表示されるパネルで、アラートタブをクリックして、ApsaraMQ for KafkaのPrometheusアラートを表示します。Managed Service for Prometheusは、ApsaraMQ for Kafkaのインスタンス、グループ、およびトピックの主要なアラートメトリックを提供します。ビジネス要件に基づいてアラートルールを追加できます。詳細については、Prometheusインスタンスのアラートルールを作成するを参照してください。
Managed Service for Prometheusを使用してセルフマネージドKafkaクラスターを監視する
Managed Service for Prometheusを使用して、ECS環境またはコンテナサービス環境(Container Service for Kubernetes(ACK)、Serverless Kubernetes(ASK)、登録済みクラスターなど)にデプロイされたセルフマネージドKafkaクラスターを監視することもできます。ブローカーの数、トピックパーティション、メッセージグループの遅延などの基本的なメトリックが収集されます。Managed Service for Prometheusを使用するために、Kafkaブローカーを設定または再起動する必要はありません。
Managed Service for Prometheusを使用してセルフマネージドKafkaクラスターを監視する場合は、内部O&Mメトリックにも焦点を当てる必要があります。
セルフマネージドKafkaクラスターのKafkaアプリケーションコンポーネントをデプロイする
Managed Service for Prometheusコンソールにログオンします。
左側のナビゲーションペインで、統合センターを選択し、右側のKafkaカードをクリックします。
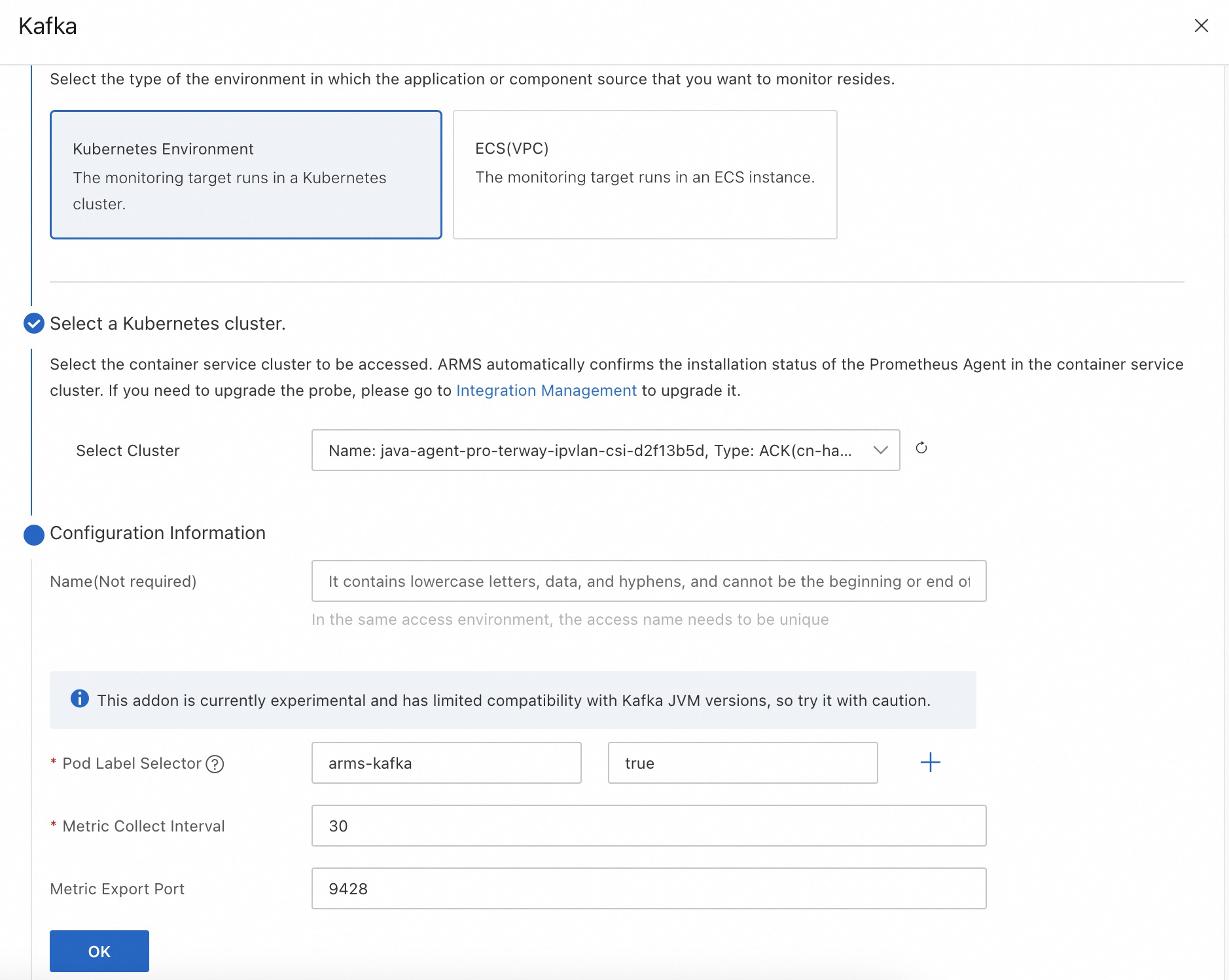
プロンプトに従ってパラメータ値を設定し、OKをクリックします。次の表に、主要なパラメータを示します。
ACK
パラメータ
説明
Podラベルセレクター
Kafka JMXエージェントのデプロイ時にポッドに設定されたタグとタグ値。Managed Service for Prometheusは、このタグをサービスディスカバリーに使用します。詳細については、Kafka JMXエージェントをデプロイおよび設定するにはどうすればよいですか?を参照してください。
メトリック収集間隔
サービスが監視データを収集する間隔。
ECS(VPC)
パラメータ
説明
Kafkaクラスター名
Kafkaクラスター名。一意である必要があります。名前が重複している場合、同じメトリックが繰り返し収集され、ダッシュボードエラーが発生する可能性があります。
サービスアドレス
セルフマネージドKafkaブローカーのエンドポイント。IPアドレスまたはドメインネームシステム(DNS)アドレスを指定できます。複数のブローカーアドレスはコンマ(,)またはセミコロン(;)で区切ります。
SASLを有効にする
Apache KafkaブローカーでSimple Authentication and Security Layer(SASL)機能を有効にするかどうかを指定します。
TLSを有効にする
Apache KafkaブローカーでTransport Layer Security(TLS)機能を有効にするかどうかを指定します。
メトリック収集間隔(単位/秒)
サービスが監視データを収集する間隔。

セルフマネージドKafkaクラスターのダッシュボードを表示する
Managed Service for Prometheusコンソールにログオンします。
左側のナビゲーションペインで、インスタンスをクリックします。
管理するPrometheusインスタンスインスタンスの名前をクリックして、統合センターページに移動します。
Kafka カードを インストール済み セクションでクリックします。表示されるパネルで、ダッシュボード タブをクリックし、表示する Grafana ダッシュボードの図をクリックします。
Kafkaアプリケーションコンポーネントのダッシュボードには、次の情報が表示されます。
Kafkaブローカーの数。
各トピックのパーティションの数。
各トピックの受信メッセージ、送信メッセージ、および累積メッセージの数。
各トピックの同期レプリカ(ISR)の数。
セルフマネージドKafkaクラスターのアラートルールを設定する
Managed Service for Prometheusコンソールに表示される統合センターページで、インストール済みセクションのKafkaカードをクリックします。表示されるパネルで、アラートタブをクリックして、Prometheusアラートを表示します。
Managed Service for Prometheusは、4つの主要なアラートメトリックを提供します。アクティブなブローカーの数の減少、複製不足のパーティションの数、パーティションの数、およびコンシューマートピックの遅延。ビジネス要件に基づいてアラートルールを追加することもできます。詳細については、Prometheusインスタンスのアラートルールを作成するを参照してください。