このトピックでは、PartitionedTableScan (PTS) オペレーターについて、その制限事項、使用方法、および Append オペレーターとのパフォーマンス比較を含めて説明します。
適用範囲
このオペレーターは、PolarDB for PostgreSQL の PostgreSQL 14 において、マイナーエンジンバージョン 2.0.14.9.15.0 以降でサポートされています。
コンソールでマイナーエンジンバージョン番号を確認するか、SHOW polardb_version; 文を実行して確認できます。マイナーエンジンバージョンが要件を満たしていない場合は、マイナーエンジンバージョンをアップグレードする必要があります。
背景情報
パーティションテーブルをスキャンする場合、オプティマイザーは各サブパーティションの実行計画を生成し、Append オペレーターを使用してそれらを連結します。この一連の計画が、パーティションテーブルスキャンの実行計画となります。サブパーティションの数が少ない場合、このプロセスは迅速に完了します。しかし、PolarDB for PostgreSQL および では、パーティションテーブル内のパーティション数に制限はありません。サブパーティションの数が多くなると、オプティマイザーが消費する時間とメモリが急激に増加します。この増加は、同じサイズの標準テーブルをスキャンする場合と比較して特に顕著です。
この問題を解決するために、PolarDB for PostgreSQL および は PartitionedTableScan (PTS) オペレーターを提供します。Append オペレーターと比較して、PTS オペレーターはオプティマイザーが実行計画を生成するのにかかる時間を大幅に短縮します。また、SQL 実行中のメモリ消費量も少なく、メモリ不足 (OOM) エラーの防止に役立ちます。
制限事項
PTS オペレーターは現在
SELECT文のみをサポートしており、DML 文はサポートしていません。PTS オペレーターはパーティションワイズ結合をサポートしていません。
enable_partitionwise_joinを有効にすると、オプティマイザーは PTS オペレーターを含む実行計画を生成しません。
パラメーターの説明
パラメーター名 | 説明 |
polar_num_parts_for_pts | PTS オペレーターを有効にする条件を制御します。デフォルト値は 64 です。有効な値は次のとおりです:
|
使用方法
パラメーターを設定して PTS オペレーターを有効化
SET polar_num_parts_for_pts TO 64;ヒントの使用
ヒント構文 PTScan(tablealias) を使用します。例:
EXPLAIN (COSTS OFF, ANALYZE) /*+ PTScan(part_range) */ SELECT * FROM part_range;
QUERY PLAN
--------------------------------------------------------------------------------
PartitionedTableScan on part_range (actual time=86.404..86.405 rows=0 loops=1)
Scan 1000 Partitions: part_range_p0, part_range_p1, part_range_p2,...
-> Seq Scan on part_range
Planning Time: 36.613 ms
Execution Time: 89.246 ms
(5 rows)並列クエリ
PTS オペレーターは並列クエリをサポートします。パーティション間並列処理とハイブリッド並列処理をサポートします。どちらもデフォルトで有効になっており、設定は不要です。
パーティション間並列処理:各ワーカープロセスが 1 つのパーティションをクエリします。
ハイブリッド並列処理:パーティション間と単一パーティション内の両方で並列実行がサポートされます。
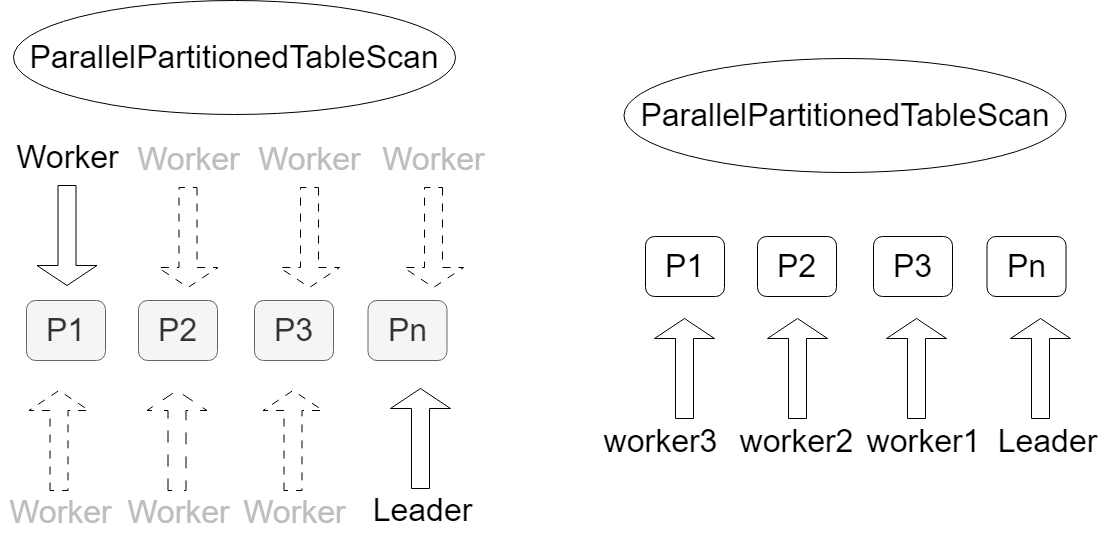
例
2 つのパーティションテーブルを作成し、それぞれに 1,000 個のサブパーティションを作成します。
CREATE TABLE part_range (a INT, b VARCHAR, c NUMERIC, d INT8) PARTITION BY RANGE (a); SELECT 'CREATE TABLE part_range_p' || i || ' PARTITION OF part_range FOR VALUES FROM (' || 10 * i || ') TO (' || 10 * (i + 1) || ');' FROM generate_series(0,999) i;\gexec CREATE TABLE part_range2 (a INT, b VARCHAR, c NUMERIC, d INT8) PARTITION BY RANGE (a); SELECT 'CREATE TABLE part_range2_p' || i || ' PARTITION OF part_range2 FOR VALUES FROM (' || 10 * i || ') TO (' || 10 * (i + 1) || ');' FROM generate_series(0,999) i;\gexec以下は、パーティションテーブルに対する全表スキャンの実行計画です。
SET polar_num_parts_for_pts TO 0; EXPLAIN (COSTS OFF, ANALYZE) SELECT * FROM part_range; QUERY PLAN --------------------------------------------------------------------------------------------- Append (actual time=8.376..8.751 rows=0 loops=1) -> Seq Scan on part_range_p0 part_range_1 (actual time=0.035..0.036 rows=0 loops=1) -> Seq Scan on part_range_p1 part_range_2 (actual time=0.009..0.009 rows=0 loops=1) -> Seq Scan on part_range_p2 part_range_3 (actual time=0.010..0.011 rows=0 loops=1) ... ... ... -> Seq Scan on part_range_p997 part_range_998 (actual time=0.009..0.009 rows=0 loops=1) -> Seq Scan on part_range_p998 part_range_999 (actual time=0.010..0.010 rows=0 loops=1) -> Seq Scan on part_range_p999 part_range_1000 (actual time=0.009..0.009 rows=0 loops=1) Planning Time: 785.169 ms Execution Time: 163.534 ms (1003 rows)クエリで 2 つのパーティションテーブルを結合すると、実行計画の生成時間が長くなり、メモリ消費量が多くなることがより顕著になります。
=> SET polar_num_parts_for_pts TO 0; => EXPLAIN (COSTS OFF, ANALYZE) SELECT COUNT(*) FROM part_range a JOIN part_range2 b ON a.a = b.a WHERE b.c = '0001'; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------- Finalize Aggregate (actual time=3191.718..3212.437 rows=1 loops=1) -> Gather (actual time=2735.417..3212.288 rows=3 loops=1) Workers Planned: 2 Workers Launched: 2 -> Partial Aggregate (actual time=2667.247..2667.789 rows=1 loops=3) -> Parallel Hash Join (actual time=1.957..2.497 rows=0 loops=3) Hash Cond: (a.a = b.a) -> Parallel Append (never executed) -> Parallel Seq Scan on part_range_p0 a_1 (never executed) -> Parallel Seq Scan on part_range_p1 a_2 (never executed) -> Parallel Seq Scan on part_range_p2 a_3 (never executed) ... ... ... -> Parallel Seq Scan on part_range_p997 a_998 (never executed) -> Parallel Seq Scan on part_range_p998 a_999 (never executed) -> Parallel Seq Scan on part_range_p999 a_1000 (never executed) -> Parallel Hash (actual time=0.337..0.643 rows=0 loops=3) Buckets: 4096 Batches: 1 Memory Usage: 0kB -> Parallel Append (actual time=0.935..1.379 rows=0 loops=1) -> Parallel Seq Scan on part_range2_p0 b_1 (actual time=0.001..0.001 rows=0 loops=1) Filter: (c = '1'::numeric) -> Parallel Seq Scan on part_range2_p1 b_2 (actual time=0.001..0.001 rows=0 loops=1) Filter: (c = '1'::numeric) -> Parallel Seq Scan on part_range2_p2 b_3 (actual time=0.001..0.001 rows=0 loops=1) Filter: (c = '1'::numeric) ... ... ... -> Parallel Seq Scan on part_range2_p997 b_998 (actual time=0.001..0.001 rows=0 loops=1) Filter: (c = '1'::numeric) -> Parallel Seq Scan on part_range2_p998 b_999 (actual time=0.000..0.001 rows=0 loops=1) Filter: (c = '1'::numeric) -> Parallel Seq Scan on part_range2_p999 b_1000 (actual time=0.002..0.002 rows=0 loops=1) Filter: (c = '1'::numeric) Planning Time: 1900.615 ms Execution Time: 3694.320 ms (3013 rows)上記の例は、パーティションテーブルでの全表スキャンが、標準テーブルでのスキャンに比べて利点がないことを示しています。これは、クエリにフィルター条件としてのパーティションキーがなく、パーティションプルーニングが妨げられるためです。このシナリオでは、パーティションテーブルは標準テーブルよりも効率が低くなります。パーティションテーブルのベストプラクティスは、可能な限りパーティションプルーニングを使用して、クエリを少数のパーティションに集中させることです。ただし、一部のオンライン分析処理 (OLAP) シナリオでは、全表スキャンが必要です。このような場合、PTS オペレーターは Append オペレーターよりも効率的です。
SET polar_num_parts_for_pts TO 10; EXPLAIN (COSTS OFF, ANALYZE) SELECT * FROM part_range; QUERY PLAN -------------------------------------------------------------------------------- PartitionedTableScan on part_range (actual time=86.404..86.405 rows=0 loops=1) Scan 1000 Partitions: part_range_p0, part_range_p1, part_range_p2,... -> Seq Scan on part_range Planning Time: 36.613 ms Execution Time: 89.246 ms (5 rows)SET polar_num_parts_for_pts TO 10; EXPLAIN (COSTS OFF, ANALYZE) SELECT COUNT(*) FROM part_range a JOIN part_range2 b ON a.a = b.a WHERE b.c = '0001'; QUERY PLAN ---------------------------------------------------------------------------------------------------- Aggregate (actual time=61.384..61.388 rows=1 loops=1) -> Merge Join (actual time=61.378..61.381 rows=0 loops=1) Merge Cond: (a.a = b.a) -> Sort (actual time=61.377..61.378 rows=0 loops=1) Sort Key: a.a Sort Method: quicksort Memory: 25kB -> PartitionedTableScan on part_range a (actual time=61.342..61.343 rows=0 loops=1) Scan 1000 Partitions: part_range_p0, part_range_p1, part_range_p2, ... -> Seq Scan on part_range a -> Sort (never executed) Sort Key: b.a -> PartitionedTableScan on part_range2 b (never executed) -> Seq Scan on part_range2 b Filter: (c = '1'::numeric) Planning Time: 96.675 ms Execution Time: 64.913 ms (16 rows)この結果から、PTS オペレーターを使用すると、実行計画の生成時間が大幅に短縮されることがわかります。
パフォーマンス比較
以下のデータは、標準的なベンチマークテストから得られたものではありません。このデータは、Append オペレーターと PTS オペレーターのパフォーマンスを比較するために、一貫した構成のステージング環境で収集されたものです。
単一 SQL 文の実行計画生成時間
パーティション数 | Append | PTS |
16 | 0.266 ms | 0.067 ms |
32 | 1.820 ms | 0.258 ms |
64 | 3.654 ms | 0.402 ms |
128 | 7.010 ms | 0.664 ms |
256 | 14.095 ms | 1.247 ms |
512 | 27.697 ms | 2.328 ms |
1024 | 73.176 ms | 4.165 ms |
単一 SQL 文のメモリ使用量
パーティション数 | Append | PTS |
16 | 1170 KB | 1044 KB |
32 | 1240 KB | 1044 KB |
64 | 2120 KB | 1624 KB |
128 | 2244 KB | 1524 KB |
256 | 2888 KB | 2072 KB |
512 | 4720 KB | 3012 KB |
1024 | 8236 KB | 5280 KB |
PGBench QPS
パーティション数 | Append | PTS |
16 | 25318 | 93950 |
32 | 10906 | 61879 |
64 | 5281 | 30839 |
128 | 2195 | 16684 |
256 | 920 | 8372 |
512 | 92 | 3708 |
1024 | 21 | 1190 |