PASE (PostgreSQL ANN search extension) は、PolarDB for PostgreSQL (Compatible with Oracle) に、パフォーマンス専有型の近似最近傍 (ANN) ベクトル検索機能を追加します。IVFFlat と HNSW (Hierarchical Navigable Small World) の 2 種類のインデックスタイプをサポートしており、ワークロードに合わせて速度と再現率のトレードオフを調整できます。
PASE は、指定されたベクターに対して類似検索を実行します。特徴ベクトルの抽出や生成は行いません。
前提条件
開始する前に、以下が準備されていることを確認してください。
PolarDB for PostgreSQL (Compatible with Oracle) クラスター
SQL ステートメントを実行するための特権アカウント
クイックスタート
以下の例は、拡張機能のインストール、テーブルの作成、インデックスのビルド、クエリの実行という一連のワークフローを示しています。
-- 拡張機能のインストール
CREATE EXTENSION pase;
-- ベクトル列を持つテーブルの作成
CREATE TABLE items (id integer, vector float4[]);
-- HNSW インデックスのビルド
CREATE INDEX hnsw_idx ON items
USING pase_hnsw(vector)
WITH (dim = 3, base_nb_num = 16, ef_build = 40, ef_search = 200, base64_encoded = 0);
-- 最近傍のクエリ
SELECT id, vector <?> '1,1,1:100:0'::pase AS distance
FROM items
ORDER BY vector <?> '1,1,1:100:0'::pase ASC
LIMIT 10;インデックスタイプの選択
| IVFFlat | HNSW | |
|---|---|---|
| 最適な用途 | 高精度シナリオ、画像比較 | 大規模データセット (数千万以上のベクター)、レコメンデーションの再現率 |
| 目標クエリレイテンシー | 最大 100 ms | 10 ms 未満 |
| ビルド時間 | 高速 | 低速 |
| メモリ使用量 | 下位 | 多い (近接グラフを格納するため) |
| 100% の再現率の可能性 | あり (クエリベクターがデータセット内に存在する場合) | なし (精度は一定のレベルで頭打ちになる) |
| 再設定可能な精度 | あり (クエリ時にプローブ数を調整) | 限定的 |
IVFFlat を使用する場合: 高い精度が必要で、最大 100 ms のクエリレイテンシーを許容でき、ストレージオーバーヘッドが少なく高速なインデックスビルドを求める場合に IVFFlat を選択します。
HNSW を使用する場合: クエリが 10 ms 以内に返される必要がある大規模データセットには HNSW を選択します。メモリ使用量が多くなり、インデックスのビルド時間も長くなることを想定してください。
仕組み
IVFFlat
IVFFlat は、IVFADC アルゴリズムの簡易版です。k 平均法を使用してベクターをクラスターに分割し、クエリ時には検索範囲をクエリベクターに最も近いクラスターに絞り込みます。
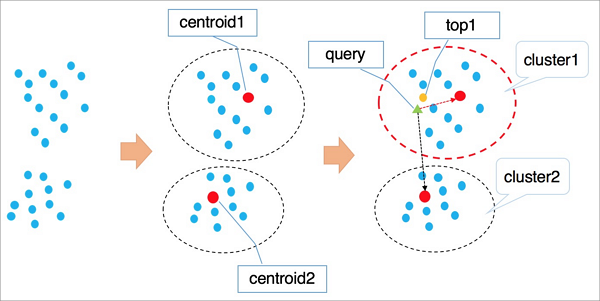
IVFFlat は k 平均法を使用してすべてのベクターをクラスタリングします。各クラスターには重心があります。
クエリ時、IVFFlat はクエリベクターに最も近い *n* 個の重心を見つけます。
IVFFlat は、それらの *n* 個のクラスター内のすべてのベクターを検索し、最も近い *k* 個を返します。
*n* 個のクラスターのみを検索することでクエリは高速化されますが、スキップされたクラスター内の類似ベクターを見逃す可能性があり、再現率が低下します。再現率を向上させるには *n* を増やしますが、その分計算量が増加します。完全な走査を避けるためにプロダクト量子化を使用する IVFADC とは異なり、IVFFlat は各クラスター内で力まかせ探索を使用して精度を維持します。
HNSW
HNSW は、NSW (Navigable Small World) アルゴリズムを使用して多層グラフを構築します。各レイヤーは、その下のレイヤーをより粗くしたビューです。
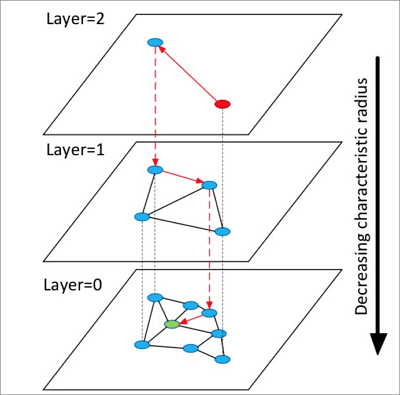
HNSW は、複数のレイヤーを持つ階層グラフを構築します。
検索は、最上位レイヤーのランダムなエントリポイントから開始されます。
HNSW は、現在の要素の近傍を特定し、それらを距離でランク付けされた固定長の動的リストに追加します。次に、それらの近傍の近傍へと展開し、リストを継続的に再ソートして上位 *k* 個の候補のみを保持します。これはリストが安定するまで続き、その後、最上位の要素が次の下位レイヤーのエントリポイントになります。
最下位レイヤーが最終的な最近傍を返します。
HNSW の近傍選択アプローチは、大規模なデータセットにおいてクラスタリングベースのアルゴリズムよりも優れたクエリパフォーマンスを発揮しますが、近接グラフを格納する必要があるため、追加のメモリを消費します。
IVFFlat インデックスの作成
距離計算メソッドの選択
| メソッド | 値 | 正規化が必要 |
|---|---|---|
| ユークリッド距離 | 0 | 不要 |
| ドット積 (内積) | 1 | はい |
ドット積またはコサインメソッドを使用する場合は、まずベクターを正規化する必要があります。ベクター ![]() の場合、
の場合、![]() を満たす必要があります。正規化後、ドット積はコサイン値と等しくなります。
を満たす必要があります。正規化後、ドット積はコサイン値と等しくなります。
PolarDB はネイティブではユークリッド距離のみをサポートしています。ドット積を使用するには、ベクターを正規化し、「付録」のアプローチに従ってください。
インデックスの作成
CREATE INDEX ivfflat_idx ON vectors_table
USING pase_ivfflat(vector)
WITH (
clustering_type = 1,
distance_type = 0,
dimension = 256,
base64_encoded = 0,
clustering_params = "10,100"
);内部クラスタリング (clustering_type = 1) を使用するには、インデックスを作成する前にテーブルにデータを挿入してください。IVFFlat インデックスのパラメーター
| パラメーター | 必須 | 説明 | デフォルト値 |
|---|---|---|---|
clustering_type | はい | 0 = 外部クラスタリング (clustering_params で指定された重心ファイルをロード)。1 = 内部 k 平均法クラスタリング。PASE を初めて使用する場合は 1 から始めてください。 | — |
distance_type | いいえ | 0 = ユークリッド距離。1 = ドット積 (正規化されたベクターが必要。ドット積の順序はユークリッド距離の順序と逆)。 | 0 |
dimension | はい | ベクトル次元数。最大:512。 | — |
base64_encoded | いいえ | 0 = ベクターの表現に float4[] を使用。1 = Base64 エンコードされた float[] を使用。 | 0 |
clustering_params | はい | 外部クラスタリングの場合:重心ファイルへのパス。内部クラスタリングの場合:clustering_sample_ratio,k。 | — |
内部クラスタリングのための `clustering_params` の設定:
clustering_sample_ratio:分母を 1000 としたサンプリング率。有効値:(0, 1000]。例えば、1は 1/1000 のサンプリング比率を意味します。サンプリングされるレコードの合計は 100,000 未満にしてください。k:重心の数。有効値:[100, 1000]。値を大きくすると再現率が向上しますが、インデックスの作成が遅くなります。
IVFFlat インデックスを使用したクエリ
<#> 演算子を使用すると、IVFFlat インデックスが有効になります。ORDER BY 句が必要です。
SELECT id, vector <#> '1,1,1'::pase AS distance
FROM vectors_ivfflat
ORDER BY vector <#> '1,1,1:10:0'::pase ASC
LIMIT 10;クエリ文字列 'vector:probe_count:distance_type' は、コロンで区切られた 3 つのパラメーターを受け入れます。
| 位置 | 説明 | 範囲 |
|---|---|---|
| 1 番目 | クエリベクター | — |
| 2 番目 | プローブ数 — 検索するクラスターの数。値を大きくすると再現率が向上しますが、クエリ速度は低下します。 | (0, 1000] |
| 3 番目 | 距離計算メソッド:0 = ユークリッド距離、1 = ドット積 (正規化されたベクターが必要) | 0 または 1 |
HNSW インデックスの作成
インデックスの作成
CREATE INDEX hnsw_idx ON vectors_table
USING pase_hnsw(vector)
WITH (
dim = 256,
base_nb_num = 16,
ef_build = 40,
ef_search = 200,
base64_encoded = 0
);HNSW インデックスのパラメーター
| パラメーター | 必須 | 説明 | デフォルト値 |
|---|---|---|---|
dim | はい | ベクトル次元数。最大:512。 | — |
base_nb_num | はい | 要素ごとの近傍の数。値を大きくすると再現率が向上しますが、ビルド時間とメモリ使用量が増加します。推奨範囲:[16, 128]。 | — |
ef_build | はい | インデックス構築時のヒープサイズ。値を大きくすると再現率が向上しますが、インデックスの作成が遅くなります。推奨範囲:[40, 400]。 | — |
ef_search | はい | クエリ時のヒープサイズ。値を大きくすると再現率が向上しますが、クエリ速度は低下します。クエリ時にオーバーライドできます。 | 200 |
base64_encoded | いいえ | 0 = ベクターの表現に float4[] を使用。1 = Base64 エンコードされた float[] を使用。 | 0 |
HNSW インデックスを使用したクエリ
<?> 演算子を使用すると、HNSW インデックスが有効になります。ORDER BY 句が必要です。
SELECT id, vector <?> '1,1,1'::pase AS distance
FROM vectors_ivfflat
ORDER BY vector <?> '1,1,1:100:0'::pase ASC
LIMIT 10;クエリ文字列 'vector:ef_search:distance_type' は、コロンで区切られた 3 つのパラメーターを受け入れます。
| 位置 | 説明 | 範囲 |
|---|---|---|
| 1 番目 | クエリベクター | — |
| 2 番目 | ef_search のオーバーライド — 値を大きくすると、クエリ速度を犠牲にして再現率が向上します。40 から始めて、目標の再現率に達するまで増やしてください。 | (0, ∞) |
| 3 番目 | 距離計算メソッド:0 = ユークリッド距離、1 = ドット積 (正規化されたベクターが必要) | 0 または 1 |
ベクトル類似度の計算
PASE は、ベクトル類似度をインラインで計算するための 2 つのコンストラクターメソッドを提供します。
PASE 型構造
<?> 演算子は、左側に float4[]、右側に PASE 型を取ります。
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[]) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 1) AS distance;PASE コンストラクターは、最大 3 つの引数 pase(vector, unused_param, distance_method) を受け入れます。2 番目の引数には特別な目的はありません。0 に設定してください。3 番目の引数は距離計算メソッドを設定します:0 はユークリッド距離、1 はドット積です。
両方のベクターは同じ次元数でなければなりません。不一致の場合はエラーが発生します。
文字列による構築
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1'::pase AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0'::pase AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0:1'::pase AS distance;文字列フォーマットは 'vector:unused_param:distance_method' で、区切り文字としてコロンを使用します。パラメーターの意味は PASE 型コンストラクターと同じです。
注意事項
インデックスの肥大化:
SELECT pg_relation_size('index_name');でインデックスサイズを確認してください。インデックスがテーブルデータよりも大きく、クエリが遅くなっている場合は、インデックスを再ビルドしてください。インデックスのドリフト: 頻繁なデータ更新はインデックスの精度を低下させる可能性があります。100% の精度が必要な場合は、定期的にインデックスを再ビルドしてください。
並列クエリ: マルチノード弾性並列クエリでは、高次元ベクターに対してシーケンシャル検索のみがサポートされています。
特権アカウント: このトピックのすべての SQL ステートメントには、特権アカウントが必要です。
付録
HNSW を使用したドット積の計算
PolarDB はネイティブでドット積距離をサポートしていないため、ベクターを正規化した後、この関数を使用してドット積で検索します。
CREATE OR REPLACE FUNCTION inner_product_search(
query_vector text,
ef integer,
k integer,
table_name text
)
RETURNS TABLE (id integer, uid text, distance float4) AS $$
BEGIN
RETURN QUERY EXECUTE format('
SELECT a.id, a.vector <?> pase(ARRAY[%s], %s, 1) AS distance
FROM (
SELECT id, vector
FROM %s
ORDER BY vector <?> pase(ARRAY[%s], %s, 0) ASC
LIMIT %s
) a
ORDER BY distance DESC;',
query_vector, ef, table_name, query_vector, ef, k);
END
$$ LANGUAGE plpgsql;正規化されたベクトルのドット積はそのコサイン値と等しくなるため、この関数はコサイン類似度検索にも使用できます。
外部重心ファイルからの IVFFlat インデックスの作成
外部クラスタリングは高度なオプションです。重心ファイルをサーバーにアップロードし、インデックス定義で clustering_type = 0 を設定します。
重心ファイルのフォーマットは次のとおりです。
次元数|重心数|重心ベクターデータセット例:
3|2|1,1,1,2,2,2参考文献
Product Quantization for Nearest Neighbor Search — Hervé Jégou, Matthijs Douze, Cordelia Schmid.
Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs — Yu.A. Malkov, D.A. Yashunin.