PolarDB for PostgreSQL (Compatible with Oracle) は、複雑な分析クエリの処理で発生する PolarDB for PostgreSQL (Compatible with Oracle) の問題を解決するマルチノードelastic parallelクエリ (ePQ) 機能を提供します。
前提条件
PolarDB for PostgreSQL (Compatible with Oracle) クラスターは、次のいずれかのエンジンを実行します。
PolarDB for PostgreSQL (Oracle互換) 2.0 (バージョン2.0.14.15.0以降)
次のステートメントを実行して、PolarDB for PostgreSQL (Compatible with Oracle) クラスターのリビジョンバージョンを表示できます。
SHOW polar_version; 背景情報
PolarDB for PostgreSQL (Oracle互換) を使用する場合、トランザクションクエリと分析クエリの両方が発生する可能性があります。 トランザクションのトラフィックが減少し、作業負荷が低い夜間に、データベースが同時並行性の高いトランザクションリクエストを処理し、分析タスクを実行してレポートを生成する場合があります。 これは、依然として、アイドルリソースの利用を最大化しない。 PolarDB for PostgreSQL (Oracleと互換) は、複雑な分析クエリを処理するときに2つの大きな課題に遭遇します。
ネイティブPostgreSQLでは、SQL文は単一のノードでのみ実行できます。 シリアル実行モードでもパラレル実行モードでも、CPUやメモリリソースなどの他のノードのコンピューティングリソースを実行に使用することはできません。 1つのクエリを高速化するには、スケールアップのみを実行でき、スケールアウトは実行できません。
PolarDB for PostgreSQL (Oracle互換) は、理論的には無制限のI/Oスループットを提供するストレージプールの上に構築されています。 ただし、ネイティブPostgreSQLでは、SQLステートメントは単一のノードでのみ実行できます。 単一ノードのCPUとメモリの制限により、ストレージのI/Oスループットを十分に活用することはできません。
次の図は、ネイティブPostgreSQLの課題を示しています。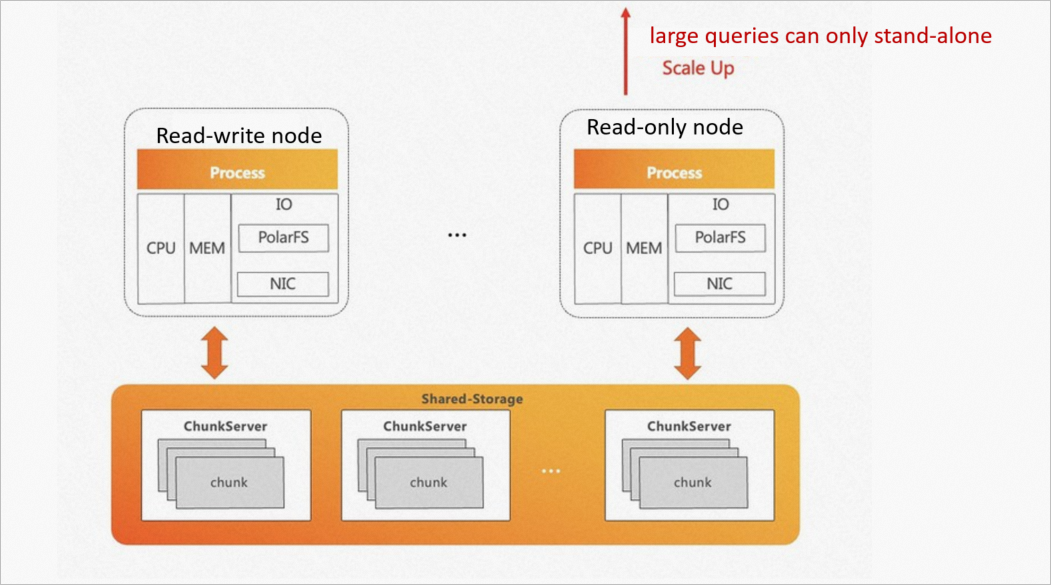
これらの課題を克服するために、 PolarDB for PostgreSQL (Compatible with Oracle) はePQ機能を提供しています。 業界では3つの主要なHTAPソリューションが提供されています。
トランザクションおよび分析クエリは、完全に分離されたストレージおよびコンピューティングリソースを使用します。
利点: 2つのリクエストタイプは互いに影響しません。
短所:
トランザクションシステムから分析システムにデータをインポートする必要があります。
2つのシステムが並行して実行されるため、O&Mのコストと難易度が高くなります。
ストレージおよびコンピューティングリソースは、トランザクションおよび分析システムによって完全に共有されます。
利点: コストが最小限に抑えられ、リソース使用率が最大になります。
短所:
分析クエリとトランザクションクエリは、互いに影響を及ぼし得る。
計算ノードをスケールアウトする場合、データを再配布する必要があり、スケールアウト速度に影響します。
トランザクションシステムと分析システムはストレージリソースを共有しますが、別々のコンピューティングリソースを使用します。
説明PolarDB for PostgreSQLは、ストレージとコンピューティングリソースを分離するアーキテクチャを使用します。 したがって、このソリューションのサポートが付属しています。
HTAPのしくみ
アーキテクチャ特性
PolarDB for PostgreSQL (Compatible with Oracle) は、ストレージとコンピューティングを分離するアーキテクチャを採用し、ePQエンジンを提供し、クロスノード並列実行、柔軟なコンピューティング、および高スケーラビリティ機能をサポートします。 ePQエンジンは、マルチノード並列実行、エラスティックコンピューティング、およびエラスティックスケーリングを保証します。 PolarDB for PostgreSQL (Oracle互換) はHTAP機能を提供します。 それは次の利点をもたらします:
共有ストレージ: データの鮮度はミリ秒単位です。
トランザクションシステムと分析システムは、ストレージデータを共有して、ストレージコストを削減し、クエリ効率を向上させます。
トランザクションシステムと分析システムの物理的分離: CPUとメモリの相互影響を排除します。
シングルノード並列クエリ (PQ) エンジン: プライマリノードまたは読み取り専用ノードで同時並行性の高いトランザクションクエリを処理します。
ePQエンジン: 読み取り専用ノードで複雑度の高い分析クエリを処理します。
サーバーレススケーリング: 任意の読み取り専用ノードからePQクエリを開始できます。
スケールアウト: ePQのノード範囲を調整できます。
スケールアップ: PQの並列度を指定できます。
PolarDB for PostgreSQL (Compatible with Oracle) バッファポーリングのアフィニティを十分に考慮して、データスキューと計算スキューを排除します。

ePQエンジン
PolarDB for PostgreSQL (Oracle互換) のコアePQはePQエンジンです。 テーブルAとBは最初に結合され、次に集約されます。 これは、ネイティブPostgreSQLが単一のノードで操作を実行する方法でもあります。 実行プロセスを次の図に示します。

大規模並列処理 (MPP) エンジンでは、データは異なるノードに分散される。 異なるノード上のデータは、ハッシュ分布、ランダム分布、複製分布などの異なる分布属性を有することができる。 MPPエンジンは、さまざまなテーブルのデータ配信特性に基づいて演算子を実行計画に挿入し、データ配信属性が上位層の演算子に対して透過的であることを保証します。
PolarDB for PostgreSQL (Oracleと互換) は、共有ストレージアーキテクチャを使用します。 PolarDB for PostgreSQLインスタンスに格納されているデータは、そのすべての計算ノードからアクセスできます。 MPPエンジンでは、各計算ノードワーカーがすべてのデータをスキャンして重複データを取得します。 スキャンプロセスは、並列スキャン方法を使用することによって加速されない。 それは本当のMPPエンジンではありません。
したがって、火山モデルの原則に従って、ePQエンジンはすべてのスキャン演算子を同時に処理し、PxScan演算子を導入して共有ストレージをマスクします。 PxScan演算子は、共有ストレージデータを共有なしデータにマッピングします。 テーブルは複数の仮想パーティションに分割され、各ワーカーは独自の仮想パーティションをスキャンしてePQスキャンを実装します。
PxScan演算子によってスキャンされたデータは、シャッフル演算子によって再配布されます。 再分配されたデータは、あたかも単一のノード上で実行されたかのように、火山モデルに基づいて各ワーカー上で実行される。
サーバーレススケーリング
MPPエンジンは、指定されたノードでのみMPPクエリを開始できます。 したがって、各ノードで1つのテーブルをスキャンできるのは1つのワーカーだけです。 サーバーレススケーリングをサポートするために、分散トランザクションの強力な一貫性が導入されます。
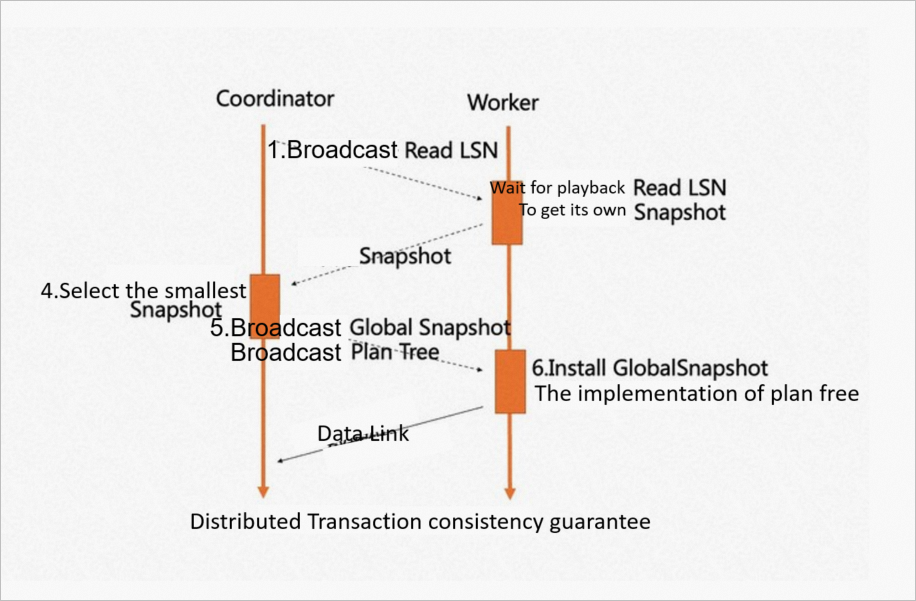
ノードがコーディネータ・ノードとして選択され、そのReadLSNが合意されたLSNとして使用される。 並列実行に関与するすべてのノードの最も古いスナップショットバージョンは、合意されたグローバルスナップショットバージョンです。 LSN再生待機およびグローバルスナップショット同期メカニズムを使用して、任意のノードがePQクエリを開始するときにデータとスナップショットが一貫して利用可能であることを保証します。
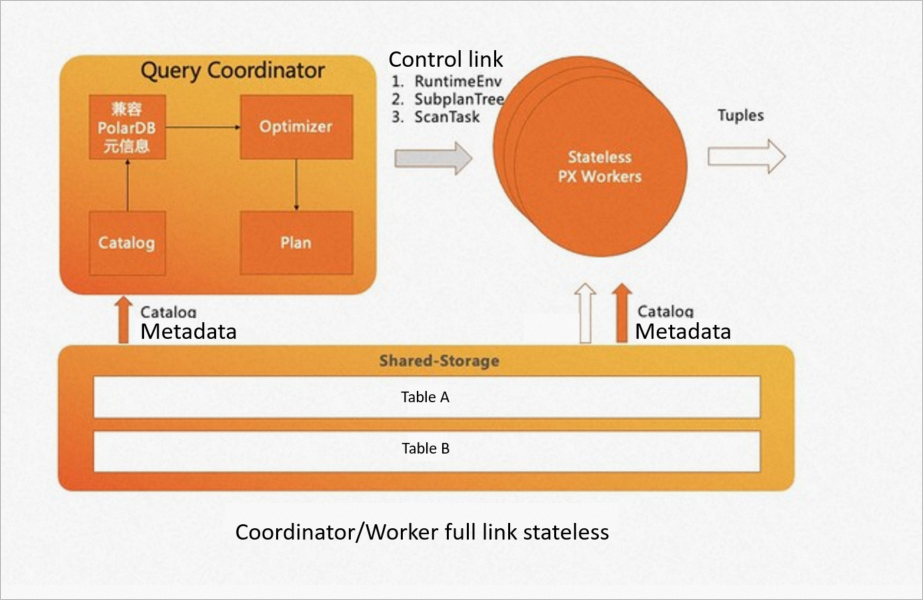
サーバーレススケーリングを実装するために、 PolarDB for PostgreSQL (Compatible with Oracle) は、共有ストレージ機能を使用して、コーディネーターノードのチェーン上のすべてのモジュールが必要とするすべての外部依存関係を共有ストレージに追加します。 すべてのワーカーノードが必要とするパラメータも、制御リンクを介してコーディネータノードから同期される。 これにより、コーディネーターノードとワーカーノードがステートレスになります。
PolarDB for PostgreSQL (Oracleと互換) が提供するサーバーレススケーリングには、次の利点があります。
任意のノードが、MPPエンジン内のコーディネータノードの単一障害点を解決するためのコーディネータノードになることができる。
PolarDB for PostgreSQL (Compatible with Oracle) を使用すると、1つのノードの計算ノード数と並列処理の程度を増やすことができます。 スケーリングは、データを再配布せずに直ちに有効になります。
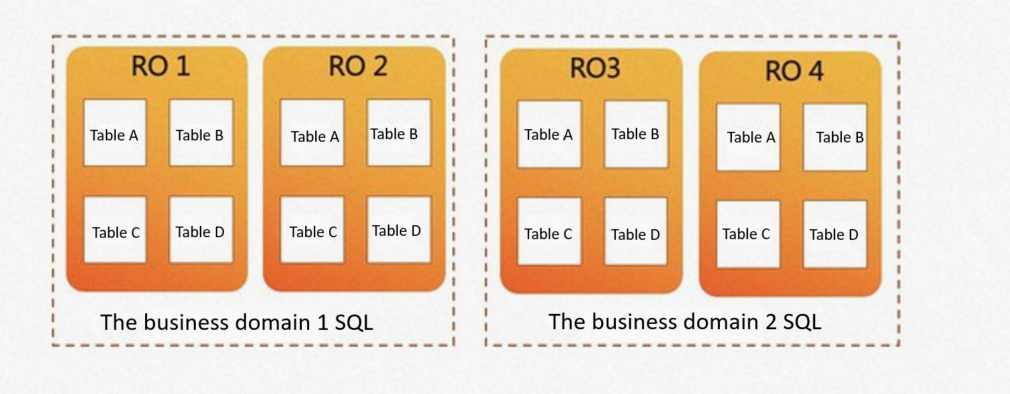
より柔軟なスケジューリングポリシーが利用可能です。 ビジネスドメインは、異なるノードコレクションで実行できます。 ビジネスドメイン1は、ノードRO1およびRO2を使用して分析クエリを実行できます。 ビジネスドメイン2は、分析クエリのノードRO3およびRO4を選択できます。 2つのビジネスドメインで使用される計算ノードは、エラスティックスケジューリングをサポートします。
スキュー除去
歪度は、MPPの固有の問題であり、データスキュー及び計算スキューを含む。
データスキューは通常、データの不均一な分布によって引き起こされます。 PostgreSQLでは、大規模なTOASTテーブルのストレージのために、いくつかの避けられないデータ配信の問題が発生します。
計算スキューは通常、異なるノードでの同時トランザクション、バッファプール、ネットワーク問題、およびI/Oジッタによって引き起こされます。
MPPにおけるスキューは、実行時間が最も遅いサブタスクによって決定されることを意味する。
PolarDB for PostgreSQL (Oracle互換) は、アダプティブスキャンメカニズムを実装しています。 次の図は、コーディネーターノードがワーカーノード間でワークロードをスケジュールする方法を示しています。 データスキャンが開始されると、コーディネータノードは、スキャンに基づいてワーカーノードをスケジュールするために、メモリ内にタスクマネージャを作成する。 コーディネーターノードには、次のスレッドがあります。
データスレッド: 主にデータリンクを処理し、タプルを収集します。
制御スレッド: 制御リンクを処理し、各スキャンオペレータのスキャンの進行状況を決定します。
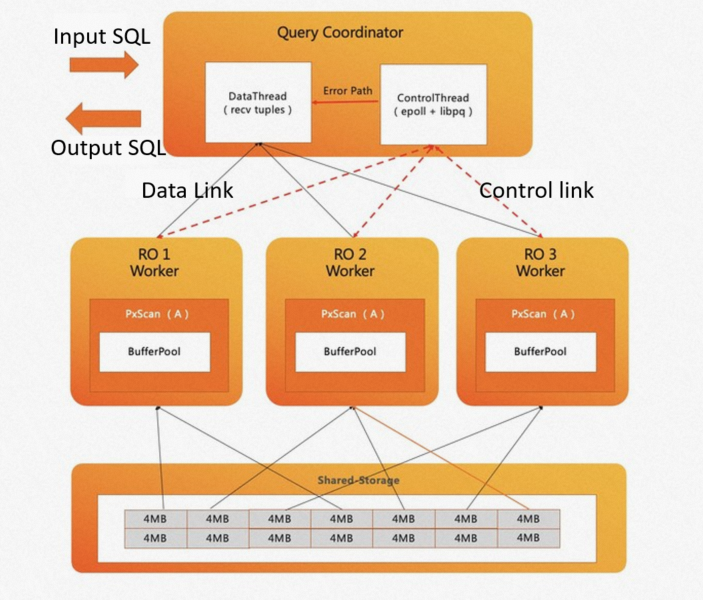
高速に動作するワーカーノードは、複数のデータブロックをスキャンできます。 前の図では、ワーカーノードRO1およびRO3はそれぞれ4つのデータブロックをスキャンします。 ワーカノードRO2は、計算スキューにより6個のデータブロックをスキャンする。
PolarDB for PostgreSQL (Compatible with Oracle) ePQのアダプティブスキャンメカニズムも、PostgreSQLのバッファプールアフィニティを考慮しています。 各ワーカーノードが常に同じデータブロックをスキャンすることを保証します。 これにより、バッファプールのヒット率が最大になり、I/O帯域幅が減少します。
TPC-Hパフォーマンスの比較
PQとePQの比較。
次の例では、16個のメモリを持つPolarDB for PostgreSQL (Compatible with Oracle) 読み取り専用ノードを使用して、テスト用の1テラバイトのTPC-H環境を構築します。 PQと比較して、ePQはすべての読み取り専用ノードのコンピューティングリソースと、基盤となる共有ストレージのI/O帯域幅を最大限に活用しているため、これまでのHTAPの課題が解決されます。 ePQ機能により、TPC-Hテストで使用される22のSQL文は平均して23倍高速に実行されます。 そのうち、3つのSQL文は60倍以上加速され、19のSQL文は10倍以上加速されます。

パフォーマンスは、コンピューティングリソースのスケーリングによっても向上します。 CPUコアの数が16から128に増加すると、TPC-Hクエリの合計実行時間と各SQL文の実行速度が線形的に向上します。 これは、 PolarDB for PostgreSQL (Oracle互換) ePQのサーバーレススケーラビリティの明確な証拠です。

テストでは、256を超えるCPUコアが使用されても、パフォーマンスの大幅な向上は見られません。 PolarDB for PostgreSQL (Compatible with Oracle) の共有ストレージのI/O帯域幅の100% が使用されているため、ボトルネックとなっています。
PolarDBデータベースとMPPデータベースの比較
16 メモリが256 GBのPolarDB for PostgreSQL読み取り専用ノードを使用して、 PolarDB for PostgreSQL (Compatible with Oracle) のePQエンジンをMPPエンジンと比較する環境を構築します。
1テラバイトのTPC-Hデータの場合、 PolarDB for PostgreSQL (Compatible with Oracle) のパフォーマンスは、同程度の並列処理の場合のMPPデータベースのパフォーマンスと90% になります。 根本的な原因は、MPPデータベースのデータがデフォルトでハッシュ分布を使用することです。 2つのテーブルの結合キーが独自の配布キーを使用する場合、シャッフル再配布なしにパーティションごとの結合を実行できます。 PolarDB for PostgreSQL (Compatible with Oracle) は共有ストレージプールを使用し、PxScan演算子によって並列にスキャンされたデータはランダム分布と同等のものを使用します。 その後の処理の前に、MPPデータベースのようにシャッフル再分配が必要です。 TPC-Hのテーブル結合が関与する場合、 PolarDB for PostgreSQL (Compatible with Oracle) は、シャッフルの再配布により、MPPデータベースよりも高いオーバーヘッドが発生します。


PolarDB for PostgreSQL (Compatible with Oracle) のePQエンジンはスケーリングをサポートしているため、データの再配布は必要ありません。 16ノードのePQの場合、 PolarDB for PostgreSQL (Compatible with Oracle) は、各サーバーのリソースを最大限に活用するために、単一サーバーの並列処理度を拡張し続けます。 PolarDB for PostgreSQL (Compatible with Oracle) の並列度が8の場合、パフォーマンスはMPPデータベースの5〜6倍になります。 PolarDB for PostgreSQL (Compatible with Oracle) の並列処理度が向上すると、の全体的なパフォーマンスが向上します。 PolarDB for PostgreSQL (Oracle互換) が強化されました。 並列度値の変更は直ちに有効になる。
特徴
並列クエリ
現在、 PolarDB for PostgreSQL (Oracle互換) ePQは、並列クエリで次の機能をサポートしています。
スキャン、結合、集計、サブクエリなど、すべての基本演算子がサポートされています。
shuffle演算子共有、SharedSeqScan共有、SharedIndexScan共有など、共有ストレージ演算子が最適化されています。 SharedSeqScan共有およびSharedIndexScan共有では、大きなテーブルが小さなテーブルに結合すると、小さなテーブルはテーブルレプリケーションと同様のメカニズムを使用してブロードキャストのオーバーヘッドを削減し、パフォーマンスを向上させます。
パーティション分割テーブルがサポートされています。ハッシュ、範囲、リストのパーティション分割だけでなく、マルチレベルパーティションの静的なプルーニングと動的なプルーニングもサポートされています。 さらに、 PolarDB for PostgreSQL (Oracleと互換) は、パーティションテーブルでのパーティション単位の結合をサポートします。
並列処理制御の程度: グローバル、テーブル、セッション、およびクエリレベルで。
サーバーレススケーリング: 任意のノードでePQクエリを開始するか、ノード範囲を指定できます。 PolarDB for PostgreSQLは自動的にクラスタートポロジ情報を維持し、共有ストレージ、プライマリ /セカンダリ、および3ノードモードをサポートします。
パラレルDML実行
並列DML実行の場合、 PolarDB for PostgreSQL (Compatible with Oracle) は、 PolarDB for PostgreSQL (Compatible with Oracle) の読み書き分離アーキテクチャとサーバーレススケーリングに基づいて、1つの書き込みと複数の読み取り機能、および複数の書き込みと複数の読み取り機能を提供します。
1つの書き込みおよび複数の読み取り機能: 読み取り専用ノードには複数の読み取りワーカーがあり、読み取り /書き込みノードには1つの書き込みワーカーのみがあります。
複数の書き込みおよび複数の読み取り機能: 読み取り専用ノード上の複数の読み取りワーカーおよび読み取り /書き込みノード上の複数の書き込みワーカー。 複数の書き込みおよび複数の読み取りのシナリオでは、読み取りの並列度は、書き込みの並列度とは無関係である。
2つの機能は、異なるシナリオで使用できます。 ビジネス特性に基づいて選択できます。
インデックス作成の高速化
PolarDB for PostgreSQL (Compatible with Oracle) のePQエンジンを使用すると、クエリとDML操作を実行し、インデックス作成プロセスを高速化できます。 OLTPビジネスには多数のインデックスが関わっています。 B-Treeインデックスが作成されると、インデックスページの書き込みに20% て、インデックスページのソートと作成に約80% の時間が費やされます。
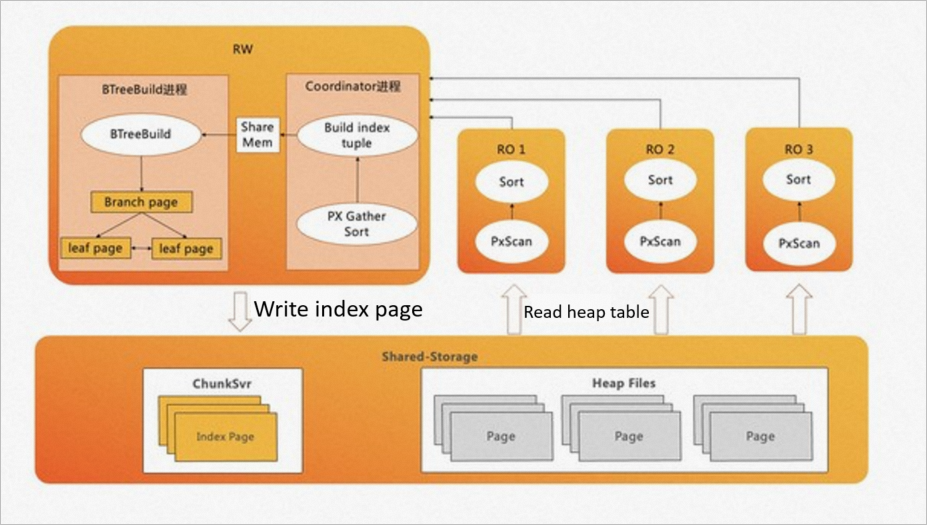 PolarDB for PostgreSQL (Oracle互換) のePQエンジンでは、読み取り専用ノードを使用してデータの並べ替えを高速化します。 インデックスページを作成するためにパイプライン技術が使用される。 バッチ書き込みは、インデックスページの書き込み速度を上げるために使用されます。 説明
PolarDB for PostgreSQL (Oracle互換) のePQエンジンでは、読み取り専用ノードを使用してデータの並べ替えを高速化します。 インデックスページを作成するためにパイプライン技術が使用される。 バッチ書き込みは、インデックスページの書き込み速度を上げるために使用されます。 説明PolarDB for PostgreSQL (Oracle互換) では、Bツリーインデックスは標準モードまたは同時モードで作成できます。
Usage
PolarDB for PostgreSQL (Oracle互換) ePQは、調整やレポートなどの分析ライトビジネスに適しています。
分析クエリにePQを使用します。
デフォルトでは、ePQ機能は PolarDB for PostgreSQL (Oracleと互換) で無効になっています。 この機能を使用するには、次のパラメーターを設定します。
パラメーター
説明
polar_enable_px
ePQ機能を有効にするかどうかを指定します。 デフォルト値:off 有効な値:
on
off
polar_px_max_workers_number
1つのノードで並列実行するワーカープロセスの最大数を指定します。 デフォルト値:30。 有効な値: 0 ~ 2147483647 このパラメーターは、単一のノードの最大並列処理度を制限します。
説明ノード上のすべてのセッションのワーカープロセスの数は、この値を超えることはできません。
polar_px_dop_per_node
現在のセッションの並列処理の度合いを指定します。 デフォルト値は 1 です。 有効な値: 1 ~ 128 値をCPUコアの数に等しく設定することを推奨します。 パラメーターをNに設定すると、各ノードのN個のワーカープロセスを1つのセッションで使用できます。
polar_px_nodes
ePQに含まれる読み取り専用ノードを指定します。 このパラメーターは既定では空です。これは、すべての読み取り専用ノードが並列実行に使用されることを示します。 ノードが複数ある場合は、カンマ (,) で区切ります。
px_worker
特定のテーブルに対してePQが有効かどうかを指定します。 デフォルトでは、ePQはどのテーブルに対しても有効ではありません。 ePQは特定のコンピューティングリソースを消費します。 コンピューティングリソースを節約するために、ePQが有効なテーブルを指定できます。 例:
ALTER TABLE t1 SET(px_workers=-1) は、ePQがt1テーブルに対して有効であることを示します。
ALTER TABLE t1 SET(px_workers=-1) は、t1テーブルに対してePQが無効であることを示します。
ALTER TABLE t1 SET(px_workers=0) は、ePQがt1テーブルに対して無効であることを示します。
次の例は、ePQが有効かどうかを示しています。 実施例では、単一のテーブルのみが使用される。
テストテーブルを作成し、データを挿入します。
CREATE TABLE test(id int); INSERT INTO test SELECT generate_series(1,1000000);実行プランを照会します。
EXPLAIN SELECT * FROM test;サンプル結果:
QUERY PLAN -------------------------------------------------------- Seq Scan on test (cost=0.00..35.50 rows=2550 width=4) (1 row)説明デフォルトでは、ePQ機能は無効になっています。 実行プランはSeq Scanで、ネイティブのPostgreSQLで使用されます。
ePQ機能を有効にします。
ALTER TABLE test SET (px_workers=1); SET polar_enable_px = on; EXPLAIN SELECT * FROM test;サンプル結果:
QUERY PLAN ------------------------------------------------------------------------------- PX Coordinator 2:1 (slice1; segments: 2) (cost=0.00..431.00 rows=1 width=4) -> Seq Scan on test (scan partial) (cost=0.00..431.00 rows=1 width=4) Optimizer: PolarDB PX Optimizer (3 rows)ePQに関係する計算ノードを指定します。
すべての読み取り専用ノードの名前を照会します。
CREATE EXTENSION polar_monitor; SELECT name,host,port FROM polar_cluster_info WHERE px_node='t';サンプル結果:
name | host | port -------+-----------+------ node1 | 127.0.0.1 | 5433 node2 | 127.0.0.1 | 5434 (2 rows)説明この例では、クラスターには2つの読み取り専用ノードnode1とnode2があります。
node1がePQに関与することを指定します。
SET polar_px_nodes = 'node1';ePQに関係するノードを照会します。
SHOW polar_px_nodes;サンプル結果:
polar_px_nodes ---------------- node1 (1 row)説明node1はePQに関与しています。
テストテーブル内のすべてのデータを照会します。
EXPLAIN SELECT * FROM test;サンプル結果:
QUERY PLAN ------------------------------------------------------------------------------- PX Coordinator 1:1 (slice1; segments: 1) (cost=0.00..431.00 rows=1 width=4) -> Partial Seq Scan on test (cost=0.00..431.00 rows=1 width=4) Optimizer: PolarDB PX Optimizer (3 rows) QUERY PLAN
パーティション分割テーブルクエリにePQを使用します。
ePQ機能を有効にします。
SET polar_enable_px = ON;パーティションテーブルのePQ機能を有効にします。
SET polar_px_enable_partition = true;説明パーティションテーブルのePQ機能はデフォルトで無効になっています。
マルチレベルパーティションテーブルのePQ機能を有効にします。
SET polar_px_optimizer_multilevel_partitioning = true;
ePQ機能を使用して、パーティションテーブルに対して次の操作を実行できます。
範囲パーティションから並列にデータを照会します。
リストパーティションから並列にデータを照会します。
単一列のハッシュパーティションから並列にデータを照会します。
パーティションを剪定します。
インデックスが並列にあるパーティションテーブルからデータを照会します。
結合されたパーティションテーブルからのデータのクエリ
マルチレベルのパーティション分割テーブルからデータを照会します。
ePQを使用したインデックス作成プロセスの高速化
アクセラレーション機能を有効にします。
SET polar_px_enable_btbuild = on;インデックスを作成します。
CREATE INDEX t ON test(id) WITH(px_build = ON);テーブルスキーマを照会します。
\d testサンプル結果:
Table "public.test" Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+--------- id | integer | | | id2 | integer | | | Indexes: "t" btree (id) WITH (px_build=finish)
説明インデックスはB-Treeモードでのみ作成できますが、INCLUDEモードでは作成できません。 式型のインデックス列はサポートされていません。
ePQ機能を使用してインデックスの作成プロセスを高速化する場合は、次のパラメーターを設定します。
パラメーター
説明
polar_px_dop_per_node
ePQ機能を使用してインデックスの作成プロセスを高速化する場合の並列処理の程度を指定します。 デフォルト値は 1 です。 有効な値: 1 ~ 128
polar_px_enable_replay_wait
ePQ機能を使用してインデックスの作成プロセスを高速化する場合、現在のセッションの高速化機能を手動で有効にする必要はありません。 アクセラレーション機能は自動的に有効になります。 これにより、最新に更新されたデータエントリをインデックスに追加できるようになり、インデックステーブルの整合性が保たれます。 インデックスが作成されると、システムはパラメーターをデータベースのデフォルト値にリセットします。
polar_px_enable_btbuild
アクセラレーション機能を有効にするかどうかを指定します。 デフォルト値OFF。 有効な値: ONとOFF。
polar_bt_write_page_buffer_size
インデックス作成時の書き込みI/O操作に関するポリシーを指定します。 デフォルトでは、パラメーターは0に設定されています。 この値は、インデックスを作成するときに、インデックス付きエントリがブロックごとにディスクにフラッシュされることを示します。 測定単位はブロックである。 最大値は8192です。 値を4096に設定することを推奨します。
このパラメーターを0に設定すると、インデックスページが完全に読み込まれたときに、インデックスページのすべてのインデックスエントリがブロックごとにディスクにフラッシュされます。
このパラメーターを0以外の値に設定した場合、フラッシュするインデックス付きエントリは、polar_bt_write_page_buffer_sizeパラメーターで指定されたサイズのカーネルバッファーに格納されます。 バッファが完全にロードされると、バッファ内のすべてのインデックス付きエントリが一度にディスクにフラッシュされる。 これにより、頻繁なI/Oスケジューリングに起因するパフォーマンスのオーバーヘッドが防止されます。 このパラメーターは、20% によるインデックスの作成に必要な時間を短縮するのに役立ちます。