ツリーの深さは、決定ツリーモデルにおいてルート頂点から最も遠いリーフ頂点までの経路上のリーフ頂点の数を指す。 Tree Depthコンポーネントは、モデルの複雑さとフィッティング能力に影響を与える重要なパラメータです。 より深いツリーは、より多くのデータモードをキャプチャできます。 これは過剰フィットを引き起こす可能性があります。 より浅い木はアンダーフィットを引き起こすかもしれません。 したがって、モデルのパフォーマンスと一般化機能を確保するために、適切なツリーの深さを選択する必要があります。
コンポーネントの設定
方法1: パイプラインページでコンポーネントを設定する
Tree Depthコンポーネントは、Platform for AI (PAI) コンソールのMachine Learning Designerのパイプラインページに追加できます。 下表に、各パラメーターを説明します。
タブ | パラメーター | 説明 |
フィールド設定 | エッジテーブル: 開始頂点列 | エッジテーブルの開始頂点列。 |
エッジテーブル: 端頂点列 | エッジテーブルの末尾の頂点列。 | |
チューニング | 労働者 | 並列ジョブ実行の頂点の数。 並列性とフレームワーク通信コストの程度は、このパラメータの値とともに増加します。 |
Workerあたりのメモリサイズ | 1つのジョブで使用できるメモリの最大サイズ。 単位:MB。 デフォルト値: 4096 使用済みメモリのサイズがこのパラメーターの値を超えると、 | |
データ分割サイズ (MB) | データ分割サイズ。 単位:MB。 デフォルト値: 64。 |
方法2: PAIコマンドを使用してコンポーネントを構成する
Tree Depthコンポーネントは、PAIコマンドを使用して設定できます。 SQLスクリプトコンポーネントを使用してPAIコマンドを実行できます。 詳細については、「SQLスクリプト」トピックの「シナリオ4: SQLスクリプトコンポーネント内でPAIコマンドを実行する」をご参照ください。
PAI -name TreeDepth
-project algo_public
-DinputEdgeTableName=TreeDepth_func_test_edge
-DfromVertexCol=flow_out_id
-DtoVertexCol=flow_in_id
-DoutputTableName=TreeDepth_func_test_result;パラメーター | 必須 / 任意 | デフォルト値 | 説明 |
inputEdgeTableName | 対象 | デフォルト値なし | 入力エッジテーブルの名前。 |
inputEdgeTablePartitions | 非対象 | フルテーブル | 入力エッジテーブルのパーティション。 |
fromVertexCol | 対象 | デフォルト値なし | 入力エッジテーブルの開始頂点列。 |
toVertexCol | 対象 | デフォルト値なし | 入力エッジテーブルの末尾の頂点列。 |
outputTableName | 対象 | デフォルト値なし | 出力テーブルの名前。 |
outputTablePartitions | 非対象 | デフォルト値なし | 出力テーブルのパーティション。 |
ライフサイクルの設定 (Set lifecycle) | 非対象 | デフォルト値なし | 出力テーブルのライフサイクル。 |
workerNum | 非対象 | 指定なし | 並列ジョブ実行の頂点の数。 並列性とフレームワーク通信コストの程度は、このパラメータの値とともに増加します。 |
workerMem | 非対象 | 4096 | 1つのジョブで使用できるメモリの最大サイズ。 単位:MB。 デフォルト値: 4096 使用済みメモリのサイズがこのパラメーターの値を超えると、 |
splitSize | 非対象 | 64 | データ分割サイズ。 |
例:
SQLスクリプトコンポーネントを頂点としてキャンバスに追加します。 [スクリプトモードの使用] および [テーブルの作成文を追加するかどうか] チェックボックスをオフにし、[SQLスクリプト] エディターに次のSQL文を入力します。
drop table if exists TreeDepth_func_test_edge; create table TreeDepth_func_test_edge as select * from ( select '0' as flow_out_id, '1' as flow_in_id union all select '0' as flow_out_id, '2' as flow_in_id union all select '1' as flow_out_id, '3' as flow_in_id union all select '1' as flow_out_id, '4' as flow_in_id union all select '2' as flow_out_id, '4' as flow_in_id union all select '2' as flow_out_id, '5' as flow_in_id union all select '4' as flow_out_id, '6' as flow_in_id union all select 'a' as flow_out_id, 'b' as flow_in_id union all select 'a' as flow_out_id, 'c' as flow_in_id union all select 'c' as flow_out_id, 'd' as flow_in_id union all select 'c' as flow_out_id, 'e' as flow_in_id )tmp; drop table if exists TreeDepth_func_test_result; create table TreeDepth_func_test_result ( node string, root string, depth bigint );データ構造
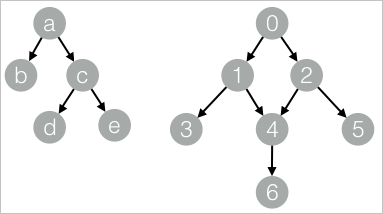
SQLスクリプトコンポーネントを頂点としてキャンバスに追加します。 [スクリプトモードの使用] および [テーブル文の作成] チェックボックスの選択を解除し、SQL Scriptエディタで次のPAIコマンドを入力して、追加した2つのコンポーネントを接続します。
drop table if exists ${o1}; PAI -name TreeDepth -project algo_public -DinputEdgeTableName=TreeDepth_func_test_edge -DfromVertexCol=flow_out_id -DtoVertexCol=flow_in_id -DoutputTableName=${o1};キャンバスの左上隅の
 をクリックしてパイプラインを実行します。
をクリックしてパイプラインを実行します。手順2でSQLスクリプトコンポーネントを右クリックし、[データの表示]> [SQLスクリプトの出力] を選択してトレーニング結果を表示します。
| node | root | depth | | ---- | ---- | ----- | | a | a | 0 | | b | a | 1 | | c | a | 1 | | d | a | 2 | | e | a | 2 | | 0 | 0 | 0 | | 1 | 0 | 1 | | 2 | 0 | 1 | | 3 | 0 | 2 | | 4 | 0 | 2 | | 5 | 0 | 2 | | 6 | 0 | 3 |