背景情報
大規模言語モデル (LLM) のパラメーター数は指数関数的に増加しています。例えば、オープンソースの DeepSeekV3-671B モデルは 700 GB を超えます。その結果、モデルの読み込み時間が推論サービスの効率を妨げる主要なボトルネックとなっています。この問題は、特に以下のシナリオで顕著です:
エラスティックスケーリング:モデルの読み込み時間は、サービスのスケーリングの俊敏性に直接影響します。
複数インスタンスのデプロイメント:OSS、NAS、CPFS などのリモートストレージからモデルを同時にプルすると、帯域幅の競合が発生し、モデルの読み込み効率がさらに低下します。
これらの課題に対処するため、Platform for AI - Elastic Algorithm Service (PAI-EAS) は Model Weight Service (MoWS) 機能をリリースしました。その中核となる技術的特徴は以下の通りです:
分散キャッシュアーキテクチャ:ノードのメモリリソースを活用して、重みキャッシュプールを構築します。
高速転送メカニズム:Remote Direct Memory Access (RDMA) に基づくマシン間接続により、低レイテンシーのデータ転送を実現します。
インテリジェントなシャーディング戦略:シャードの並列転送と完全性チェックをサポートします。
メモリ共有の最適化:単一マシン上の複数プロセス間でゼロコピーの重み共有を実装します。
インテリジェントな重みプリフェッチ:アイドル期間中にモデルの重みを事前に読み取ります。
効率的なキャッシュポリシー:インスタンス間でモデルシャードのロードバランシングを確保します。
大規模なインスタンスクラスターにおいて、このソリューションは以下の結果を達成します:
従来のプルモードと比較して、スケーリング速度が 10 倍に向上します。
帯域幅使用率が 60% 以上向上します。
サービスのコールドスタート時間が秒単位に短縮されます。
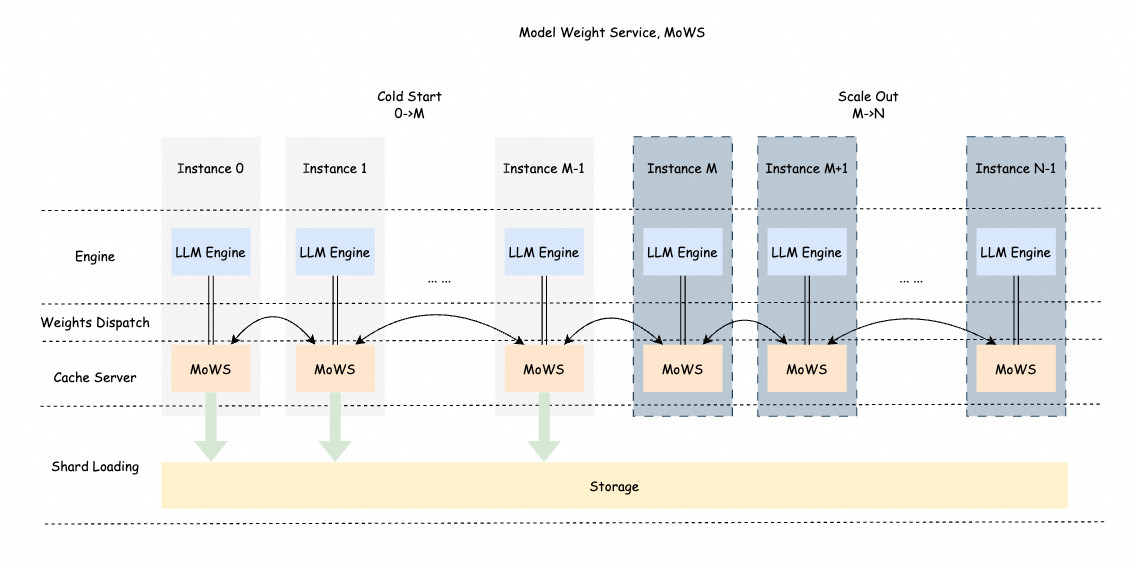
MoWS は、複数インスタンス間の帯域幅リソースを最大限に活用し、高速かつ効率的なモデルの重み転送を実現します。MoWS は、モデルの重みのローカルキャッシュをサポートするだけでなく、インスタンス間での重み共有も可能にします。大規模なパラメーターを持つモデルや大規模なインスタンスデプロイメントの場合、MoWS はサービスのスケーリング効率と起動速度を大幅に向上させます。
操作手順
PAI コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、Elastic Algorithm Service (EAS) をクリックします。
[サービスをデプロイ] をクリックします。[カスタムモデルのデプロイ] セクションで、[カスタムデプロイ] をクリックします。
Custom Deployment ページで、以下の主要なパラメーターを設定します。その他のパラメーターの詳細については、「カスタムデプロイ」をご参照ください。
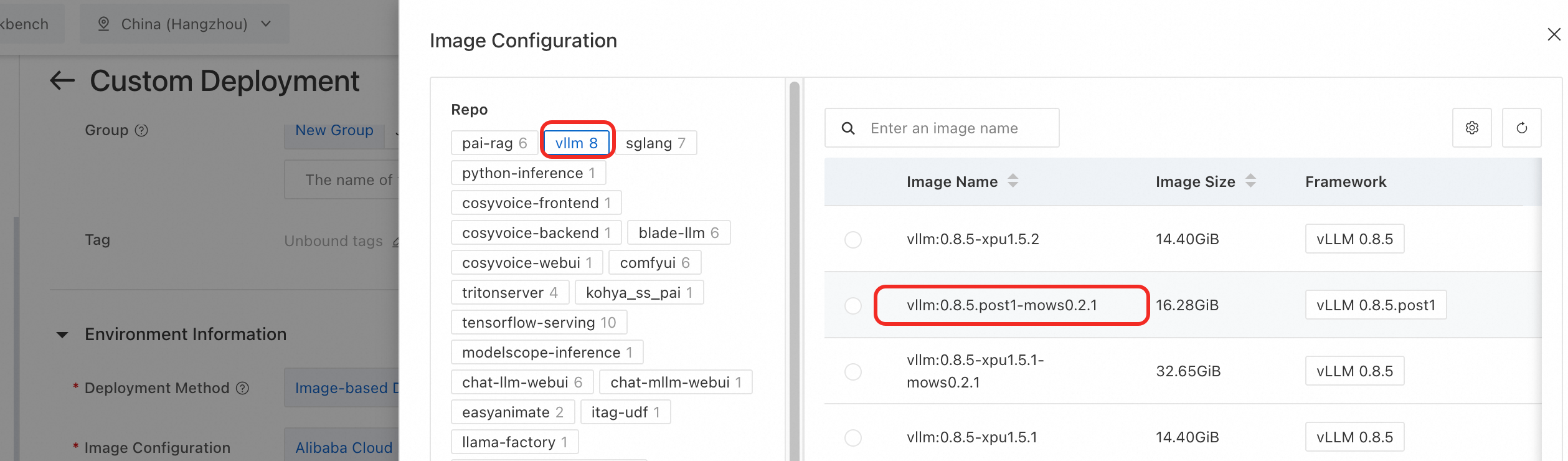
Environment Information の Image Configuration セクションで、Alibaba Cloud Image を選択します。vllm イメージリポジトリから、mows タグが付いたイメージバージョンを選択します。
 重要
重要起動コマンドに、vllm および sglang 推論エンジンでサポートされている
--load-format=mowsパラメーターを追加します。[リソース情報] セクションで、[リソースタイプ] を EAS Resource Group または Resource Quota に設定します。
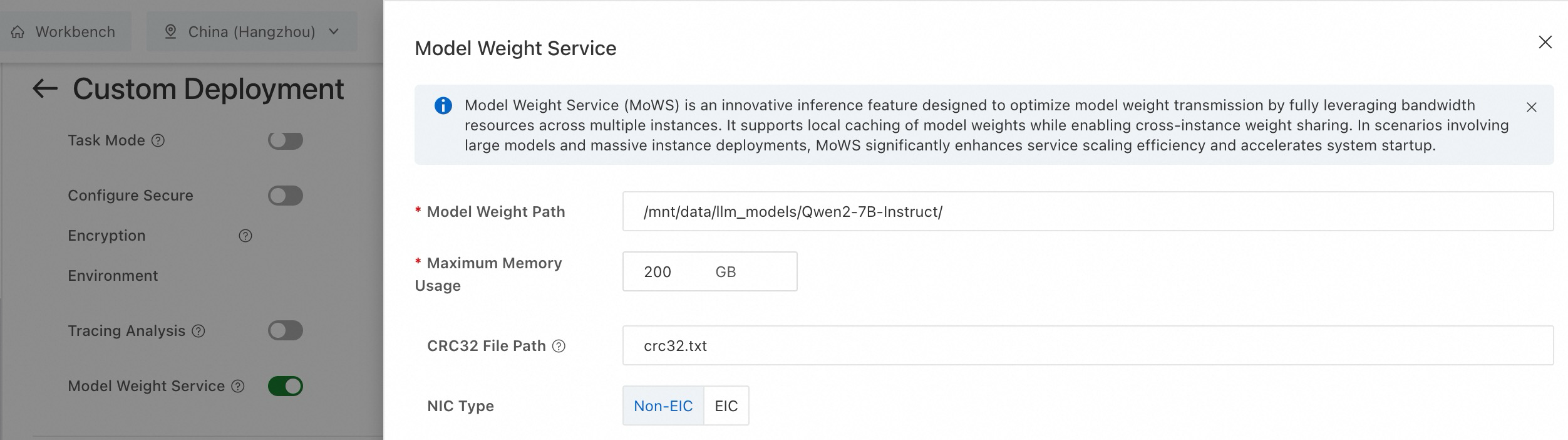
Features セクションで、Model Weight Service (MoWS) を有効にし、パラメーターを以下のように設定します。
設定項目
説明
例
Model Weight Path
必須。モデルの重みのパス。OSS、NAS、または CPFS のマウントパスを指定できます。
/mnt/data/llm_models/Qwen2-7B-Instruct/Maximum Memory Usage
必須。単一インスタンスで MoWS が使用するメモリリソースの量。単位:GB。
200
CRC32 File Path
任意。モデルの読み込み時にデータ検証に使用されます。crc32 ファイルの名前を入力します。これは、上記で設定したモデルの重みパスからの相対パスです。
ファイル形式:[crc32] [relative_file_path]
デフォルト値:"crc32.txt"
crc32.txt
その内容は次のとおりです:
3d531b22 model-00004-of-00004.safetensors 1ba28546 model-00003-of-00004.safetensors b248a8c0 model-00002-of-00004.safetensors 09b46987 model-00001-of-00004.safetensorsNIC Type
任意。ハードウェアが Elastic Interconnect Card (EIC) のネットワークインターフェースコントローラー (NIC) である場合は、EIC を選択します。
非 EIC NIC
パフォーマンス上の利点
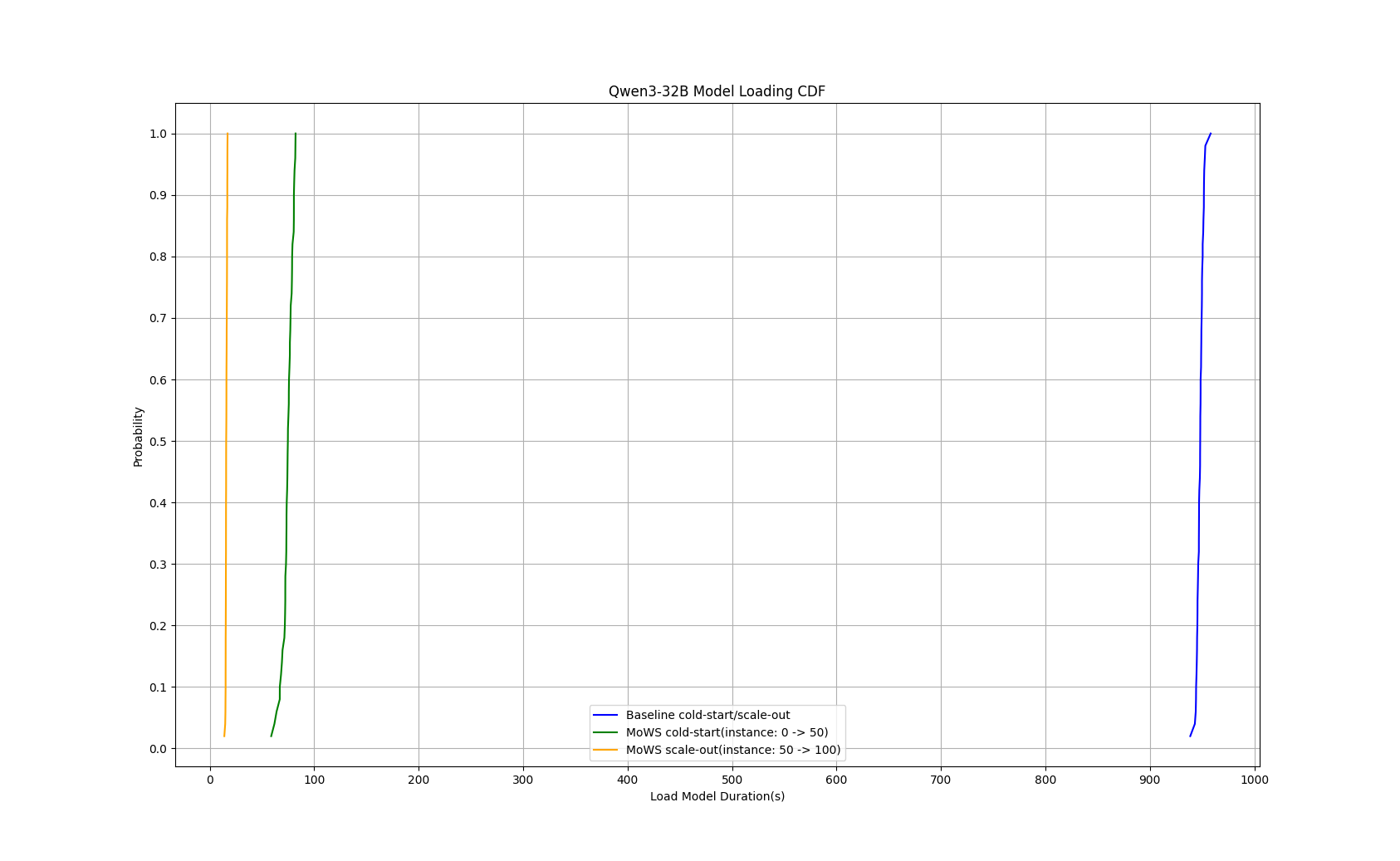
Qwen3-8B モデルの評価では、推論サービスの TP99 コールドスタート時間が 235 秒から 24 秒に短縮され、89.8% の削減となりました。インスタンスのスケールアウト時間は 5.7 秒に短縮され、97.6% の削減となりました。
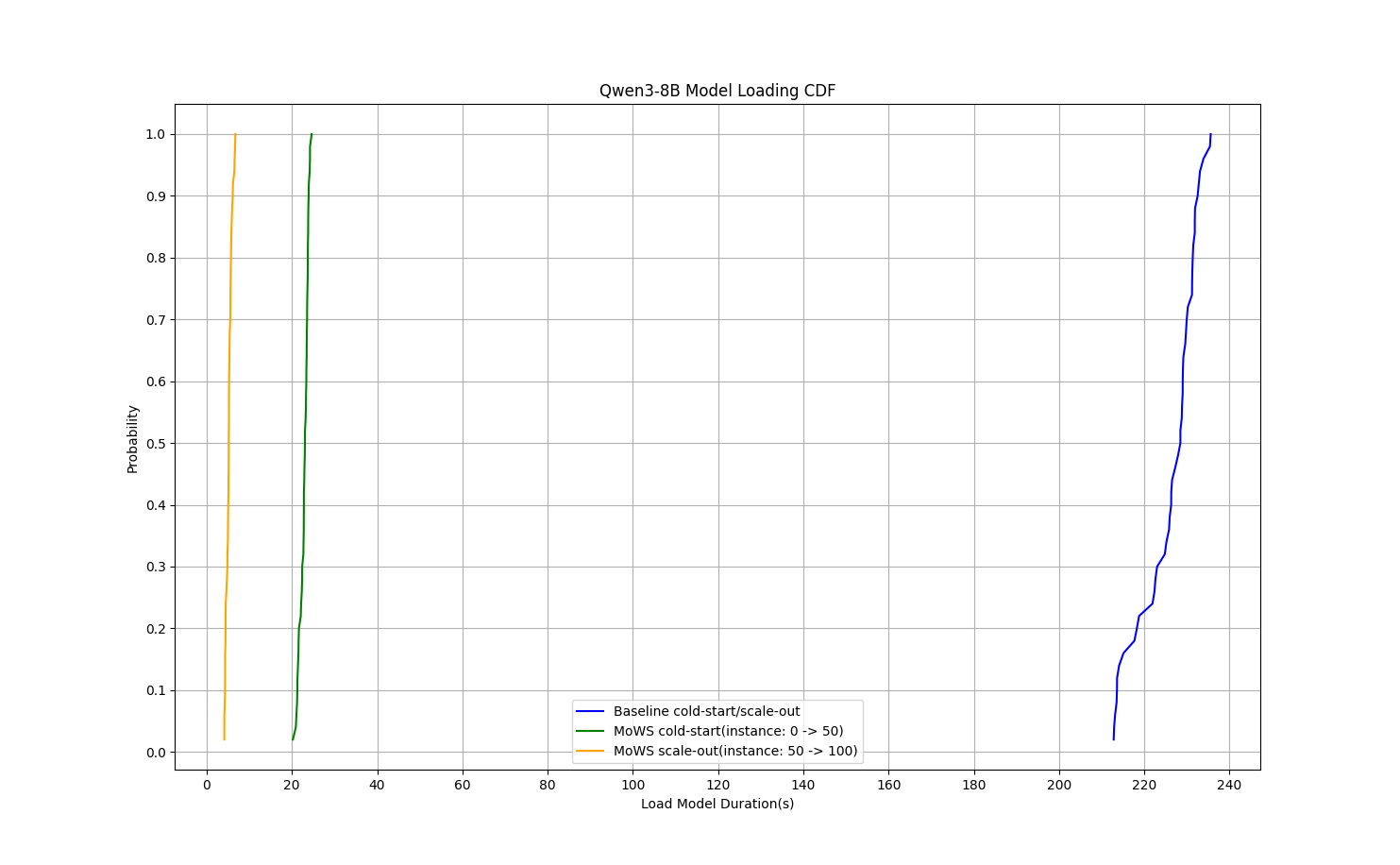
Qwen3-32B モデルの評価では、推論サービスのコールドスタート時間が 953 秒から 82 秒に短縮され、91.4% の削減となりました。インスタンスのスケールアウト時間は 17 秒に短縮され、98.2% の削減となりました。