リソースクォータを作成した後、スケーリング、子クォータの追加、リストや詳細の表示ができます。
Lingjun AI 計算リソースでは、ノード間の高速ネットワーク接続を有効にするために、すべてのノードで同じ hz 識別子を使用する必要があります。
親子リソースクォータの作成
リソースクォータページでは、親子リソースクォータを作成できます。これらのクォータは QuotaTree と呼ばれるツリー構造を形成し、よりきめ細かいリソース管理と割り当てを実現します。親子関係の図については、「機能」をご参照ください。
-
親リソースクォータの作成: Add Resource Quota をクリックして、ルートリソースクォータを作成します。詳細については、「クラウドネイティブリソースクォータ」をご参照ください。
-
サブレベルリソースクォータの作成: 新しいリソースクォータを追加するか、既存のリソースクォータのActions 列で New Child-level Resource Quota をクリックします。

クォータのスケーリング
リソースクォータを作成した後、ジョブの要件に基づいてそのサイズを調整し、コストを管理できます。

リソースクォータ ページで、対象のリソースクォータを見つけ、Actions 列の Scale をクリックします。リソースクォータをスケールするには、その Source または Nodes/Instance Type を調整します。
-
スケールアップ:新しいソースや仕様を追加するか、既存のものを調整して、利用可能なリソースを増やします。
-
スケールダウン:関連する仕様のノード数を減らすか、特定の仕様を削除して、アイドルリソースを解放します。

クォータリストの表示
[リソースクォータ] ページで、Lingjun Intelligent Computing resources または General Computing Resources タブに切り替えると、対応する作成済みリソースクォータのリストが表示されます。

リストには、各リソースクォータの基本的な情報 (名前、タイプ、関連ワークスペース、ステータス、GPU タイプ、ノード数、リソース量 (GPU、CPU コア、メモリなど)) が表示されます。次の操作を実行できます:
-
リソースクォータのフィルタリング:[Name/ID] または [Status] でクォータをフィルタリングします。
-
リソース量によるソート:合計または割り当て済みの CPU、メモリ、または GPU リソースでソートして、リソースの分散と使用状況を表示します。
クォータ詳細の表示
[リソースクォータ] ページで、Lingjun Intelligent Computing resources または General Computing Resources タブに切り替え、リソースクォータ名をクリックすると詳細が表示されます。GPU、CPU、メモリなどのリソースのスケジュール済み、デキュー済み、および送信済みの量、ならびにアイドル状態を表示することで、リソース使用状況の概要とジョブのキューイング状況を把握できます。
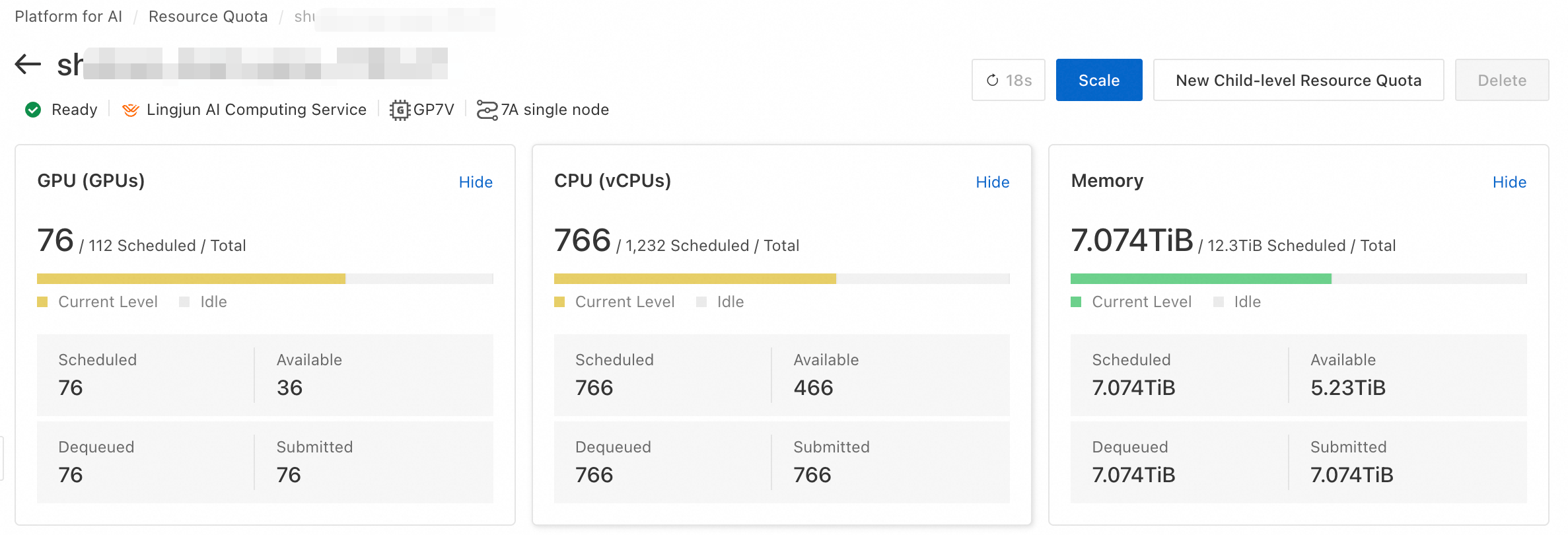
概要
「リソースクォータ詳細」ページの Overview タブで、設定を表示および更新します。
-
[Basic Information]:リソースクォータ名、ID、および関連ワークスペースが含まれます。
-
編集アイコン
 をクリックして、Resource Quota Name、関連付けられたワークスペース、および Tag を更新します。
をクリックして、Resource Quota Name、関連付けられたワークスペース、および Tag を更新します。 -
ワークスペースを関連付けた後、ワークスペース名をクリックしてその詳細ページに移動し、そのワークスペースで AI 開発のためにリソースクォータを使用します。
-
-
[Resource Information]:
-
リソースグループ情報:リソースクォータが属するリソースグループ、およびその親子リソースクォータが含まれます。親子関係の図については、「親子リソースクォータの作成」セクションをご参照ください。リソース名をクリックすると、その詳細ページに移動できます。
-
[GPU Default Driver]:GPU タイプ、ドライバー、SDK、およびコンテナイメージのカスタム要件を満たすためにデフォルトドライバーを設定できます。
-
-
[Network Information]:VPC、セキュリティグループ、NAT ゲートウェイなどのネットワークリソースに対する制限を表示します。この情報は、ネットワークレイヤーでのリソースクォータのスコープを定義します。
-
[Scheduling Information]:リソースクォータのスケジューリング情報を表示し、その設定を更新できます。
-
[Scheduling Policy]:基盤となる原則に基づいて適切なスケジューリングポリシーを選択し、デキュー効率とコンピューティングリソース使用率を向上させます。設定の詳細については、「スケジューリングポリシー」をご参照ください。
-
[Child-level Preemption]および[Self-level Preemption]:リソースが限られている場合、現在のリソースクォータでキューイング中のジョブは、子レベルまたは自己レベルのクォータで実行中のジョブをプリエンプトできます。設定の詳細については、「プリエンプションポリシー」をご参照ください。
-
[Idle Sharing]:デフォルトで有効になっています。これにより、ジョブは現在のクォータとその子クォータのアイドルリソースを使用できます。
-
-
[Resource Change History]:作成、スケーリング、削除操作の履歴を表示します。レコードには、変更タイプ、開始者、ステータス、およびターゲットインスタンスタイプが表示されます。
-
[Event History]:ノードのスケーリング、スケジューリングの有効化/無効化、ノードのアタッチ/デタッチなど、クォータに関連するイベントを表示します。履歴には、イベントのトリガー時間、開始者、および内容が含まれます。
-
[Advanced Information]:
-
[Enable Local Cache]:Lingjun AI 計算リソースクォータでは、この機能を有効にしてデータをコンピューティングノードの近くにキャッシュし、読み取りパフォーマンスを向上させることができます。この機能を有効にすると、ノード上の一部のリソースが消費されるため、十分なリソースがあることを確認してください。詳細については、「Lingjun AI 計算のキャッシュアクセラレーション」をご参照ください。
-
ストレージサービス:
OSS、汎用NAS、およびBMCPFSのローカルキャッシュをサポートします。 -
[Supports RDMA]:キャッシュで高速化された読み取りは RDMA (tail) をサポートし、より高い通信帯域幅を提供してデータ読み取りパフォーマンスの要件を満たします。
-
-
ENI ウォームアップ:リソースクォータ内のノードに対して Elastic Network Interface (ENI) を事前にプロビジョニングし、ジョブの起動を高速化します。この機能を有効にすると ENI リソースが消費されるため、VPC サブネットに十分な数の利用可能な IP アドレスがあることを確認してください。子リソースクォータに割り当てられたノードの場合、最下位レベルのクォータの設定が優先されます。
-
ノード

「リソースクォータ詳細」ページで、Nodes タブに移動して、クォータのノード情報を表示および管理します:
-
ノード詳細: Node Specification、Dedicated Resource Group Name/ID、リソースの In Use と Total の量 (GPU Type、Number of GPUs、および CPU Cores)、ゾーン (AZ)、高速ネットワーク相互接続ゾーン (HZ)、およびノードで作成された Tasks と Instances が含まれます。
-
ジョブとインスタンスの詳細: ターゲットノードの Tasks および Instances 列で、対応する番号をクリックすると、ジョブとインスタンスの詳細が表示されます。
-
ノードのフィルタリング:ノードステータスまたは注文ステータスでノードをフィルタリングするか、リソース量でソートします。
-
hz (高速ネットワーク相互接続ゾーン):Lingjun AI 計算のシナリオでは、
hzは、基盤となるコンピューティングリソースが存在する高速ネットワークゾーンを示します。同じhz識別子を持つリソースは、高速ネットワークを介して通信できます。
-
-
[Node Status]:サポートされているステータス:
-
[Ready]:コンピューティングノードは利用可能です。
-
[Not Ready]:コンピューティングノードは初期化中です。
-
[Scheduling Disabled]:ノードはスケジューリングできません。考えられる原因:
-
[Stopped by User]:ユーザーがノードのスケジューリングを手動で無効にしました。
-
[Expired]:ノードのサブスクリプションが期限切れになりました。
-
Recovering:ノードは回復中です。このノードでジョブが実行されている場合は、回復を中断しないように、速やかに停止してください。
-
Unknown:原因は不明です。サポートについては、アカウントマネージャーにお問い合わせください。
-
-
-
ノードの管理:
-
ノードでのスケジューリングの停止/開始: 対象のノードの Actions 列で、Stop Scheduling または Start Scheduling をクリックして、そのノードでのリソーススケジューリングを一時停止または再開します。
-
ノードのクリア: 対象のノードのActions 列でClear Node をクリックすると、そのノード上のすべてのジョブ (DSW、DLC、または EAS ジョブを含む) が終了します。
-
ノードリストのダウンロード:
 アイコンをクリックして、現在のページからノードリストをエクスポートし、ローカルマシンにダウンロードします。
アイコンをクリックして、現在のページからノードリストをエクスポートし、ローカルマシンにダウンロードします。
-
ジョブ

リソースクォータ詳細ページの Job タブでは、ジョブステータス、リソースクォータ、インスタンス情報、GPU カード数、CPU コア、メモリサイズなどの主要なメトリクスを含む、Queuing および Dequeued ジョブのリソース使用量が表示されます。
-
ジョブのフィルタリング:[Type] または [Job Status] でフィルタリングします。
-
詳細の表示:ジョブ名、リソースクォータ名、またはワークスペース名をクリックして、対応する詳細ページに移動します。
-
現在のクォータ内のジョブのフィルタリング:[View Current Resource Quota] スイッチを有効にすると、このクォータ内で作成されたジョブのみが表示されます。
ユーザー

「リソースクォータ詳細」ページの User タブでは、GPU カード数、CPU コア数、メモリサイズ、ジョブ数などの主要なメトリックを含む、クォータ内のユーザーごとのリソース使用量を確認できます。
-
現在のクォータのユーザーのフィルタリング:[View Current Resource Quota Users] スイッチを有効にすると、子クォータではなく、このクォータに直接ジョブを送信したユーザーのみが表示されます。
-
ジョブの詳細の表示: ユーザーの Number of Tasks 列で Details をクリックして、そのユーザーが送信したジョブを表示します。 ジョブリストページで、ジョブ名をクリックしてその詳細を表示します。
モニタリング
リソースクォータ詳細ページのMonitoring タブに移動すると、モニタリング情報を表示できます。
-
GPU 計算能力のヒートマップ (リアルタイム使用率)、リソースレベル、およびジョブステータスの分布が表示されます。

-
クォータとノードの 2 つの観点からモニタリング情報を表示します。これには、CPU、メモリ、ディスク、ネットワーク、GPU のメトリクスが含まれます。メトリクスの詳細、および CloudMonitor と ARMS を使用してデータを表示し、アラートを設定し、メトリクスを購読する方法については、「リソースクォータのモニタリングとアラート」をご参照ください。

トポロジー
「リソースクォータ詳細」ページで、Topology タブに移動して、クォータのトポロジを表示します。2 つのビューが利用可能です。
-
リソースビュー:現在のクォータとその子クォータのCPU、メモリ、GPUリソースの割り当てを表示します。

-
ジョブビュー:現在のクォータとその子クォータで作成されたジョブの総数を、ステータス別の内訳とともに表示します。

クォータの削除
Resource Quota ページで、Actions 列にある Delete をクリックして、不要になったリソースクォータを削除します。リソースクォータを削除する前に、ワークスペースとの関連付けを解除する必要があります。詳細については、「概要」をご参照ください。
