このトピックでは、Kohya を使用して Low-Rank Adaptation(LoRA)モデルをトレーニングする方法について説明します。
PAI ArtLab コンソール にログインします。
背景情報
Stable Diffusion(SD)は、テキストから画像を生成するオープンソースのディープ ラーニング モデルです。 SD WebUI は、テキストから画像への変換と画像から画像への変換の操作をサポートする、SD の Web ベースのユーザーインターフェースです。 また、拡張機能やモデルのインポートによって高度にカスタマイズすることもできます。
SD WebUI で画像を生成するには、それぞれに独自の特徴とアプリケーションを持つさまざまなモデルが必要です。 各モデルには、特定のトレーニング データセットと戦略が必要です。 LoRA は、高速で、小さなファイルを生成し、ハードウェア要件が低い、軽量なモデル微調整メソッドです。
Kohya は、LoRA モデルをトレーニングするための人気のあるオープンソース サービスです。 Kohya GUI パッケージは、専用のトレーニング環境とユーザーインターフェースを提供し、他のプログラムからの干渉を防ぎます。 SD WebUI も拡張機能を介してモデル トレーニングをサポートしていますが、このメソッドは競合やエラーを引き起こす可能性があります。
他のモデル微調整メソッドの詳細については、「モデル」をご参照ください。
LoRA モデルの概要
LoRA(大規模言語モデルの低ランク適応)は、基盤モデルとデータセットに基づいて、様式化されたモデルをトレーニングする方法です。 このプロセスにより、高度にカスタマイズされた画像生成が可能になります。
ファイルの仕様は次のとおりです。
ファイル サイズ:通常、数 MB から数百 MB の範囲です。 正確なサイズは、トレーニングされたパラメーターと基盤モデルの複雑さによって異なります。
ファイル形式:標準のファイル名拡張子として .safetensors を使用します。
ファイル アプリケーション:特定のチェックポイント基盤モデルで使用する必要があります。
ファイル バージョン:Stable Diffusion v1.5 と Stable Diffusion XL バージョンを区別する必要があります。 モデルはこれらのバージョン間で交換できません。
LoRA 微調整モデル
Stable Diffusion v1.5 モデル、v2.1 モデル、または Stable Diffusion XL base 1.0 モデルなどの基盤モデルは、基本的な材料と考えることができます。 LoRA モデルは特別な調味料として機能し、独自のスタイルと創造性を加えます。 LoRA モデルは、基盤モデルの制限を克服するのに役立ち、コンテンツ作成をより柔軟で効率的、そしてパーソナライズされたものにします。
たとえば、Stable Diffusion v1.5 モデルには次の制限があります。
不正確な詳細:特定の詳細または複雑なコンテンツを含む画像を生成する場合、モデルはすべての詳細を正確に再現するのに苦労する可能性があります。 これにより、詳細やリアリズムに欠ける画像が生成される可能性があります。
一貫性のない論理構造:生成された画像内のオブジェクトのレイアウト、比率、および照明は、現実世界の原則に準拠していない可能性があります。
一貫性のないスタイル:非常に複雑でランダムな生成プロセスにより、一貫したスタイルを維持したり、ニューラル スタイル転送を確実に実行したりすることが困難になります。
オープンソース コミュニティは、基盤モデルを微調整することによって作成された多くの優れたモデルを提供しています。 元の基盤モデルと比較して、これらの微調整されたモデルは、より豊かなディテール、より明確なスタイルの特徴、そしてより制御可能なコンテンツを持つ画像を生成します。 たとえば、次の画像は Stable Diffusion v1.5 モデルの結果と微調整されたモデルの結果を比較しており、画像品質の大幅な改善を示しています。

さまざまなタイプの LoRA モデル
LyCORIS(LoHa/LoCon の前身)
LyCORIS は LoRA の拡張バージョンであり、LoRA の 17 層と比較して、ニューラル ネットワークの 26 層を微調整できます。 これにより、パフォーマンスが向上します。 LyCORIS はより表現力豊かで、パラメーターが多く、LoRA よりも多くの情報を処理できます。 LyCORIS のコア コンポーネントは LoHa と LoCon です。 LoCon は SD モデルの各レベルを調整し、LoHa は処理される情報量を 2 倍にします。
LoRA と同じ方法で使用されます。 テキスト エンコーダー、U-Net、および DyLoRA の重みを調整することで、高度な結果を得ることができます。
LoCon
従来の LoRA はクロスアテンション層のみを調整します。 LoCon は同じ方法を使用して ResNet マトリックスを調整します。 LoCon は現在 LyCORIS にマージされているため、古い LoCon 拡張機能は不要になりました。 詳細については、「畳み込みネットワーク用 LoCon-LoRA」を参照してください。
LoHa
LoHa(アダマール積による LoRA)は、元のメソッドのマトリックス ドット積をアダマール積に置き換えます。 理論的には、同じ条件下でより多くの情報を保持できます。 詳細については、「通信効率の高い連合学習のためのアダマール積による FedPara 低ランク」を参照してください。
DyLoRA
LoRA の場合、ランクが高いほど良いとは限りません。 最適値は、特定のモデル、データセットの特性、およびタスクによって異なります。 DyLoRA は、指定されたディメンション(ランク)内でさまざまな LoRA ランク構成を探索および学習できます。 これにより、最適なランクを見つけるプロセスが簡素化され、モデル微調整の効率と精度が向上します。
データセットを準備する
LoRA タイプを決定する
まず、トレーニングする LoRA モデルのタイプ(キャラクター タイプやスタイル タイプなど)を決定します。
たとえば、Alibaba Cloud Evolving Design 言語システムに基づいて、Alibaba Cloud 3D プロダクト アイコンのスタイル モデルをトレーニングする必要がある場合があります。
データセット コンテンツの要件
データセットは、画像と対応する注釈用テキスト ファイルの 2 種類のファイルで構成されます。
データセット コンテンツの準備:画像
画像の要件
数量:15 枚以上の画像。
品質:適度な解像度と鮮明な画質。
スタイル:一貫したスタイルの画像セット。
コンテンツ:画像はトレーニング対象を強調表示する必要があります。 複雑な背景やその他の無関係なコンテンツ、特にテキストは避けてください。
サイズ:解像度は 64 の倍数で、512 ~ 768 の範囲である必要があります。 ビデオ メモリが少ない場合は、画像を 512 × 512 にトリミングします。 ビデオ メモリが多い場合は、画像を 768 × 768 にトリミングします。
画像の前処理
品質調整:適度な画像解像度を使用して、鮮明な画質を確保します。 画像解像度が低い場合は、SD WebUI または他の画像処理ツールの追加機能を使用してアップスケールできます。
サイズ調整:バッチ トリミング ツールを使用して画像をトリミングします。
準備された画像の例
画像をオンプレミス フォルダに保存します。

データセットを作成してファイルをアップロードする
アップロードする前に、ファイルの属性と命名要件に注意してください。 プラットフォームを使用してデータセット ファイルを管理したり、画像に注釈を付けたりするだけの場合は、ファイルまたはフォルダを直接アップロードできます。 これらのファイルとフォルダに特別な命名要件はありません。
データセットに注釈を付けた後、プラットフォームで Kohya を使用して LoRA モデルをトレーニングするには、アップロードされたファイルが次の属性と命名要件を満たしている必要があります。
命名形式:数値_カスタム名
ユーザー定義。
たとえば、フォルダに 10 枚の画像が含まれている場合、各画像は 1500 / 10 = 150 回トレーニングされます。 この場合、フォルダ名に含まれる数値は 150 にすることができます。 フォルダに 20 枚の画像が含まれている場合、各画像は 1500 / 20 = 75 回トレーニングされます。 75 は 100 未満であるため、フォルダ名に含まれる数値は 100 に設定する必要があります。
カスタム名:データセットのわかりやすい名前。 このトピックでは、例として 100_ACD3DICON を使用します。
PAI ArtLab にログインし、[Kohya (排他的エディション)] を選択して Kohya-SS ページを開きます。
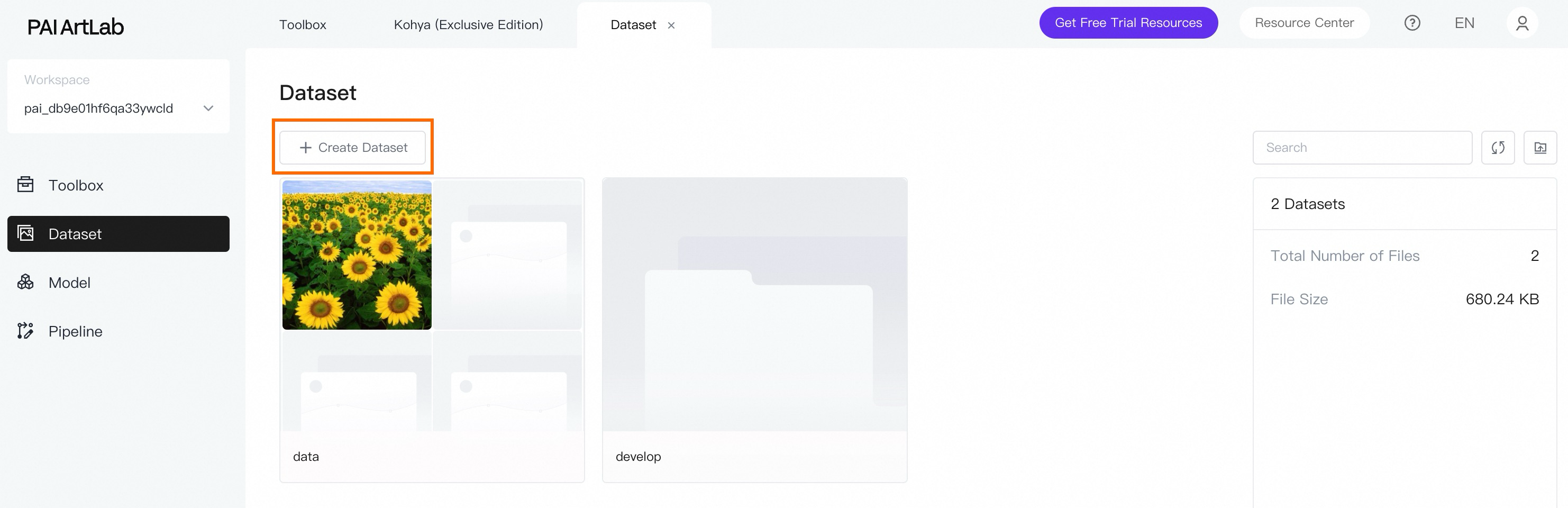
データセットを作成します。
データセット ページで、[データセットの作成] をクリックし、データセット名を入力します。 たとえば、acd3dicon と入力します。
データセット ファイルをアップロードします。
作成したデータセットの名前をクリックします。 次に、準備した画像フォルダをローカル コンピューターからアップロード領域にドラッグします。

アップロードが成功すると、フォルダがページに表示されます。
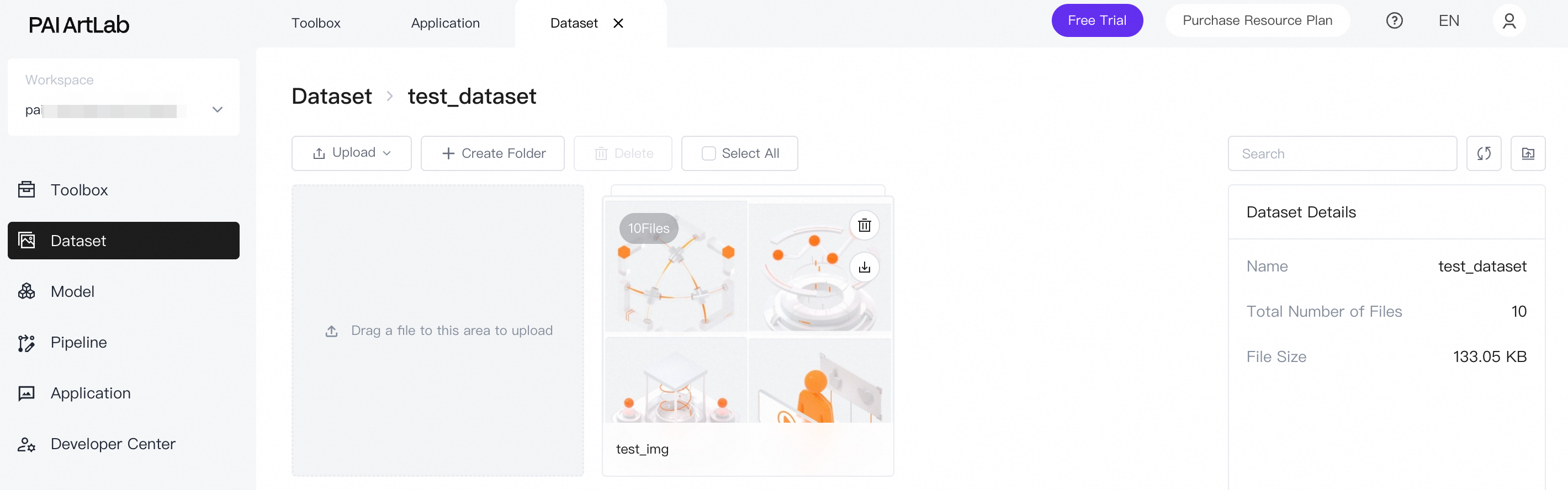
フォルダをクリックして、アップロードされた画像を表示します。
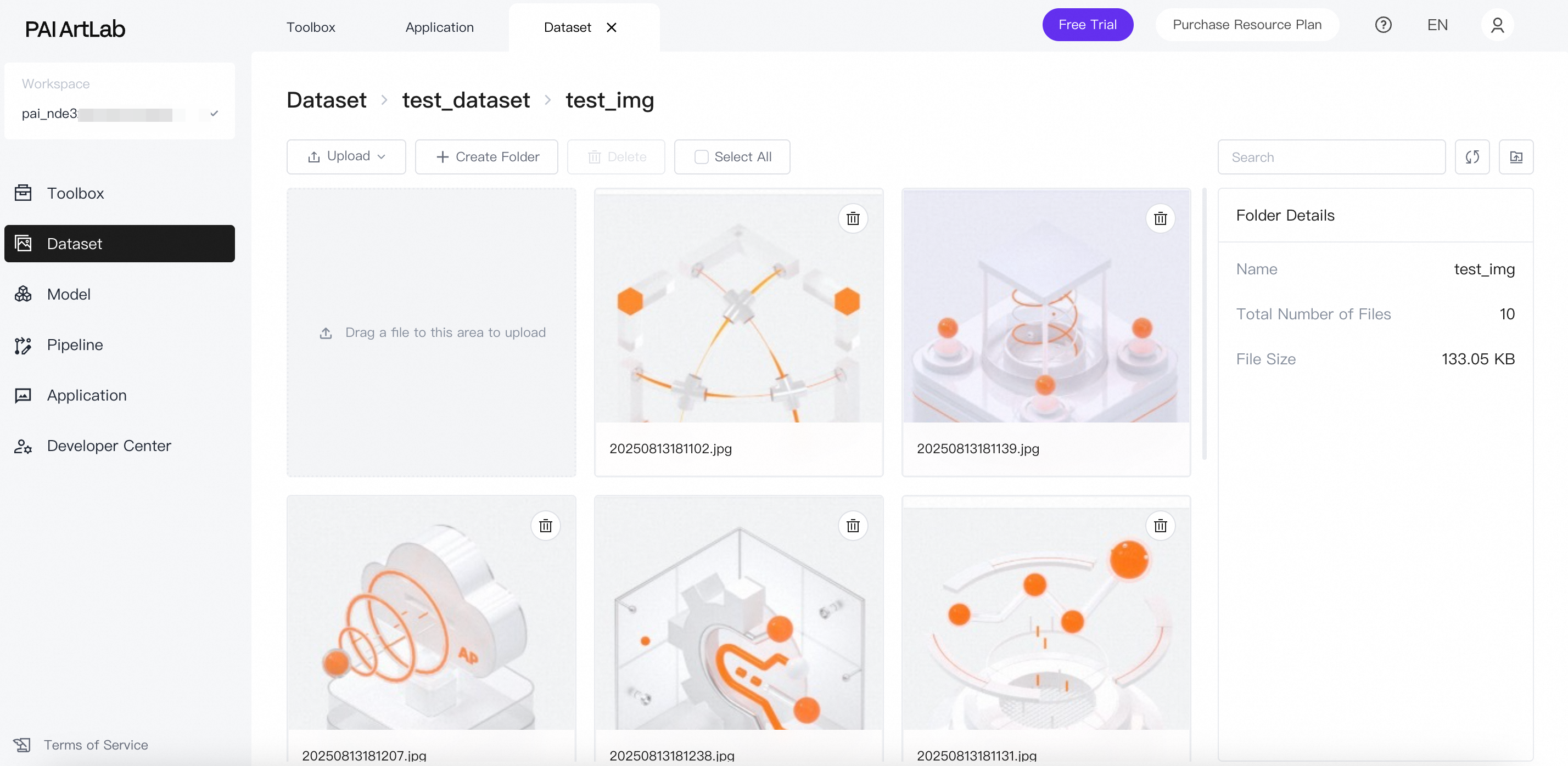
データセット コンテンツの準備:画像の注釈
画像の注釈とは、各画像のテキストによる説明のことです。 注釈ファイルは、画像と同じ名前の TXT ファイルです。
画像の注釈の要件
明確な構造レイアウト、標準的な遠近法、特定の照明を持つ要素(プロダクト アイコンなど)では、ポートレートや風景とは異なる注釈プロセスが必要です。 基本的な記述的注釈を使用します。 「球」や「立方体」などの主要な要素の単純な幾何学的形状に焦点を当てます。
カテゴリ
キーワード
サービス
プロダクト/サービス
database, cloud security, computing platform, container, cloud-native など (英語)
クラウド コンピューティング要素
データ処理、ストレージ、コンピューティング、クラウド コンピューティング、エラスティック コンピューティング、分散ストレージ、クラウド データベース、仮想化、コンテナー化、クラウド セキュリティ、クラウド アーキテクチャ、クラウド サービス、サーバー、負荷分散、自動管理、スケーラビリティ、ディザスタ リカバリ、高可用性、クラウド モニタリング、クラウド 課金
デザイン (テクスチャ)
環境と構成
ビューファインダー、アイソメトリック、HDRI 環境、白背景、ネガティブ スペース
素材
光沢のあるテクスチャ、マット テクスチャ、メタリック テクスチャ、ガラステクスチャ、すりガラス テクスチャ
照明
スタジオ照明、ソフト照明
色
アリババ クラウド オレンジ、白、黒、グラデーション オレンジ、透明、シルバー
感情
合理的、秩序だった、エネルギッシュ、活気のある
品質
UHD、正確、高ディテール、最高品質、1080P、16k、8k
デザイン (雰囲気)
...
...
画像に注釈を追加する
各画像にテキストによる説明を手動で追加できます。 ただし、大規模なデータセットの場合、手動による注釈は非効率的です。 時間を節約するために、ニューラル ネットワークを使用してすべての画像のバッチのテキストによる説明を生成できます。 Kohya では、BLIP 画像注釈モデルを使用し、結果を手動で調整して要件を満たすことができます。
データセットに注釈を付ける
Kohya-SS ページで、[ユーティリティ] > [キャプション] > [BLIP キャプション] を選択します。
作成したデータセットで、アップロードされた画像フォルダを選択します。
プレフィックス フィールドに、各注釈の先頭に追加されるキーワードを入力します。 これらのキーワードは、データセット画像の主要な特徴に基づいている必要があります。 注釈の特徴は、画像のタイプによって異なります。
[画像にキャプションを付ける] をクリックして、注釈を開始します。

下部のログで、注釈の進行状況と完了ステータスを確認できます。

データセット ページに戻ります。 各画像に対応する注釈ファイルが作成されています。
(オプション) 不適切な注釈を手動で修正します。
LoRA モデルをトレーニングする
Kohya-SS ページで、[LoRA] > [トレーニング] > [ソース モデル] に移動します。
次のパラメーターを構成します。
[モデルのクイック選択] で、[runwayml/stable-diffusion-v1-5] を選択します。
[トレーニング済みモデルの保存形式] を [safetensors] に設定します。
説明[モデルのクイック選択] ドロップダウン リストに必要なモデルが見つからない場合は、カスタムを選択してからモデルを選択できます。 カスタム パスでは、[モデル ギャラリー] から [マイ モデル] に追加したベース モデル、またはローカルで [マイ モデル] にアップロードしたモデルを見つけることができます。
Kohya-SS ページで、[LoRA] > [トレーニング] > [フォルダ] に移動します。
データセット フォルダを含むデータセットを選択し、トレーニング パラメーターを構成します。
 説明
説明データセット ファイルに注釈を付ける場合は、データセット内の特定の画像フォルダを選択します。 モデルをトレーニングする場合は、このフォルダを含む親データセットを選択します。
[トレーニングを開始] をクリックします。
パラメーターの詳細については、「頻繁に使用されるトレーニング パラメーター」をご参照ください。
下部のログで、モデル トレーニングの進行状況と完了ステータスを確認できます。

頻繁に使用されるトレーニング パラメーター
パラメーター
画像数 × 繰り返し回数 × エポック数 / バッチ サイズ = トレーニング ステップ数
例:10 画像 × 20 繰り返し × 10 エポック / 2 (バッチ サイズ) = 1000 ステップ。
Kohya-SS ページで、[LoRA] > [トレーニング] > [パラメーター] に移動して、モデル トレーニングのパラメーターを構成します。 以下は一般的なパラメーターです。
[基本] タブ

パラメーター
機能
設定
repeat (繰り返し)
画像を読み取る回数
フォルダ名に画像を読み取る回数を設定します。 数値が高いほど学習効果が高くなります。 初期トレーニングの推奨設定:
アニメと漫画:7~15
ポートレート:20~30
実際のオブジェクト:30~100
LoRA タイプ
使用する LoRA タイプ
デフォルトの選択である [標準] を維持します。
LoRA ネットワーク重み
LoRA ネットワーク重み
オプション。 トレーニングを続けるには、最後にトレーニングされた LoRA を選択します。
トレーニング バッチ サイズ
トレーニング バッチ サイズ
グラフィック カードのパフォーマンスに基づいて値を選択します。 最大値は、ビデオ メモリが 12 GB の場合は 2、8 GB の場合は 1 です。
Epoch (エポック)
トレーニング ラウンド数。 1 ラウンドは、すべてのデータに対する 1 回の完全なトレーニング パスです。
必要に応じて計算します。 一般的に:
Kohya でのトレーニング ステップ数 = トレーニング画像数 × 繰り返し回数 × エポック数 / トレーニング バッチ サイズ
WebUI でのトレーニング ステップ数 = トレーニング画像数 × 繰り返し回数
カテゴリ画像を使用する場合、Kohya または WebUI でのトレーニング ステップ数は 2 倍になります。 Kohya では、モデルの保存回数が半分になります。
N エポックごとに保存
トレーニング エポック N 回ごとに結果を保存する
2 に設定すると、トレーニング結果は 2 トレーニング エポックごとに保存されます。
キャプション拡張子
注釈ファイル名拡張子
オプション。 トレーニング データセットの注釈/プロンプト ファイルの形式は .txt です。
混合精度
混合精度
グラフィック カードのパフォーマンスによって決まります。 有効値:
no
fp16 (デフォルト)
bf16 (RTX 30 シリーズ以降のグラフィック カードで選択可能)
保存精度
保存精度
グラフィック カードのパフォーマンスによって決まります。 有効値:
no
fp16 (デフォルト)
bf16 (RTX 30 シリーズ以降のグラフィック カードで選択可能)
コアあたりの CPU スレッド数
コアあたりの CPU スレッド数
これは主に CPU パフォーマンスに依存します。 購入したインスタンスと要件に基づいて調整します。 デフォルト値を維持できます。
Seed (シード)
乱数シード
画像生成検証に使用できます。
潜在変数をキャッシュ
潜在変数をキャッシュ
デフォルトで有効になっています。 トレーニング後、画像情報は潜在変数ファイルとしてキャッシュされます。
LR スケジューラ
学習率スケジューラ
理論的には、単一の最適な学習ポイントはありません。 良好な仮説値を見つけるには、一般的に [コサイン] を使用できます。
オプティマイザ
オプティマイザ
デフォルトは [AdamW8bit] です。 sd1.5 基盤モデルに基づいてトレーニングする場合は、デフォルト値を維持します。
学習率
学習率
初期トレーニングでは、学習率を 0.01 ~ 0.001 の値に設定します。 デフォルト値は 0.0001 です。
損失関数 (損失) に基づいて学習率を調整できます。 損失値が高い場合は、学習率を適度に上げることができます。 損失値が低い場合は、学習率を徐々に下げると、モデルの微調整に役立ちます。
高い学習率はトレーニングを高速化しますが、粗い学習により過学習が発生する可能性があります。 これは、モデルがトレーニング データに過剰に適応し、汎化能力が低いことを意味します。
低い学習率では詳細な学習が可能になり、過学習が軽減されますが、トレーニング時間が長くなり、過少適合になる可能性があります。 これは、モデルが単純すぎてデータの特性を捉えられないことを意味します。
LR ウォームアップ (ステップの %)
学習率ウォームアップ (ステップの %)
デフォルト値は 10 です。
最大解像度
最大解像度
画像に基づいて設定します。 デフォルト値は 512,512 です。
ネットワーク ランク (ディメンション)
モデルの複雑さ
ほとんどのシナリオでは、64 の設定で十分です。
ネットワーク アルファ
ネットワーク アルファ
小さい値を設定します。 ランクとアルファの設定は、出力 LoRA の最終サイズに影響します。
クリップ スキップ
テキスト エンコーダーでスキップする層の数
アニメの場合は 2、リアルなモデルの場合は 1 を選択します。 アニメ モデル トレーニングでは、最初は 1 つの層がスキップされます。 トレーニング教材もアニメ画像の場合は、さらに 1 つの層をスキップして合計 2 層にします。
n エポックごとにサンプリング
トレーニング エポック n 回ごとにサンプリングする
数ラウンドごとにサンプルを保存します。
サンプル プロンプト
サンプル プロンプト
プロンプトのサンプル。 次のパラメーターを持つコマンドを使用する必要があります。
--n:ネガティブ プロンプト。
--w:画像の幅。
--h:画像の高さ。
--d:画像シード。
--l:プロンプトの関連性 (CFG スケール)。
--s:反復ステップ (ステップ)。
[詳細設定] タブ
パラメーター
機能
設定
クリップ スキップ
テキスト エンコーダーでスキップする層の数
アニメの場合は 2、リアルなモデルの場合は 1 を選択します。 アニメ モデル トレーニングでは、最初は 1 つの層がスキップされます。 トレーニング教材もアニメ画像の場合は、さらに 1 つの層をスキップして合計 2 層にします。
[サンプル] タブ

パラメーター
機能
設定
N エポックごとにサンプリング
トレーニング エポック N 回ごとにサンプリングする
数ラウンドごとにサンプルを保存します。
サンプル プロンプト
サンプル プロンプト
プロンプトのサンプル。 次のパラメーターを持つコマンドを使用する必要があります。
--n:ネガティブ プロンプト。
--w:画像の幅。
--h:画像の高さ。
--d:画像シード。
--l:プロンプトの関連性 (CFG スケール)。
--s:反復ステップ (ステップ)。
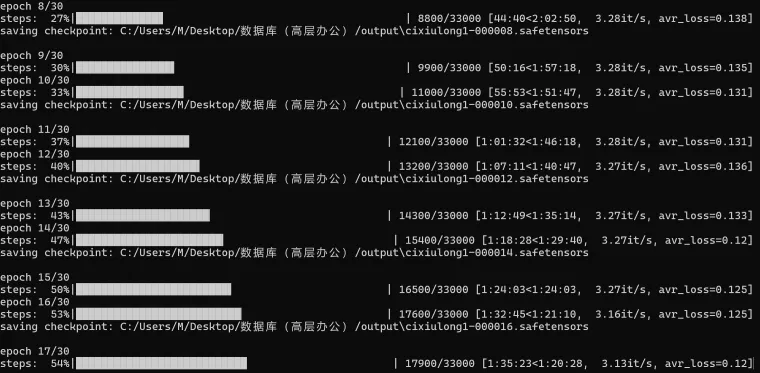
損失値
LoRA モデルの微調整プロセス中に、損失値はモデル品質を評価するための重要な指標です。 理想的には、トレーニングが進むにつれて損失値は徐々に減少します。これは、モデルが効果的に学習し、トレーニング データに適合していることを示しています。 0.08 ~ 0.1 の損失値は、一般的にモデルが十分にトレーニングされていることを示しています。 0.08 付近の損失値は、モデル トレーニングが非常に効果的であったことを示唆しています。
LoRA 学習は、損失値が時間とともに減少するプロセスです。 トレーニング エポック数を 30 に設定したとします。 目標が 0.07 ~ 0.09 の損失値を持つモデルを取得することである場合、この目標は 20 ~ 24 エポックの間に達成される可能性があります。 適切なエポック数を設定すると、損失値が急激に低下するのを防ぐのに役立ちます。 たとえば、エポック数が少なすぎると、損失値が 1 ステップで 0.1 から 0.06 に低下し、最適な範囲を見逃してしまう可能性があります。