ラベル伝播分類は、グラフ構造を使用してラベル付きデータポイントとラベルなしデータポイントの間でラベル情報を伝播するように設計された半教師あり学習アルゴリズムです。 このアルゴリズムは、データ点間の類似性に基づいてグラフを構築し、収束するまでノードのラベル分布を反復的に更新する。 ラベル伝播アルゴリズムは、少数のラベル付きサンプルからの情報を効果的に使用してデータセット全体に拡張し、それによって分類性能を向上させる。
アルゴリズムの説明
システムがラベル伝播アルゴリズムおよび分類アルゴリズムを実行するとき、各頂点のラベルは、類似性に基づいて隣接する頂点に伝播される。 各伝播ステップにおいて、各頂点は、その隣接する頂点のラベルに基づいてそのラベルを更新する。 類似性が高いほど、隣接する頂点が頂点に及ぼすラベリングの影響が高いことを示す。 この場合、ラベルは容易に伝播される。 ラベル伝播中、ラベル付きデータのラベルは変更されないままである。 これらのラベルは、ラベルなしデータへの伝播のソースとして機能します。 反復が終了した後、類似する頂点の確率分布は類似する傾向がある。 これらの頂点は、同じカテゴリに分類することができる。 これでラベルの伝播が完了する。
コンポーネントの設定
方法1: パイプラインページでコンポーネントを設定する
ラベル伝播分類コンポーネントは、Platform for AI (PAI) コンソールのMachine Learning Designerのパイプラインページに追加できます。 下表に、各パラメーターを説明します。
タブ | パラメーター | 説明 |
フィールド設定 | Vertexテーブル: Vertex Column | 頂点テーブルの頂点列。 |
頂点テーブル: ラベル列 | 頂点テーブルの頂点ラベル列。 | |
頂点のテーブル: 重量のコラム | 頂点テーブルの頂点の重み列。 | |
エッジテーブル: ソース頂点列 | エッジテーブルの開始頂点列。 | |
エッジテーブル: ターゲット頂点列 | エッジテーブルの末尾の頂点列。 | |
エッジテーブル: 選択重量列 | エッジテーブルのエッジ重み列。 | |
パラメーター設定 | 最大イテレーション数 | 反復の最大数。 デフォルト値:30。 |
ダンピング係数 | ダンピング係数。 デフォルト値: 0.8 | |
収束係数 | 収束係数。 デフォルト値: 0.000001 | |
チューニング | 数の労働者 | 並列ジョブ実行の頂点の数。 並列性とフレームワーク通信コストの程度は、このパラメータの値とともに増加します。 |
ワーカーメモリ (MB) | 1つのジョブで使用できるメモリの最大サイズ。 単位:MB。 デフォルト値: 4096 使用済みメモリのサイズがこのパラメーターの値を超えると、 |
方法2: PAIコマンドを使用してコンポーネントを構成する
ラベル伝播分類コンポーネントは、PAIコマンドを使用して設定できます。 SQLスクリプトコンポーネントを使用してPAIコマンドを実行できます。 詳細については、「SQLスクリプト」トピックの「シナリオ4: SQLスクリプトコンポーネント内でPAIコマンドを実行する」をご参照ください。
PAI -name LabelPropagationClassification
-project algo_public
-DinputEdgeTableName=LabelPropagationClassification_func_test_edge
-DfromVertexCol=flow_out_id
-DtoVertexCol=flow_in_id
-DinputVertexTableName=LabelPropagationClassification_func_test_node
-DvertexCol=node
-DvertexLabelCol=label
-DoutputTableName=LabelPropagationClassification_func_test_result
-DhasEdgeWeight=true
-DedgeWeightCol=edge_weight
-DhasVertexWeight=true
-DvertexWeightCol=label_weight
-Dalpha=0.8
-Depsilon=0.000001;パラメーター | 必須 / 任意 | デフォルト値 | 説明 |
inputEdgeTableName | 対象 | デフォルト値なし | 入力エッジテーブルの名前。 |
inputEdgeTablePartitions | 非対象 | フルテーブル | 入力エッジテーブルのパーティション。The partition in the input edge table. |
fromVertexCol | 対象 | デフォルト値なし | 入力エッジテーブルの開始頂点列。 |
toVertexCol | 対象 | デフォルト値なし | 入力エッジテーブルの末尾の頂点列。 |
inputVertexTableName | 対象 | デフォルト値なし | 入力頂点テーブルの名前。 |
inputVertexTablePartitions | 非対象 | フルテーブル | 入力頂点テーブルのパーティション。 |
vertexCol | 対象 | デフォルト値なし | 入力頂点テーブルの頂点列。 |
outputTableName | 対象 | デフォルト値なし | 出力テーブルの名前。 |
outputTablePartitions | 非対象 | デフォルト値なし | 出力テーブルのパーティション。 |
ライフサイクルの設定 (Set lifecycle) | 非対象 | デフォルト値なし | 出力テーブルのライフサイクル。 |
workerNum | 非対象 | デフォルト値なし | 並列ジョブ実行の頂点の数。 並列性とフレームワーク通信コストの程度は、このパラメータの値とともに増加します。 |
workerMem | 非対象 | 4096 | 1つのジョブで使用できるメモリの最大サイズ。 単位:MB。 デフォルト値: 4096 使用済みメモリのサイズがこのパラメーターの値を超えると、 |
splitSize | 非対象 | 64 | データ分割サイズ。 単位:MB。 |
hasEdgeWeight | 非対象 | false | 入力エッジテーブルのエッジに重みがあるかどうかを指定します。 |
edgeWeightCol | 非対象 | デフォルト値なし | 入力エッジテーブルのエッジ重み列。 |
hasVertexWeight | 非対象 | false | 入力頂点テーブルの頂点に重みがあるかどうかを指定します。 |
vertexWeightCol | 非対象 | デフォルト値なし | 入力頂点テーブルの頂点の重み列。 |
アルファ | 非対象 | 0.8 | ダンピング係数。 |
イプシロン | 非対象 | 0.000001 | 収束係数。 |
maxIter | 非対象 | 30 | 反復の最大数。 |
例:
SQLスクリプトコンポーネントを追加します。 [スクリプトモードの使用] および [テーブル作成文を追加するかどうか] の選択を解除します。 次に、次のSQL文を入力します。
drop table if exists LabelPropagationClassification_func_test_edge; create table LabelPropagationClassification_func_test_edge as select * from ( select 'a' as flow_out_id, 'b' as flow_in_id, 0.2 as edge_weight union all select 'a' as flow_out_id, 'c' as flow_in_id, 0.8 as edge_weight union all select 'b' as flow_out_id, 'c' as flow_in_id, 1.0 as edge_weight union all select 'd' as flow_out_id, 'b' as flow_in_id, 1.0 as edge_weight )tmp ; drop table if exists LabelPropagationClassification_func_test_node; create table LabelPropagationClassification_func_test_node as select * from ( select 'a' as node,'X' as label, 1.0 as label_weight union all select 'd' as node,'Y' as label, 1.0 as label_weight )tmp;データ構造
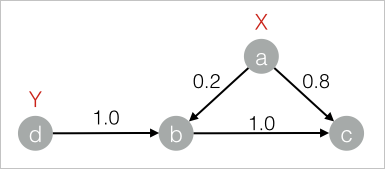
別のSQLスクリプトコンポーネントを追加します。 [スクリプトモードの使用] および [テーブル作成文を追加するかどうか] の選択を解除します。 次に、次のSQL文を入力し、手順1と2で2つのコンポーネントを接続します。
drop table if exists ${o1}; PAI -name LabelPropagationClassification -project algo_public -DinputEdgeTableName=LabelPropagationClassification_func_test_edge -DfromVertexCol=flow_out_id -DtoVertexCol=flow_in_id -DinputVertexTableName=LabelPropagationClassification_func_test_node -DvertexCol=node -DvertexLabelCol=label -DoutputTableName=${o1} -DhasEdgeWeight=true -DedgeWeightCol=edge_weight -DhasVertexWeight=true -DvertexWeightCol=label_weight -Dalpha=0.8 -Depsilon=0.000001;左上隅の
 をクリックしてパイプラインを実行します。
をクリックしてパイプラインを実行します。手順2のSQLスクリプトコンポーネントを右クリックし、[データの表示]> [SQLスクリプトの出力] を選択してトレーニング結果を表示します。
| node | tag | weight | | ---- | --- | ------------------- | | a | X | 1.0 | | c | X | 0.5370370370370371 | | c | Y | 0.4629629629629629 | | b | X | 0.16666666666666666 | | b | Y | 0.8333333333333333 | | d | Y | 1.0 |