PAI-DLC を使用すると、Kubernetes を活用して計算ノードを起動し、シングルマシンまたは分散トレーニングジョブを迅速に作成できます。これにより、マシンの手動プロビジョニングやランタイム環境の構成が不要となり、既存のワークフローを維持できます。PAI-DLC は、トレーニングジョブを素早く開始する必要があるユーザーに最適であり、柔軟なリソース構成オプションを備えた複数の深層学習フレームワークをサポートします。
前提条件
ルートアカウントを使用して PAI を有効化し、ワークスペースを作成します。PAI コンソール にログインします。ページ上部で対象リージョンを選択し、「ワンクリック権限付与」をクリックしてサービスを有効化します。詳細については、「PAI の有効化とワークスペースの作成」をご参照ください。
RAM ユーザーに必要な権限を付与します。ルートアカウントを使用している場合は、この手順はスキップしてください。RAM ユーザーを使用している場合、以下のいずれかのロールを割り当てます:アルゴリズム開発者、アルゴリズム運用管理者、またはワークスペース管理者。手順については、「ワークスペースの管理 > メンバーのロール設定」をご参照ください。
コンソールからジョブを作成
DLC に初めて触れる場合は、コンソールを使用してジョブを作成してください。DLC では、SDK またはコマンドライン を使用したジョブ作成もサポートしています。
Create Job ページに移動します。
PAI コンソール にログインします。ページ上部でターゲットリージョンおよび対象ワークスペースを選択し、「DLC へ移動」をクリックします。
「Deep Learning Containers (DLC)」ページで、Create Job をクリックします。
以下のセクションでトレーニングジョブのパラメーターを構成します。
基本情報
Job Name および Tag を設定します。
環境情報
パラメーター
説明
Image Configuration
Alibaba Cloud Image に加えて、以下のイメージタイプがサポートされています:
Custom Image:PAI に追加されたカスタムイメージを使用します。イメージリポジトリをパブリックプルモードに設定するか、Container Registry (ACR) にイメージを保存してください。詳細については、「カスタムイメージ」をご参照ください。
説明Lingjun リソースを選択してカスタムイメージを使用する場合、Lingjun の高性能 RDMA ネットワークを完全に活用するために、RDMA を手動でインストールする必要があります。詳細については、「RDMA:分散トレーニング向けの高性能ネットワーキングの利用」をご参照ください。
Image Address:インターネット経由でアクセス可能なレジストリアドレスを入力します。カスタムイメージまたは Alibaba Cloud イメージのいずれかを使用できます。
レジストリアドレスが非公開の場合、「ユーザー名とパスワードの入力」をクリックし、レジストリのユーザー名とパスワードを入力します。
イメージのプル速度を向上させるには、「イメージアクセラレーション」をご参照ください。
Mount dataset
データセットは、モデルトレーニングに必要なデータファイルを提供します。以下のデータセットタイプがサポートされています:
Custom Dataset:カスタムデータセット を作成してトレーニングデータファイルを格納します。読み取り専用かどうかを設定でき、バージョン一覧からバージョンを選択できます。
Public Dataset:PAI が提供する組み込みのパブリックデータセットです。読み取り専用のマウントのみをサポートします。
Mount Path:データセットを DLC コンテナーにマウントするパスです。例:
/mnt/data。コード内でこのパスを取得してデータセットにアクセスします。その他のマウント構成の詳細については、「DLC トレーニングジョブにおけるクラウドストレージの利用」をご参照ください。重要CPFS データセットを構成する場合、DLC に対して仮想プライベートクラウド (VPC) を構成する必要があります。この VPC は CPFS で使用される VPC と一致している必要があります。そうでない場合、ジョブが「環境準備中」状態のまま長時間滞留する可能性があります。
Mount storage
データソースのパスを直接マウントして、必要なデータを読み取ったり、中間結果および出力ファイルを保存したりできます。
サポートされるデータソースタイプ:OSS、汎用型 NAS ファイルシステム、超高速型 NAS ファイルシステム、および BMCPFS(Lingjun リソースでのみ利用可能)。
Advanced Settings:さまざまなデータソース向けの機能を有効化するために高度な構成を使用します。以下に例を示します:
OSS:高度な構成で
{"mountType":"ossfs"}を設定して、ossfs を使用して OSS をマウントします。汎用型 NAS および CPFS:DLC コンテナーから NAS へのアクセス時にスループットパフォーマンスを向上させるために、高度な構成で nconnect パラメーターを設定します。詳細については、「Linux における NAS のパフォーマンス低下を解決する方法」をご参照ください。例:
{"nconnect":"<example value>"}。「<example value>」を正の整数に置き換えます。
詳細については、「DLC トレーニングジョブにおけるクラウドストレージの利用」をご参照ください。
Startup Command
タスクの起動コマンドを設定します。シェルコマンドがサポートされており、DLC は 一般的な PyTorch および TensorFlow 環境変数(例:
MASTER_ADDR、WORLD_SIZE)を自動的に挿入します。これらの変数は$ENV_VAR_NAMEを使用して取得できます。起動コマンドの例を以下に示します:Python の実行:
python -c "print('Hello World')"複数の GPU およびサーバーにまたがる分散 PyTorch トレーニング:
python -m torch.distributed.launch \ --nproc_per_node=2 \ --master_addr=${MASTER_ADDR} \ --master_port=${MASTER_PORT} \ --nnodes=${WORLD_SIZE} \ --node_rank=${RANK} \ train.py --epochs=100シェルスクリプトのパスを起動コマンドとして使用:
/ml/input/config/launch.sh
Environment Variable
自動挿入される PyTorch および TensorFlow の汎用環境変数 に加えて、
Key:Value形式で最大 20 個のカスタム環境変数を指定できます。Third-party Libraries
コンテナイメージに一部のサードパーティライブラリが不足している場合、 Third-party Libraries を使用して追加できます。以下の 2 つの方法がサポートされています:
Select from List:テキストボックスにライブラリ名を直接入力します。
Directory of requirements.txt:requirements.txt ファイルにサードパーティライブラリを記述します。このファイルをコード構成、データセット、または直接マウントを使用して DLC コンテナーにアップロードし、テキストボックス内にコンテナー内のファイルパスを指定します。
Code Builds
トレーニングコードファイルを DLC コンテナーにアップロードします。以下の 2 つの構成方法がサポートされています:
Online configuration:Git コードリポジトリがあり、アクセス権限がある場合、 コードビルドの作成 を使用して DLC に関連付けます。これにより、DLC がジョブコードをフェッチできます。
Local Upload:
 ボタンをクリックしてローカルのコードファイルをアップロードします。アップロード後、 Mount path をコンテナー内の指定されたパス(例:
ボタンをクリックしてローカルのコードファイルをアップロードします。アップロード後、 Mount path をコンテナー内の指定されたパス(例: /mnt/data)に設定します。
リソース情報
パラメーター
説明
Resource Type
デフォルトは General Computing です。 Lingjun Intelligence Resources は、中国 (ウランチャブ)、シンガポール、中国 (深セン)、中国 (北京)、中国 (上海)、および中国 (杭州) のリージョンでのみ選択できます。
Source
Public Resources:
課金方法:従量課金。
利用シーン:パブリックリソースはキューイング遅延が発生する場合があります。比較的少ないジョブ数かつ低レイテンシー要件がある場合にのみ使用してください。
制限事項:最大サポートリソースは 2 GPU および 8 CPU コアです。これらの制限を引き上げるには、アカウントマネージャーにお問い合わせください。
Resource Quota:汎用計算リソースまたは Lingjun インテリジェント計算リソースを含みます。
課金方法:サブスクリプション。
利用シーン:多数のジョブを実行し、高い信頼性を要求する場合に使用します。
特殊パラメーター:
Resource Quota:GPU および CPU リソースの数を設定します。手順については、「リソースクォータの追加」をご参照ください。
優先度:同時に実行されるジョブの優先度を設定します。有効値:1~9。値が 1 の場合、最も低い優先度を意味します。
Preemptible Resources:
課金方法:従量課金。
利用シーン:コスト削減のためにプリエンプティブルリソースを使用します。通常、割引が適用されます。
制限事項:利用の保証はありません。即座に取得できない場合や、リソースが回収される場合があります。詳細については、「プリエンプティブルジョブの利用」をご参照ください。
Framework
サポートされる深層学習フレームワークおよびツール:TensorFlow、PyTorch、ElasticBatch、XGBoost、OneFlow、MPIJob、および Ray。
説明Resource Quota に Lingjun インテリジェント計算リソースを選択した場合、TensorFlow、PyTorch、ElasticBatch、MPIJob、および Ray ジョブのみがサポートされます。
Job Resource
選択した Framework に基づいて、Worker、PS、Chief、Evaluator、GraphLearn ノードのリソースを構成します。Ray を選択した場合、「Add Role」をクリックして、異種リソースの混在に対応したカスタム Worker ロールを定義します。
パブリックリソースの使用:以下のパラメーターを構成します:
Number of Nodes:DLC ジョブを実行するノード数。
Resource Type:仕様を選択します。コンソールには対応する価格が表示されます。その他の課金の詳細については、「DLC の課金詳細」をご参照ください。
リソースクォータの使用:各ノードタイプについて、ノード数、CPU コア数、GPU カード数、メモリ (GiB)、共有メモリ (GiB) を構成します。以下の特殊パラメーターも構成できます:
Node-Specific Scheduling:特定の計算ノード上でジョブを実行します。
Idle Resources:他のクォータのアイドルリソースを使用してリソース利用率を向上させます。元のクォータがこれらのリソースを必要とする場合、アイドルジョブは自動的に停止してリソースを解放します。詳細については、「アイドルリソースの利用」をご参照ください。
CPU Affinity:CPU アフィニティを有効化して、コンテナーまたは Pod 内のプロセスを特定の CPU コアにバインドします。これにより、CPU キャッシュミスおよびコンテキストスイッチが減少し、CPU 使用率およびアプリケーションパフォーマンスが向上します。パフォーマンスに敏感なアプリケーションおよびリアルタイムアプリケーションで使用します。
プリエンプティブルリソースの使用:ノード数およびリソース仕様に加えて、 Bid Price パラメーターを構成します。プリエンプティブルリソースをリクエストするための最大入札価格を設定します。「
 」ボタンをクリックして入札方法を選択します:
」ボタンをクリックして入札方法を選択します:割引による入札:最大価格は、リソース仕様の市場価格に対する割引額です。オプションは 10%~90%です。これは入札の上限を設定します。最大入札価格が市場価格以上であり、在庫がある場合に、プリエンプティブルリソースを取得できます。
価格による入札:最大価格は市場価格の範囲内にあります。
VPC 構成
VPC を構成しない場合、ジョブはインターネットおよびパブリックゲートウェイを使用します。パブリックゲートウェイは帯域幅が制限されており、ジョブ実行中にカクつきや失敗が発生する可能性があります。
VPC を構成し、対応する vSwitch およびセキュリティグループを選択することで、ネットワーク帯域幅、安定性、およびセキュリティが向上します。ジョブを実行するクラスターは、VPC 内のサービスに直接アクセスできます。
重要VPC を使用する場合、タスクのリソースグループインスタンスおよびデータセットストレージ(OSS)が同じリージョンの VPC ネットワーク内にあることを確認してください。また、コードリポジトリとのネットワーク接続も確保してください。
CPFS データセットを使用する場合、VPC を構成してください。選択した VPC は CPFS の VPC と一致している必要があります。そうでない場合、DLC トレーニングジョブが「環境準備中」状態のまま長時間滞留する可能性があります。
Lingjun インテリジェント計算プリエンプティブルリソースを使用して DLC ジョブを送信する場合、VPC を構成してください。
また、 Internet Access Gateway を構成できます。以下の 2 つのオプションがあります:
Public Gateway:ネットワーク帯域幅が制限されています。高同時実行性または大規模ファイルのダウンロード時、ネットワーク速度が要件を満たさない場合があります。
Private Gateway:パブリックゲートウェイの帯域幅制限を解決するために、DLC VPC 内にインターネット NAT ゲートウェイを作成し、弾性 IP アドレス(EIP)をアタッチし、SNAT エントリを設定します。詳細については、「専用ゲートウェイを使用したインターネットアクセス速度の向上」をご参照ください。
フォールトトレランスおよび診断
パラメーター
説明
Automatic Fault Tolerance
Automatic Fault Tolerance を有効化し、関連するパラメーターを構成します。これにより、ジョブの監視および制御機能が提供されます。アルゴリズムレベルでエラーを検出し回避することで、GPU 利用率が向上します。詳細については、「AIMaster:弾性自動フォールトトレランスエンジン」をご参照ください。
説明自動フォールトトレランスが有効化されている場合、システムはジョブインスタンスとともに AIMaster インスタンスを起動します。これにより、計算リソースが消費されます。AIMaster のリソース使用量は以下のとおりです:
リソースクォータ:1 CPU コアおよび 1 GiB メモリ。
パブリックリソース:ecs.c6.large インスタンスタイプ。
Sanity Check
Sanity Check を有効化します。ヘルスチェックは、トレーニングリソースに対して包括的なチェックを実行します。障害のあるノードを自動的に分離し、自動 O&M プロセスをトリガーします。これにより、トレーニング初期段階での問題が軽減され、成功率が向上します。詳細については、「SanityCheck:計算パワーのヘルスチェック」をご参照ください。
説明ヘルスチェックは、Lingjun インテリジェント計算リソースクォータを使用して送信された GPU 数がゼロより大きい PyTorch トレーニングジョブでのみサポートされています。
ロールおよび権限
インスタンス RAM ロールの構成について以下に説明します。詳細については、「DLC RAM ロールの構成」をご参照ください。
インスタンス RAM ロール
説明
Default Role of PAI
このロールは、サービスロール AliyunPAIDLCDefaultRole を基に動作します。MaxCompute および OSS へのアクセスのみに限定された詳細な権限を持ちます。
MaxCompute テーブルにアクセスする場合、 DLC インスタンス所有者 と同等の権限が付与されます。
OSS にアクセスする場合、現在のワークスペースに設定されたデフォルト OSS バケットへのアクセスのみが許可されます。
Custom Role
カスタム RAM ロールを選択または入力します。インスタンス内で STS 一時認証情報を使用してクラウドサービスにアクセスする場合、権限はカスタムロールのものと一致します。
Does Not Associate Role
DLC ジョブに RAM ロールを関連付けません。これがデフォルトのオプションです。
すべてのパラメーターを構成した後、 OK をクリックします。
参考情報
トレーニングジョブを送信した後、以下のタスクを実行します:
基本ジョブ情報、リソースビュー、および操作ログを表示します。詳細については、「トレーニングの詳細の表示」をご参照ください。
ジョブの管理(クローン作成、停止、削除など)を行います。詳細については、「トレーニングジョブの管理」をご参照ください。
TensorBoard を使用して分析レポートを表示します。詳細については、「TensorBoard 可視化ツール」をご参照ください。
ジョブのモニタリングおよびアラートを構成します。詳細については、「トレーニングのモニタリングおよびアラート」をご参照ください。
ジョブ実行の課金詳細を表示します。詳細については、「課金詳細」をご参照ください。
現在のワークスペースから DLC ジョブログを指定された Simple Log Service (SLS) Logstore に転送して、カスタム分析を行います。詳細については、「ジョブログの購読」をご参照ください。
PAI ワークスペースのイベントタブでメッセージ通知ルールを作成して、DLC ジョブのステータスを追跡およびモニターします。詳細については、「メッセージ通知」をご参照ください。
DLC ジョブ実行中のよくある問題とその解決策については、「DLC よくある質問」をご参照ください。
DLC のユースケースについては、「DLC ユースケースの概要」をご参照ください。
付録
SDK またはコマンドラインを使用したジョブの作成
Python SDK
ステップ 1:Alibaba Cloud 認証情報ツールのインストール
Alibaba Cloud SDK を使用して OpenAPI 操作を呼び出す場合、アクセス認証情報を構成するために認証情報ツールをインストールします。要件:
Python バージョン:3.7 以上。
Alibaba Cloud SDK V2.0 を使用します。
pip install alibabacloud_credentialsステップ 2:アカウントの AccessKey の取得
この例では、AK 情報を使用してアクセス認証情報を構成します。認証情報の漏洩を防ぐため、AccessKey を環境変数として設定します。ID には ALIBABA_CLOUD_ACCESS_KEY_ID を、シークレットには ALIBABA_CLOUD_ACCESS_KEY_SECRET を使用します。
AccessKey 情報の取得方法については、「AccessKey の作成」をご参照ください。
環境変数の設定方法については、「環境変数の構成」をご参照ください。
その他の認証情報構成方法については、「認証情報ツールのインストール」をご参照ください。
ステップ 3:Python SDK のインストール
ワークスペース SDK をインストールします。
pip install alibabacloud_aiworkspace20210204==3.0.1DLC SDK をインストールします。
pip install alibabacloud_pai_dlc20201203==1.4.17
ステップ 4:ジョブの送信
パブリックリソースを使用したジョブの送信
以下のコードは、ジョブの作成および送信方法を示しています。
サブスクリプションリソースクォータを使用したジョブの送信
PAI コンソール にログインします。
下図の手順に従って、ワークスペース一覧ページでワークスペース ID を確認します。
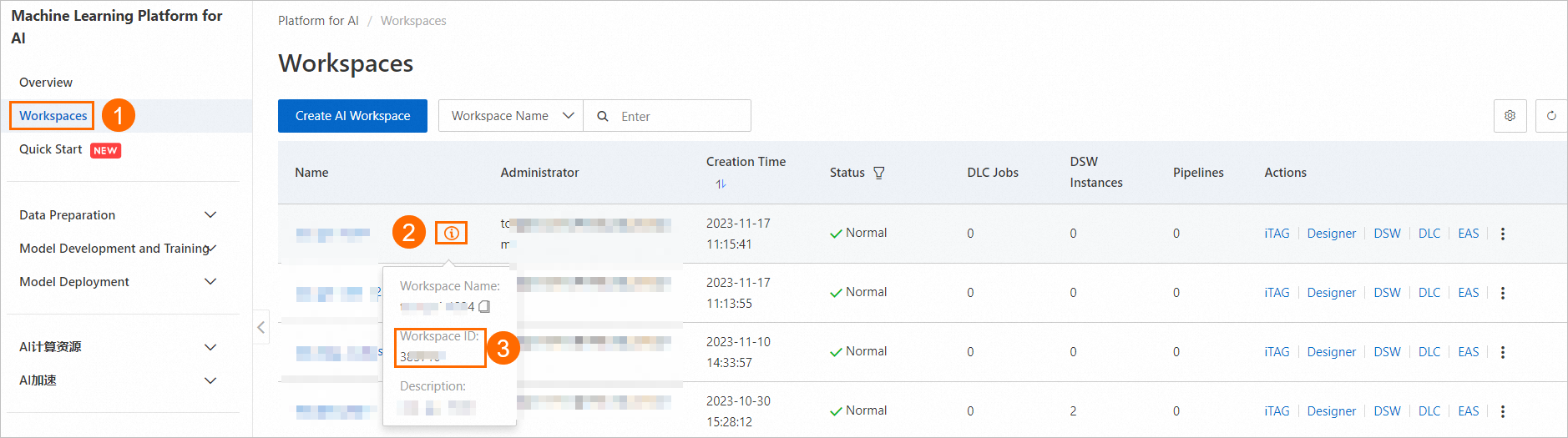
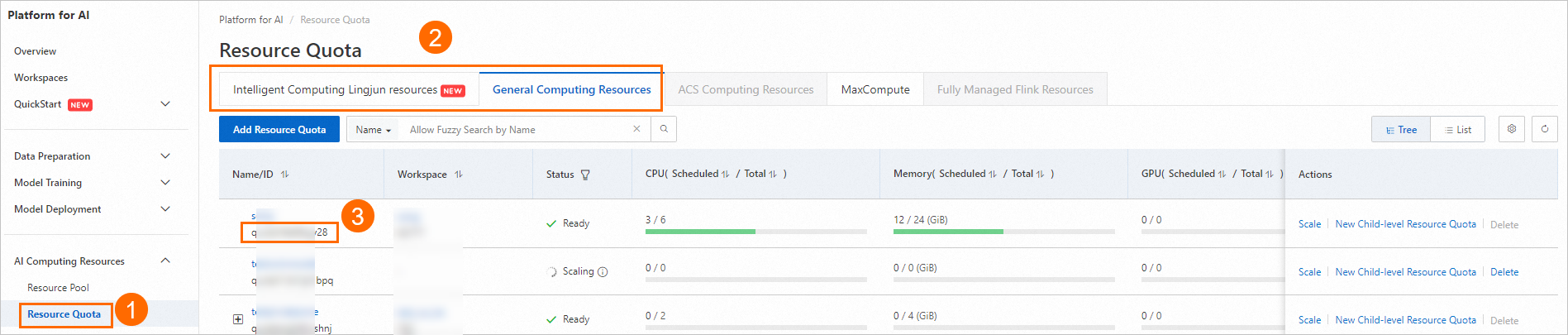
下図の手順に従って、専用リソースグループのリソースクォータ ID を確認します。
以下のコードを使用してジョブを作成および送信します。利用可能なパブリックイメージの一覧については、「ステップ 2:イメージの準備」をご参照ください。
from alibabacloud_pai_dlc20201203.client import Client from alibabacloud_credentials.client import Client as CredClient from alibabacloud_tea_openapi.models import Config from alibabacloud_pai_dlc20201203.models import ( CreateJobRequest, JobSpec, ResourceConfig, GetJobRequest ) # DLC API にアクセスするためのクライアントを初期化します。 region = 'cn-hangzhou' # ルートアカウントの AccessKeys は完全な API アクセス権限を持ちます。API アクセスまたは日常的な O&M には、RAM ユーザーの使用を推奨します。 # AccessKey ID および AccessKey シークレットをコード内に保存しないでください。これにより認証情報が漏洩し、アカウント内のすべてのリソースが危険にさらされる可能性があります。 # この例では、認証情報 SDK を使用して環境変数から認証情報を読み込みます。 cred = CredClient() client = Client( config=Config( credential=cred, region_id=region, endpoint=f'pai-dlc.{region}.aliyuncs.com', ) ) # ジョブリソース構成を定義します。イメージの選択については、ドキュメント内のパブリックイメージ一覧を参照するか、独自のレジストリアドレスを指定してください。 spec = JobSpec( type='Worker', image=f'registry-vpc.cn-hangzhou.aliyuncs.com/pai-dlc/tensorflow-training:1.15-cpu-py36-ubuntu18.04', pod_count=1, resource_config=ResourceConfig(cpu='1', memory='2Gi') ) # ジョブ実行内容を定義します。 req = CreateJobRequest( resource_id='<replace with your resource quota ID>', workspace_id='<replace with your WorkspaceID>', display_name='sample-dlc-job', job_type='TFJob', job_specs=[spec], user_command='echo "Hello World"', ) # ジョブを送信します。 response = client.create_job(req) # ジョブ ID を取得します。 job_id = response.body.job_id # ジョブのステータスを照会します。 job = client.get_job(job_id, GetJobRequest()).body print('job status:', job.status) # ジョブ実行コマンドを表示します。 job.user_command
プリエンプティブルリソースを使用したジョブの送信
SpotDiscountLimit(スポット割引)
#!/usr/bin/env python3 from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_pai_dlc20201203.client import Client as DLCClient from alibabacloud_pai_dlc20201203.models import CreateJobRequest region_id = '<region-id>' # DLC ジョブが存在するリージョンの ID(例:cn-hangzhou)。 cred = CredClient() workspace_id = '12****' # DLC ジョブが属するワークスペースの ID。 dlc_client = DLCClient( Config(credential=cred, region_id=region_id, endpoint='pai-dlc.{}.aliyuncs.com'.format(region_id), protocol='http')) create_job_resp = dlc_client.create_job(CreateJobRequest().from_map({ 'WorkspaceId': workspace_id, 'DisplayName': 'sample-spot-job', 'JobType': 'PyTorchJob', 'JobSpecs': [ { "Type": "Worker", "Image": "dsw-registry-vpc.<region-id>.cr.aliyuncs.com/pai/pytorch-training:1.12-cpu-py39-ubuntu20.04", "PodCount": 1, "EcsSpec": 'ecs.g7.xlarge', "SpotSpec": { "SpotStrategy": "SpotWithPriceLimit", "SpotDiscountLimit": 0.4, } }, ], 'UserVpc': { "VpcId": "vpc-0jlq8l7qech3m2ta2****", "SwitchId": "vsw-0jlc46eg4k3pivwpz8****", "SecurityGroupId": "sg-0jl4bd9wwh5auei9****", }, "UserCommand": "echo 'Hello World' && ls -R /mnt/data/ && sleep 30 && echo 'DONE'", })) job_id = create_job_resp.body.job_id print(f'jobId is {job_id}')SpotPriceLimit(スポット価格)
#!/usr/bin/env python3 from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_pai_dlc20201203.client import Client as DLCClient from alibabacloud_pai_dlc20201203.models import CreateJobRequest region_id = '<region-id>' cred = CredClient() workspace_id = '12****' dlc_client = DLCClient( Config(credential=cred, region_id=region_id, endpoint='pai-dlc.{}.aliyuncs.com'.format(region_id), protocol='http')) create_job_resp = dlc_client.create_job(CreateJobRequest().from_map({ 'WorkspaceId': workspace_id, 'DisplayName': 'sample-spot-job', 'JobType': 'PyTorchJob', 'JobSpecs': [ { "Type": "Worker", "Image": "dsw-registry-vpc.<region-id>.cr.aliyuncs.com/pai/pytorch-training:1.12-cpu-py39-ubuntu20.04", "PodCount": 1, "EcsSpec": 'ecs.g7.xlarge', "SpotSpec": { "SpotStrategy": "SpotWithPriceLimit", "SpotPriceLimit": 0.011, } }, ], 'UserVpc': { "VpcId": "vpc-0jlq8l7qech3m2ta2****", "SwitchId": "vsw-0jlc46eg4k3pivwpz8****", "SecurityGroupId": "sg-0jl4bd9wwh5auei9****", }, "UserCommand": "echo 'Hello World' && ls -R /mnt/data/ && sleep 30 && echo 'DONE'", })) job_id = create_job_resp.body.job_id print(f'jobId is {job_id}')
主な構成の詳細:
パラメーター | 説明 |
SpotStrategy | 入札ポリシーです。入札タイプのパラメーターは、このパラメーターを SpotWithPriceLimit に設定した場合にのみ有効になります。 |
SpotDiscountLimit | スポット割引入札タイプです。 説明
|
SpotPriceLimit | スポット価格入札タイプです。 |
UserVpc | Lingjun リソースを使用してジョブを送信する場合に必須のパラメーターです。ジョブが存在するリージョンの VPC、vSwitch、およびセキュリティグループ ID を構成します。 |
コマンドライン
ステップ 1:クライアントのダウンロードおよびユーザー認証の完了
お使いのオペレーティングシステム向け Linux 64 ビットまたは Mac クライアントをダウンロードし、ユーザー認証を完了します。詳細については、「事前準備」をご参照ください。
ステップ 2:ジョブの送信
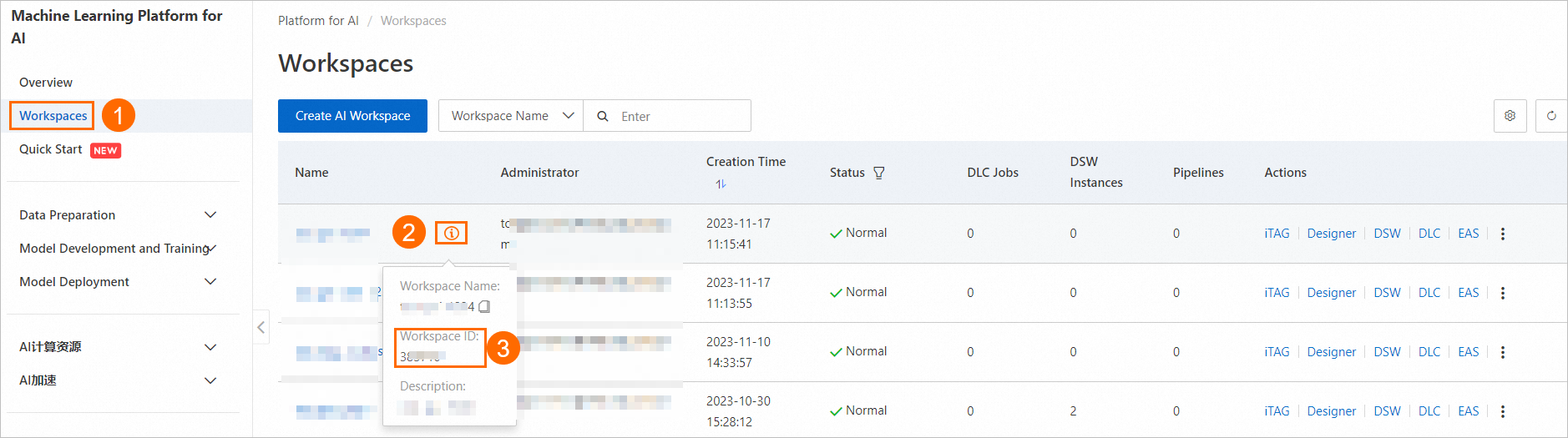
PAI コンソール にログインします。
下図の手順に従って、ワークスペース一覧ページでワークスペース ID(WorkspaceID)を確認します。
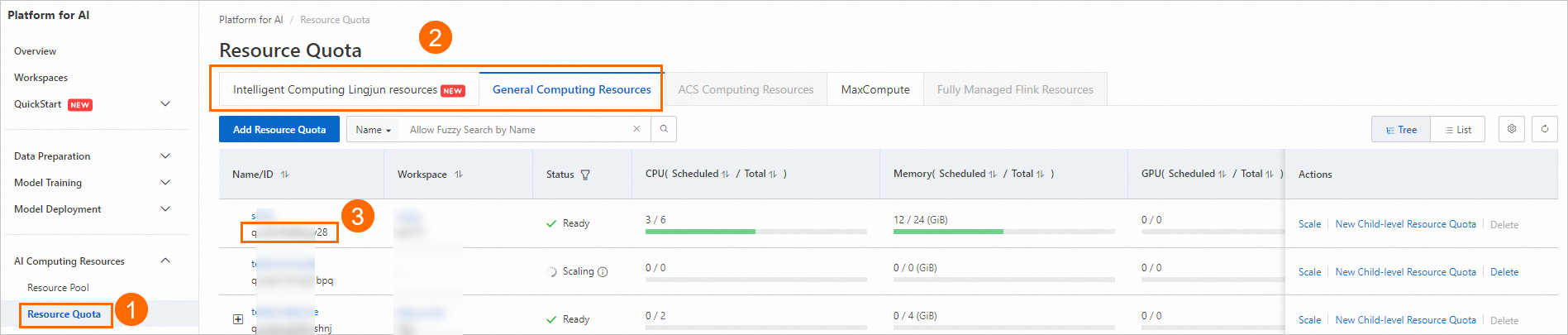
下図の手順に従って、リソースクォータ ID を確認します。
以下の内容を使用して、
tfjob.paramsという名前のパラメーターファイルを準備します。パラメーターファイルの構成に関する詳細については、「送信コマンド」をご参照ください。name=test_cli_tfjob_001 workers=1 worker_cpu=4 worker_gpu=0 worker_memory=4Gi worker_shared_memory=4Gi worker_image=registry-vpc.cn-beijing.aliyuncs.com/pai-dlc/tensorflow-training:1.12.2PAI-cpu-py27-ubuntu16.04 command=echo good && sleep 120 resource_id=<replace with your resource quota ID> workspace_id=<replace with your WorkspaceID>以下のコード例を使用して、
params_fileパラメーターでジョブを送信できます。これにより、 DLC ジョブが指定されたワークスペースおよびリソースクォータに送信されます。./dlc submit tfjob --job_file ./tfjob.params以下のコードを使用して、送信した DLC ジョブを表示します。
./dlc get job <jobID>
詳細パラメーターリスト
パラメーター(キー) | サポートされるフレームワークタイプ | パラメーターの説明 | パラメーターの値(値) |
| ALL | カスタムリソース解放ルールを構成します。空欄のままにすることもできます。空欄の場合は、ジョブ終了時にすべての Pod リソースが解放されます。構成する場合は、現在 pod-exit のみがサポートされています。これは、Pod が終了したときにリソースを解放します。 | pod-exit |
| ALL | GPU ドライバーのロード時に IBGDA を有効化します。 |
|
| ALL | GDRCopy カーネルモジュールをインストールします。現在のバージョンは 2.4.4 です。 |
|
| ALL | NUMA を有効化します。 |
|
| ALL | ジョブ送信時に、クォータ内の合計リソース(ノード仕様)がすべてのジョブロールの要件を満たすかどうかを確認します。 |
|
| PyTorch | Worker 間のネットワーク通信を許可します。
有効化すると、各 Worker のドメイン名はその名前(例: |
|
| PyTorch | 各 Worker で開くネットワークポートを定義します。 未構成の場合、Master でポート 23456 のみが開かれます。カスタムポートリストではポート 23456 を避けてください。 重要 このパラメーターは | ポート番号またはポート範囲のセミコロン区切り文字列(例: |
| PyTorch | 各 Worker で開くネットワークポート数をリクエストします。 このパラメーターが未構成の場合、デフォルトで Master でポート 23456 のみが開かれます。DLC は、パラメーターで定義されたポート数に基づいて Worker にポートをランダムに割り当てます。割り当てられたポート番号は、Worker がクエリできるように 重要
| 整数(最大 65536) |
| Ray | フレームワークが Ray の場合、ランタイム環境を定義するために RayRuntimeEnv を手動で構成します。 重要 環境変数およびサードパーティライブラリの構成は、この設定によって上書きされます。 | 環境変数およびサードパーティライブラリの構成( |
| Ray | 外部 GCS Redis アドレス。 | 文字列 |
| Ray | 外部 GCS Redis ユーザー名。 | 文字列 |
| Ray | 外部 GCS Redis パスワード。 | 文字列 |
| Ray | submitter の再試行回数。 | 正の整数(int) |
| Ray | ノードの共有メモリを構成します。例:ノードあたり 1 GiB の共有メモリを構成します。構成例: | 正の整数(int) |