生データとクラスタリング結果を使用してクラスタリングモデルのパフォーマンスを評価し、評価メトリックを生成します。
制限事項
このコンポーネントの可視化レポートは、元の Machine Learning Studio でのみ利用可能です。
背景情報
カリンスキーハラバスインデックスは、分散比基準 (VRC) とも呼ばれ、次の数式を使用して計算される評価メトリックです。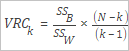
|
パラメーター |
説明 |
|
SSB |
クラスター間分散。次のように定義されます。
|
|
SSW |
クラスター内分散。次のように定義されます。
|
|
N |
レコードの総数。 |
|
k |
クラスターセンターの数。 |
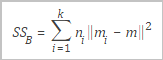 ここで、
ここで、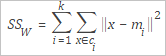 ここで、
ここで、コンポーネントの設定
クラスタリングモデル評価コンポーネントは、次のいずれかの方法で設定できます。
方法 1:GUI
ビジュアルモデリングのパイプラインページでコンポーネントのパラメーターを設定します。
|
タブ |
パラメーター |
説明 |
|
フィールド設定 |
評価列 |
評価する列。 |
|
入力がスパースフォーマット |
入力データがスパースなキーと値のペア (KV) フォーマットであるかどうかを指定します。 |
|
|
キーと値のペアのデリミタ |
デフォルトはカンマ (,) です。 |
|
|
キーと値の内部デリミタ |
デフォルトはコロン (:) です。 |
|
|
実行チューニング |
コア数 |
[コアあたりのメモリ] と一緒に使用します。正の整数である必要があります。 |
|
コアあたりのメモリ |
[コア数] と一緒に使用します。単位:MB。 |
方法 2:PAI コマンド
SQL スクリプトコンポーネントで PAI コマンドを実行して、コンポーネントのパラメーターを設定します。詳細については、「SQL スクリプト」をご参照ください。
PAI -name cluster_evaluation
-project algo_public
-DinputTableName=pai_cluster_evaluation_test_input
-DselectedColNames=f0,f3
-DmodelName=pai_kmeans_test_model
-DoutputTableName=pai_ft_cluster_evaluation_out;|
パラメーター |
必須 |
説明 |
デフォルト値 |
|
inputTableName |
はい |
入力テーブルの名前。 |
なし |
|
selectedColNames |
いいえ |
評価する入力テーブルの列。複数の列を指定するには、列名をカンマ (,) で区切ります。 |
すべての列 |
|
inputTablePartitions |
いいえ |
評価に使用する入力テーブルのパーティション。次のフォーマットがサポートされています:
説明
複数のパーティションを指定する場合は、カンマ (,) で区切ります。 |
テーブル全体 |
|
enableSparse |
いいえ |
入力データがスパースフォーマットであるかどうかを指定します。有効な値: |
false |
|
itemDelimiter |
いいえ |
スパースフォーマットにおけるキーと値のペア間のデリミタ。 |
カンマ (,)。 |
|
kvDelimiter |
いいえ |
スパースフォーマットにおけるキーと値の間のデリミタ。 |
コロン (:)。 |
|
modelName |
はい |
入力クラスタリングモデル。 |
なし |
|
outputTableName |
はい |
出力テーブル。 |
なし |
|
lifecycle |
いいえ |
出力テーブルのライフサイクル。 |
なし |
例
-
SQL ステートメントを使用してテストデータを生成します。
create table if not exists pai_cluster_evaluation_test_input as select * from ( select 1 as id, 1 as f0,2 as f3 union all select 2 as id, 1 as f0,3 as f3 union all select 3 as id, 1 as f0,4 as f3 union all select 4 as id, 0 as f0,3 as f3 union all select 5 as id, 0 as f0,4 as f3 )tmp; -
PAI コマンドを使用してクラスタリングモデルを作成します。この例では、k 平均法を使用します。
PAI -name kmeans -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f3 -DcenterCount=3 -Dloop=10 -Daccuracy=0.00001 -DdistanceType=euclidean -DinitCenterMethod=random -Dseed=1 -DmodelName=pai_kmeans_test_model -DidxTableName=pai_kmeans_test_idx -
PAI コマンドを使用して、クラスタリングモデル評価コンポーネントを実行します。
PAI -name cluster_evaluation -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f3 -DmodelName=pai_kmeans_test_model -DoutputTableName=pai_ft_cluster_evaluation_out; -
出力テーブル pai_ft_cluster_evaluation_out を表示します。コンポーネントの実行後、出力テーブルには
calinharaの値3、centerCountの値3、countの値5が含まれます。次の表に、出力テーブルのフィールドを示します。フィールド
説明
count
レコードの総数。
centerCount
クラスターセンターの数。
calinhara
カリンスキーハラバスインデックス。