Platform for AI (PAI) のLLM-Clean Copyright Information (MaxCompute) コンポーネントを使用して、コードテキストから著作権コメントヘッダーなどの著作権情報をテキストから削除します。 大規模言語モデル (LLM) のテキスト前処理中にコンポーネントを使用できます。
サポートされるコンピューティングリソース
アルゴリズムの説明
このアルゴリズムは、テキストから著作権情報を削除するために次の操作を実行します。
テキストに正規表現
'/\*[^ *]* \* +(?:[^/*][^ *]* \* +)*/'に準拠する文字列が含まれているかどうかを確認します。対応する文字列が一致する場合、アルゴリズムは、文字列が
著作権フィールドを含むかどうかをチェックする。 文字列にフィールドが含まれている場合、アルゴリズムは文字列を削除して結果を返します。 文字列にフィールドが含まれていない場合、アルゴリズムは直接結果を返します。正規表現が一致しない場合は、手順2に進みます。
改行でテキストを分割します。 アルゴリズムはテキストを行ごとにトラバースして、行が次のコメント文字
//、#、または--で始まるかどうかを確認します。 条件を満たす行が一致する場合、アルゴリズムはコメントシンボルが終了するまでテキストをトラバースし続けます。 テキスト内の連続するコメント行が削除されます。
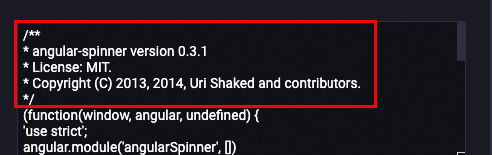
アルゴリズムはテキストのヘッダーのみをチェックします。 例:
処理前
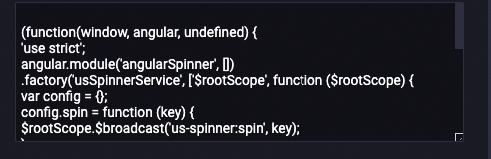
| 処理後
|
コンポーネントの設定
Machine Learning DesignerのパイプラインページにLLM-Clean Copyright Information (MaxCompute) コンポーネントを追加し、次のパラメーターを設定します。
カテゴリ | パラメーター | デフォルト値 | 説明 |
フィールド設定 | ターゲット列の選択 | なし | 処理する列。The columns that you want to process. 複数の列を選択できます。 |
出力テーブルのライフサイクル | 28 | 値は正の整数です。 単位:日 デフォルト値: 28。 テーブルのデフォルトのライフサイクルが経過すると、コンポーネントによって生成された一時テーブルがリサイクルされます。 | |
チューニング | マップタスクのインスタンスごとのCPU数 | 100 | マップタスクの各インスタンスのCPU数。 有効な値: 50 ~ 800 |
マップタスクのインスタンスあたりのメモリサイズ | 1024 | マップタスクの各インスタンスのメモリサイズ。 単位:MB。 有効な値: 256〜12288。 | |
マップの入力データの最大サイズ | 256 | マップタスクの各インスタンスが処理できるデータの最大量。 このパラメーターを使用して、マップの入力を制御できます。 単位:MB。 有効な値: 1〜Integer.MAX_VALUE。 |