EAS は、計算能力のチェックとフォールトトレランス機能を提供します。これらの機能は、GPU の計算能力やノード通信などのリソースのヘルス状態を自動的にチェックし、トラブルシューティングの効率を向上させ、大規模なデプロイメントにおけるサービスの可用性と安定性を確保します。
ユースケース
計算能力のチェックとフォールトトレランス機能は、Lingjun リソースにデプロイされたマルチノードの分散推論サービスを対象としています。
コアコンセプト
チェックのタイミング:
インスタンス起動前: サービスインスタンス (Pod) 内のプログラムが開始される前にチェックが実行されます。これにより、リソースのエラーによる起動の失敗を防ぎ、ハードウェアやネットワークの問題を事前に特定できます。
インスタンス実行中: サービスの実行中にバックグラウンドプロセスとしてチェックが実行されます。
チェック項目:
インスタンス起動前: 計算パフォーマンスチェック、ノード通信チェック、および計算と通信のクロスチェックをサポートします。
インスタンス実行中: C4D (GPU のヘルス状態をチェック) のみをサポートします。
チェック項目の詳細については、「付録: チェック項目の説明」をご参照ください。
異常状態の処理:
インスタンス起動の失敗: 問題が検出された場合、システムは現在のインスタンスの起動を終了します。
操作なし: 問題が検出された場合、システムはイベントを記録するだけで、他の操作は行いません。
手順
計算能力チェックの有効化と構成
PAI コンソールにログインします。ページの上部でリージョンを選択します。次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS)] をクリックします。
[Deploy Service] をクリックし、[Custom Model Deployment] セクションで [Custom Deployment] を選択します。
[Features] セクションの [Stability Guarantee] で、[Compute Monitoring & Fault Tolerance] を有効にします。右側に表示されるパネルでチェックパラメーターを構成します。JSON ファイルを直接構成するには、「付録: JSON ファイルのパラメーターの説明」をご参照ください。
説明実行前と [インスタンス実行中] の両方のチェックを追加できます。
インスタンス起動前のチェックを構成する (オプション)
検出タイミング:[実行前] を選択します。
[チェック項目]: 必要に応じて、[計算パフォーマンスチェック] や [ノード通信チェック] などのチェック項目を選択します。デフォルトでは、プラットフォームは [GPU GEMM]、[All-Reduce-Single Node]、および [All-Reduce-Node-Node] チェックを有効にします。
最大チェック期間の設定: 選択したチェック項目に基づいて、「チェック項目の説明」の推定期間 (チェックは順次実行されます) を参照して、タイムアウト期間を設定します。デフォルトは 5 分です。この時間内にチェックが完了しない場合、チェックは失敗します。
[異常状態の処理]: デフォルトは [インスタンス起動の失敗] です。
インスタンス実行中のチェックを構成する (オプション)
検出タイミング: [インスタンス実行中] を選択します。
[チェック項目]: 現在、[C4D] のみがサポートされています。
[異常状態の処理]: 現在、[無視] のみがサポートされています。
計算能力のヘルスチェック結果の表示
この機能を構成した後、2 つの方法でチェックレポートを表示できます:
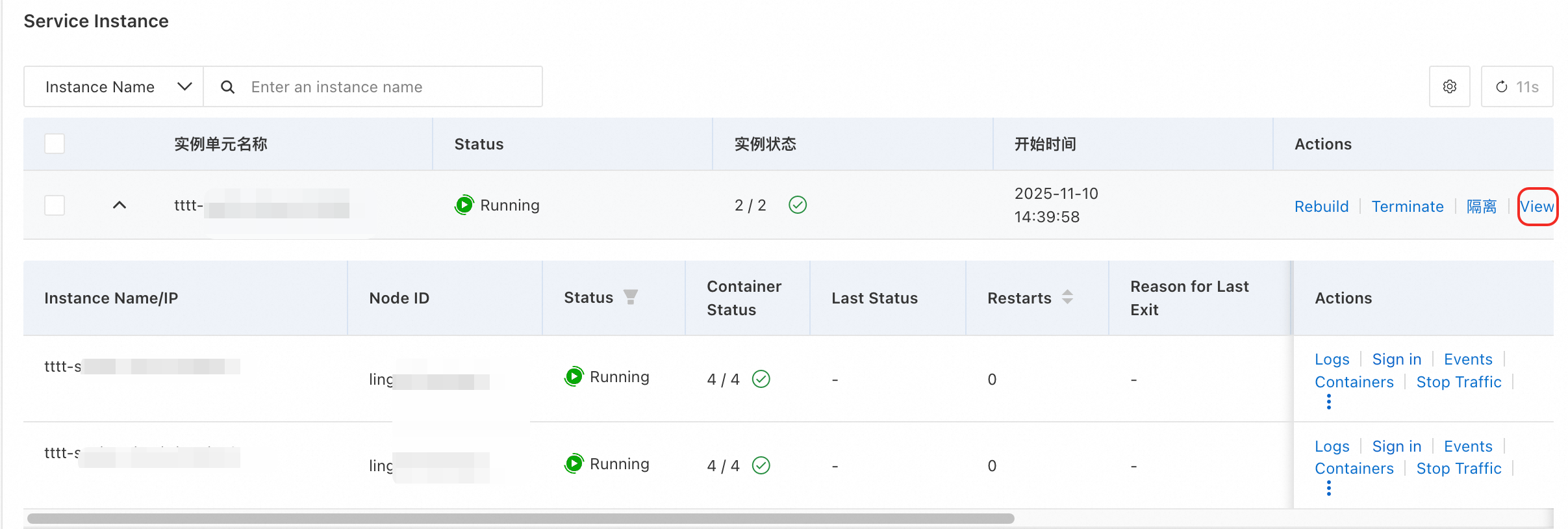
方法 1: インスタンスリストから
サービス詳細ページで、[概要] タブをクリックします。
[サービスインスタンス] セクションで、目的のインスタンスを見つけ、アクション 列の [結果の表示] をクリックします。
方法 2: デプロイメントイベントから
サービス詳細ページで、[デプロイメントイベント] タブをクリックします。
タイプが
SanityCheckSucceededまたはSanityCheckFailedのイベントを見つけ、[Action] 列の [結果の表示] をクリックします。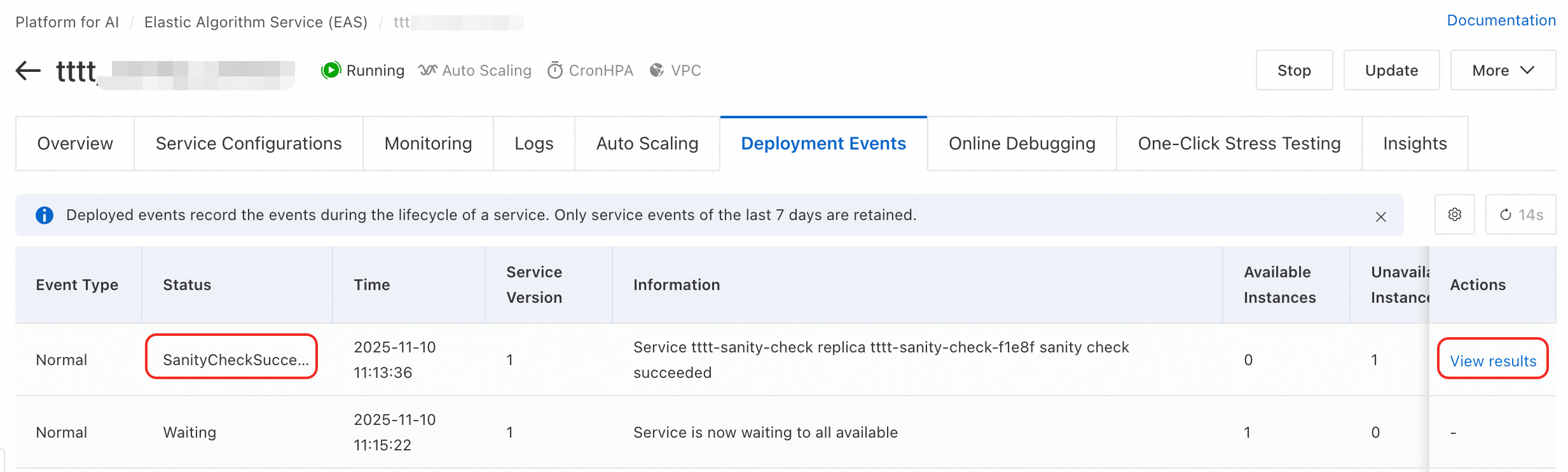
右側に [計算能力ヘルスチェック結果] ドロワーが表示されます。このドロワーで各チェック項目の詳細なレポートを表示できます。
よくある質問
Q: All-Reduce チェックが失敗する一般的な原因は何ですか?
All-Reduce チェックの失敗は、通常、ノード間のネットワーク通信の問題を示します。これらの問題には、高いネットワーク遅延、深刻なパケット損失、またはノード間の不正な Remote Direct Memory Access (RDMA) 構成が含まれる場合があります。レポートの詳細なデータを使用して、通信が遅いノードのトラブルシューティングに集中できます。
付録: チェック項目の説明
チェック項目 | 説明 (推奨シナリオ) | 推定チェック期間 | |
インスタンス起動前 | |||
計算パフォーマンスチェック | GPU GEMM | GPU GEMM のパフォーマンスを検出し、以下を特定します:
| 1 分 |
GPU Kernel Launch | GPU カーネルの起動遅延を検出し、以下を特定します:
| 1 分 | |
ノード通信チェック | All-Reduce | ノード通信のパフォーマンスを検出し、遅いまたはエラーのあるノードを特定します。さまざまな通信パターンで、このチェックは以下を特定します:
| 単一コレクション通信検出 5 分 |
All-to-All | |||
All-Gather | |||
Multi-All-Reduce | |||
PyTorch-Gloo | PyTorch Gloo を使用してノード通信をチェックし、エラーのある通信ノードを特定します。 | 1 分 | |
Network Connectivity | ヘッドノードまたはテールノードのネットワーク接続性をチェックし、接続性が異常なノードを特定します。 | 2 分 | |
計算と通信のクロスチェック | MatMul/All-Reduce Overlap | 通信カーネルと計算カーネルが重複する場合の単一ノードのパフォーマンスを検出します。このチェックは以下を特定します:
| 1 分 |
インスタンス実行中 | |||
C4D | インスタンスの実行中に GPU カードのヘルス状態をチェックします。 | ||
付録: JSON ファイルのパラメーターの説明
構成例
{
"aimaster": {
"runtime_check": {
"fail_action": "retain",
"micro_benchmarks": "c4d"
},
"sanity_check": {
"fail_action": "retain",
"micro_benchmarks": "gemm_flops,all_reduce_1,all_reduce_2,kernel_launch,all_reduce,all_to_all_2,all_gather_2,all_gather,multi_all_reduce_2,multi_all_reduce,pytorch_gloo_2,network_connectivity,comp_comm_overlap",
"timeout": 100
}
}
}パラメーターの説明
パラメーター | 説明 | ||
aimaster | runtime_check インスタンス実行中 | fail_action | 異常状態の処理方法。 |
micro_benchmarks | チェック項目。有効な値: c4d。 | ||
sanity_check インスタンス起動前 | fail_action | 異常状態の処理方法。 | |
micro_benchmarks | チェック項目。複数の項目はカンマで区切ります。 | ||
timeout | 最大チェック期間 (分)。 | ||