LangStudio は、アプリケーションフローの構築、テスト、最適化を行うための直感的かつ効率的な統合開発環境(IDE)です。これらのフローには、大規模言語モデル(LLM)、Python ノード、その他のツールを含めることができます。
はじめに
詳細については、「ワークフロー アプリケーションの作成」をご参照ください。
作成方法
テンプレートから作成:さまざまなシナリオ向けのアプリケーションテンプレートを使用して、AI アプリケーションを迅速に構築します。
タイプ別に作成:
標準:このタイプは一般的なアプリケーション開発をサポートします。大規模言語モデル、カスタム Python コード、その他のツールを使用してアプリケーションフローを構築できます。
対話型:このタイプは対話型アプリケーション開発向けに設計されています。「標準」タイプを拡張し、会話履歴や入出力の管理機能を追加し、ダイアログボックスを使用したテストインターフェイスを提供します。
OSS からインポート:アプリケーションフローの ZIP パッケージ、またはアプリケーションフローを含む OSS パスを選択します。このパスには、アプリケーションフローの flow.dag.yaml ファイルおよびその他のコードファイルが直接含まれている必要があります。
LangStudio のアプリケーションフローリストの [操作] 列にある [エクスポート] 機能を使用してアプリケーションフローをエクスポートし、他のユーザーと共有してインポートおよび利用できます。
Dify ドメイン固有言語(DSL)ファイルを LangStudio アプリケーションフロー形式に変換し、この方法でインポートできます。
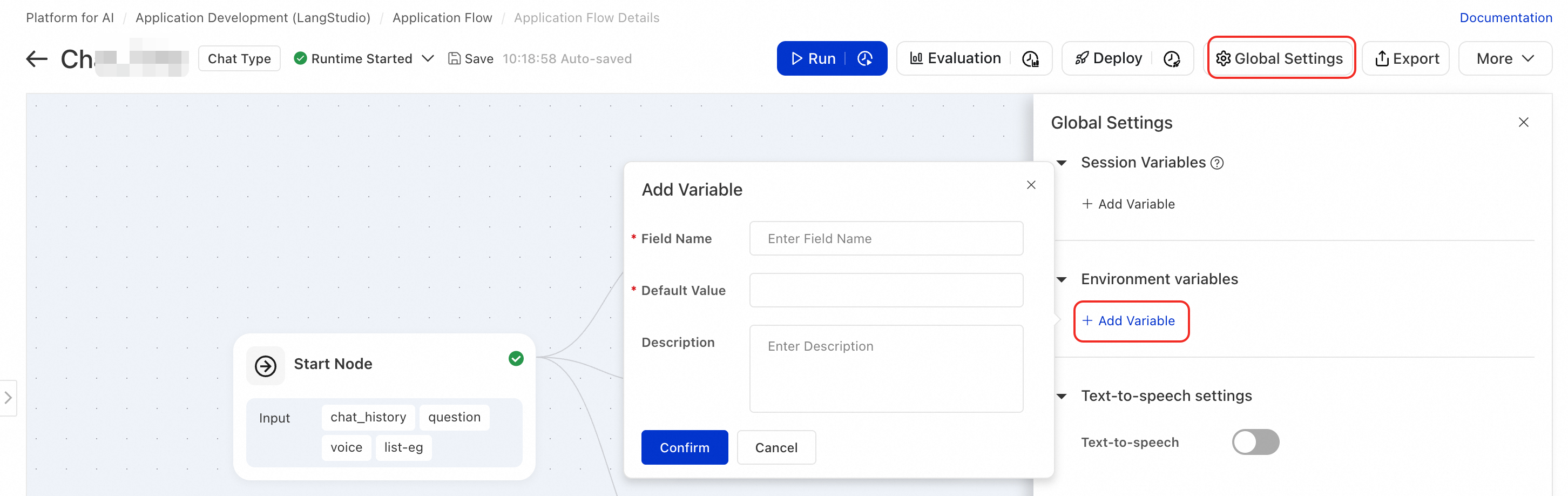
環境変数の設定
LangStudio では、アプリケーションフローの実行時に必要な環境変数を追加できます。システムはフロー実行前にこれらの変数を自動的に読み込みます。Python ノード、ツール呼び出し、カスタムロジックからこれらの変数にアクセス可能です。
利用シーン
機密情報の管理:API キー、認証トークンなどの機密情報をコード内にハードコードせずに保管します。
設定のパラメーター化:モデルエンドポイントやタイムアウト期間など、実行時パラメーターを柔軟に設定します。
設定と使用方法
アプリケーションフロー編集ページの右上隅にある Settings をクリックして、環境変数を追加します。
Python ノードでは、標準的な Python の
os.environを通じて構成済みの環境変数にアクセスできます。import os # 例:API キーの取得 api_key = os.environ["OPENAI_API_KEY"]
対話型音声応答の構成
アプリケーションフロー編集ページの右上隅にある Settings をクリックします。Global Settings タブで、対話型音声応答の設定を行います。
音声テキスト変換
音声テキスト変換機能は、ユーザーの音声入力をテキストに変換します。このテキストは、スタートノードで「会話入力」としてマークされたフィールドの入力として使用されます。

構成パラメーター | 説明 |
モデル設定 | 構成済みのモデルサービス接続と自動音声認識(ASR)モデルを選択します。現在は Paraformer シリーズのモデルがサポートされています。 |
言語検出 | 音声認識の言語を設定します。現在は paraformer-v2 モデルのみが認識言語の指定に対応しています。 |
音声合成
音声合成(TTS)機能は、ワークフローの会話出力を自動的に音声に合成します。
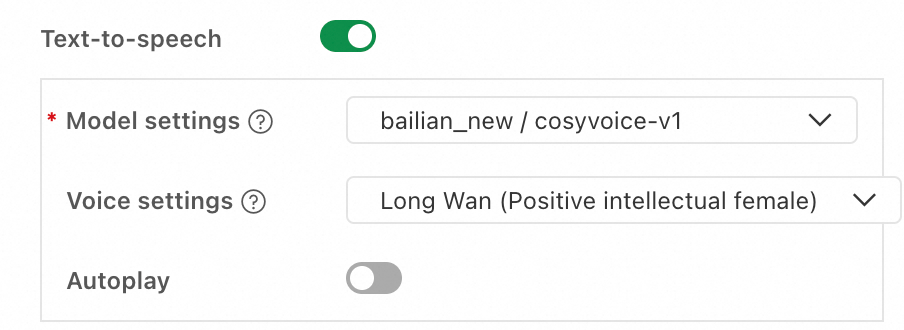
構成パラメーター | 説明 |
モデル設定 | 構成済みのモデルサービス接続と TTS モデルを選択します。現在は CosyVoice シリーズのモデルがサポートされています。 |
音声設定 | 合成音声の音声を選択します。さまざまなプリビルド音声がサポートされています。 |
自動再生 | この機能を有効にすると、会話中に合成音声が自動的に再生されます。 |
デプロイと呼び出し
アプリケーションを Elastic Algorithm Service (EAS) にデプロイします。その後、API 呼び出しを使用して対話型音声応答機能を有効にします。一般的な API 呼び出し方法については、「アプリケーションフローのデプロイ」をご参照ください。本項では、対話型音声応答に関連する差異について説明します。
音声入力
音声ファイルの URL を渡すには、リクエストボディに `system.audio_input` フィールドを追加します。ファイルのデータ構造の詳細については、「ファイルタイプの入力と出力」をご参照ください。システムが音声を自動的にテキストに変換し、会話入力フィールドに入力します。
{
"question": "",
"system": {
"audio_input": {
"source_uri": "oss://your-bucket.oss-cn-hangzhou.aliyuncs.com/audio/input.wav"
}
}
}音声出力
TTS によって合成された音声データを取得するには、フルモード(<Endpoint>/run エンドポイント)を使用して呼び出します。基本モードでは音声データは返されません。
フィールド | 説明 |
audio_data | Base64 エンコードされた音声データセグメントです。クライアントは、再生のためにセグメントをデコードして連結する必要があります。 |
tts_metadata | 音声メタデータです。フォーマット(pcm)、サンプルレート(22050 Hz)、チャンネル数(1)、ビット深度(16 ビット)が含まれます。 |
ストリーミング応答
TTS 音声は、Server-Sent Events(SSE)ストリーム内の TTSOutput イベントを通じて返されます。
{
"event": "TTSOutput",
"audio_data": "<Base64 エンコードされた音声データ>",
"tts_metadata": {
"format": "pcm",
"sample_rate": 22050,
"channels": 1,
"bit_depth": 16
}
}非ストリーミング応答
TTS 音声は、JSON 応答内の output.tts_audio フィールドとして含まれます。
{
"output": {
"answer": "xxx",
"tts_audio": {
"audio_data": "<Base64 エンコードされた完全な音声データ>",
"tts_metadata": {
"format": "pcm",
"sample_rate": 22050,
"channels": 1,
"bit_depth": 16
}
}
}
}事前構築済みコンポーネント
詳細については、「ワークフローノード リファレンス」をご参照ください。
次のステップ
アプリケーションフローを開発およびテストした後は、アプリケーションフローを評価できます。フローがビジネス要件を満たしたら、アプリケーションフローを EAS にデプロイして本番環境で使用できます。